Hive之GROUP BY详解
一,GROUP BY 执行理解
先来看下表1,表名为test:
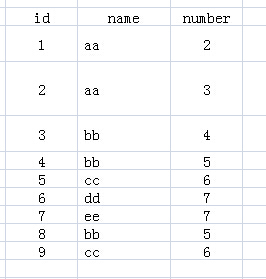
表1
执行如下SQL语句:
SELECT name from test GROUP BY name ;
你应该很容易知道运行的结果,没错,就是下表2:

表2
可是为了能够更好的理解“group by”多个列“和”聚合函数“的应用,我建议在思考的过程中,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
1.FROM test:该句执行后,应该结果和表1一样,就是原来的表。
2.FROM test Group BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面。
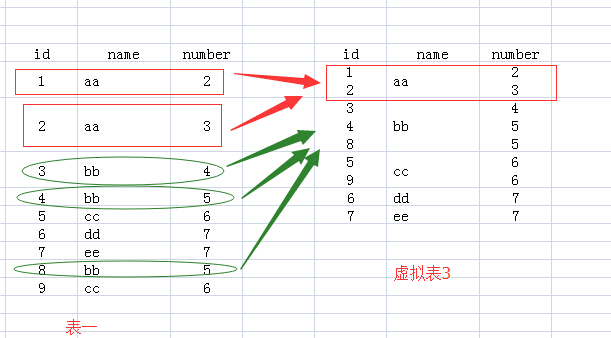
3.接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以你看,执行select * 语句就报错了。
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和number里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如cout(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
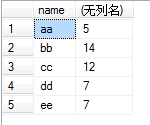
(4)例如我们执行select name,sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3,返回5,最后执行结果如下:
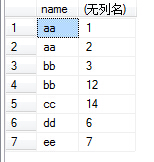
(5)group by 多个字段该怎么理解呢:如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。如下图
(6)接下来就可以配合select和聚合函数进行操作了。如执行select name,sum(id) from test group by name,number,结果如下图:
二 ,GROUP BY 与 DISTINCT 去重比较
GROUP BY 与 DISTINCT都有去重的功能,具体例子如下:

SELECT aa from zhangtest WHERE aa is not NULL GROUP BY aa ;

如果在select 中加入其它字段 ,而在GROUP BY中没有,则会报错,如下。

select col1,col2,count(1),sel_expr(聚合操作)
from tableName
where condition
group by col1,col2
having...
注意:
(1):select后面的非聚合列必须出现在group by中(如上面的col1和col2)。
(2):除了普通列就是一些聚合操作。
group的特性:
(1):使用了reduce操作,受限于reduce数量,通过参数mapred.reduce.tasks设置reduce个数。
(2):输出文件个数与reduce数量相同,文件大小与reduce处理的数量有关。
问题:
(1):网络负载过重。
(2):出现数据倾斜(我们可以通过hive.groupby.skewindata参数来优化数据倾斜的问题)。
下面,看下hive group by distinct区别以及性能比较
有兴趣的可以看下这篇博文,讲解的比较清楚。
https://blog.csdn.net/xiaoshunzi111/article/details/68484426
结论:能用GROUP BY 的 不用 DISTINCT。
参考:https://blog.csdn.net/lzm1340458776/article/details/43231707
部分转自:https://blog.csdn.net/hao1066821456/article/details/69556644
Hive之GROUP BY详解的更多相关文章
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- Hive 的collect_set使用详解
Hive 的collect_set使用详解 https://blog.csdn.net/liyantianmin/article/details/48262109 对于非group by字段,可以 ...
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列. 本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile. ...
- Hive学习之三 《Hive的表的详解和应用案例详解》
一.Hive的表 Hive的表分为内部表.外部表和分区表. 1.内部表,为托管表. 2.外部表,external. 3.分区表. 详解: 内部表,删除表的时候,数据会跟着删除. 外部表,在删除表的时候 ...
- Hive安装与配置详解
既然是详解,那么我们就不能只知道怎么安装hive了,下面从hive的基本说起,如果你了解了,那么请直接移步安装与配置 hive是什么 hive安装和配置 hive的测试 hive 这里简单说明一下,好 ...
- HUE配置文件hue.ini 的hive和beeswax模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- Hive 3.x 配置&详解
Hive 1. 数据仓库概述 1.1 基本概念 数据仓库(英语:Data Warehouse,简称数仓.DW),是一个用于存储.分析.报告的数据系统. 数据仓库的目的是构建面向分析的集成化数据环境,分 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- HDU 1104 Remainder(BFS 同余定理)
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=1104 在做这道题目一定要对同余定理有足够的了解,所以对这道题目对同余定理进行总结 首先要明白计算机里的 ...
- Currency Exchange---poj1860 ( spfa, 回路,最长路)
题目链接:http://poj.org/problem?id=1860 题解: 两种情况YES,一种是存在正权回路: 一种是求最长路后,实现了增值,也是YES: 用spfa来判断是否存在正权回路,其实 ...
- Web开发者应知的URL编码知识(转)
原文出处: lunatech 译文出处:oschina - 桔子, lwei, 史涛, Khiyuan, super0555, LinuxQueen, 抛出异常的爱 本文首先阐述了人们关于统一资源 ...
- Nginx rewrite 中break与last指令的区别
location /break/ { rewrite ^/break/(.*) /test/$1 break; return 402; } location /last/ { rewrite ^/la ...
- qt——exec()的基本用法
qt中 if(my1.exec()==QDialog::Accepted) 是什么意思 这个先说这个my1.exec()这个就是个等待消息的循环,就是说它在等待你给的命令. 再说这个QDialog:: ...
- centos linux 系统日常管理4 scp,rsync,md5sum,sha1sum,strace ,find Rsync 常见错误及解决方法 第十七节课
centos linux 系统日常管理4 scp,rsync,md5sum,sha1sum,strace ,find Rsync 常见错误及解决方法 第十七节课 rsync可以增量同步,scp不行 ...
- mysql源码编译安装
首先去官网http://dev.mysql.com/downloads/mysql/ 下载mysql源码.我下的是5.7.10 源码选择的是 Generic Linux (Architecture I ...
- TCP三次握手和四次挥手详解
背景描述通过上一篇中网络模型中的IP层的介绍,我们知道网络层,可以实现两个主机之间的通信.但是这并不具体,因为,真正进行通信的实体是在主机中的进程,是一个主机中的一个进程与另外一个主机中的一个进程在交 ...
- cocos代码研究(10)ActionEase子类学习笔记
理论部分 缓动动作的基类,继承自 ActionInterval类.ActionEase本身是一个抽象的概念父类,开发者最好不要在代码中直接创建它的对象,因为它没有具体的执行效果,这一类的子类速度变化大 ...
- 2018-2019 Russia Open High School Programming Contest
A. Company Merging Solved. 温暖的签到. #include<bits/stdc++.h> using namespace std; ; typedef long ...