续上一篇文章 Redis Scan迭代器遍历操作原理(一)–基础 ,这里着重讲一下dictScan函数的原理,其实也就是redis SCAN操作最有价值(也是最难懂的部分)。
关于这个算法的源头,来自于githup这里:Add SCAN command #579,长篇的讨论,确实难懂····建议看看这帖子,antirez 跟pietern 关于这个奇怪算法的讨论···
这个算法的作者是:Pieter Noordhuis,作者称其为:reverse binary iteration ,不知道我一对一翻译为“反向二进制迭代器”可不可以,不过any way ··作者自己也没有明确的证明其真假:
antirez: Hello @pietern! I’m starting to re-evaluate the idea of an iterator for Redis, and the first item in this task is definitely to understand better your pull request and implementation. I don’t understand exactly the implementation with the reversed bits counter…
I wonder if there is a way to make that more intuitive… so investing some more time into this, and if I fail I’ll just merge your code trying to augment it with more comments…
Hard to explain but awesome.
pietern: Although I don’t have a formal proof for these guarantees, I’m reasonably confident they hold. I worked through every hash table state (stable, grow, shrink) and it appears to work everywhere by means of the reverse binary iteration (for lack of a better word).
下面从零开始讲一下redis的迭代器应该怎么设计,以及为什么不这么设计,而要这么设计·····
0.可用性 保证(Guarantees):
1.迭代结果可以重复;
2.整个迭代过程中,没有变化(增加删除)过的key必须出现在结果中;
redis的key是用hash存在的,key分布在数组的槽位内,下标从0到2^N,并且采用链表解决冲突。
hash会自动扩容或者缩小,并且每次 都是按2^N变化的。具体可以参阅:Redis源码学习-Dict/hash 字典。
1.最简单暴力的方法:顺序迭代:
这个简单,从0到2^N下标扫描一次,每次返回一个slot(槽位,也就是数组的一项,下同)或者多个slot的数据,这样实现非常简单,在不发生rehash的时候,这种方法没问题,能够完成前面的要求。,但有以下问题:
1.如果后来字典扩容了,比如2,4倍长度,那么能够保证一定能找出没变化的key,但是却会出现大量重复。
比如当前的key数组大小是8,后来变为16了,比如从0,1,2,3““顺序扫描,如果数组发生扩容,那么前面的0,1,2,3 slot里面的数据会发生一部分迁移到对应的8,9,10,11 slot里面去,并且这个量挺大;
2.如果字典缩小了,比如从16缩小到8, 原先scan已经遍历了0,1,2,3 ,然后发生缩小,这样后来迭代停止在7号slot,但是8,9,10,11这几个slot的数据会分别合并到0,1,2,3里面去,从而scan就没有扫描出这部分元素出来,无法保证可用性;
3.在发生rehashing的过程中,这个肯定有问题的。
2.中间的改进版本:
为了避免上面第一种方法中第1个问题,也就是大量重复的问题,我们可以改进为这样迭代扫描:如果字典大小为8, 那么扫描的时候,总是这么扫描:0,4, 1,5, 2,6, 3,7, 也就是访问完i 后,再访问i+2^(N-1), 这样如果已经访问过0,4, 1,5 了,当访问完2号slot之后,发生了扩容,变成了字典大小是16, 那么我们不需要再次去访问8,9号了,原因是8,9号里面的数据一定是从0和1里面迁移过去的。
但很可惜,这样还是无法解决字典缩小的时候没有访问问题,比如访问完0后,发生字典缩小,原来8号的数据迁移到了0号,然后按照算法,会去访问4号的。这样就会有问题。
2.redis的反向二进制位迭代器 原理:
首先从直观感觉上,跟第二种方法类似的跳跃扫描,但是redis的方法更加完善。下面一步步的来介绍一下redis的SCAN原理
首先我们知道,这个迭代操作有下面几个地方需要注意:
- 字典大小不变的时候;
- 字典大小扩容的时候 ;
- 字典大小缩小的时候;
- 发生rehash的时候;
对于最简单的时候,也就是没有发生字典大小变化,那么最简单了,按照redis现在的方式处理如下,然后再扩展到redis怎么处理变化的时候。
先贴一下代码:
1 |
unsigned long dictScan(dict *d, |
10 |
if (dictSize(d) == 0) return 0; |
12 |
if (!dictIsRehashing(d)) {//没有在做rehash,所以只有第一个表有数据的 |
15 |
//槽位大小-1,因为大小总是2^N,所以sizemask的二进制总是后面都为1, |
16 |
//比如16个slot的字典,sizemask为00001111 |
18 |
/* Emit entries at cursor */ |
19 |
de = t0->table[v & m0];//找到当前这个槽位,然后处理数据 |
21 |
fn(privdata, de);//将这个slot的链表数据全部入队,准备返回给客户端。 |
29 |
/* Make sure t0 is the smaller and t1 is the bigger table */ |
30 |
if (t0->size > t1->size) {//将地位设置为 |
38 |
/* Emit entries at cursor */ |
39 |
de = t0->table[v & m0];//处理小一点的表。 |
45 |
/* Iterate over indices in larger table that are the expansion |
46 |
* of the index pointed to by the cursor in the smaller table */ |
47 |
do {//扫描大点的表里面的槽位,注意这里是个循环,会将小表没有覆盖的slot全部扫描一次的 |
48 |
/* Emit entries at cursor */ |
49 |
de = t1->table[v & m1]; |
55 |
/* Increment bits not covered by the smaller mask */ |
56 |
//下面的意思是,还需要扩展小点的表,将其后缀固定,然后看高位可以怎么扩充。 |
57 |
//其实就是想扫描一下小表里面的元素可能会扩充到哪些地方,需要将那些地方处理一遍。 |
58 |
//后面的(v & m0)是保留v在小表里面的后缀。 |
59 |
//((v | m0) + 1) & ~m0) 是想给v的扩展部分的二进制位不断的加1,来造成高位不断增加的效果。 |
60 |
v = (((v | m0) + 1) & ~m0) | (v & m0); |
62 |
/* Continue while bits covered by mask difference is non-zero */ |
63 |
} while (v & (m0 ^ m1));//终止条件是 v的高位区别位没有1了,其实就是说到头了。 |
66 |
/* Set unmasked bits so incrementing the reversed cursor |
67 |
* operates on the masked bits of the smaller table */ |
69 |
//按位取反,其实相当于v |= m0-1 , ~m0也就是11110000, |
70 |
//这里相当于将v的不相干的高位全部置为1,待会再进行翻转二进制位,然后加1,然后再转回来 |
72 |
/* Increment the reverse cursor */ |
76 |
//下面将v的每一位倒过来再加1,再倒回去,这是什么意思呢, |
77 |
//其实就是要将有效二进制位里面的高位第一个0位设置置为1,因为现在是0嘛 |
0. 字典大小不变
假设字典大小为8,那么redis 的slot扫描顺序为:

细心的可以发现一个规律,就是可以两两分组,并且互相相差正好是8/2= 4。 对,这个是为了后面设计的。
我们来看一下其二进制位的变化,如下,可以看出其两两的差异在于高位不一样,算法会依次从高位开始尝试0和1的变化:

来说一下它的好处,这种方法还可以这样描述:
依次从高位(有效位)开始,不断尝试将当前高位设置为1,然后变动更高位为不同组合,以此来扫描整个字典数组。
这里我们肯定是一定能够扫描完整个数组的,不会漏。但其最大的好处在于,从高位扫描的时候,如果槽位是2^N个,扫描的临近的2个元素都是与2^(N-1)相关的就是说同模的,比如槽位8时,0%4 == 4%4, 1%4 == 5%4 , 因此想到其实hash的时候,跟模是很相关的。
比如当整个字典大小只有4的时候,一个元素计算出的整数为5, 那么计算他的hash值需要模4,也就是hash(n) == 5%4 == 1 , 元素存放在第1个槽位中。当字典扩容的时候,字典大小变为8, 此时计算hash的时候为5%8 == 5 , 该元素从1号slot迁移到了5号,1和5是对应的,我们称之为同模或者对应。同模的槽位的元素最容易出现合并或者拆分了。因此在迭代的时候需要及时的扫描这些相关的槽位,这样就不会造成大面积的重复扫描。
我们可以来走一遍代码,正常情况下,SCAN从0开始,假设字典大小为8,那么dictScan代码中字典肯定不是在做rehashing,所以进入第一个if,直接将table[v & 8] 里面的链表节点返回给客户端。然后计算下一个scan的游标,计算代码如下:
1 |
//v == 0 ,也就是0000 0000 , m0是size == 8时的掩码,也就是0000 0111 |
2 |
v |= ~m0; //~m0按位取反,为1111 1000 , 跟v做或得到v的新值为 1111 1000 |
3 |
v = rev(v);//将V的每一位反过来,得到 0001 1111 |
4 |
v++; //这个是关键,加1,注意其效果,得到0010 0000 , 什么意思呢?对一个数加1,其实就是将这个数的低位的连续1变为0,然后将最低的一个0变为1,其实就是将最低的一个0变为1 |
5 |
v = rev(v);//再次反过来,得到了:0000 0100 , 十进制就是4 , 正好跟上面的吻合 |
这里来体味一下,上面反转,然后加1,然后再反转,整体效果其实就是想将有效位中,从高位开始的第一个0之上的1变为0,将第一个碰到的0变为1, 或者说尝试将0变为1的slot。
更细致的说,上面的例子,是将0变为了1,效果就是scan的游标从0升为4,升到一个对应的高槽位去。下面来看一下从高槽位回到低位的过程,也就是将高位1设置会0,的过程:
1 |
//v == 4 ,也就是0000 0100 , m0是size == 8时的掩码,也就是0000 0111 |
2 |
v |= ~m0; //~m0按位取反,为1111 1000 , 跟v做或得到v的新值为 1111 1100 |
3 |
v = rev(v);//将V的每一位反过来,得到 0011 1111 |
4 |
v++; //这个是关键,加1,注意其效果,得到0100 0000 |
5 |
v = rev(v);//再次反过来,得到了:0000 0010 , 十进制就是2 |
注意上面本来游标等于0000 0100 , 到最后的结果变为,从高位开始,第一个1变为了0,随后的0变为了1. 其实就是说,从4,降到了2,也就是开始新的一个搭配。因为最高位已经尝试过了,0->4是将最高位的0变为1的过程,现在应该轮到次高位了。
这种情况下既能够保证未改动的key一定存在,并且只会存在一次;
不太明白的话可以再一步步走一遍,在纸上写一下整个计算过程,多几次就清楚了。
1.当字典大小扩大的时候
这里假设变化之前,字典大小为8,后来扩大为16了。具体的流程为:
- scan 0 扫描,后来依次扫描了0,最后游标返回为4 ;
- 发生字典扩容以及rehashing,并且完成了;
- 客户端发送scan 4的指令过来;
当前的情况如下:

原先0号下 链表的元素被分拆到了0或者8号新slot, 取决于对应key的hash值第4位为0还是1,;但这个在上面的第一步返回给客户端了,所以后续的迭代是不需要返回的。
至于4号,此时scan 4, 那么redis会先将4的下标的链表元素返回给客户端,然后计算下一个slot,注意此时的计算不一样了,因为有效位掩码不一样了,多加了一位高位1. 因此这次返回的游标不再是2,而应该是12了。看下面的计算过程:
1 |
//v == 4 ,也就是0000 0100 , m0是size == 16时的掩码了,所以就是0000 1111 |
2 |
v |= ~m0; //~m0按位取反,为1111 0000 , 跟v做或得到v的新值为 1111 0100 |
3 |
v = rev(v);//将V的每一位反过来,得到 0010 1111 |
4 |
v++; //这个是关键,加1,注意其效果,得到0011 0000 , 也就是讲上面的0010 1111的后面所有的连续1换成0,第一个1换成1 |
5 |
v = rev(v);//再次反过来,得到了:0000 1100 , 十进制就是4+8 = 12. |
根据上面的计算,访问4之后,自然的就过度懂啊了8,而不是之前的12,因为之前的4号的数据迁移到了4或者8号,必须扫描迁移到8号的元素,否则就会出现漏掉的key。这种情况下,访问到的key不会多也不会小,因为原先访问的0现在分到了0和8,但已经访问过了,因此自然的从4号开始访问就行了。
这里再考虑一下第二种情况,如果扩容后,游标不是在4上,而是在2上,也就是在一个高位为0的上面,假设已经访问完了0,4,返回游标2,此时发生了扩容并且已经完成,size变为16了。此时0和4都不需要访问了。下一个访问2号,并且计算下一个slot是多少:
1 |
//v == 2 ,也就是0000 0010 , m0是size == 16时的掩码了,所以就是0000 1111 |
2 |
v |= ~m0; //~m0按位取反,为1111 0000 , 跟v做或得到v的新值为 1111 0010 |
3 |
v = rev(v);//将V的每一位反过来,得到 0100 1111 |
4 |
v++; //这个是关键,加1,注意其效果,得到0101 0000 , 也就是讲上面的0100 1111的后面所有的连续1换成0,第一个1换成1 |
5 |
v = rev(v);//再次反过来,得到了:0000 1010 , 十进制就是2+8 = 10. |
由于0,4号slot已经访问完毕,当前还没有访问的4号,也已经发生了迁移,有一部分高位为1的跑到了2+8 = 10 号slot 上面了。所以扫描完2后,需要自然的去迭代10号下标,不漏掉一个key。后续10号访问完成后,应该将是:6,然后14,一次继续就行了。跟上面的类似。
总结一下,对于字典大小扩大的情况,redis是是这样解决的:先访问n号slot,然后再访问n+2^N,因为这里面的元素其实都是从老的8个size的2号slot拆分到了2个slot,后面就需要访问这2个地方才行。正好这个算法支持这个。
这一点,redis scan保证了什么呢?保证了没有发生增删的操作的key一定能够找到;
在这种情况下,没变过的key一定能够返回,数据不会出现2次;
2.当字典大小缩小的时候:
其实字典缩小跟扩大类似,不过也有区别的。
字典大小缩小,也就是降低为原来的一半或者1/4····等等;假设我们之前是16个slot,后来变为8个slot了。如果当前用户扫描过了0,8,4, 手里最新的游标为12的话,我们来看一下图片:
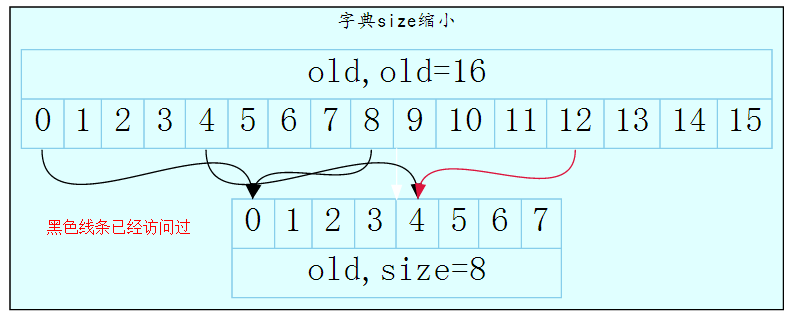
由于我们之前访问过了0和8,当字典缩小时, 原先的0和8的数据肯定是放到了新的数组的0号位置上(去掉高位),这个我们之前已经访问过了,所以不需要访问了的。
但是对于已经访问了原先的4号,然后发生了迁移,字典大小减少为8,原来的4和12 中12号下标的元素还没有访问,但是,当发生迁移后,12号的元素已经迁移到了新slot的4号位置上。那怎么能够保证不丢这个的数据呢?答案在代码中。
de = t0->table[v & m0]; 这个语句,总是跟当前的掩码进行按位求与,也就是只留那些有效位,本来scan 12发送过来,其v等于:0000 1100, m0此时应该是8,也就是0000 0111, 那么v&m0等于0000 0100, 也就是第四位的1被抹掉了,迁移到了4号,其实也就是说原先我们已经访问了老数组的 0,8, 4号,其中4和12号是一组的,迁移缩小后,4和12都映射到了4号上面去了。接下来的scan 12虽然游标是12,但是截取有效位后,也就是访问的还是4号;
这里就出现了重复的情况;重新访问4号,然后4号后根据以往的经验,4号后的访问,我们不在需要访问8以上的key了,因为size只有8了。并且能够放心的是,像3,11, 2,10, 等这些一对一的还没有访问的数据,肯定都会映射到了对应的8个槽位的对应元素里面。之后就当是一开始字典大小为8的dict的遍历工作。
总结一下当数组发生缩小的时候,会发生的事情:照样能够保证key没变动过的数据一定能够扫描出来返回; 另外由于要高位会合并到低位的slot里面,所以会发生重复,重复的数据是原先在4里面的所有数据。
3.在rehashing的过程中
前面讨论的情况都是没有遇到在rehashing的过程中,都是扩容或者缩小的时候都没有请求到来。这里来简单讨论一下发生rehashing的过程中,接受到的SCAN该怎么处理;
redis处理这个情形的方法很简单:干脆就一次查找字典里面的2个表,一个临时扩容,一个就是主要的dict。 免得中间的状态基本无法维护;所以这种情况下,redis会先扫描数据项小一点的表,然后就扫描大的表,将其2份数据和在一起返回给客户端。这样简单粗暴,但绝对靠谱。这种情况下,是不会出现丢数据,和重复的情况的。
但从dictScan 函数里面可以看到,为了处理rehashing,里面对于大点的表的处理有一个比较关键的地方,如下代码:
1 |
/* Iterate over indices in larger table that are the expansion |
2 |
* of the index pointed to by the cursor in the smaller table */ |
3 |
do {//扫描大点的表里面的槽位,注意这里是个循环,会将小表没有覆盖的slot全部扫描一次的 |
4 |
/* Emit entries at cursor */ |
5 |
de = t1->table[v & m1]; |
11 |
/* Increment bits not covered by the smaller mask */ |
12 |
//下面的意思是,还需要扩展小点的表,将其后缀固定,然后看高位可以怎么扩充。 |
13 |
//其实就是想扫描一下小表里面的元素可能会扩充到哪些地方,需要将那些地方处理一遍。 |
14 |
//后面的(v & m0)是保留v在小表里面的后缀。 |
15 |
//((v | m0) + 1) & ~m0) 是想给v的扩展部分的二进制位不断的加1,来造成高位不断增加的效果。 |
16 |
v = (((v | m0) + 1) & ~m0) | (v & m0); |
18 |
/* Continue while bits covered by mask difference is non-zero */ |
19 |
} while (v & (m0 ^ m1));//终止条件是 v的高位区别位没有1了,其实就是说到头了。 |
上面的代码是个do-while循环,终止条件是游标v与 m0和m1的不同的位 之间没有相同的二进制位了。这里我们知道m0和m1一定都是低位全部为1的,因为字典大小为2^N。这样m0^m1的异或结果就是m1的相对m0超过的高位部分,打个比方,第一个ht表的大小为8,第二个为64, 那么m0 == 0000 0111, m1 == 0011 1111 , m0^m1 的结果是: 0011 1000,如下图:

其实就是想扫描m1和m0相差的那些高位。可能有人不禁会问,这个相差的高位不是只有1位么?其实不是的,rehashing的时候是可能2个表相差很大的。比如8 和64 。
上面do-while的前面部分是遍历第一个slot,小一点的。其实redis这里不管rehashing的方向,只管大小,反过来也是一样的。简化了逻辑;扫描完小一点的表后,需要将大一点的表进行扫描。
那么需要扫描哪些呢?答案是:所有可能从当前的小表的游标v所指的slot扩展迁移过去的slot,都需要扫描。比如当前的游标v等于0, 小表大小为8,大的表为64,那么需要扫描大表的这几个位置:0, 8, 16, 32。 原因是因为可能t0(小表)里面的一部分元素已经发生了迁移,仅仅扫描t0不够,还要扫描哪些可能的迁移目的地(来源,一样的)。如下所示,t0到t1大小从8变化到64之后,原来在0号slot的元素可能会迁移到了0, 8, 16, 24,32这几个t1的slot中。所以我们需要扫描这几个槽位,一次将其返回给客户端,免得夜长梦多,下次找不到地方了。

仔细观察可以发现,,他们都有个共同特点,从其二进制位中可以看出来:

也就是低位总是跟dictScan的参数v一样,高位从0开始不断加1 遍历,其实就是形成同模的效果,后缀一样,前缀不断变化加1,达到扫描所有可能的迁移slot,将其遍历返回给客户端。
这个遍历最主要的一行就是:
v = (((v | m0) + 1) & ~m0) | (v & m0);
下面简单分析一下它到底干了什么:
前面部分:(((v | m0) + 1) & ~m0) , v|m0就是将v的低位全部设置为1(这里所说的低位指t0的mask覆盖的位,高位指m1相对于m0独有的位。((v | m0) + 1)后面的+1 就是将(v | m0) 的值加1,也就是给v的高位部分加1。
后面的& ~m0效果就是去掉v的前面的二进制位。最后的(v & m0) 其实就是提取出v的低位部分。两边或起来,其实语义就是:保留v的低位,高位不断加1,赋值给v;这样V能带着低位不变,高位每次加1。高明!
这下清楚了,rehashing的时候会返回t0的槽位,以及t1里面所有可能发生迁移到的槽位。
总结
1. redis的SCAN操作能够保证 一直没变动过的元素一定能够在扫描结束的之前返回给客户端,这一点在不同情况下都可以实现;
2. 当发生字典大小缩小的时候,如果接受到一个scan cursor, 游标位于高位为1的部分,那么会被有效位掩码给注释最高位,从而从重新读取之前已经访问过的元素,这种情况下回发生数据重复,但应该有限;
整体来看redis的SCAN操作是很不错的,能够在hash的数据结构里面提供比较稳定可靠的SCAN操作。
摘自博客:http://www.chenzhenianqing.cn/articles/1101.html, 我稍作改动某些原作者笔误!核心不变