MyBatis 源码解析
本文源码解析针对的是 MyBatis 3.4.4
MyBatis 执行流程
第一阶段
MyBatis 在这个阶段获得 Mapper 的动态代理对象,具体逻辑如下图所示:
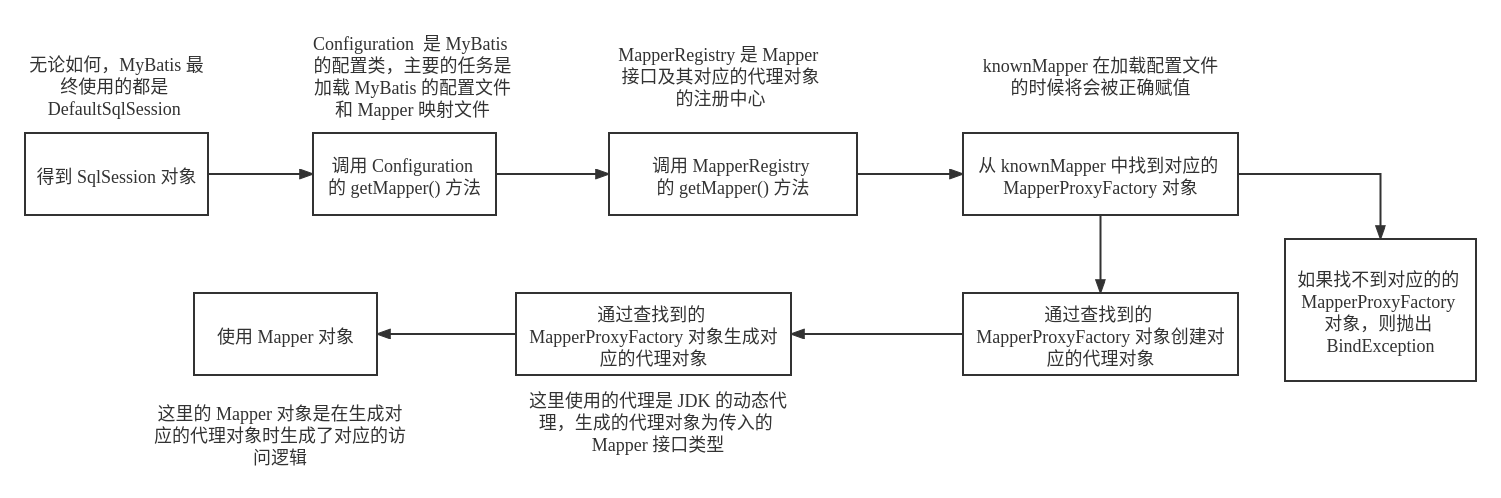
其中,Configuration 类和 MapperRegistry 都是在创建 SqlSession 对象时对相关的 MyBatis 配置文件 和 Mapper XML 映射文件进行加载的,因此不需要做过多的深入
生成动态代理对象的主要逻辑在 MapperProxyFactory 类中,通过传入的接口的类型来生成对应的代理对象,主要的源代码如下:
// 使用 JDK 动态代理的方式生成对应的代理对象protected T newInstance(MapperProxy<T> mapperProxy) {return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] {mapperInterface}, mapperProxy);}public T newInstance(SqlSession sqlSession) {/*** 创建MapperProxy对象,每次调用都会创建新的MapperProxy对象,MapperProxy implements InvocationHandler** MapperProxy 是真正执行 SQL 语句的地方*/final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);return newInstance(mapperProxy);}
第二阶段
该阶段的主要任务是生成对应的 Mapper 接口方法对象
通过第一阶段得到的 Mapper 对象,当使用 Mapper 接口的相关方法时,由于 MyBatis 使用的是 JDK 的动态代理,因此对于 Mapper 接口的任何方法的调用都会调用到代理对象的 invoke() 方法,在 MyaBatis 当前的上下文环境中,该 inboke() 方法的具体逻辑如下图所示:
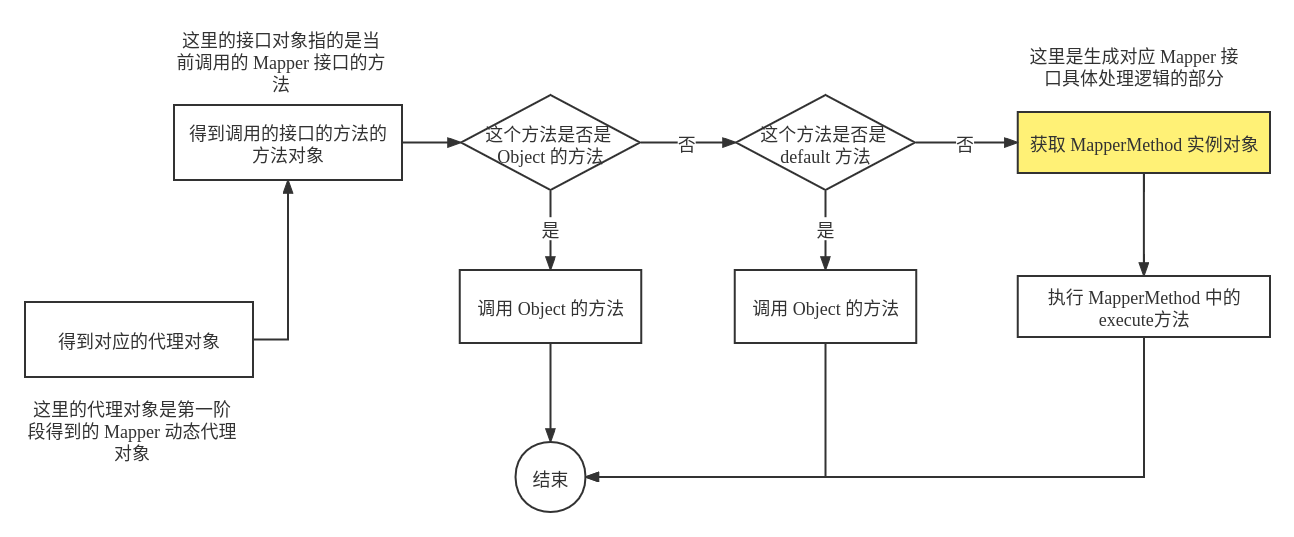
具体的源代码如下所示:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {try {/*如果当前执行的方法对象对应的方法是 Object 的方法,如 hash()、toString()、equals() 等,那么直接执行 Object 的方法*/if (Object.class.equals(method.getDeclaringClass())) {return method.invoke(this, args);}/*由于较高版本的 JDK 允许接口定义 default 方法,因此遇到这类方法时优先执行这类方法*/else if (isDefaultMethod(method)) {return invokeDefaultMethod(proxy, method, args);}} catch (Throwable t) {throw ExceptionUtil.unwrapThrowable(t);}/*如果不是 Object 的方法或者接口的 default 方法,那么就需要加载对应的具体方法了*/final MapperMethod mapperMethod = cachedMapperMethod(method);/*获得对应的 MapperMethod 对象后,需要执行 MapperMethod 的 execute() 方法,这个方法是实际 SQL 的执行点*/return mapperMethod.execute(sqlSession, args);}
具体来讲, MapperMethod 是真正处理逻辑的地方。获取 MapperMethod的过程如下:首先从对应的缓存中查找是否存在对应的 MapperMethod 方法,如果存在则直接村缓存中获取到这个 MaperMethod 对象,否则的话就需要生成一个新的 MapperMethod 对象,同时将这个新的 MapperMethod 对象放入缓存中。具体的流程如下图所示:
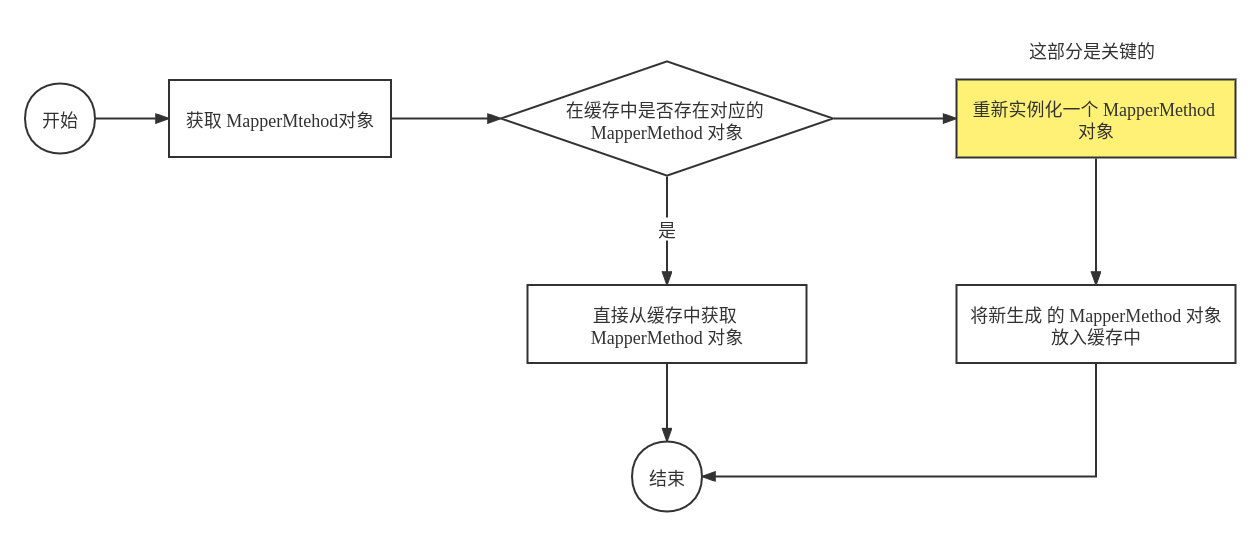
其中,关键的部分是实例化 MapperMethod 对象,因为具体的逻辑都是在实例化 MapperMethod 对象时指定了的。
对应的源代码如下:
private MapperMethod cachedMapperMethod(Method method) {/*** 在缓存中查找MapperMethod,若没有,则创建MapperMethod对象,并添加到methodCache集合中缓存*/MapperMethod mapperMethod = methodCache.get(method);// 构建mapperMethod对象,并维护到缓存methodCache中if (mapperMethod == null) {mapperMethod = new MapperMethod(mapperInterface, method, sqlSession.getConfiguration());methodCache.put(method, mapperMethod); // 这里的 methodCache 使用 ConcurrentHashMap 作为缓存的集合}return mapperMethod;}
现在关键的部分就是 MapperMethod 的实例化过程了。实例化 MapperMethod 主要的工作就是实例化 SqlCommand 对象和 MethodSignature 对象。
对应的源代码如下所示:
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {this.command = new SqlCommand(config, mapperInterface, method); // 实例化 SqlCommane 对象this.method = new MethodSignature(config, mapperInterface, method); // 实例化 MethodSignature 对象}
SqlCommand 的实例化
SqlCommand 对象只存储两个属性字段:一个是 MapperStatement 的唯一标识 name;另一个是这个 MapperMethod 执行的 Sql 语句的类型 type("SELECT"、“UPDATE”、“INSERT” 等)
具体源代码如下所示:
// SqlCommand 是 MapperMethod 的一个静态类public static class SqlCommand {/** MappedStatement的唯一标识 */private final String name;/** sql的命令类型 UNKNOWN, INSERT, UPDATE, DELETE, SELECT, FLUSH; */private final SqlCommandType type;// 省略构造函数和其他的源代码}
对于 SqlCommand 的实例化,具体的初始化流程如下所示:
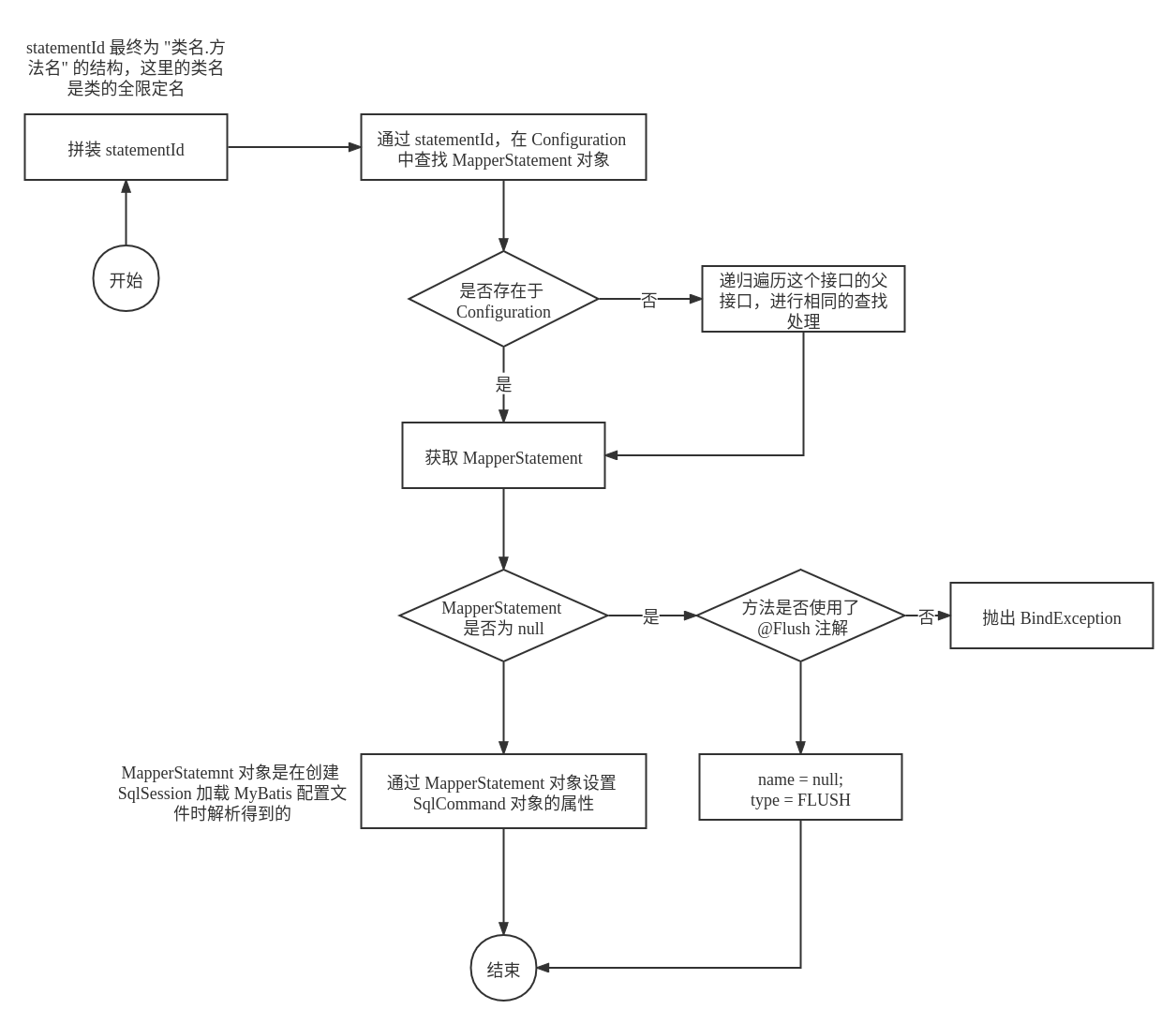
SqlCommand 初始化的主要部分在于如何通过传入的方法和接口类来加载对应的 MapperStatement 对象,具体的源代码如下所示:
private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName,Class<?> declaringClass, Configuration configuration) {String statementId = mapperInterface.getName() + "." + methodName;// 在 Configuration 对象中查找是否存在该方法。注意,这里的方法名是 "类的全限定名.方法名"if (configuration.hasStatement(statementId)) {// 如果能够查找到,那么返回这个 MapperStatement 对象return configuration.getMappedStatement(statementId);} else if (mapperInterface.equals(declaringClass)) { // 传入的接口类和声明的类一样,那么就没有必要再去向父接口再去查找了return null;}// 这个方法在当前接口无法找到,那么将会递归处理父接口,以此来查找对应的方法for (Class<?> superInterface : mapperInterface.getInterfaces()) {if (declaringClass.isAssignableFrom(superInterface)) {MappedStatement ms = resolveMappedStatement(superInterface, methodName,declaringClass, configuration);if (ms != null) {return ms;}}}return null;}
MethodSignature 实例化
MethodSignature 主要的任务是维护方法签名,如方法的返回值类型、入参名称等。
MethodSignature 的属性字段如下所示:
private final boolean returnsMany; // 判断返回类型是集合或者数组吗private final boolean returnsMap; // 判断返回类型是Map类型吗private final boolean returnsVoid; // 判断返回类型是集void吗private final boolean returnsCursor; // 判断返回类型是Cursor类型吗private final Class<?> returnType; // 方法返回类型private final String mapKey; // 获得@MapKey注解里面的value值private final Integer resultHandlerIndex; // 入参为ResultHandler类型的下标号private final Integer rowBoundsIndex; // 入参为RowBounds类型的下标号private final ParamNameResolver paramNameResolver; // 入参名称解析器
MethodSignature 实例化的主要任务就是解析传入的方法对象,初始化这些属性字段。
对应的源代码如下所示:
public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) {Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface);// 判断返回的类型是否是实体类if (resolvedReturnType instanceof Class<?>) {this.returnType = (Class<?>) resolvedReturnType;} else if (resolvedReturnType instanceof ParameterizedType) {this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType();} else {this.returnType = method.getReturnType();}this.returnsVoid = void.class.equals(this.returnType);/** 判断returnType是否为集合或者数组 */this.returnsMany = (configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray());this.returnsCursor = Cursor.class.equals(this.returnType);/** 判断returnType是否为 Map 类型 */this.mapKey = getMapKey(method);this.returnsMap = (this.mapKey != null);/** 获得方法 method 中,入参为 RowBounds 类型的下标号 */this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);/** 获得方法method中,入参为ResultHandler类型的下标号 */this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);/** 生成paramNameResolver实例对象, 构造方法中已经对参数序号和参数名称进行了映射 */this.paramNameResolver = new ParamNameResolver(configuration, method);}
值得注意的是对于参数的解析,具体的源代码如下所示:
// 解析方法入参,维护到names中。public ParamNameResolver(Configuration config, Method method) {final Class<?>[] paramTypes = method.getParameterTypes();/*由于一个方法参数可以被多个注解修饰,因此需要使用一个二维数组来存储这些注解信息这个二维数组是从做向右开始遍历的,第一维表示参数顺序,第二维表示修饰的注解*/final Annotation[][] paramAnnotations = method.getParameterAnnotations();// 这个 Map 维护的是参数位置索引和参数名称之间的映射关系。通过这个 Map,在之后的实际传入参数处理中将会十分方便final SortedMap<Integer, String> map = new TreeMap<>();int paramCount = paramAnnotations.length;// 处理被 @Param 注解修饰的参数for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {// 判断是否是特殊的参数——即:RowBounds.class或ResultHandler.classif (isSpecialParameter(paramTypes[paramIndex])) {continue;}String name = null;// 通过 @Param 得到对应的 SQL 参数的名称for (Annotation annotation : paramAnnotations[paramIndex]) {if (annotation instanceof Param) {hasParamAnnotation = true;name = ((Param) annotation).value();break;}}// 对于没有使用 @Param 注解修饰的参数,将会通过实际 SQL 中使用的参数进行关联if (name == null) {/** @Param was not specified;useActualParamName默认值为true*/if (config.isUseActualParamName()) {/** use the parameter index as the name ("arg0", "arg1", ...) */name = getActualParamName(method, paramIndex);}if (name == null) {/** use the parameter index as the name ("0", "1", ...) */name = String.valueOf(map.size());}}map.put(paramIndex, name);}// 这个映射关系应当是不能被修改的names = Collections.unmodifiableSortedMap(map);}
第三阶段
这个阶段的主要任务是通过第二阶段生成的 SqlCommand 对象,选择合适的执行 SQL 的方法。
具体流程如下所示:
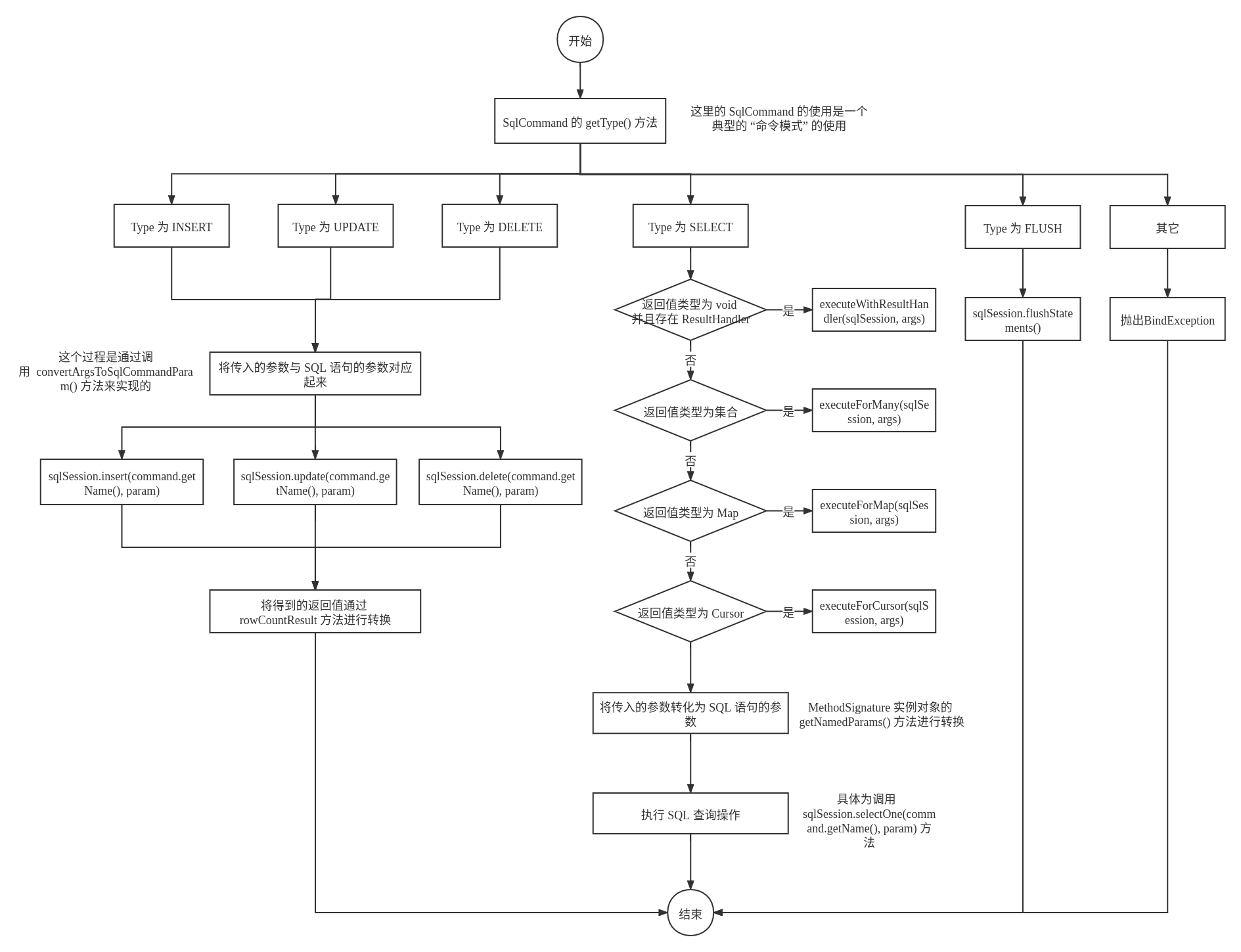
以执行 SELECT 类型的 SQL 语句为例,假设查询返回的是单个的对象(其它的类似),首先会将方法中传入的查询参数与 SQL 中的参数进行转换,这个过程是在 ParamNameResolver 的 getNamedParams(Object[] args) 方法中完成额。具体的源代码如下所示:
// 将传入的参数与 SQL 中需要的参数对应起来public Object getNamedParams(Object[] args) {// eg1: names={0:"id"} paramCount=1final int paramCount = names.size();if (args == null || paramCount == 0) {return null;}/**如果不包含@Param注解并且只有一个入参,那么这个参数就是唯一确定的*/else if (!hasParamAnnotation && paramCount == 1) {return args[names.firstKey()]; // 0 -> "arg0"} else {final Map<String, Object> param = new ParamMap<>();int i = 0;// 遍历在创建 MethodSignature 过程中解析参数时得到的 Map,设置每个参数对应的实际参数for (Map.Entry<Integer, String> entry : names.entrySet()) {// 将 SQL 中的处理参数与传入的参数进行绑定param.put(entry.getValue(), args[entry.getKey()]);/*** add generic param names (param1, param2, ...)*/final String genericParamName = GENERIC_NAME_PREFIX + String.valueOf(i + 1);/*** ensure not to overwrite parameter named with @Param*/if (!names.containsValue(genericParamName)) {param.put(genericParamName, args[entry.getKey()]);}i++;}return param;}}
由于具体的 SQL 语句在打开 SqlSession 时就已经加载了,因此执行 SQL 的时候只需要从配置中拿到这个对应的 SQL,再通过解析的参数进行查询即可。
第四阶段
这个阶段的主要任务是处理真正查询之前的缓存。
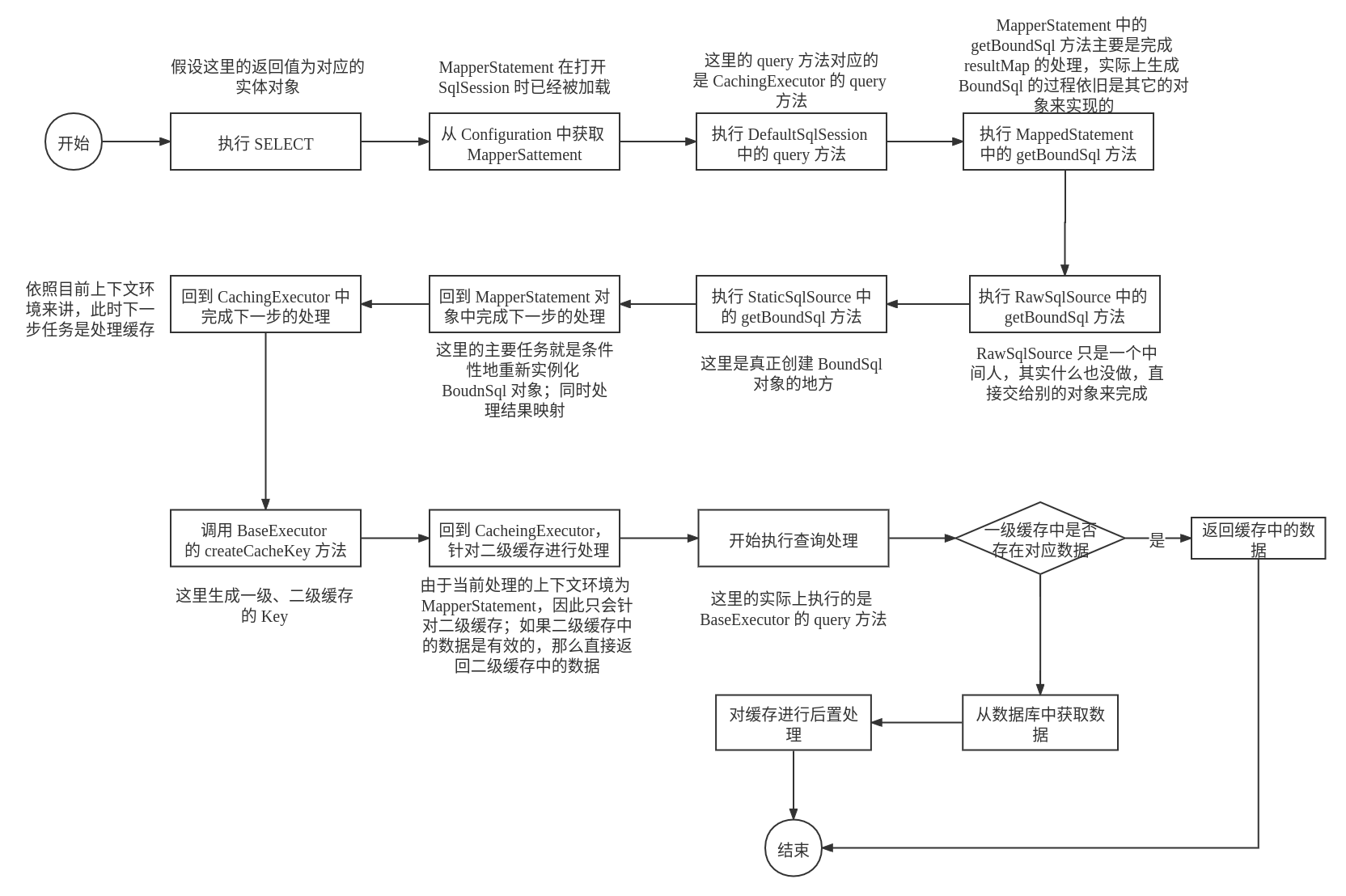
实例化 BoundSql 对象
BoundSql 对象的主要任务是用于建立 SQL 和对应的参数,一个 BoundSql 对象的实例化流程如下:
实例化的 BoundSql ——> StaticSqlSource ——> RawSqlSource ——> MapperStatement ——> CachingExecutor
主要需要关注的地方是 MapperStatement 中对于 BoundSql实例对象的处理:
// BoundSql 是为了将 Mapper XML 中的参数进行转化,即原来为参数的地方要转换为 '?' 以及其对应位置的对应参数映射信息等public BoundSql getBoundSql(Object parameterObject) {// 这里的 BoundSql 对象来自 RawSqlSourceBoundSql boundSql = sqlSource.getBoundSql(parameterObject);// 获得相关的参数信息List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();// 如果参数信息为空,那么将会重新实例化一个 BoundSql 对象if (parameterMappings == null || parameterMappings.isEmpty()) {boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);}/*** 处理结果映射,对应 Mapper XML 映射文件的 resultMap 属性*/for (ParameterMapping pm : boundSql.getParameterMappings()) {String rmId = pm.getResultMapId();// eg1: rmId = nullif (rmId != null) {ResultMap rm = configuration.getResultMap(rmId);if (rm != null) {hasNestedResultMaps |= rm.hasNestedResultMaps();}}}return boundSql;}
缓存的处理
在 CachingExecutor 的 query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,ResultHandler resultHandler) 方法中,在获取了 BoundSql 对象之后,将会创建缓存 key,作为本次查询结果的 key。这里创建缓存 key 的任务是有 BaseExecutor 的 createCacheKey 方法来完成的。
对于二级缓存的处理
由于二级缓存实在 Mapper XML 映射文件中开启的,因此它只能针对特定的 Mapper。
在执行查询时,首先会检测是否存在二级缓存,如果存在,那么就需要进一步地检测这个二级缓存是否是有效的;如果这个二级缓存是有效的,那么将会从二级缓存中进行读取数据,如果读取不到那么将会直接进行数据库的查询;如果这个二级缓存不是有效的,那么将会首先清除二级缓存,再从数据库中读取,再添加到二级缓存中。
对应的源代码如下所示:
Cache cache = ms.getCache();// 如果开启了二级缓存,即在 Mapper XML 映射文件中添加了 <cache />,那么将能够检测到二级缓存的存在if (cache != null) {/*** 如果flushCacheRequired=true并且缓存中有数据,则先清空缓存** <select id="save" parameterType="XXXXXEO" statementType="CALLABLE" flushCache="true" useCache="false">* ……* </select>* */flushCacheIfRequired(ms);if (ms.isUseCache() && resultHandler == null) {ensureNoOutParams(ms, parameterObject, boundSql);@SuppressWarnings("unchecked")List<E> list = (List<E>) tcm.getObject(cache, key);if (list == null) {// 二级缓存中不存在对应数据,需要进行数据库的查询list = delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);// 以cacheKey为主键,将结果维护到缓存中tcm.putObject(cache, key, list); // issue #578 and #116}return list;}}
对于一级缓存的处理
一级缓存的处理将在
BaseExecutor中进行处理,具体的源代码如下所示:public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,CacheKey key, BoundSql boundSql) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());if (closed) {throw new ExecutorException("Executor was closed.");}/** 如果配置了flushCacheRequired=true并且queryStack=0(没有正在执行的查询操作),则会执行清空缓存操作*/if (queryStack == 0 && ms.isFlushCacheRequired()) {clearLocalCache();}List<E> list;try {/** 记录正在执行查询操作的任务数*/queryStack++;/** localCache维护一级缓存,试图从一级缓存中获取结果数据,如果有数据,则返回结果;如果没有数据,再执行queryFromDatabase */list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;// eg1: list = nullif (list != null) {// 如果一级缓存中存在对应的数据,那么将从缓存中读取数据handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);} else {// 在一级缓存中不存在对应的数据,需要从数据库中进行查找list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);}} finally {queryStack--;}if (queryStack == 0) {/** 延迟加载处理 */for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601deferredLoads.clear();// eg1: configuration.getLocalCacheScope()=SESSION/** 如果设置了<setting name="localCacheScope" value="STATEMENT"/>,则会每次执行完清空缓存。即:使得一级缓存失效 */if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {// issue #482clearLocalCache();}}return list;}
第五阶段
这个阶段的任务是预执行 SQL,然后设置相关的参数,执行相关的 SQL 语句
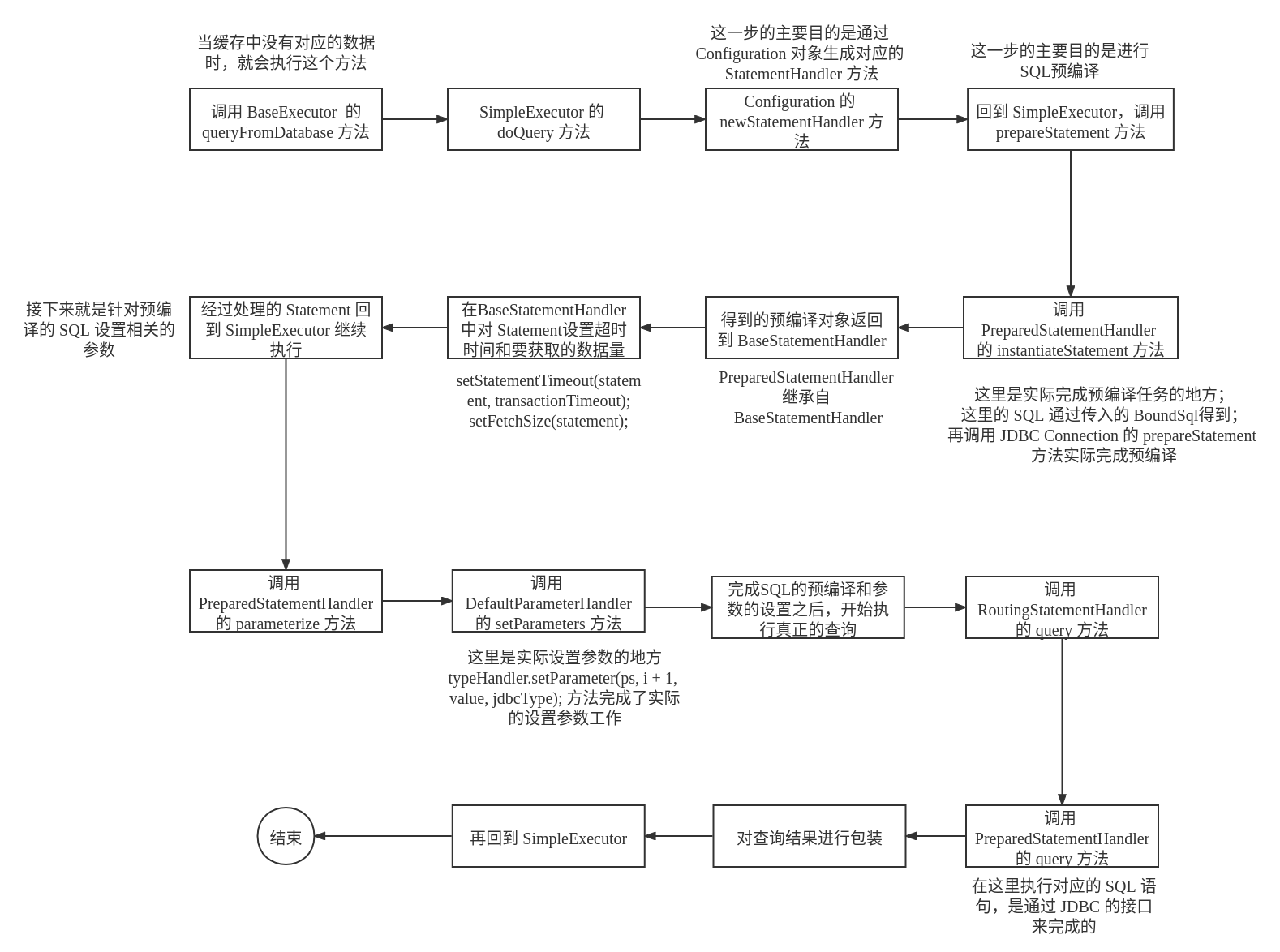
SQL的预处理调用链为
SimpleExecutor——>PreparedStatementHandler——>BaseStatementHandler——>PreparedStatementHandler对应的源代码如下所示:
@Overrideprotected Statement instantiateStatement(Connection connection) throws SQLException {// 这里的 SQL 是经过参数映射转换的,即有参数的地方已经转换为了 '?'String sql = boundSql.getSql();if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {String[] keyColumnNames = mappedStatement.getKeyColumns();if (keyColumnNames == null) {return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);} else {return connection.prepareStatement(sql, keyColumnNames);}} else if (mappedStatement.getResultSetType() != null) {return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(),ResultSet.CONCUR_READ_ONLY);} else {// 预执行 SQL 语句return connection.prepareStatement(sql);}}
除了预处理
SQL之外,在这个过程中还会设置SQL语句的最大执行时间和要获取的数据行的个数等信息(分页的操作就在这里处理)对预处理的
SQL设置对应的参数通过对
SQL的预处理,下一步就是设置对应的参数,设置了参数之后的SQL就可以直接被执行具体设置参数的源代码如下所示:
// 设置参数的工作是由 DefaultParameterHandler 类进行处理的public void setParameters(PreparedStatement ps) {ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());// 之前在实例化 BoundSql 的过程中已经设置了相关的参数映射关系List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();if (parameterMappings != null) {// 遍历这个参数映射集合,将对应的参数放到正确的位置上for (int i = 0; i < parameterMappings.size(); i++) {ParameterMapping parameterMapping = parameterMappings.get(i);// eg1: parameterMapping.getMode() = INif (parameterMapping.getMode() != ParameterMode.OUT) {// 从传入的参数中获取值Object value;String propertyName = parameterMapping.getProperty();if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional paramsvalue = boundSql.getAdditionalParameter(propertyName);} else if (parameterObject == null) {value = null;} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {// 对于一般的基本数据类型的装箱类,都有对应的 typeHandlervalue = parameterObject;} else {// 传入的是一个实体对象,那么需要通过反射的方式从这个对象中获取对应的属性值MetaObject metaObject = configuration.newMetaObject(parameterObject);value = metaObject.getValue(propertyName);}// 从参数对象中获取值的过程结束。。。。。。// 将数据库表中列的类型与对象属性字段的类型对应起来TypeHandler typeHandler = parameterMapping.getTypeHandler();JdbcType jdbcType = parameterMapping.getJdbcType();if (value == null && jdbcType == null) {jdbcType = configuration.getJdbcTypeForNull();}// 对应阶段结束// 针对预处理语句和得到的参数值,设置对应的 SQL 语句的实际参数typeHandler.setParameter(ps, i + 1, value, jdbcType);}}}}
执行
SQL通过上面的步骤,现在已经得到了一个可以执行的
SQL,这一步的主要任务是执行这个SQL,同时将得到的结果进行包装对应的源代码如下:
// 这里的任务是通过 PreparedStatementHandler 对象来完成的public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {// 调用 JDBC 的 PreparedStatement 去执行 SQLPreparedStatement ps = (PreparedStatement) statement;// 执行这个 SQLps.execute();/** 将结果集进行封装 */return resultSetHandler.handleResultSets(ps);}
在执行完 SQL 之后,将会删除旧的缓存,将这次从数据库中查找得到的数据保存到缓存(一级缓存)中
第六阶段
以查询数据为例,会调用 DefaultResultSetHandler 对象的 handleResultSets 方法来进行结果集的处理。
调用
getFirstResultSet方法,获取执行之后的结果集,并且封装到ResultSetWrapper对象中,对应的源代码如下所示:private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException {/** 通过JDBC获得结果集ResultSet */ResultSet rs = stmt.getResultSet();while (rs == null) {if (stmt.getMoreResults()) {rs = stmt.getResultSet();} else {/*** getUpdateCount()==-1,既不是结果集,又不是更新计数了.说明没的返回了。* 如果getUpdateCount()>=0,则说明当前指针是更新计数(0的时候有可能是DDL指令)。* 无论是返回结果集或是更新计数,那么则可能还继续有其它返回。* 只有在当前指指针getResultSet()==null && getUpdateCount()==-1才说明没有再多的返回。*/if (stmt.getUpdateCount() == -1) {// no more results. Must be no resultsetbreak;}}}/** 将结果集ResultSet封装到ResultSetWrapper实例中 */return rs != null ? new ResultSetWrapper(rs, configuration) : null;}
从
MappeedStatement对象中获取ResultMap列表(还记得 Mapper XML 中配置的resultMap吗?)遍历
ResultMap集合,针对每个ResultMap对象进行相应的处理,对应的源代码如下所示:final List<Object> multipleResults = new ArrayList<>(); // 存储 ResultMapint resultSetCount = 0;// 从 MappedStatement 对象中获取对应的 ResultMap 列表List<ResultMap> resultMaps = mappedStatement.getResultMaps();int resultMapCount = resultMaps.size();while (rsw != null && resultMapCount > resultSetCount) {// 遍历每个 ResultMap 对象ResultMap resultMap = resultMaps.get(resultSetCount);/** 处理结果集, 存储在 multipleResults 中 */handleResultSet(rsw, resultMap, multipleResults, null);// 通过游标的方式获取下一条数据rsw = getNextResultSet(stmt);cleanUpAfterHandlingResultSet();resultSetCount++;}
第三步的主要任务是处理结果集,对应的源代码如下所示:
// 此方法位于 DefaultResultSetHandler 对象中private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults,ResultMapping parentMapping) throws SQLException {try {if (parentMapping != null) {handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);} else {if (resultHandler == null) {/** 初始化ResultHandler实例,用于解析查询结果并存储于该实例对象中 */DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);/** 解析行数据 */handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);multipleResults.add(defaultResultHandler.getResultList());} else {handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);}}} finally {/** 关闭ResultSet */closeResultSet(rsw.getResultSet());}}
最终都会调用
DefaultResultSetHandler的handleRowValues方法,对指定的行数据进行处理这一步的任务主要是针对不同的返回结果进行一个选择,针对不同的返回结果进行处理
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler,RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {/** 是否是聚合Nested类型的结果集 */if (resultMap.hasNestedResultMaps()) {ensureNoRowBounds();checkResultHandler();// 针对 NestedResultMap 的结果进行处理handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);} else {// 针对 SimpleResultMap进行处理handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);}}
这里以简单查询为例,因此最终会执行
handleRowValuesForSimpleResultMap方法这一步的主要任务是处理行数据,对应的源代码如下所示
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap,ResultHandler<?> resultHandler, RowBounds rowBounds,ResultMapping parentMapping) throws SQLException {DefaultResultContext<Object> resultContext = new DefaultResultContext<>();/**将指针移动到rowBounds.getOffset()指定的行号,即:略过(skip)offset之前的行*/skipRows(rsw.getResultSet(), rowBounds);while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) {/**解析结果集中的鉴别器<discriminate/>,即鉴别器这个一般来讲不会遇到,因此一般为 null*/ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);/**将数据库操作结果保存到POJO并返回,这里是真正处理数据的地方*/Object rowValue = getRowValue(rsw, discriminatedResultMap);/**存储POJO对象到DefaultResultHandler中*/storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());}}
getRowValue,对应的源代码如下:/*** 将数据库操作结果保存到 POJO 并返回*/private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException {final ResultLoaderMap lazyLoader = new ResultLoaderMap();/** 创建空的结果对象 */Object rowValue = createResultObject(rsw, resultMap, lazyLoader, null);/*对这个返回结果执行对应的 typeHandler;如果这个 resultType 不存在 typeHandler,则直接返回原来的对象*/if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {/**创建rowValue的metaObject*/final MetaObject metaObject = configuration.newMetaObject(rowValue);boolean foundValues = this.useConstructorMappings;/** 是否应用自动映射 */if (shouldApplyAutomaticMappings(resultMap, false)) {/*** 将查询出来的值赋值给metaObject中的POJO对象*/foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;}foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues;foundValues = lazyLoader.size() > 0 || foundValues;/**configuration.isReturnInstanceForEmptyRow() 当返回行的所有列都是空时,MyBatis默认返回null。当开启这个设置时,MyBatis会返回一个空实例。*/rowValue = (foundValues || configuration.isReturnInstanceForEmptyRow()) ? rowValue : null;}return rowValue;}
其中,最主要的两部分是调用
createResultObject方法创建一个结果对象和调用applyAutomaticMappings方法将查询到的数据赋值到创建的结果对象中。createResultObject的源代码如下:private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader,String columnPrefix) throws SQLException {this.useConstructorMappings = false; // 重置原来的映射关系final List<Class<?>> constructorArgTypes = new ArrayList<>();final List<Object> constructorArgs = new ArrayList<>();/**创建一个空的resultMap.getType()类型的实例对象*/Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);/**判断resultMap.getType() 是否存在TypeHandler*/if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();for (ResultMapping propertyMapping : propertyMappings) {/**如果是聚合查询并且配置了懒加载*/if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration,objectFactory, constructorArgTypes, constructorArgs);break;}}}this.useConstructorMappings = (resultObject != null && !constructorArgTypes.isEmpty());return resultObject;}
applyAutomaticMappings的源代码如下所示:private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject,String columnPrefix) throws SQLException {/**创建自动映射集合*/List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);boolean foundValues = false;if (autoMapping.size() > 0) {// 遍历这些映射的对象,从对应的列中获取数据for (UnMappedColumnAutoMapping mapping : autoMapping) {final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);if (value != null) {foundValues = true;}if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {// 将查询到的数据放到对应的属性中metaObject.setValue(mapping.property, value);}}}return foundValues;}
UnMappedColumnAutoMapping类定义如下:private static class UnMappedColumnAutoMapping {private final String column;private final String property;private final TypeHandler<?> typeHandler;private final boolean primitive;public UnMappedColumnAutoMapping(String column, String property, TypeHandler<?> typeHandler,boolean primitive) {this.column = column;this.property = property;this.typeHandler = typeHandler;this.primitive = primitive;}}
storeObject,主要的任务是将查询到的 POJO 对象存储到ResultHandler对象中(这里是DefaultResultHandler)private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext,Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {if (parentMapping != null) {linkToParents(rs, parentMapping, rowValue);} else {/** 将结果存储到DefaultResultHandler中 */callResultHandler(resultHandler, resultContext, rowValue);}}
MyBatis 源码解析的更多相关文章
- 【MyBatis源码解析】MyBatis一二级缓存
MyBatis缓存 我们知道,频繁的数据库操作是非常耗费性能的(主要是因为对于DB而言,数据是持久化在磁盘中的,因此查询操作需要通过IO,IO操作速度相比内存操作速度慢了好几个量级),尤其是对于一些相 ...
- Mybatis源码解析-DynamicSqlSource和RawSqlSource的区别
XMLLanguageDriver是ibatis的默认解析sql节点帮助类,其中的方法其会调用生成DynamicSqlSource和RawSqlSource这两个帮助类,本文将对此作下简单的简析 应用 ...
- mybatis源码-解析配置文件(四-1)之配置文件Mapper解析(cache)
目录 1. 简介 2. 解析 3 StrictMap 3.1 区别HashMap:键必须为String 3.2 区别HashMap:多了成员变量 name 3.3 区别HashMap:key 的处理多 ...
- mybatis源码-解析配置文件(四)之配置文件Mapper解析
在 mybatis源码-解析配置文件(三)之配置文件Configuration解析 中, 讲解了 Configuration 是如何解析的. 其中, mappers作为configuration节点的 ...
- mybatis源码-解析配置文件(三)之配置文件Configuration解析
目录 1. 简介 1.1 系列内容 1.2 适合对象 1.3 本文内容 2. 配置文件 2.1 mysql.properties 2.2 mybatis-config.xml 3. Configura ...
- Mybatis源码解析,一步一步从浅入深(一):创建准备工程
Spring SpringMVC Mybatis(简称ssm)是一个很流行的java web框架,而Mybatis作为ORM 持久层框架,因其灵活简单,深受青睐.而且现在的招聘职位中都要求应试者熟悉M ...
- Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码
在文章:Mybatis源码解析,一步一步从浅入深(一):创建准备工程,中我们为了解析mybatis源码创建了一个mybatis的简单工程(源码已上传github,链接在文章末尾),并实现了一个查询功能 ...
- Mybatis源码解析,一步一步从浅入深(三):实例化xml配置解析器(XMLConfigBuilder)
在上一篇文章:Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码 ,中我们看到 代码:XMLConfigBuilder parser = new XMLConfigBuilder(read ...
- Mybatis源码解析,一步一步从浅入深(四):将configuration.xml的解析到Configuration对象实例
在Mybatis源码解析,一步一步从浅入深(二):按步骤解析源码中我们看到了XMLConfigBuilder(xml配置解析器)的实例化.而且这个实例化过程在文章:Mybatis源码解析,一步一步从浅 ...
- Mybatis源码解析,一步一步从浅入深(五):mapper节点的解析
在上一篇文章Mybatis源码解析,一步一步从浅入深(四):将configuration.xml的解析到Configuration对象实例中我们谈到了properties,settings,envir ...
随机推荐
- Go with Protobuf
原文在这里. 本教程为 Go 程序员提供了使用Protocol buffer的基本介绍. 本教程使用proto3向 Go 程序员介绍如何使用 protobuf.通过创建一个简单的示例应用程序,它向你展 ...
- Tarjan强连通分量详解
1.简介: 在阅读下列内容之前,请务必了解 图论相关概念 中的基础部分. 强连通的定义是:有向图 G 强连通是指,G 中任意两个结点连通. 强连通分量(Strongly Connected Compo ...
- jmeter的基本功能使用
jmeter安装配置 1.可以参考教程:https://blog.csdn.net/lfmsky1/article/details/88631190 jmeter简单基础使用步骤 (1)添加线程组 ( ...
- WPF 笔迹算法 从点集转笔迹轮廓
本文将告诉大家一些笔迹算法,从用户输入的点集,即鼠标轨迹点或触摸轨迹点等,转换为一个可在界面绘制显示笔迹画面的基础数学算法.尽管本文标记的是 WPF 的笔迹算法,然而实际上本文更侧重基础数学计算,理论 ...
- [ABC202E] Count Descendants 题解
Count Descendants 题目大意 给定一颗以 \(1\) 为根的树,多次询问求某点的子树中深度为给定值的点的个数. 思路分析 对于每个深度开一个 vector,从大到小存下这个深度的所有点 ...
- 掌握 Kubernetes 故障排除:有效维护集群的最佳实践和工具
Kubernetes 是一款管理容器化应用程序的强大工具.然而,与任何复杂的系统一样,使用它时也可能出错.当问题出现时, 掌握有效的故障排除技术和工具非常重要. 本文将介绍以下步骤,助您了解事件收集的 ...
- CSP2021游记
题外话 中午十二点半到了考场.没到时间不让进,恰巧发现 lhm 在对面饭店于是去讨论了一下上午 J 组的题,复习了线段树板子( 等到进考场坐好的时候已经两点半了,看考号本来以为我们同机房三个同学会坐一 ...
- ORACLE SQL语句逻辑读高优化案例
川川找我优化SQL,逻辑读达到398,000,安排一下. SQL和执行计划: SELECT t1.*, t3.bed_number, t3.patient_name, t4.name FROM odw ...
- decltype关键词
简述 decltype 是 C++11 新增的一个关键字,它和 auto 的功能一样,都用来在编译时期进行自动类型推导. decltype 是"declare type"的缩写,译 ...
- Codeforces Round #697 (Div. 3) A~E题解
写在前边 状态及其不佳,很累很困,还好\(unrated\)了 链接:Codeforces Round #697 (Div. 3) A. Odd Divisor 链接:A题链接 题目大意: 判断一个数 ...