hadoop学习笔记(一):hadoop生态系统及简介
一、hadoop1.x的生态系统
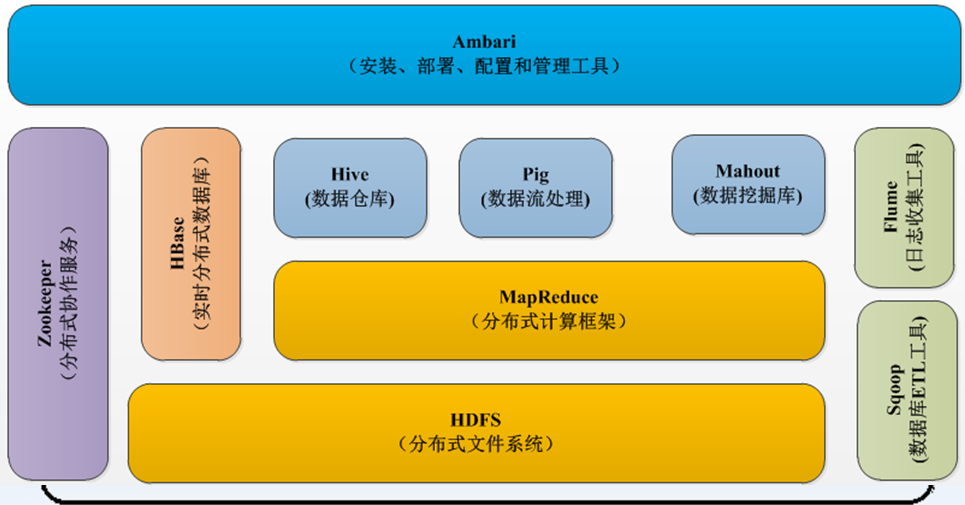
HBase:实时分布式数据库
相当于关系型数据库,数据放在文件中,文件就放在HDFS中。因此HBase是基于HDFS的关系型数据库。实时性:延迟非常低,实时性高。
举栗:在近18亿条数据的表中查询1万条数据仅需1.58s,这是普通数据库(Oracle集群,Mysql集群)无法办到的。
HDFS:分布式文件系统
MapReduce:分布式计算框架
Zookeeper:分布式协作服务
协作HBase存储、管理、查询数据,Zookeeper是一个很好的分布式协作服务框架。
Hive:数据仓库
数据仓库:
比如给你一块1000平方米的仓库,让你放水果。如果有春夏秋冬四季的水果,让你放在某一个分类中。但是水果又要分为香蕉、苹果等等。然后又要分为好的水果和坏的水果。。。。。
因此数据仓库的概念也是如此,他是一个大的仓库,然后里面有很多格局,每个格局里面又分小格局等等。对于整个系统来说,比如文件系统。文件如何去管理?Hive就是来解决这个问题。
Hive:
分类管理文件和数据,对这些数据可以通过很友好的接口,提供类似于SQL语言的HiveQL查询语言来帮助你进行分析。其实Hive底层是转换成MapReduce的,写的HiveQL进行执行的时候,Hive提供一个引擎将其转换成MapReduce再去执行。
Hive设计目的:方便DBA很快地转到大数据的挖掘和分析中。
Pig:数据流处理
基于MapReduce的,基于流处理的。写了动态语言之后,也是转换成MapReduce进行执行。和Hive类似。
Mahout:数据挖掘库
基于图形化的数据碗蕨。
Sqoop:数据库ETL工具
ELT:提取 --> 转换 --> 加载。
从数据库中获取数据,并进行一系列的数据清理和清洗筛选,将合格的数据转换成一定格式的数据进行存储,将格式化的数据存储到HDFS文件系统上,以供计算框架进行数据分析和挖掘。
格式化数据:
|- TSV 格式:每行数据的每列之间以制表符(tab \t)进行分割
|- CVS 格式:每行数据的每列之间以逗号进行分割
Sqoop:将关系型数据库中的数据与HDFS(HDFS 文件,HBase中的表,Hive中的表)上的数据进行相互导入导出。
Flume:日志收集工具
将大的集群上面的每台机器的日志收集起来,自动地放到你指定的HDFS文件系统的某个路径中去。
Ambari:安装、部署、配置和管理工具
提供一个图形化工具对集群进行安装、部署、配置及管理,无需手动在命令行操作。
四、hadoop2.x的生态系统
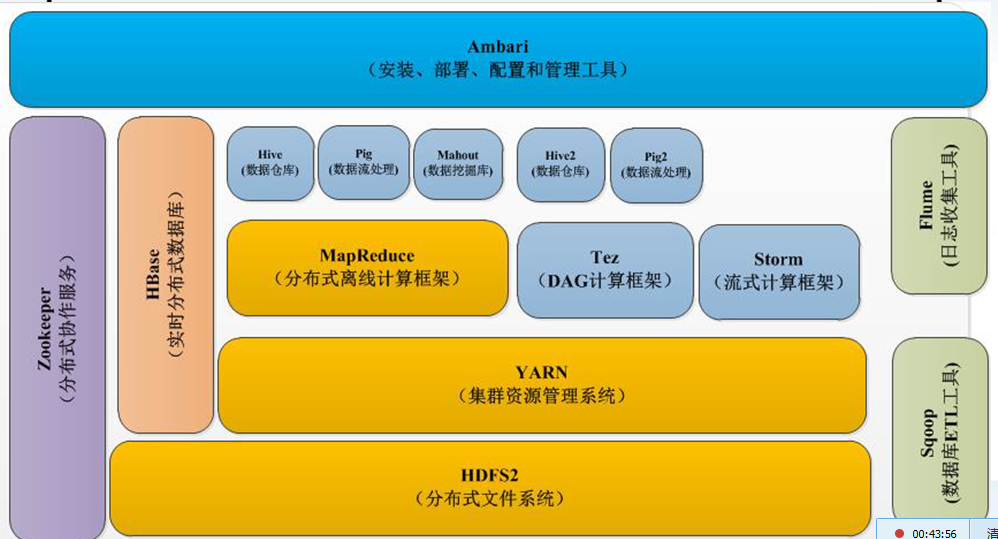
YARN:集群资源管理系统
对整个集群每台机器的资源进行管理,对每个服务、每个job、每个应用进行调度(CPU等)。
HDFS2:分布式文件系统
增强了一些特性,最主要的就是NameNode的单节点故障和NameNode的横向扩展。
Tez:DAG计算框架
Storm:流式计算框架
五、hadoop1.x组成
对于分布式系统和框架的架构来说,一般分为两部分:
第一部分:管理层,用于管理应用层的。
第二部分:应用层(工作)。
HDFS核心后台守护进程:
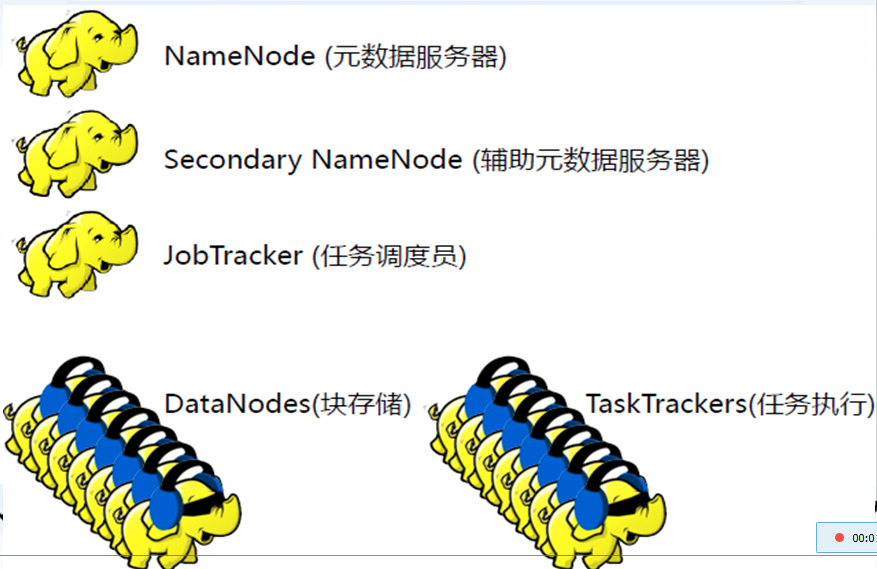
NameNode:元数据服务器
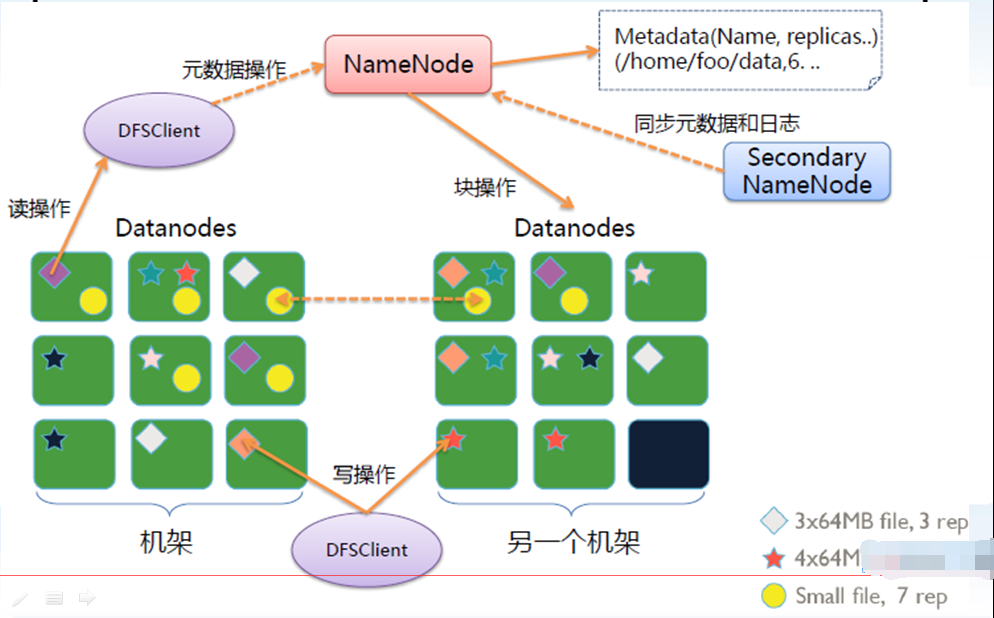
NameNode是主节点,存储文件的元数据如文件名、文件目录结构、文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在DataNode等。
属于管理层,用于管理数据的存储。
Secondary NameNode:辅助元数据服务器
用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
属于管理层,辅助NameNode进行管理。
DataNode:块存储
在本地文件系统存储文件块数据,以及块数据的校验和。
属于应用层,用于进行数据的存储,被NameNode进行管理。要定时向NameNode进行工作汇报,执行NameNode分配分发的任务。
MapReduce,分布式进行计算框架:
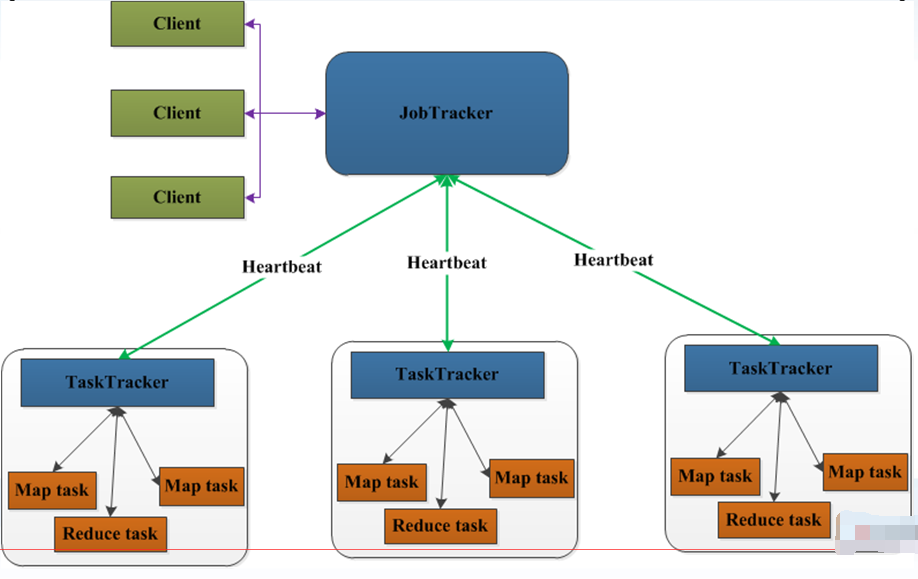
JobTracker:任务调度员
负责接收用户提交的作业,负责启动、跟踪任务执行。
属于管理层,管理集群资源和对任务进行资源调度,监控任务的执行。
TaskTrackers:任务执行
负责执行由JobTracker分配的任务,管理各个任务在每个节点上的执行情况。
属于应用层,执行JobTracker分配分发的任务,并向JobTracker汇报工作情况。
六、HDFS架构图
七、MapReduce架构图
hadoop学习笔记(一):hadoop生态系统及简介的更多相关文章
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- 吴裕雄--天生自然Hadoop学习笔记:Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储.Hadoop实现了一个分布式文件系统(H ...
- Hadoop学习笔记【Hadoop家族成员概述】
Hadoop家族成员概述 一.Hadoop简介 1.1 什么是Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者. Hadoop实现了 ...
- [Hadoop] Hadoop学习笔记之Hadoop基础
1 Hadoop是什么? Google公司发表了两篇论文:一篇论文是“The Google File System”,介绍如何实现分布式地存储海量数据:另一篇论文是“Mapreduce:Simplif ...
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- Hadoop学习笔记—6.Hadoop Eclipse插件的使用
开篇:Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率.但是,它也有一些缺点,如编码.调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高 ...
- Hadoop学习笔记—3.Hadoop RPC机制的使用
一.RPC基础概念 1.1 RPC的基础概念 RPC,即Remote Procdure Call,中文名:远程过程调用: (1)它允许一台计算机程序远程调用另外一台计算机的子程序,而不用去关心底层的网 ...
- Hadoop学习笔记(3) Hadoop I/O
1. HDFS的数据完整性 HDFS会对写入的所有数据计算校验和,并在读取数据时验证校验和.datanode负责在验证收到的数据后存储数据及其校验和.正在写数据的客户端将数据及其校验和发送到由一系列d ...
- Hadoop学习笔记(3) Hadoop文件系统二
1 查询文件系统 (1) 文件元数据:FileStatus,该类封装了文件系统中文件和目录的元数据,包括文件长度.块大小.备份.修改时间.所有者以及版权信息.FileSystem的getFileSta ...
- Hadoop学习笔记(3) Hadoop文件系统一
1. 分布式文件系统,即为管理网络中跨多台计算机存储的文件系统.HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上.HDFS的构建思路为:一次写入.多次读取是最高效的访问模式.数据集通常由 ...
随机推荐
- dockerfile构建redis
-------------------------------------------------------------
- iOS NSMutableArray "removeObjectIdenticalTo" vs "removeObject"
NSMutableArray 有多种可以删除元素的方法. 其中 removeObject,removeObjectIdenticalTo 这两个方法是有区别的. [anArray removeObje ...
- Oracle数据库exp和imp方式导数据
这里导入导出路径都在D盘下,默认文件名为:example.dmpexp方式导出数据相关参数项如下: 关键字 说明 默认USERID 用户名/口令FULL ...
- php性能优化二(PHP配置php.ini)
PHP优化对于PHP的优化主要是对php.ini中的相关主要参数进行合理调整和设置,以下我们就来看看php.ini中的一些对性能影响较大的参数应该如何设置. # vi /etc/PHP.ini (1) ...
- item pipeline 实例:爬取360摄像图片
生成项目 scrapy startproject image360 cd Image360 && scrapy genspider images images.so.com 一. 构 ...
- zookeeper 高可用集群搭建
前言 记录Zookeeper集群搭建的过程! 什么是 Zookeeper ? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hado ...
- Dota2APP--第二天
一.今天的任务 1)自定义标签栏控制器 2)自定义导航栏控制器 3)在新特性界面播放音频 1.第一个任务:自定义标签栏控制器 原因:默认的TabbarViewController不能满足项目的需求. ...
- docker微服务部署之:三,搭建Zuul微服务项目
docker微服务部署之:二.搭建文章微服务项目 一.新增demo_eureka模块,并编写代码 右键demo_parent->new->Module->Maven,选择Module ...
- Python基础部分的疑惑解析(2)
变量: 变量名由 字母.数字.下划线构成,数字不能做为开头 不能用关键字:另外一些内置的方法也别用 推荐使用下划线命名间两个单词user_id 变量在最后底层处理的时候没什么意义,但是在命名的时候有利 ...
- python 异步IO(syncio) 协程
python asyncio 网络模型有很多中,为了实现高并发也有很多方案,多线程,多进程.无论多线程和多进程,IO的调度更多取决于系统,而协程的方式,调度来自用户,用户可以在函数中yield一个状态 ...