K-means + PCA + T-SNE 实现高维数据的聚类与可视化
使用matlab完成高维数据的聚类与可视化
[idx,Centers]=kmeans(qy,)
[COEFF,SCORE,latent] = pca(qy);
SCORE = SCORE(:,:);
mappedX = tsne(SCORE,'Algorithm','exact','NumDimensions',);
c=zeros(,);
for i = :
c(i,idx(i)) = ;
end
scatter3(mappedX(:,),mappedX(:,),mappedX(:,),,c,'fill') % 数据qy为211个,48维。
% K-means: [idx,Centers]=kmeans(data,k)
% 将数据分为k类,idx为每个数据的类别标号,centers为k个中心的坐标, % PCA: [COEFF SCORE latent]=princomp(X)
% 现在已经改名为pca而非princomp
% 参数说明:
% )COEFF 是主成分分量,即样本协方差矩阵的特征向量;
% )SCORE主成分,是样本X在低维空间的表示形式,即样本X在主成份分量COEFF上的投影 ,若需要降k维,则只需要取前k列主成分分量即可
% )latent:一个包含样本协方差矩阵特征值的向量; % T-SNE: mappedX = tsne(X, labels, no_dims, init_dims, perplexity)
% tsne 是无监督降维技术,labels 选项可选;
% X∈RN×D,N 个样本,每个样本由 D 维数据构成;
% no_dims 的默认值为 ;(压缩后的维度)
% tsne 函数实现,X∈RN×D⇒RN×no_dimes(mappedX)
% init_dims:注意,在运行 tsne 函数之前,需要使用 PCA 对数据预处理,将原始样本集的维度降低至 init_dims 维度(默认为 )。
% perplexity:高斯分布的perplexity,默认为 ;
最终效果:
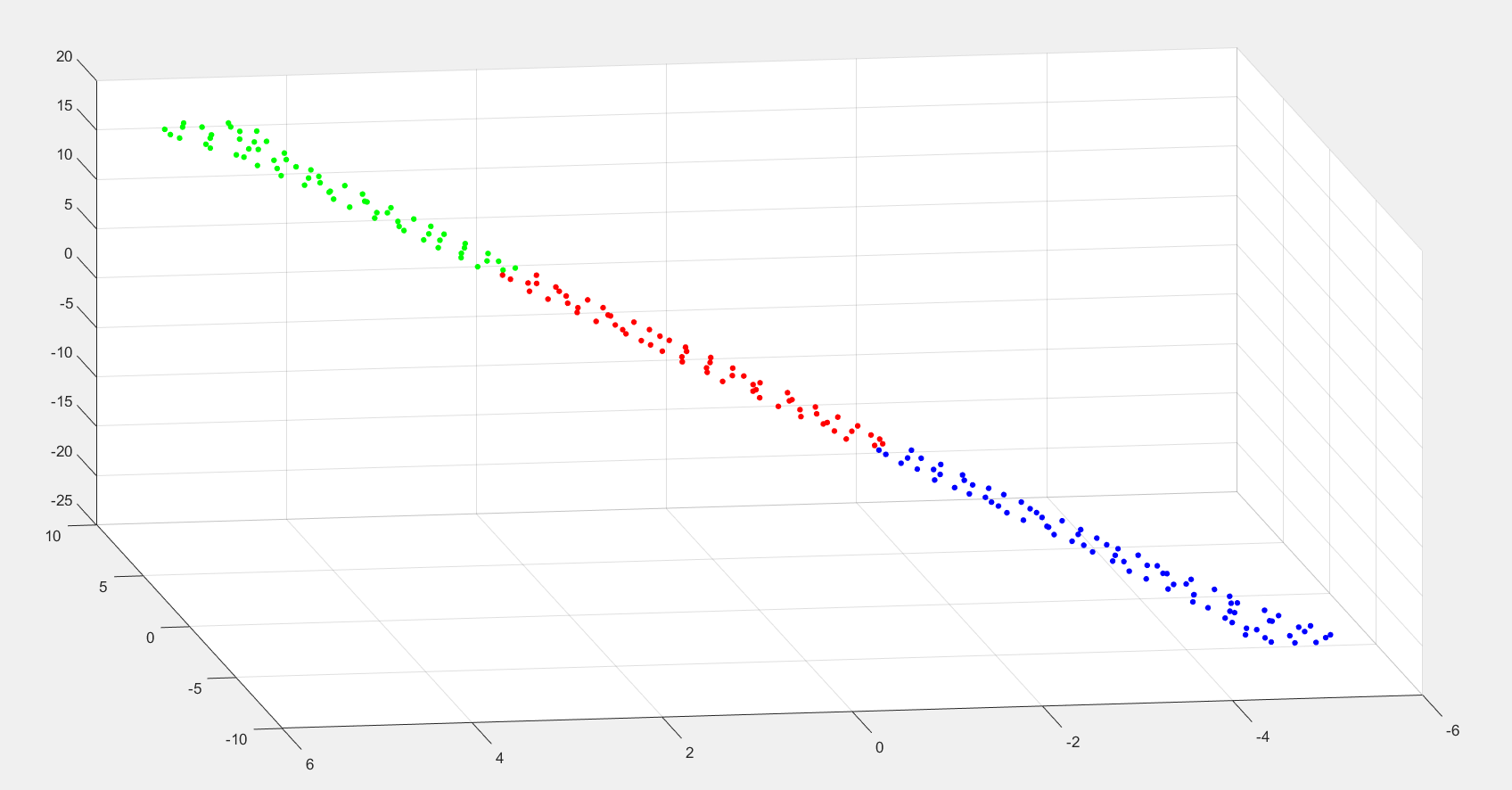
K-means + PCA + T-SNE 实现高维数据的聚类与可视化的更多相关文章
- 机器学习:PCA(高维数据映射为低维数据 封装&调用)
一.基础理解 1) PCA 降维的基本原理 寻找另外一个坐标系,新坐标系中的坐标轴以此表示原来样本的重要程度,也就是主成分:取出前 k 个主成分,将数据映射到这 k 个坐标轴上,获得一个低维的数据集. ...
- 基于Hash算法的高维数据的最近邻检索
一.摘要 最紧邻检索:一种树基于树结构,一种是基于hash a.随机投影算法,需要产生很多哈希表,才能提高性能. b.基于学习的哈希算法在哈希编码较短时候性能不错,但是增加编码长度并不能显著提高性能. ...
- PCA算法详解——本质上就是投影后使得数据尽可能分散(方差最大),PCA可以被定义为数据在低维线性空间上的正交投影,这个线性空间被称为主⼦空间(principal subspace),使得投影数据的⽅差被最⼤化(Hotelling, 1933),即最大方差理论。
PCA PCA(Principal Component Analysis,主成分分析)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量 ...
- 【笔记】求数据前n个主成分以及对高维数据映射为低维数据
求数据前n个主成分并进行高维数据映射为低维数据的操作 求数据前n个主成分 先前的将多个样本映射到一个轴上以求使其降维的操作,其中的样本点本身是二维的样本点,将其映射到新的轴上以后,还不是一维的数据,对 ...
- 高维数据的高速近期邻算法FLANN
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jinxueliu31/article/details/37768995 高维数据的高速近期邻算法FL ...
- 利用 t-SNE 高维数据的可视化
利用 t-SNE 高维数据的可视化 具体软件和教程见: http://lvdmaaten.github.io/tsne/ 简要介绍下用法: % Load data load ’mnist_trai ...
- 高维数据降维 国家自然科学基金项目 2009-2013 NSFC Dimensionality Reduction
2013 基于数据降维和压缩感知的图像哈希理论与方法 唐振军 广西师范大学 多元时间序列数据挖掘中的特征表示和相似性度量方法研究 李海林 华侨大学 基于标签和多特征融合的图像语义空间学习技 ...
- 高维数据Lasso思路
海量数据的特征工程中, 如果数据特征维度达到几千乃至上万 常规的lasso很容易失效 这里介绍几种泛义lasso,是在实际数据处理中常用的 迭代与分块思路/分组的使用(有兴趣的同学可自行实践一下) 1 ...
- EM 算法-对鸢尾花数据进行聚类
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍过K 均值算法,它是一种聚类算法.今天介绍EM 算法,它也是聚类算法,但比K 均值算法更加灵活强大. ...
随机推荐
- linux下安装perl
1.在官网 http://www.perl.org/get.html 下载perl安装包 2.上传服务器并解压 3../Configure -des -Dprefix=安装目录 4.make&am ...
- Oracle AWR与警报系统一
管理自动工作负荷知识库 Oracle收集大量有关性能和活动的统计信息.这些信息在内存中积累,并定期写入数据库:写入到构成自动工作负荷知识库(Automatic Workload Repository, ...
- 关于使用iframe,父元素无法获得子iframe对的元素
首先确定自己写的方法对不对: $(document.getElementById('iframe的ID').contentWindow.document.body).find("要获得的元素 ...
- js如何获取键盘高度
在移动端或混合app开发中,js如何获取键盘高度,直接贴上代码吧 input是一个html input 标签 var timer = { id:null, run:function (callback ...
- 两张图证明 WolframAlpha 的强大
引用于:https://capbone.com/wolfram-alpha/ 两张图证明 WolframAlpha 的强大 之前在" 我手机中有哪些应用 "里提到过 Wolfram ...
- PMP十五至尊图(第六版)
PMP(Project Management Professinoal)项目经理专业资格认证,由美国项目管理学会PMI(Project Management Institute)发起并组织的一种资格认 ...
- 20155232 2016-2017-2 《Java程序设计》第2周学习总结
20155232 2016-2017-2 <Java程序设计>第2周学习总结 教材学习内容总结 类型 基本类型 整数(short.int.long) 字节(byte) -128~127 字 ...
- 20155313 2016-2017-2 《Java程序设计》第四周学习总结
20155313 2016-2017-2 <Java程序设计>第四周学习总结 教材学习内容总结 6 继承与多态 面对对象中,子类继承父类,避免重复的行为定义,不过并非为了避免重复定义行为就 ...
- java 万能转换器 输入SQL 直接得到ArrayList
//java万能List转换器 public static <T> ArrayList<T> ToList(Class<T> clazz,String sql) t ...
- python 多线程笔记(1)-- 概念
本文对不使用线程和使用线程做了一个对比. 假设有两件事情:听歌.看电影 一.不用线程 import time songs = ['爱情买卖','朋友','回家过年','好日子'] movies = [ ...