Deeplearning - Overview of Convolution Neural Network
Finally pass all the Deeplearning.ai courses in March! I highly recommend it!
If you already know the basic then you may be interested in course 4 & 5, which shows many interesting cases in CNN and RNN. Although I do think that 1 & 2 is better structured than others, which give me more insight into NN.
I have uploaded the assignment of all the deep learning courses to my GitHub. You can find the assignment for CNN here. Hopefully it can give you some help when you struggle with the grader. For a new course, you indeed need more patience to fight with the grader. Don't ask me how I know this ... >_<
I have finished the summary of the first course in my pervious post:
I will keep working on the others. Since I am using CNN at work recently, let's go through CNN first. Any feedback is absolutely welcomed! And please correct me if I make any mistake.
When talking about CNN, image application is usually what comes to our mind first. While actually CNN can be more generally applied to different data that fits certain assumption. what assumption? You will know later.
1. CNN Features
CNN stands out from traditional NN in 3 area:
- sparse interaction (connection)
- parameter sharing
- equivariant representation.
Actually the third feature is more like a result of the first 2 features. Let's go through them one by one.
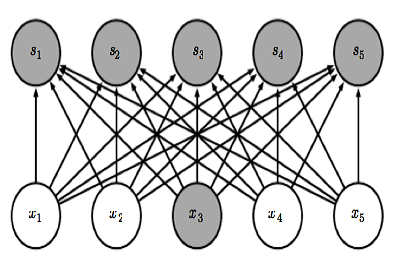
| Fully Connected NN | NN with Sparse connection |
|---|---|
 |
 |
Sparse interaction, unlike fully connected neural network, for Convolution layer each output is only connected to limited inputs like above. For a hidden layer that takes \(m\) neurons as input and \(n\) neurons as output, a fully connected hidden layer has a weight matrix of size \(m*n\) to compute each output. When \(m\) is very big, the weight can be a huge matrix. With sparse connection, only \(k\) input is connected to each output, leading to a decrease in computation scale from \(O(m*n)\) to \(O(k*n)\). And a decrease in memory usage from \(m*n\) to \(k*n\).
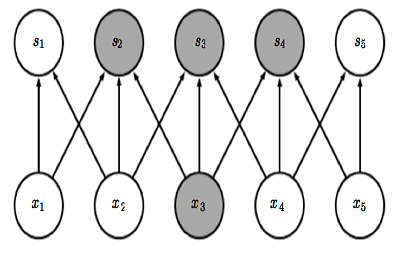
Parameter sharing has more insight when considered together with sparse connection. Because sparse connection creates segmentation among data. For example \(x_1\) \(x_5\) is independent in above plot due to sparse connection. However with parameter sharing, same weight matrix is used across all positions, leading to a hidden connectivity. Additionally, it can further reduces the memory storage of weight matrix from \(k*n\) to \(k\). Especially when dealing with image, from \(m*n\) to \(k\) can be a huge improvement in memory usage.
Equivariant representation is a result of parameter sharing. Because same weight matrix is used at different position across input. So the output is invaritate to parallel movement. Say \(g\) represent parallel shift and \(f\) is the convolution function, then \(f(g(x)) = g(f(x))\). This feature can be very useful when we only care about the presence of feature not their position. But on the other hand this can be a big flaw of CNN that it is not good at detecting position.
2. CNN Components
Given the above 3 features, let's talk about how to implement CNN.
(1).Kernel
Kernel, or so-called filter, is the weight matrix in CNN. It implements element-wise computation across input matrix and output the sum. Kernel usually has a size that is much smaller than the original input so that we can take advantage of decrease in memory.
Below is a 2D input of convolution layer. It can be greyscale image, or multivarate timeseries.
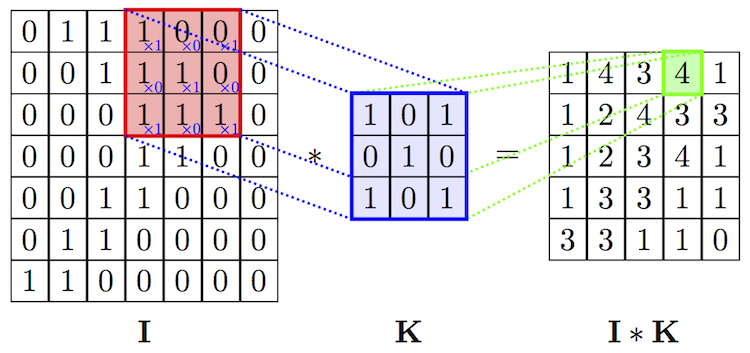
When input is 3D dimension, we call the 3rd dimension Channel(volume). The most common case is the RGB image input, where each channel is a 2D matrix representing one color. See below:
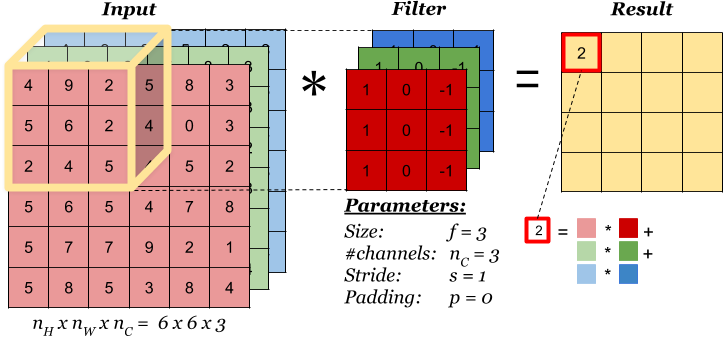
Please keep in mind that Kernel always have same number of channel as input! Therefore it leads to dimension reduction in all dimensions (unless you use 1*1 kernel). But we can have multiple kernels to capture different features. Like below, we have 2 kernels(filters), each has dimension (3,3,3).
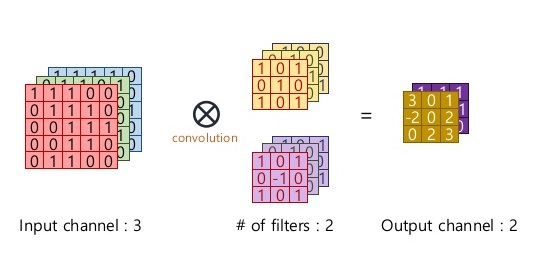
Dimension Cheatsheet of Kernel
- Input Dimension ( n_w, n_h, n_channel ). When n_channel = 1, it is a 2D input.
- Kernel Dimension ( n_k, n_k, n_channel ). Kernel is not always a square, it can be ( n_k1, n_k2, n_channel )
- Output Dimension (n_w - n_k + 1, n_h - n_k + 1, 1 )
- When we have n different kernels, output dimension will be (n_w - n_k + 1, n_h - n_k + 1, n)
(2). Stride
Like we mention before, one key advantage of CNN is to speed up computation using dimension reduction. Can we be more aggressive on this ?! Yes we can use Stride! Basically stride is when moving kernel across input, it skips certain input by certain length.
We can easily tell how stride works by below comparison:
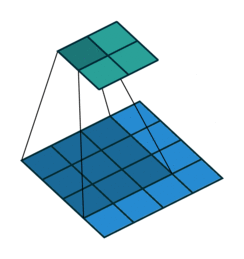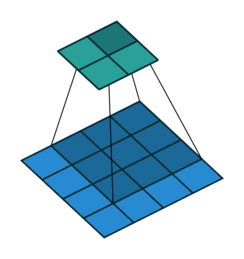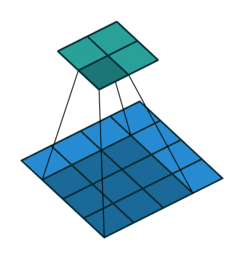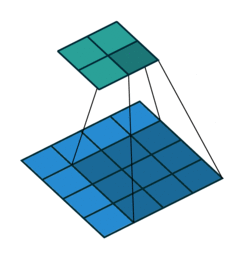 No Stride
No Stride
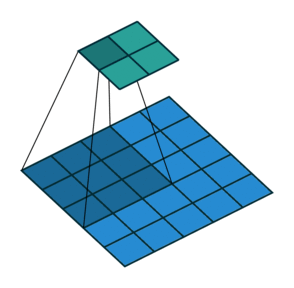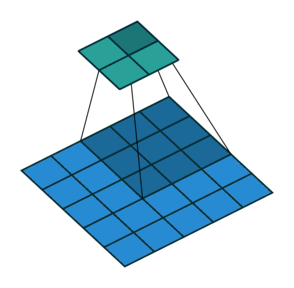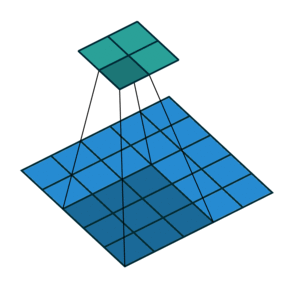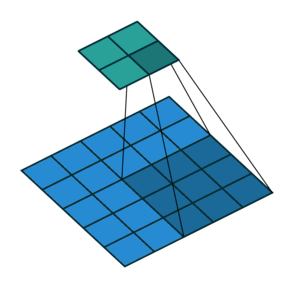 Stride = 1
Stride = 1
Thanks vdumoulin for such great animation. You can find more at his GitHub
Stride can further speed up computation, but it will lose some feature in the output. We can consider it as output down-sampling.
(3). Padding
Both Kernel and Stride function as dimension reduction technic. So for each convolution layer, the output dimension will always be smaller than input. However if we want to build a deep convolution network, we don't want the input size to shrink too fast. A small kernel can partly solve this problem. But in order to maintain certain dimension we need zero padding. Basically it is adding zero to your input, like below:
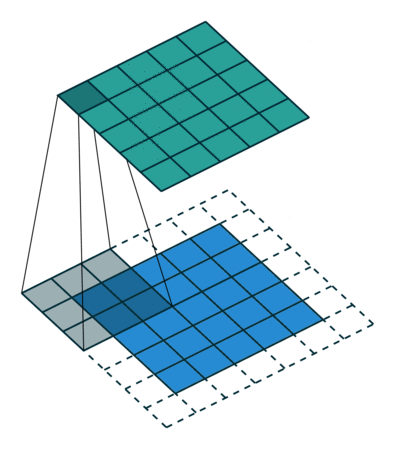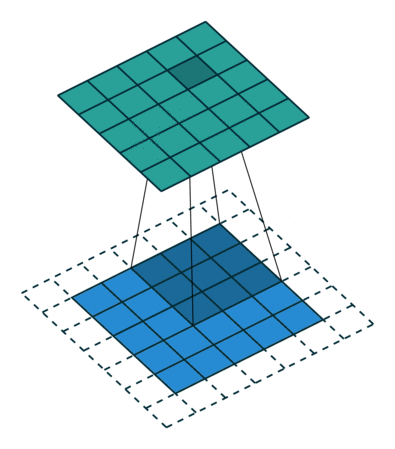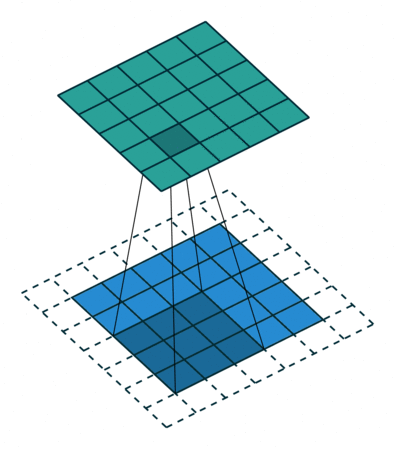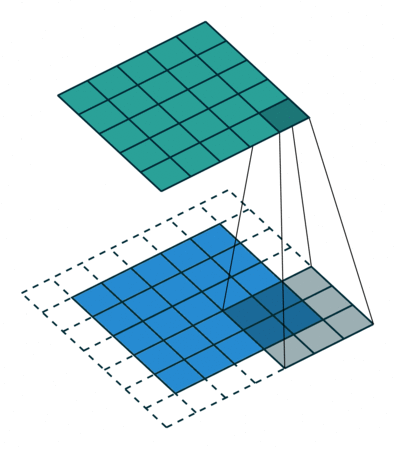 Padding = 1
Padding = 1
There is a few types of padding that are frequently used:
- Valid padding: no padding at all, output = input - (K - 1)
- Same padding: maintain samesize, output = input
- Full padding: each input is visited k times, output = input + (k - 1)
To summarize, We use \(s\) to denote stride, and \(p\) denotes padding. \(n\) is the input size, \(k\) is kernel size (kernel and input are both square for simplicity). Then output dimension will be following:
\[\lfloor (n+2p-k)/s\rfloor +1\]
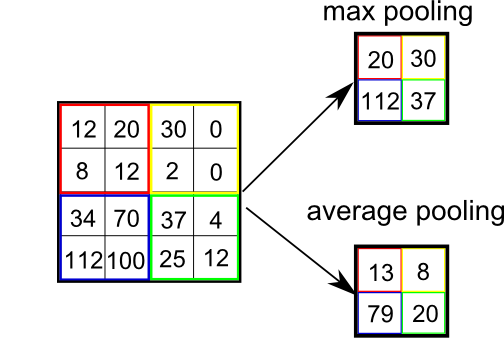
(4). Pooling
I remember in a latest paper of CNN, the author says that I can't explain why I add pooling layer, but a good CNN structure always comes with a pooling layer.
Pooling functions as a dimension reduction Technic. But unlike Kernel which reduces all dimensions, pooling keep channel dimension untouched. Therefore it can further accelerate computation.
Basically Pooling outputs a certain statistics for a certain among of input. This introduces a feature stronger than Equivariant representation -- Invariant representation.
The mainly used Pooling is max and average pooling. And there is L2, and weighted average, and etc.
3. CNN structure
(1). Intuition of CNN
In Deep Learning book, author gives a very interesting insight. He consider convolution and pooling as a infinite strong prior distribution. The distribution indicates that all hidden units share the same weight, derived from certain amount of the input and have parallel invariant feature.
Under Bayesian statistics, prior distribution is a subjective preference of the model based on experience. And the stronger the prior distribution is, the higher impact it will have on the optimal model. So before we use CNN, we have to make sure that our data fits the above assumption.
(2). classic structure
A classic convolution neural network has a convolutional layer, a non-linear activation layer, and a pooling layer. For deep NN, we can stack a few convolution layer together. like below
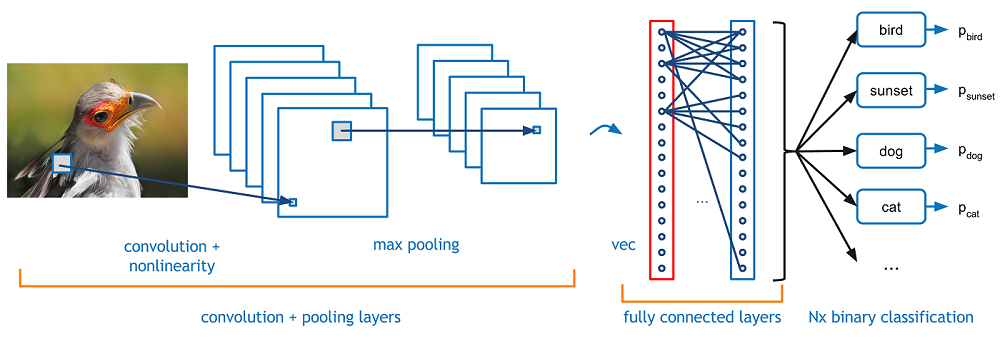
The above plot is taken from Adit Deshpande's A Beginner's Guide To Understanding Convolutional Neural Networks, one of my favorite blogger of ML.
The interesting part of deep CNN is that deep hidden layer can receive more information from input than shallow layer, meaning although the direct connection is sparse, the deeper hidden neuron are still able to receive nearly all the features from input.
(3). To be continue
With learning more and more about NN, I gradually realize that NN is more flexible than I thought. It is like LEGO, convolution, pooling, they are just different basic tools with different assumption. You need to analyze your data and select tools that fits your assumption, and try combining them to improve performance interatively. Later I will open a new post to collect all the NN structure that I ever read about.
Reference
1 Vincent Dumoulin, Francesco Visin - A guide to convolution arithmetic for deep learning (BibTeX)
2 Adit Deshpande - A Beginner's Guide To Understanding Convolutional Neural Networks
3 Ian Goodfellow, Yoshua Bengio, Aaron Conrville - Deep Learning
Deeplearning - Overview of Convolution Neural Network的更多相关文章
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1
3.Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1 http://blog.csdn.net/sunbow0 ...
- Convolution Neural Network (CNN) 原理与实现
本文结合Deep learning的一个应用,Convolution Neural Network 进行一些基本应用,参考Lecun的Document 0.1进行部分拓展,与结果展示(in pytho ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.2
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.2 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.3
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.3 http://blog.csdn.net/sunbow0 ...
- 【面向代码】学习 Deep Learning(三)Convolution Neural Network(CNN)
========================================================================================== 最近一直在看Dee ...
- keras02 - hello convolution neural network 搭建第一个卷积神经网络
本项目参考: https://www.bilibili.com/video/av31500120?t=4657 训练代码 # coding: utf-8 # Learning from Mofan a ...
- 深度学习:卷积神经网络(convolution neural network)
(一)卷积神经网络 卷积神经网络最早是由Lecun在1998年提出的. 卷积神经网络通畅使用的三个基本概念为: 1.局部视觉域: 2.权值共享: 3.池化操作. 在卷积神经网络中,局部接受域表明输入图 ...
- 斯坦福大学卷积神经网络教程UFLDL Tutorial - Convolutional Neural Network
Convolutional Neural Network Overview A Convolutional Neural Network (CNN) is comprised of one or mo ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
随机推荐
- centos安装GD库失败
Error: Package: php-gd-5.6.11-1.el6.remi.x86_64 (remi-php56) Requires: gd-last(x86-64) >= 2.1.1 E ...
- 使用interface与类型诊断机制判断一个类型是否实现了某个方法
Golang中的interface通常用来定义接口,在接口里提供一些方法,其他类型可以实现(implement)这些方法,通过将接口指针指向不同的类型实例实现多态(polymorphism),这是in ...
- 一点一点看JDK源码(〇)
一点一点看JDK源码(〇) liuyuhang原创,未经允许进制转载 写在前面: 几乎所有的大神都会强调看源码,也强调源码的重要性: 但是如何看源码,源码看什么?看了什么用?看了怎么用? 困扰很多人, ...
- Linux-- 目录基本操作(2)
cp 复制文件或目录 用法:cp [OPTION] SOURCE源文件 DIRECTORY目标文件,具体可以查看 man cp 以常用的参数举例 [root@hs-192-168-33-206 tom ...
- 使用属性Props完成一张卡片
一:我们先安装bootstrap,为了使我们的样式好看些 cnpm install bootstrap --save 二:我们在index.js中引入bootstap Import ‘bootst ...
- java环境变量配置(win7)
JDK1.8 1.单击“计算机-属性-高级系统设置”,单击“环境变量”.在“系统变量”栏下单击“新建”,创建新的系统环境变量. 2. (1)新建->变量名"JAVA_HOME&quo ...
- Linux基础练习题之(四)
Linux基础练习题 请详细总结vim编辑器的使用并完成以下练习题 1.复制/etc/rc.d/rc.sysinit文件至/tmp目录,将/tmp/rc.sysinit文件中的以至少一个空白字符开头的 ...
- swiper 仿淘宝详情页面 视频图片切换
1.好兄弟,看一下是否是你需要的 2.废话不多说 直接上代码,复制粘贴一下 自己引用一下swiper.js和css 然后就可以开始玩儿了 <!DOCTYPE html> <html& ...
- 高性能MySQL--MySQL数据类型介绍和最优数据类型选择
MySQL支持的数据类型很多,那么选择合适的数据类型对于获得高性能就至关重要.那么就先了解各种类型的优缺点! 一.类型介绍 1.整型类型 整型类型有: TINYINT,SMALLINT,MEDIUMI ...
- PHP处理高分辨率图片的问题
今天小伙伴在群里问了这么一个问题: 出现这种情况就是因为内存不足,PHP程序直接退出了,报错大概如下: 上图的意思就是说,我们能使用的内存最大是8M,但是处理这个图片还需要额外的41bytes,就会导 ...