Algorithm partI 第2节课 Union−Find
发展一个有效算法的具体(一般)过程:

union-find用来解决dynamic connectivity,下面主要讲quick find和quick union及其应用和改进。
基本操作:find/connected queries和union commands

动态连接性问题的场景:
1.1 建立模型(Model the problem):
关于object:0-N-1

关于连接的等价性:

关于连接块:
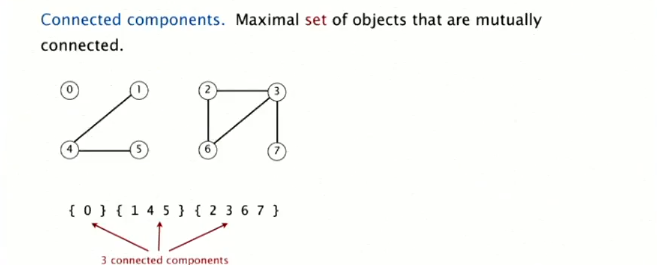
关于基本操作find query和union command:
比如union操作:
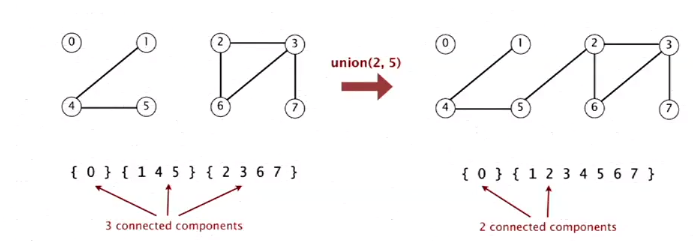
目标:

练习:

答案:C。最后剩下的连接块有{0,5,6}{3,4}{1,2,7,8,9}。
1.2 算法及其改进(Algorithm and improvement):
1.2.1 Quick Find
实现过程:
public class QuickFindUF
{
private int[] id; public QuickFindUF(int N)
{
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
} public boolean connected(int p, int q)
{ return id[p] == id[q]; } public void union(int p, int q)
{
int pid = id[p];
int qid = id[q];
for (int i = 0; i < id.length; i++)
//这里有个约定:
//p和q联合的时候,所有和p是一个连接块(connected conponents)的点的id都要设置为与id[q]相等
if (id[i] == pid) id[i] = qid;
}
}
各个函数的时间复杂度: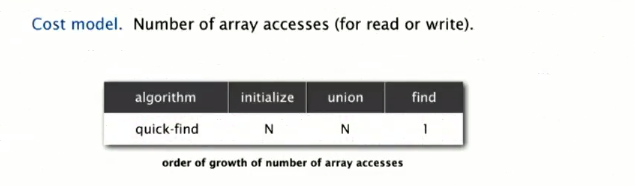
弊端:

对N个实体做N次的union操作,时间复杂度是O(N2)。换言之,Quick find太慢,不适合大量的数据。
练习:
答案:C。最差情况就是除了id[q],其他元素都要改变。
1.2.2 Quick Union
说明:

实现过程:
public class QuickUnionUF
{
private int[] id;//id[i],节点i的父节点 public QuickFindUF(int N)
{
id = new int[N];
//划分为N棵子树,每个子树的根节点就是本身
for (int i = 0; i < N; i++)
id[i] = i;
} private int root(int i)//找打i所在子树的根节点
{
//如果id[i] == i,说明i是某一棵子树的根节点
while (i != id[i]) i = id[i];
return i;
} public boolean connected(int p, int q)
{
return root(p) == root(q);
} public void union(int p, int q)//将p所在子树的根节点的父节点设为q所在子树的根节点
{
int i = root(p);
int j = root(q);
id[i] = j;
}
}
各个操作的时间复杂度:注意quick union的union和find是最差情况(例如,形成的子树很高)的时间复杂度。

弊端:
练习:

答案:D。3的根节点是6:3->5->2->6。7的根节点是6:7->1->9->5->2->6。
练习:
答案:C
1.2.3 Weighted quick union
Improvement 1:weighting。为每个树保留track记录树的规模;union的时候将规模小的树的根节点添加为规模大的树的根节点的子节点。主要针对Quick union中容易出现树很高的情况。
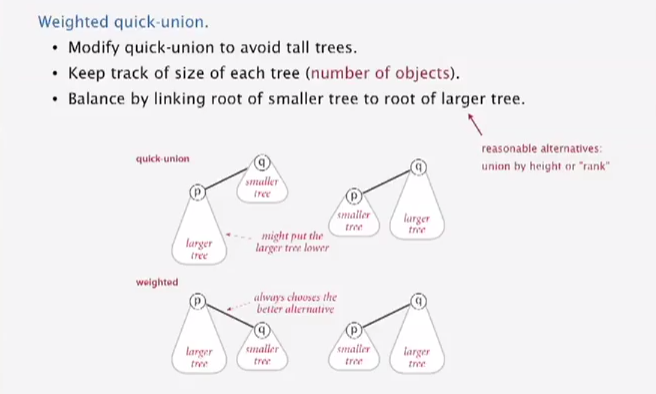
实现过程:
public class WeightedQuickUnionUF {
private int[] id,sz;
public WeightedQuickUnionUF(int N)
{
id = new int[N];
sz = new int[N];//记录以i为根节点的树的节点个数
for (int i = 0; i < N; i++)
{
sz[i] = 1;
id[i] = i;
}
}
private int root(int i)//和quick union相同
{
while (i != id[i]) i = id[i];
return i;
}
public boolean connected(int p, int q)//和quick union相同
{
return root(p) == root(q);
}
public void union(int p, int q)
{
int i = root(p);
int j = root(q);
if (i == j) return;
if (sz[i] < sz[j]){id[i] = j; sz[j] += sz[i];}
else {id[j] = i; sz[i] += sz[j];}
}
}
各个函数的时间复杂度:注意到weighted quick union中的union和connected操作的时间复杂度都是log2N。

命题:按照Weighted quick union实现的树的任意一个节点的深度不会超过log2N。
证明:关注任意节点x。
1. 只有当包含x的子树T1作为lower tree被合并的时候,x的深度才有可能增加1。
2. 另一棵树T2,其中sz[T2]>=sz[T1]。
每合并1次,树的规模*2,并且最后的树的规模==N,所以x最多只能增加log2N次,意味着节点x最后的深度不会超过log2N。
Weighted quick union和Quick union的比较实例:
Weighted quick union实现结果更加均衡,叶节点到根的距离最大为4,每个节点到根节点的距离的平均要远远小于Quick union的结果。

1.2.4 Weighted quick union with path compressioin
Improvement 2:path compression。就是路径压缩。

实现过程有2种方式:主要区别是root函数的实现。
1. 找到当前点x的根节点后,将x与根节点相连路径上的所有节点的父节点设为根节点。
2. 在寻找当前点x的根节点的过程中,直接将x的父节点设置为x的父节点的父节点。

下面只展示union函数的实现:
方式1:
private int root(int i)
{
if (id[i] == i) return i;//只有指向根节点才返回
return id[i] = root(id[i]);
}
方式2:
private int root(int i)
{
while (i != id[i])
{
id[i] = id[id[i]];//指向父节点的父节点
i = id[i];
}
return i;
}
对N个点使用Weighted quick union with path compressioin中的union find操作m次的时间复杂度:

关于lg*的解释:http://stackoverflow.com/questions/2387656/what-is-olog-n/2387669
log* (n)- "log Star n" as known as "Iterated logarithm"
In simple word you can assume log* (n)= log(log(log(.....(log* (n))))
已经证明,union find问题的时间复杂度不可能到O(N)。
练习:


答案:

总结:

Algorithm partI 第2节课 Union−Find的更多相关文章
- centos DNS服务搭建 DNS原理 使用bind搭建DNS服务器 配置DNS转发 配置主从 安装dig工具 DHCP dhclient 各种域名解析记录 mydns DNS动态更新 第三十节课
centos DNS服务搭建 DNS原理 使用bind搭建DNS服务器 配置DNS转发 配置主从 安装dig工具 DHCP dhclient 各种域名解析记录 mydns DNS动态更 ...
- 风炫安全Web安全学习第十六节课 高权限sql注入getshell
风炫安全Web安全学习第十六节课 高权限sql注入getshell sql高权限getshell 前提条件: 需要知道目标网站绝对路径 目录具有写的权限 需要当前数据库用户开启了secure_file ...
- centos linux安全和调优 第四十一节课
centos linux安全和调优 第四十一节课 上半节课 Linux安全 下半节课 Linux调优 2015-07-01linux安全和调优 [复制链接]--http://www.apele ...
- centos shell编程6一些工作中实践脚本 nagios监控脚本 自定义zabbix脚本 mysql备份脚本 zabbix错误日志 直接送给bc做计算 gzip innobackupex/Xtrabackup 第四十节课
centos shell编程6一些工作中实践脚本 nagios监控脚本 自定义zabbix脚本 mysql备份脚本 zabbix错误日志 直接送给bc做计算 gzip innobacku ...
- [iOS]Objective-C 第一节课
Objective-C 第一节课 本节课的主要内容 创建Objective-C的第一个工程 HelloWorld Objective-C中的字符串 创建Objective-C的第一个工程 打开Xcod ...
- 《从零玩转python+人工智能-3》120,122节课深度优先疑问解答
深度优先(从左往右): 按照这个原则来:至于使用栈,或者队列:根据它们不同的特性:最终务必保证最终结果是原继承结构的“从左往右”:所以,如果是栈,就是右侧先入栈,左侧再入(这样左侧能先出来,遵循从左 ...
- [转][南京米联ZYNQ深入浅出]第二季更新完毕课程共计16节课
[南京米联]ZYNQ第二季更新完毕课程共计16节课 [第二季ZYNQ] ...
- SpringBoot常用Starter介绍和整合模板引擎Freemaker、thymeleaf 4节课
1.SpringBoot Starter讲解 简介:介绍什么是SpringBoot Starter和主要作用 1.官网地址:https://docs.spring.io/spring-boot/doc ...
- centos mysql 实战 第一节课 安全加固 mysql安装
centos mysql 实战 第一节课 安全加固 mysql安装 percona名字的由来=consultation 顾问+performance 性能=per con a mysql ...
随机推荐
- centos 7.6 开机报错信息(一):welcome to emergency mode!
welcome to emergency mode!after logging in ,type "journalctl -xb" to view system logs,&quo ...
- [LeetCode 题解]: Linked List Cycle II
Given a linked list, return the node where the cycle begins. If there is no cycle, return null. Foll ...
- Tomcat 配置用户认证服务供C#客户端调用
项目里,遇到的一个小问题来好好的总结一下.因为我们这个项目是用Java写的服务端发布WebService,客户端呢使用C#来调用WebService(本人以前搞过一段时间C#客户端,还总结了一个MVP ...
- C#注册表操作类(完整版) 整理完整
/// <summary> /// 注册表基项静态域 /// /// 主要包括: /// 1.Registry.ClassesRoot 对应于HKEY_CLASSES_ROOT主键 /// ...
- JSON 解析的两种方法
今天帮朋友看了下JSON解析结果············· eval解析JSON中的注意点 在JS中将JSON的字符串解析成JSON数据格式,一般有两种方式: 1.一种为使用eval()函数. 2. ...
- UWP开发入门(十)——通过继承来扩展ListView
本篇之所以起这样一个名字,是因为重点并非如何自定义控件,不涉及创建CustomControl和UserControl使用的Template和XAML概念.而是通过继承的方法来扩展一个现有的类,在继承的 ...
- dubbo事件通知机制(1)
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. dubbo事件通知机制:http://dubbo.io/books/dubbo-user-book/demos ...
- JAVA数组的遍历和取最值
1.获取数组中的所有元素,会用到数组的遍历 数组的遍历,通常用for循环. public class ArrayDemo { public static void main(String[] args ...
- Spring 事务相关点整理
Spring和事务的关系 关系型数据库.某些消息队列等产品或中间件称为事务性资源,因为它们本身支持事务,也能够处理事务. Spring很显然不是事务性资源,但是它可以管理事务性资源,所以Spring和 ...
- vue重构后台管理系统调研
Q4要来了,我来这家公司已经一个季度了,通过对公司前端框架的整体认识,对业务的一些认识,发现,这些东西也都是可以重构,无论是v2,还是v3的代码. 首先就要那后台管理来开刀来,现有的技术框架就是php ...