[转帖]ElasticSearch 最全详细使用教程
https://zhuanlan.zhihu.com/p/449555826?utm_source=weibo&utm_medium=social&utm_oi=27124941455360&utm_content=snapshot
导读:本文介绍了ElasticSearch的必备知识:从入门、索引管理到映射详解。
一、快速入门1. 查看集群的健康状况
http://localhost:9200/_cat

http://localhost:9200/_cat/health?v

说明:v是用来要求在结果中返回表头
状态值说明
Green - everything is good (cluster is fully functional),即最佳状态
Yellow - all data is available but some replicas are not yet allocated (cluster is fully functional),即数据和集群可用,但是集群的备份有的是坏的
Red - some data is not available for whatever reason (cluster is partially functional),即数据和集群都不可用
查看集群的节点
http://localhost:9200/_cat/?v

2. 查看所有索引
http://localhost:9200/_cat/indices?v

3. 创建一个索引
创建一个名为 customer 的索引。pretty要求返回一个漂亮的json 结果
PUT /customer?pretty

再查看一下所有索引
http://localhost:9200/_cat/indices?v

GET /_cat/indices?v

4. 索引一个文档到customer索引中
curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe"}' 5. 从customer索引中获取指定id的文档
curl -X GET "localhost:9200/customer/_doc/1?pretty" 6. 查询所有文档
GET /customer/_search?q=*&sort=name:asc&pretty JSON格式方式
GET /customer/_search{ "query": { "match_all": {} }, "sort": [ {"name": "asc" } ]} 二、索引管理

1. 创建索引
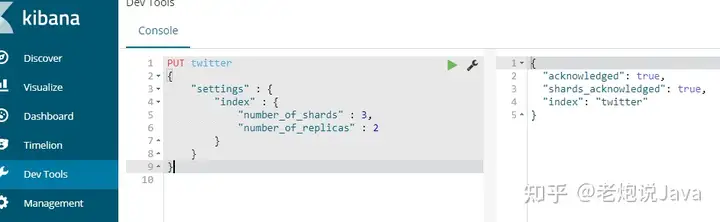
创建一个名为twitter的索引,设置索引的分片数为3,备份数为2。
注意:在ES中创建一个索引类似于在数据库中建立一个数据库(ES6.0之后类似于创建一个表)
PUT twitter{ "settings" : { "index" : { "number_of_shards" : 3, "number_of_replicas" : 2 } }} 说明:
默认的分片数是5到1024
默认的备份数是1
索引的名称必须是小写的,不可重名
创建结果:
创建的命令还可以简写为
PUT twitter{ "settings" : { "number_of_shards" : 3, "number_of_replicas" : 2 }} 2. 创建mapping映射
注意:在ES中创建一个mapping映射类似于在数据库中定义表结构,即表里面有哪些字段、字段是什么类型、字段的默认值等;也类似于solr里面的模式schema的定义
PUT twitter{ "settings" : { "index" : { "number_of_shards" : 3, "number_of_replicas" : 2 } }, "mappings" : { "type1" : { "properties" : { "field1" : { "type" : "text" } } } }} 3. 创建索引时加入别名定义
PUT twitter{ "aliases" : { "alias_1" : {}, "alias_2" : { "filter" : { "term" : {"user" : "kimchy" } }, "routing" : "kimchy" } }} 4. 创建索引时返回的结果说明

5. Get Index 查看索引的定义信息
GET /twitter,可以一次获取多个索引(以逗号间隔) 获取所有索引 _all 或 用通配符*

GET /twitter/_settings

GET /twitter/_mapping

6. 删除索引
DELETE /twitter
说明:
可以一次删除多个索引(以逗号间隔) 删除所有索引 _all 或 通配符 *
7. 判断索引是否存在
HEAD twitter

HTTP status code 表示结果 404 不存在 , 200 存在
8. 修改索引的settings信息
索引的设置信息分为静态信息和动态信息两部分。静态信息不可更改,如索引的分片数。动态信息可以修改。
REST 访问端点:
/_settings 更新所有索引的。
{index}/_settings 更新一个或多个索引的settings。
详细的设置项请参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html#index-modules-settings
9. 修改备份数
PUT /twitter/_settings10. 设置回默认值,用null
PUT /twitter/_settings11. 设置索引的读写
index.blocks.read_only:设为true,则索引以及索引的元数据只可读12. 索引模板
在创建索引时,为每个索引写定义信息可能是一件繁琐的事情,ES提供了索引模板功能,让你可以定义一个索引模板,模板中定义好settings、mapping、以及一个模式定义来匹配创建的索引。
注意:模板只在索引创建时被参考,修改模板不会影响已创建的索引
12.1 新增/修改名为tempae_1的模板,匹配名称为te* 或 bar*的索引创建:
PUT _template/template_112.2 查看索引模板
GET /_template/template_112.3 删除模板
DELETE /_template/template_113. Open/Close Index 打开/关闭索引
POST /my_index/_close说明:
关闭的索引不能进行读写操作,几乎不占集群开销。
关闭的索引可以打开,打开走的是正常的恢复流程。
14. Shrink Index 收缩索引
索引的分片数是不可更改的,如要减少分片数可以通过收缩方式收缩为一个新的索引。新索引的分片数必须是原分片数的因子值,如原分片数是8,则新索引的分片数可以为4、2、1 。
什么时候需要收缩索引呢?
最初创建索引的时候分片数设置得太大,后面发现用不了那么多分片,这个时候就需要收缩了
收缩的流程:
先把所有主分片都转移到一台主机上;
在这台主机上创建一个新索引,分片数较小,其他设置和原索引一致;
把原索引的所有分片,复制(或硬链接)到新索引的目录下;
对新索引进行打开操作恢复分片数据;
(可选)重新把新索引的分片均衡到其他节点上。
收缩前的准备工作:
将原索引设置为只读;
将原索引各分片的一个副本重分配到同一个节点上,并且要是健康绿色状态。
PUT /my_source_index/_settings进行收缩:
POST my_source_index/_shrink/my_target_index监控收缩过程:
GET _cat/recovery?v15. Split Index 拆分索引
当索引的分片容量过大时,可以通过拆分操作将索引拆分为一个倍数分片数的新索引。
能拆分为几倍由创建索引时指定的index.number_of_routing_shards 路由分片数决定。这个路由分片数决定了根据一致性hash路由文档到分片的散列空间。
如index.number_of_routing_shards = 30 ,指定的分片数是5,则可按如下倍数方式进行拆分:
5 → 10 → 30 (split by 2, then by 3)为什么需要拆分索引?
当最初设置的索引的分片数不够用时就需要拆分索引了,和压缩索引相反
注意:只有在创建时指定了index.number_of_routing_shards 的索引才可以进行拆分,ES7开始将不再有这个限制。
和solr的区别是,solr是对一个分片进行拆分,es中是整个索引进行拆分。
拆分步骤:
准备一个索引来做拆分:
PUT my_source_index先设置索引只读:
PUT /my_source_index/_settings做拆分:
POST my_source_index/_split/my_target_index监控拆分过程:
GET _cat/recovery?v16. Rollover Index 别名滚动指向新创建的索引
对于有时效性的索引数据,如日志,过一定时间后,老的索引数据就没有用了。
我们可以像数据库中根据时间创建表来存放不同时段的数据一样,在ES中也可用建多个索引的方式来分开存放不同时段的数据。
比数据库中更方便的是ES中可以通过别名滚动指向最新的索引的方式,让你通过别名来操作时总是操作的最新的索引。
ES的rollover index API 让我们可以根据满足指定的条件(时间、文档数量、索引大小)创建新的索引,并把别名滚动指向新的索引。
注意:这时的别名只能是一个索引的别名。
Rollover Index 示例:
创建一个名字为logs-0000001 、别名为logs_write 的索引:
PUT /logs-000001添加1000个文档到索引logs-000001,然后设置别名滚动的条件
POST /logs_write/_rollover说明:
如果别名logs_write指向的索引是7天前(含)创建的或索引的文档数>=1000或索引的大小>= 5gb,则会创建一个新索引 logs-000002,并把别名logs_writer指向新创建的logs-000002索引
Rollover Index 新建索引的命名规则:
如果索引的名称是-数字结尾,如logs-000001,则新建索引的名称也会是这个模式,数值增1。
如果索引的名称不是-数值结尾,则在请求rollover api时需指定新索引的名称
POST /my_alias/_rollover/my_new_index_name在名称中使用Date math(时间表达式)
如果你希望生成的索引名称中带有日期,如logstash-2016.02.03-1 ,则可以在创建索引时采用时间表达式来命名:
# PUT /<logs-{now/d}-1> with URI encoding:Rollover时可对新的索引作定义:
PUT /logs-000001Dry run 实际操作前先测试是否达到条件:
POST /logs_write/_rollover?dry_run说明:
测试不会创建索引,只是检测条件是否满足
注意:rollover是你请求它才会进行操作,并不是自动在后台进行的。你可以周期性地去请求它。
17. 索引监控
17.1 查看索引状态信息
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-stats.html
查看所有的索引状态:
GET /_stats
查看指定索引的状态信息:
GET /index1,index2/_stats
17.2 查看索引段信息
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-segments.html
GET /test/_segments 17.3 查看索引恢复信息
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-recovery.html
GET index1,index2/_recovery?human
GET /_recovery?human
17.4 查看索引分片的存储信息
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-shards-stores.html
# return information of>GET /test/_shard_stores18. 索引状态管理
18.1 Clear Cache 清理缓存
POST /twitter/_cache/clear
默认会清理所有缓存,可指定清理query, fielddata or request 缓存
POST /kimchy,elasticsearch/_cache/clear18.2 Refresh,重新打开读取索引
POST /kimchy,elasticsearch/_refresh18.3 Flush,将缓存在内存中的索引数据刷新到持久存储中
POST twitter/_flush18.4 Force merge 强制段合并
POST /kimchy/_forcemerge?only_expunge_deletes=false&max_num_segments=100&flush=true可选参数说明:
max_num_segments 合并为几个段,默认1
only_expunge_deletes 是否只合并含有删除文档的段,默认false
flush 合并后是否刷新,默认true
POST /kimchy,elasticsearch/_forcemerge三、映射详解
1. Mapping 映射是什么
映射定义索引中有什么字段、字段的类型等结构信息。相当于数据库中表结构定义,或 solr中的schema。因为lucene索引文档时需要知道该如何来索引存储文档的字段。
ES中支持手动定义映射,动态映射两种方式。
1.1. 为索引创建mapping
PUT test说明:映射定义后续可以修改
2. 映射类别 Mapping type 废除说明
ES最先的设计是用索引类比关系型数据库的数据库,用mapping type 来类比表,一个索引中可以包含多个映射类别。这个类比存在一个严重的问题,就是当多个mapping type中存在同名字段时(特别是同名字段还是不同类型的),在一个索引中不好处理,因为搜索引擎中只有 索引-文档的结构,不同映射类别的数据都是一个一个的文档(只是包含的字段不一样而已)
从6.0.0开始限定仅包含一个映射类别定义( "index.mapping.single_type": true ),兼容5.x中的多映射类别。从7.0开始将移除映射类别。
为了与未来的规划匹配,请现在将这个唯一的映射类别名定义为“_doc”,因为索引的请求地址将规范为:PUT {index}/_doc/{id} and POST {index}/_doc
Mapping 映射示例:
PUT twitter多映射类别数据转储到独立的索引中:
ES 提供了reindex API 来做这个事

3. 字段类型 datatypes
字段类型定义了该如何索引存储字段值。ES中提供了丰富的字段类型定义,请查看官网链接详细了解每种类型的特点:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
3.1 Core Datatypes 核心类型
string3.2 Complex datatypes 复合类型
Array datatype3.3 Geo datatypes 地理数据类型
Geo-point datatype3.4 Specialised datatypes 特别的类型
IP datatype4. 字段定义属性介绍
字段的type (Datatype)定义了如何索引存储字段值,还有一些属性可以让我们根据需要来覆盖默认的值或进行特别定义。
请参考官网介绍详细了解:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
analyzer 指定分词器字段定义属性—示例
PUT my_index5. Multi Field 多重字段
当我们需要对一个字段进行多种不同方式的索引时,可以使用fields多重字段定义。如一个字符串字段即需要进行text分词索引,也需要进行keyword 关键字索引来支持排序、聚合;或需要用不同的分词器进行分词索引。
示例:
定义多重字段:
说明:raw是一个多重版本名(自定义)
PUT my_index往多重字段里面添加文档
PUT my_index/_doc/1获取多重字段的值:
GET my_index/_search6. 元字段
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-fields.html
元字段是ES中定义的文档字段,有以下几类:

7. 动态映射
动态映射:ES中提供的重要特性,让我们可以快速使用ES,而不需要先创建索引、定义映射。如我们直接向ES提交文档进行索引:
PUT data/_doc/1ES将自动为我们创建data索引、_doc 映射、类型为 long 的字段 count
索引文档时,当有新字段时, ES将根据我们字段的json的数据类型为我们自动加人字段定义到mapping中。
7.1 字段动态映射规则

7.2 Date detection 时间侦测
所谓时间侦测是指我们往ES里面插入数据的时候会去自动检测我们的数据是不是日期格式的,是的话就会给我们自动转为设置的格式
date_detection 默认是开启的,默认的格式dynamic_date_formats为:
[ "strict_date_optional_time","yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"]自定义时间格式:
PUT my_index禁用时间侦测:
PUT my_index7.3 Numeric detection 数值侦测
开启数值侦测(默认是禁用的)
PUT my_index[转帖]ElasticSearch 最全详细使用教程的更多相关文章
- elasticsearch最全详细使用教程:搜索详解
一.搜索API 1. 搜索API 端点地址从索引tweet里面搜索字段user为kimchy的记录 GET /twitter/_search?q=user:kimchy从索引tweet,user里面搜 ...
- elasticsearch最全详细使用教程:入门、索引管理、映射详解、索引别名、分词器、文档管理、路由、搜索详解
一.快速入门1. 查看集群的健康状况http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 状 ...
- Linux环境CentOS6.9安装配置Elasticsearch6.2.2最全详细教程
Linux环境CentOS6.9安装配置Elasticsearch6.2.2最全详细教程 前言 第一步:下载Elasticsearch6.2.2 第二步:创建应用程序目录 第四步:创建Elastics ...
- StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程)
@ 目录 StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程) 一.下载ELK的安装包上传并解压 1.Elasticsearch下载 2.Logstash下载 3.Kibana ...
- Myeclipse详细使用教程
Myeclipse详细使用教程.. /*+Shift+Enter(生成多行注释) /**+Shift+Enter(生成文档注释)-----------------问题:在编辑jsp的时候,如果光标移动 ...
- rsync for windows 详细使用教程
rsync for windows 详细使用教程内容简介:rsync在windows与windows服务器之间的同步设置 1.准备两台机器: server-----192.168.0.201 clie ...
- Vue2.0史上最全入坑教程(下)—— 实战案例
书接上文 前言:经过前两节的学习,我们已经可以创建一个vue工程了.下面我们将一起来学习制作一个简单的实战案例. 说明:默认我们已经用vue-cli(vue脚手架或称前端自动化构建工具)创建好项目了 ...
- Kibana详细入门教程
Kibana详细入门教程 目录 一.Kibana是什么 二.如何安装 三.如何加载自定义索引 四.如何搜索数据 五.如何切换中文 六.如何使用控制台 七.如何使用可视化 八.如何使用仪表盘 一.K ...
- gulp详细入门教程
本文链接:http://www.ydcss.com/archives/18 gulp详细入门教程 简介: gulp是前端开发过程中对代码进行构建的工具,是自动化项目的构建利器:她不仅能对网站资源进行优 ...
- 在虚拟机中安装红旗桌面7.0 Linux操作系统的详细图文教程
本文作者:souvc 本文出处:http://www.cnblogs.com/liuhongfeng/p/5343087.html 以下是详细的内容: 一.安装虚拟机. 安装虚拟机可以参考:在Wind ...
随机推荐
- Spring Cloud 学习推荐
学习 Spring Boot Spring tutorials | Java Web Development, Spring Cloud Programming tutorials Spring Bo ...
- 【小白学YOLO】一文带你学YOLOv1 Testing
摘要:本文将为初学者带详细分析如何进行YOLOv1 Testing的内容. YOLOv1 Testing 进入testing阶段,我们已经得到98个bounding box和confidence还有C ...
- 实时入库不用愁,HStore帮分忧
本文分享自华为云社区<直播回顾 | 实时入库不用愁,HStore帮分忧>,作者:汀丶. 海量数据时代,如何实现数据实时入库与实时查询?GaussDB(DWS) HStore表为数据高效存储 ...
- Nacos是什么?
摘要:Nacos是 Dynamic Naming and Configuration Service的首字母简称,相较之下,它更易于构建云原生应用的动态服务发现.配置管理和服务管理平台. 本文分享自华 ...
- 认识一下MRS里的“中间人”Alluxio
摘要:Alluxio在mrs的数据处理生态中处于计算和存储之间,为上层spark.presto.mapredue.hive计算框架提供了数据抽象层,计算框架可以通过统一的客户端api和全局命名空间访问 ...
- web messaging与Woker分类:漫谈postMessage跨线程跨页面通信
web messaging 跨文档通信(cross-document messaging):跨就是我们国内更为熟知的HTML5 window.postMessage()应用的那种通信: 通道通信(ch ...
- 字节跳动基于DataLeap的DataOps实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 本文根据 ArchSummit 全球架构师峰会(深圳站)来自抖音数据研发负责人王洋的现场分享实录整理而成(有删减) ...
- Could not autowire. No beans of 'RestTemplate' type found.
解决方案 @Resourceprivate RestTemplate restTemplate;
- CompletableFuture 使用
Future的局限性,它没法直接对多个任务进行链式.组合等处理,而CompletableFuture是对Future的扩展和增强.CompletableFuture实现了Future接口,并在此基础上 ...
- 语音顶会 ICASSP 2022 成果分享:基于时频感知域模型的单通道语音增强算法
近日,阿里云视频云音频技术团队与新加坡国立大学李海洲教授团队合作论文 <基于时频感知域模型的单通道语音增强算法 >(Time-Frequency Attention for Monaura ...