VAE--就是AutoEncoder的编码输出服从正态分布
花式解释AutoEncoder与VAE
什么是自动编码器
自动编码器(AutoEncoder)最开始作为一种数据的压缩方法,其特点有:
1)跟数据相关程度很高,这意味着自动编码器只能压缩与训练数据相似的数据,这个其实比较显然,因为使用神经网络提取的特征一般是高度相关于原始的训练集,使用人脸训练出来的自动编码器在压缩自然界动物的图片是表现就会比较差,因为它只学习到了人脸的特征,而没有能够学习到自然界图片的特征;
2)压缩后数据是有损的,这是因为在降维的过程中不可避免的要丢失掉信息;
到了2012年,人们发现在卷积网络中使用自动编码器做逐层预训练可以训练更加深层的网络,但是很快人们发现良好的初始化策略要比费劲的逐层预训练有效地多,2014年出现的Batch Normalization技术也是的更深的网络能够被被有效训练,到了15年底,通过残差(ResNet)我们基本可以训练任意深度的神经网络。
所以现在自动编码器主要应用有两个方面,第一是数据去噪,第二是进行可视化降维。然而自动编码器还有着一个功能就是生成数据。
我们之前讲过GAN,它与GAN相比有着一些好处,同时也有着一些缺点。我们先来讲讲其跟GAN相比有着哪些优点。
第一点,我们使用GAN来生成图片有个很不好的缺点就是我们生成图片使用的随机高斯噪声,这意味着我们并不能生成任意我们指定类型的图片,也就是说我们没办法决定使用哪种随机噪声能够产生我们想要的图片,除非我们能够把初始分布全部试一遍。但是使用自动编码器我们就能够通过输出图片的编码过程得到这种类型图片的编码之后的分布,相当于我们是知道每种图片对应的噪声分布,我们就能够通过选择特定的噪声来生成我们想要生成的图片。
第二点,这既是生成网络的优点同时又有着一定的局限性,这就是生成网络通过对抗过程来区分“真”的图片和“假”的图片,然而这样得到的图片只是尽可能像真的,但是这并不能保证图片的内容是我们想要的,换句话说,有可能生成网络尽可能的去生成一些背景图案使得其尽可能真,但是里面没有实际的物体。
自动编码器的结构
首先我们给出自动编码器的一般结构
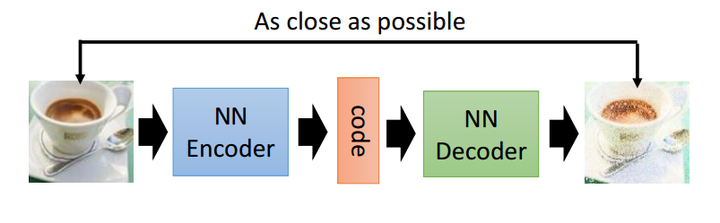
从上面的图中,我们能够看到两个部分,第一个部分是编码器(Encoder),第二个部分是解码器(Decoder),编码器和解码器都可以是任意的模型,通常我们使用神经网络模型作为编码器和解码器。输入的数据经过神经网络降维到一个编码(code),接着又通过另外一个神经网络去解码得到一个与输入原数据一模一样的生成数据,然后通过去比较这两个数据,最小化他们之间的差异来训练这个网络中编码器和解码器的参数。当这个过程训练完之后,我们可以拿出这个解码器,随机传入一个编码(code),希望通过解码器能够生成一个和原数据差不多的数据,上面这种图这个例子就是希望能够生成一张差不多的图片。
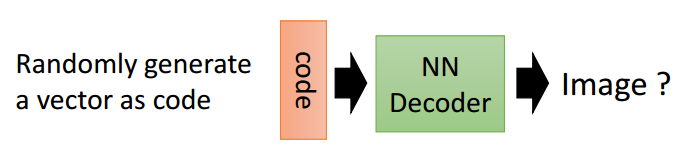
这件事情能不能实现呢?其实是可以的,下面我们会用PyTorch来简单的实现一个自动编码器。
首先我们构建一个简单的多层感知器来实现一下。
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
这里我们定义了一个简单的4层网络作为编码器,中间使用ReLU激活函数,最后输出的维度是3维的,定义的解码器,输入三维的编码,输出一个28x28的图像数据,特别要注意最后使用的激活函数是Tanh,这个激活函数能够将最后的输出转换到-1 ~1之间,这是因为我们输入的图片已经变换到了-1~1之间了,这里的输出必须和其对应。
训练过程也比较简单,我们使用最小均方误差来作为损失函数,比较生成的图片与原始图片的每个像素点的差异。
同时我们也可以将多层感知器换成卷积神经网络,这样对图片的特征提取有着更好的效果。
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # b, 16, 5, 5
nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # b, 8, 2, 2
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
这里使用了nn.ConvTranspose2d(),这可以看作是卷积的反操作,可以在某种意义上看作是反卷积。
我们使用卷积网络得到的最后生成的图片效果会更好,具体的图片效果我就不再这里放了,可以在我们的github上看到图片的展示。
变分自动编码器(Variational Autoencoder)
变分编码器是自动编码器的升级版本,其结构跟自动编码器是类似的,也由编码器和解码器构成。
回忆一下我们在自动编码器中所做的事,我们需要输入一张图片,然后将一张图片编码之后得到一个隐含向量,这比我们随机取一个随机噪声更好,因为这包含着原图片的信息,然后我们隐含向量解码得到与原图片对应的照片。
但是这样我们其实并不能任意生成图片,因为我们没有办法自己去构造隐藏向量,我们需要通过一张图片输入编码我们才知道得到的隐含向量是什么,这时我们就可以通过变分自动编码器来解决这个问题。
其实原理特别简单,只需要在编码过程给它增加一些限制,迫使其生成的隐含向量能够粗略的遵循一个标准正态分布,这就是其与一般的自动编码器最大的不同。
这样我们生成一张新图片就很简单了,我们只需要给它一个标准正态分布的随机隐含向量,这样通过解码器就能够生成我们想要的图片,而不需要给它一张原始图片先编码。
在实际情况中,我们需要在模型的准确率上与隐含向量服从标准正态分布之间做一个权衡,所谓模型的准确率就是指解码器生成的图片与原图片的相似程度。我们可以让网络自己来做这个决定,非常简单,我们只需要将这两者都做一个loss,然后在将他们求和作为总的loss,这样网络就能够自己选择如何才能够使得这个总的loss下降。另外我们要衡量两种分布的相似程度,如何看过之前一片GAN的数学推导,你就知道会有一个东西叫KL divergence来衡量两种分布的相似程度,这里我们就是用KL divergence来表示隐含向量与标准正态分布之间差异的loss,另外一个loss仍然使用生成图片与原图片的均方误差来表示。
我们可以给出KL divergence 的公式
这里变分编码器使用了一个技巧“重新参数化”来解决KL divergence的计算问题。
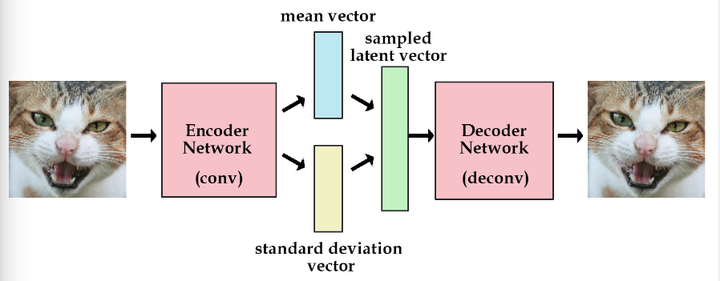
这时不再是每次产生一个隐含向量,而是生成两个向量,一个表示均值,一个表示标准差,然后通过这两个统计量来合成隐含向量,这也非常简单,用一个标准正态分布先乘上标准差再加上均值就行了,这里我们默认编码之后的隐含向量是服从一个正态分布的。这个时候我们是想让均值尽可能接近0,标准差尽可能接近1。而论文里面有详细的推导如何得到这个loss的计算公式,有兴趣的同学可以去看看推导
下面是PyTorch的实现
reconstruction_function = nn.BCELoss(size_average=False) # mse loss
def loss_function(recon_x, x, mu, logvar):
"""
recon_x: generating images
x: origin images
mu: latent mean
logvar: latent log variance
"""
BCE = reconstruction_function(recon_x, x)
# loss = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
KLD = torch.sum(KLD_element).mul_(-0.5)
# KL divergence
return BCE + KLD
另外变分编码器除了可以让我们随机生成隐含变量,还能够提高网络的泛化能力。
最后是VAE的代码实现
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparametrize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
if torch.cuda.is_available():
eps = torch.cuda.FloatTensor(std.size()).normal_()
else:
eps = torch.FloatTensor(std.size()).normal_()
eps = Variable(eps)
return eps.mul(std).add_(mu)
def decode(self, z):
h3 = F.relu(self.fc3(z))
return F.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparametrize(mu, logvar)
return self.decode(z), mu, logvar
VAE的结果比普通的自动编码器要好很多,下面是结果


VAE的缺点也很明显,他是直接计算生成图片和原始图片的均方误差而不是像GAN那样去对抗来学习,这就使得生成的图片会有点模糊。现在已经有一些工作是将VAE和GAN结合起来,使用VAE的结构,但是使用对抗网络来进行训练,具体可以参考一下这篇论文。
参考内容: kvfrans blog
本文代码已经上传到了github上
VAE--就是AutoEncoder的编码输出服从正态分布的更多相关文章
- VAE (variational autoencoder)
https://www.zhihu.com/question/41490383/answer/103006793 自编码是一种表示学习的技术,是deep learning的核心问题 让输入等于输出,取 ...
- Keras(六)Autoencoder 自编码 原理及实例 Save&reload 模型的保存和提取
Autoencoder 自编码 压缩与解压 原来有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 所 ...
- 如何用minitab检测一组数据是否服从正态分布
打开Minitab之后 点击Stat>Basic Statistics> Normality Test 分析之后若 P value(P值)>0.05,说明此组数据服从正态分布
- 使用K-S检验一个数列是否服从正态分布、两个数列是否服从相同的分布
假设检验的基本思想: 若对总体的某个假设是真实的,那么不利于或者不能支持这一假设的事件A在一次试验中是几乎不可能发生的.如果事件A真的发生了,则有理由怀疑这一假设的真实性,从而拒绝该假设. 实质分析: ...
- Javascript 随机数函数 学习之二:产生服从正态分布随机数
一.为什么需要服从正态分布的随机函数 一般我们经常使用的随机数函数 Math.random() 产生的是服从均匀分布的随机数,能够模拟等概率出现的情况,例如 扔一个骰子,1到6点的概率应该相等,但现实 ...
- 样本服从正态分布,证明样本容量n乘样本方差与总体方差之比服从卡方分布x^2(n)
样本服从正态分布,证明样本容量n乘样本方差与总体方差之比服从卡方分布x^2(n) 正态分布的n阶中心矩参见: http://www.doc88.com/p-334742692198.html
- 用Keras搭建神经网络 简单模版(六)——Autoencoder 自编码
import numpy as np np.random.seed(1337) from keras.datasets import mnist from keras.models import Mo ...
- VAE(Variational Autoencoder)的原理
Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint ar ...
- JavaScript模板引擎artTemplate.js——是否编码输出html字符
template.config(name, value)方法用于更改引擎的默认配置. 其中字段escape,类型为boolean,默认为true. 首先,我们不修改配置信息输出一段带有html标签的字 ...
随机推荐
- Nginx正向代理配置
服务器端: server { resolver 8.8.8.8; resolver_timeout 5s; listen 0.0.0.0:8888; access_log /usr/local/ngi ...
- sql server学习路径地址
联机丛书2005:https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2005/ms130214(v=sql.90) 联 ...
- Linux安装rpm包时报错Header V3 DSA/SHA1 Signature, key ID 1d1e034b: NOKEY解决办法
这是因为yum安装了旧版本的GPG key造成的,解决办法: rpm --import /etc/pki/rpm-gpg/RPM* Header V3 DSA/SHA1 Signature, key ...
- What do you think the coming adidas NMD Singapore
adidas NMD Singapore is surprising everybody with a lot of completely new NMD choices combined with ...
- HIVE: 自定义TextInputFormat (旧版MapReduceAPI ok, 新版MapReduceAPI实现有BUG?)
我们的输入文件 hello0, 内容如下: xiaowang 28 shanghai@_@zhangsan 38 beijing@_@someone 100 unknown 逻辑上有3条记录, 它们以 ...
- SQL学习笔记四(补充-2)之MySQL多表查询
阅读目录 一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习 一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 准备表 #建表 create table depart ...
- 20145326 《Java程序设计》第4周学习总结
20145326 <Java程序设计>第4周学习总结 教材学习内容总结 第六章 一.何谓继承 1.继承共同行为 面向对象中,子类继承父类,避免重复的行为定义.不过并非为了避免重复定义行为就 ...
- pytorch 从入门到实战
一.安装 按照 http://pytorch.org 官网上的说明来做,遇到了几个坑.记录如下: 1.用 conda 安装 pytorch 时,下载安装包非常慢,无法忍受. 解决办法:用蓝灯FQ,将蓝 ...
- 使用Python登陆QQ邮箱发送垃圾邮件 简单实现
参考:Python爱好者 知乎文章 需要做的是: 1.邮箱开启SMTP功能 2.获取授权码 上述两步百度都有. 源码: #!/usr/bin/env python from email.mime.te ...
- Notepad++ 管理工程--转载
http://blog.csdn.net/cashey1991/article/details/7001385 @1.首先从下面这个菜单打开工程panel @2.在工程panel的“Workspace ...