[转帖]使用 Crash 工具分析 Linux dump 文件
前言
Linux 内核(以下简称内核)是一个不与特定进程相关的功能集合,内核的代码很难轻易的在调试器中执行和跟踪。开发者认为,内核如果发生了错误,就不应该继续运行。因此内核发生错误时,它的行为通常被设定为系统崩溃,机器重启。基于动态存储器的电气特性,机器重启后,上次错误发生时的现场会遭到破坏,这使得查找内核的错误变得异常困难。
内核社区和一些商业公司为此开发了很多种调试技术和工具,希望可以让内核的调试变得简单。其中一种是单步跟踪调试方法,即使用代码调试器,一步步的跟踪执行的代码,通过查看变量和寄存器的值来分析错误发生的原因。这一类的调试器有 gdb,kdb, kgdb。另一种方法是在系统崩溃时,将内存保存起来,供事后进行分析。多数情况下,单步调式跟踪可以满足需求,但是单步跟踪调试也有缺点。如遇到如下几种情况时:
错误发生在客户的机器上。
错误发生在很关键的生产机器上。
错误很难重现。
单步调试跟踪方法将无能为力。对于这几种情况,在内核发生错误并崩溃的时候,将内存转储起来供事后分析就显得尤为重要。本文接下来将介绍内核的内存转储机制以及如何对其进行分析。
内核的内存转储机制
由于 Linux 的开放性的缘故,在 Linux 下有好几种内存转储机制。下面将对它们分别做简要的介绍。
LKCD
LKCD(Linux Kernel Crash Dump) 是 Linux 下第一个内核崩溃内存转储项目,它最初由 SGI 的工程师开发和维护。它提供了一种可靠的方法来发现、保存和检查系统的崩溃。LKCD 作为 Linux 内核的一个补丁,它一直以来都没有被接收进入内核的主线。目前该项目已经完全停止开发。
Diskdump
Diskdump 是另外一个内核崩溃内存转储的内核补丁,它由塔高 (Takao Indoh) 在 2004 年开发出来。与 LKCD 相比,Diskdump 更加简单。当系统崩溃时,Diskdump 对系统有完全的控制。为避免混乱,它首先关闭所有的中断;在 SMP 系统上,它还会把其他的 CPU 停掉。然后它校验它自己的代码,如果代码与初始化时不一样。它会认为它已经被破坏,并拒绝继续运行。然后 Diskdump 选择一个位置来存放内存转储。Diskdump 作为一个内核的补丁,也没有被接收进入内核的主线。在众多的发行版中,它也只得到了 RedHat 的支持。
Netdump
RedHat 在它的 Linux 高级服务器 2.1 的版本中,提供了它自己的第一个内核崩溃内存转储机制:Netdump。 与 LKCD 和 Diskdump 将内存转储保存在本地磁盘不同,当系统崩溃时,Netdump 将内存转储文件通过网络保存到远程机器中。RedHat 认为采用网络方式比采用磁盘保的方式要简单,因为当系统崩溃时,可以在没有中断的情况下使用网卡的论询模式来进行网络数据传送。同时,网络方式对内存转储文件提供了更好的管理支持。与 Diskdump 一样,Netdump 没有被接收进入内核的主线,目前也只有 RedHat 的发行版对 Netdump 提供支持。
Kdump
Kdump 是一种基于 kexec 的内存转储工具,目前它已经被内核主线接收,成为了内核的一部分,它也由此获得了绝大多数 Linux 发行版的支持。与传统的内存转储机制不同不同,基于 Kdump 的系统工作的时候需要两个内核,一个称为系统内核,即系统正常工作时运行的内核;另外一个称为捕获内核,即正常内核崩溃时,用来进行内存转储的内核。 在本文稍后的内容中,将会介绍如何设置 kump。
MKdump
MKdump(mini kernel dump) 是 NTT 数据和 VA Linux 开发另一个内核内存转储工具,它与 Kdump 类似,都是基于 kexec,都需要使用两个内核来工作。其中一个是系统内核;另外一个是 mini 内核,用来进行内存转储。与 Kdump 相比,它有以下特点:
将内存保存到磁盘。
可以将内存转储镜像转换到 lcrash 支持格式。
通过 kexec 启动时,mini 内核覆盖第一个内核。
各种内存转储分析工具
与具有众多的内存转储机制一样,Linux 下也有众多的内存转储分析工具,下面将会逐一做简单介绍。
Lcrash
Lcrash 是随 LKCD 一起发布的一个内内存储分析工具。随着 LKCD 开发的停止,lcrash 的开发也同时停止了。目前它的代码已经被合并进入 Crash 工具中。
Alicia
Alicia (Advanced Linux Crash-dump Interactive Analyzer,高级 Linux 崩溃内存转储交互分析器 ) 是一个建立在 lcrash 和 Crash 工具之上的一个内存转储分析工具。它使用 Perl 语言封装了 Lcrash 和 Crash 的底层命令,向用户提供了一个更加友好的交互方式和界面。Alicia 目前的开发也已经停滞。
Crash
Crash 是由 Dave Anderson 开发和维护的一个内存转储分析工具,目前它的最新版本是 5.0.0。 在没有统一标准的内存转储文件的格式的情况下,Crash 工具支持众多的内存转储文件格式,包括:
Live linux 系统
kdump 产生的正常的和压缩的内存转储文件
由 makedumpfile 命令生成的压缩的内存转储文件
由 Netdump 生成的内存转储文件
由 Diskdump 生成的内存转储文件
由 Kdump 生成的 Xen 的内存转储文件
IBM 的 390/390x 的内存转储文件
LKCD 生成的内存转储文件
Mcore 生成的内存转储文件
使用 Crash 分析内存转储文件的例子
通过前面的学习,你现在可能已经跃跃欲试了。本文接下来的部分,将以 kdump 为例子,向大家演示如何设置系统、如何产生内存转储文件以及如何对内存转储文件进行分析。
kdump 的安装设置
如前面所述,支持 kdump 的系统使用两个内核进行工作。目前一些发行版,如 RedHat 和 SUSE 的 Linux 都已经编译并设置好这两个内核。如果你使用其他发行版的 Linux 或者想自己编译内核支持 kdump,那么可以根据如下介绍进行。
安装 kexec
使用 root 用户登录系统。
使用 wget 从 Internet 上下载 kexec。
12wget http://www.kernel.org/pub/linux/kernel/people/horms/kexec-tools/\
kexec-tools.tar.gz解压并安装 kexec 到系统中。
1234# tar xvpzf kexec-tools.tar.gz# cd kexec-tools-VERSION# ./configure# make && make install
配置系统内核和捕捉内核都需要的内核选项:
在 "Processor type and features."选项中启用"kexec system call"。
1CONFIG_KEXEC=y在"Filesystem" -> "Pseudo filesystems." 中启用"sysfs file system support"。
1CONFIG_SYSFS=y在"Kernel hacking."中启用"Compile the kernel with debug info"。
1CONFIG_DEBUG_INFO=Y
配置捕捉内核的与架构无关的选项:
在"Processor type and features"中启用"kernel crash dumps"。
1CONFIG_CRASH_DUMP=y在"Filesystems" -> "Pseudo filesystems"中启用"/proc/vmcore support"。
1CONFIG_PROC_VMCORE=y
配置捕捉内核的与架构相关的选项:
Linux 内核支持多种 CPU 架构,这里只介绍捕捉内核在 i386 下的配置
在"Processor type and features"中启用高端内存支持。
1CONFIG_HIGHMEM64G=y在"Processor type and features"中关闭多处理器支持。
1CONFIG_SMP=n在"Processor type and features"中启用"Build a relocatable kernel"。
1CONFIG_RELOCATABLE=y在"Processor type and features"->"Physical address where the kernel is loaded"中,为内核设置一个加载起始地址。在大多数的机器上,16M 是一个合适的值。
1CONFIG_PHYSICAL_START=0x1000000
加载新的系统内核
编译系统内核和捕捉内核。
将重新编译好的内核添加到启动引导中,注意不要将捕捉内核添加到启动引导菜单中。
给系统内核添加启动参数"crashkernel=Y@X",这里,Y 是为 dump 捕捉内核保留的内存,X 是保留部分内存的开始位置。在 i386 的机器上,设置"crashkernel=64M@16M"。
重启机器,在启动菜单中选择新添加的启动项,启动新的系统内核。
加载捕捉内核
在系统内核引导完成后,需要将捕捉内核加载到内存中。使用 kexec 工具将捕捉内核加载到内存:
|
1
2
3
|
# kexec -p <dump-capture-kernel-bzImage> \
--initrd=<initrd-for-dump-capture-kernel> \
--append="root=<root-dev> <arch-specific-options>"
|
触发内核崩溃
在捕捉内核被加载进入内存后,如果系统崩溃开关被触发,则系统会自动切换进入捕捉内核。触发系统崩溃的开关有 panic(),die(),die_nmi() 内核函数和 sysrq 触发事件,可以使用其中任意的一个来触发内核崩溃。不过,在让内核崩溃之前,我们还需要做一些安装设置。
Crash 工具的安装设置
Crash 目前的最新的版本是 5.0.0, 你可以从它的官方网站下载最新的版本。下载完成后对其进行解压安装。
|
1
2
3
4
|
# tar -zvxf crash-5.0.0.tar.gz
# cd crash-5.0.0
# ./configure
# make &&make install
|
生成内存转储文件
现在已经设置好 Kdump 和 crash,现在可以使用前面介绍的系统崩溃开关中的任意一个来引发系统崩溃来生成一个内存转储文件,并可以使用 crash 对其进行分析。
首先,触发系统崩溃,这里使用 sysrq 触发事件。
|
1
|
# echo c > /proc/sysrq-trigger
|
紧接着,系统会自动启动捕捉内核。待完全启动进入捕捉内核后,通过以下命令保存内存转储文件。
|
1
|
# cp /proc/vmcore mydumpfile
|
将在当前目录生成一个 mydumpfile 文件。
分析内存转储文件
现在有了一个内存转储文件,接下来使用 crash 对其进行分析
|
1
|
# crash vmlinux mydumpfile
|
这里 vmlinux 是带调试信息的内核。如果一切正常,将会进入到 crash 中,如图 1 所示。
图 1. crash 命令提示符
在该提示符下,可以执行 crash 的内部命令。通过 crash 的内部命令,可以查看寄存器的值、函数的调用堆栈等信息。在图 2 中,显示了执行 bt命令后得到的函数调用的堆栈信息。
图 2. 函数调用堆栈信息
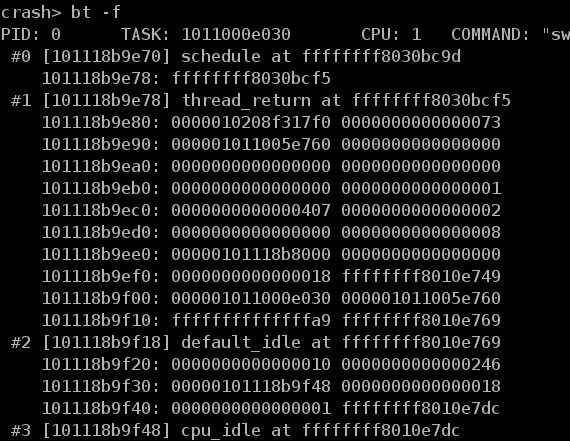
crash 使用 gdb 作为它的内部引擎,crash 中的很多命令和语法都与 gdb 相同。如果你曾经使用过 gdb,就会发现 crash 并不是很陌生。如果想获得 crash 更多的命令和相关命令的详细说明,可以使用 crash 的内部命令 help来获取。
后记
本文介绍了 Linux 下的各种内存转储机制,以及如何 crash 工具开对内存转储文件进行分析。内核虽然复杂,但通过结合使用内核的内存转储文件和 crash 分析工具,可以轻松的找到内核问题的所在。通过对这篇文章的学习,相信你也可以像一个专业的内核开发者那样去追踪和修复内核的错误了。

[转帖]使用 Crash 工具分析 Linux dump 文件的更多相关文章
- 使用Crash工具分析 Linux dump文件【转】
转自:https://blog.csdn.net/bytxl/article/details/45025183 前言 Linux 内核(以下简称内核)是一个不与特定进程相关的功能集合,内核的代码很难轻 ...
- 使用 Crash 工具分析 Linux dump 文件
转自:http://blog.csdn.net/commsea/article/details/11804897 简介: Linux 内核由于其复杂性,使得对内核出现的各种异常的追踪变得异常困难.本文 ...
- 使用jdk自带工具jvisualvm 分析内存dump文件
1.获取dump文件 使用 以下命令 创建 进程PID = 16231的 dump文件,命名为 order.hprof jmap -dump:format=b,file=order.hprof 162 ...
- Linux gdb分析core dump文件
文章目录1. coredump1.1 coredump简介1.2 coredump的文件存储路径1.3 coredump产生的条件1.4 coredump产生原因2. 测试生成coredump1. c ...
- Unix 用gdb分析core dump文件
产生core文件条件 用ulimit -c 指定core文件大小来开启core文件的生成,如:ulimit -c unlimited 用gdb分析core文件的条件 可执行程序在编译时,需加入-g参数 ...
- 【linux】linux下对java程序生成dump文件,并使用IBM Heap Analyzer进行分析,查找定位内存泄漏的问题代码
1.首先,java程序启动在linux,怎么生成dump文件? 1>第一步,首先你需要得到java程序的PID,最简单的方法使用如下命令 ps -ef|grep java 或者如果是docker ...
- Crash工具实战-变量解析【转】
转自:http://blog.chinaunix.net/uid-14528823-id-4358785.html Crash工具实战-变量解析 Crash工具用于解析Vmcore文件,Vmcore文 ...
- 蓝屏 Dump文件分析方法
WinDbg使用有点麻烦,还要符号表什么的.试了下,感觉显示很乱,分析的也不够全面... 试试其他的吧!今天电脑蓝屏了,就使用其dump文件测试,如下: 1.首先,最详细的,要属Osr Online这 ...
- <实战> 通过分析Heap Dump 来了解 Memory Leak ,Retained Heap,Shallow Heap
引入: 最近在和别的团队的技术人员聊天,发现很多人对于堆的基本知识都不太熟悉,所以他们不能很好的检测出memory leak问题,这里就用一个专题来讲解如何通过分析heap dump文件来查找memo ...
- 本地模拟内存溢出并分析Dump文件
java Dump文件分析 前言 dump文件是java虚拟机内存在某一时间点的快照文件,一般是.hprof文件,下面自己模拟一下本地内存溢出,生成dump文件,然后通过mat工具分析的过程. 配置虚 ...
随机推荐
- DWS轻量化更新黑科技:宽表加工优化
本文分享自华为云社区<GaussDB(DWS)性能调优:宽表加工优化方案>,作者:譡里个檔 . 1. 业务背景 宽表加工性能慢,在Gauss(DWS)中可以使用DWS的轻量化更新的黑科技实 ...
- 加快脑动脉瘤检测,AI来了
摘要:华为云EI创新孵化Lab联合华中科技大学电信学院.华中科技大学同济医学院附属协和医院放射科在放射学领域的国际顶级期刊Radiology(<放射学>)上共同发表了最新研究成果. 日前, ...
- 云小课|聊一聊DRS的数据过滤特性
[本期推荐专题]在DevOps市场中,华为云DevCloud拔得头筹,看它如何助力企业面对商业环境瞬息万变快速响应. [摘要] 目前,DRS已支持其他云.本地IDC.ECS自建MySQL.SQL Se ...
- 支持60+数据传输链路,华为云DRS链路商用大盘点
如今,业务上云已是时代潮流,技术的迅猛发展也使得上云变得愈发轻松起来.但在实际迁移过程中,客户仍会担心以下问题:不同数据库之间能迁吗?迁移前后数据不一致怎么办?可以不停机迁移吗-- 迁移毕竟是项大工程 ...
- 云图说丨应用宕机怎么办?MAS帮您实现业务无缝切换
摘要: 多云高可用服务(Multi-cloud high Availability Service,简称MAS)源自华为消费者多云应用高可用方案,提供从流量入口.数据到应用层的端到端的业务故障切换及容 ...
- 解决MySQL在连接时警告:WARN: Establishing SSL connection without server's identity verificatio
起因: 程序在启动时,连接MySQL数据库,发出警告️: Establishing SSL connection without server's identity verification is n ...
- VS以及C++开发和学习使用注意事项
VS以及C++开发使用注意事项 在vs2013版本开始出现安全检查 最好提前禁用错误4996 制表符问题:Visual Studio中设置Tab键对应空格数的方如下:依次选择:工具-〉选项 -〉文本编 ...
- <vue 组件 1、组件化基本使用>
代码结构 组件就是将复杂的功能拆分成简单的块,拆分后的块可以被多处使用. 组件的使用分成三个步骤: 1.创建组件构造器 Vue.extend() 2.注册组件 Vu ...
- vue学习笔记 十、状态管理基础结构
系列导航 vue学习笔记 一.环境搭建 vue学习笔记 二.环境搭建+项目创建 vue学习笔记 三.文件和目录结构 vue学习笔记 四.定义组件(组件基本结构) vue学习笔记 五.创建子组件实例 v ...
- element-plus-admin学习笔记
https://toscode.gitee.com/hsiangleev/element-plus-admin