hadoop(三)HDFS基础使用
一、HDFS前言
1、 设计思想
分而治之:将大文件,大批量文件,分布式的存放于大量服务器上。以便于采取分而治之的方式对海量数据进行运算分析
2、 在大数据系统架构中的应用
为各类分布式运算框架( MapReduce, Spark, Tez, Flink, …)提供数据存储服务
3、 重点概念: 数据块, 负载均衡, 心跳机制, 副本存放策略, 元数据/元数据管理, 安全 模式,机架感知…
二、HDFS相关概念和特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
1、 HDFS 中的文件在物理上是分块存储( block),块的大小可以通过配置参数( dfs.blocksize) 来规定,默认大小在 hadoop2.x 版本中是 128M,老版本中是 64M
2、 HDFS 文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形 如: hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
3、 目录结构及文件分块位置信息(元数据)的管理由 namenode 节点承担
——namenode 是 HDFS 集群主节点,负责维护整个 hdfs 文件系统的目录树,以及每一个路 径(文件)所对应的 block 块信息( block 的 id,及所在的 datanode 服务器)
4、 文件的各个 block 的存储管理由 datanode 节点承担
---- datanode 是 HDFS 集群从节点,每一个 block 都可以在多个 datanode 上存储多个副本(副 本数量也可以通过参数设置 dfs.replication,默认是 3)
5、 HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改,支持追加 (PS:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开 销大,成本太高)
三、HDFS优缺点:
HDFS优点:
高容错性
数据自动保存多个副本
副本丢失后,自动恢复
适合批处理
移动计算而非数据
数据位置暴露给计算框架
适合大数据处理
GB、 TB、甚至 PB 级数据
百万规模以上的文件数量
10K+节点规模
流式文件访问
一次性写入,多次读取
保证数据一致性
可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复机制
HDFS缺点:
不适于以下操作:
低延迟数据访问 : 比如毫秒级 低延迟与高吞吐率
小文件存取 : 占用 NameNode 大量内存 寻道时间超过读取时间
并发写入、文件随机修改: 一个文件只能有一个写者 仅支持 append
四、HDFS的shell操作
常用命令参数介绍:




五、HDFS的Java API操作
1、利用eclipse 查看HDFS集群的文件信息
(1)下载一个 eclipse 开发工具 eclipse-jee-luna-SR1-win32-x86_64.zip
(2) 解压到一个文件夹 C:\myProgram\eclipse
(3) 把 hadoop-eclipse-plugin-2.6.4.jar 放入到 eclipse/plugins 文件夹下
(4)双击启动 eclipse
(5) 将 无 jar 版 windows 平台 hadoop-2.6.1.zip 解压到 windows 系统下一个文件夹下,文件 夹的路径最好不要带中文。我的目录是: C:\myProgram\hadoop-2.6.1
(6) 打开了 eclipse 之后, 点击 windows –> prefrences -> 会出现一个对话框。找到如图所示 Hadoop MapReduce 选项: 然后把你安装的 hadoop 路径配置上,就是上一步你解压的那 个文件夹: C:\myProgram\hadoop-2.6.1,然后保存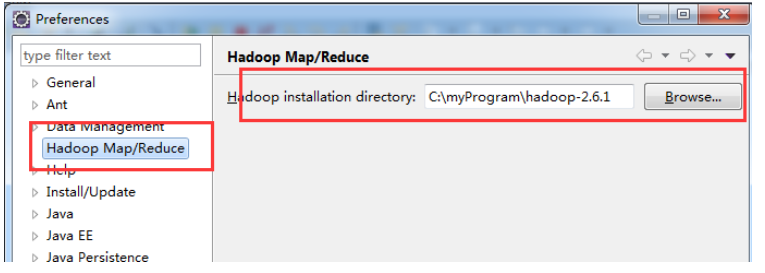
(注意的是如果 C:\myProgram\hadoop-2.6.1下还有一层文件就是hadoop-2.6.1,要写到C:\myProgram\hadoop-2.6.1\hadoop-2.6.1)
(7) 然后点击 windows show view other 在列表中找到图中这个东西: 然后双击
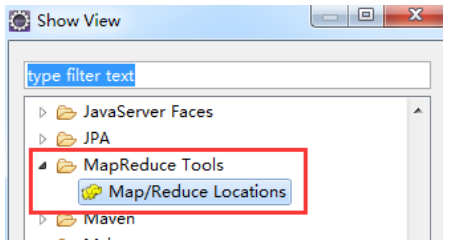
(8)然后会出现这么一个显示框

(9)咱们点击红框中这个东西,会出现相应的这么一个对话框,修改相应的信息,
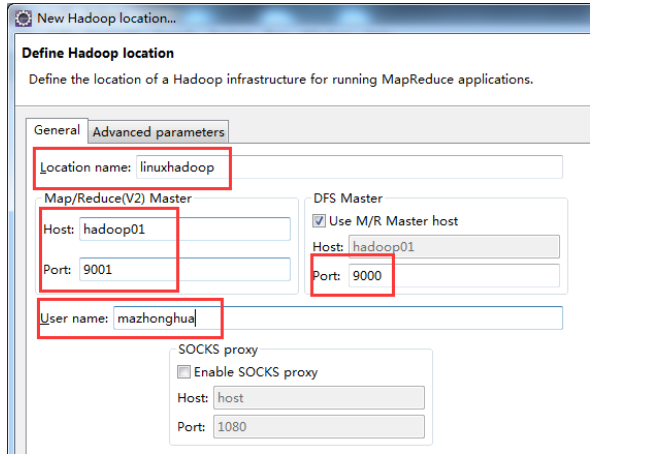
(10)填完以上信息之后,点击 finish 会出现:

(11)最重要的时候在左上角的这个地方会出现:
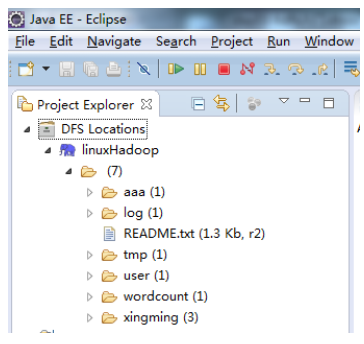
至此,我们便完成了,利用 hadoop 的 eclipse 插件链接 hdfs 集群实现查看 hdfs 集群文件的 功能,大功告成。
2、搭建开发环境
创建Java project ,导入操作HDFS的jar包,导入的jar包有:
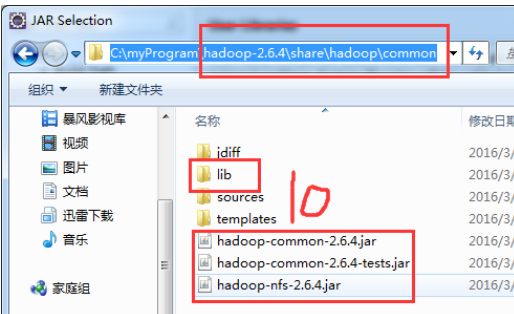

3、FileSystem实例获取讲解
在 java 中操作 hdfs,首先要获得一个客户端实例:
Configuration conf = new Configuration()
FileSystem fs = FileSystem.get(conf)
而我们的操作目标是 HDFS,所以获取到的 fs 对象应该是 DistributedFileSystem 的实例; get 方法是从何处判断具体实例化那种客户端类呢?
——从 conf 中的一个参数 fs.defaultFS 的配置值判断;
如果我们的代码中没有指定 fs.defaultFS,并且工程 classpath 下也没有给定相应的配置, conf 中的默认值就来自于 hadoop 的 jar 包中的 core-default.xml,默认值为: file:///,则获取的 将不是一个 DistributedFileSystem 的实例,而是一个本地文件系统的客户端对象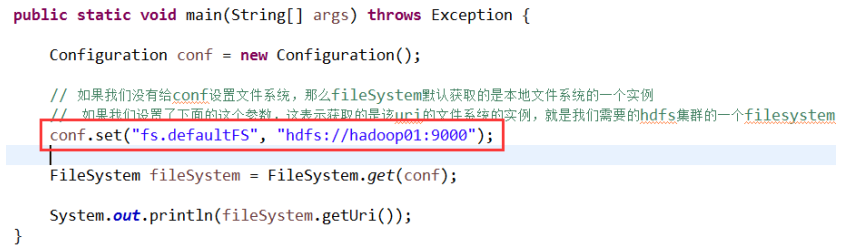
4、HDFS常用Java API演示
- package com.ghgj.hdfs;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.BlockLocation;
- import org.apache.hadoop.fs.FileStatus;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.LocatedFileStatus;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.fs.RemoteIterator;
- public class HDFSDemo {
- static FileSystem fs = null;
- static Configuration conf = null;
- public static void main(String[] args) throws Exception {
- init();
- // testMkdirs();
- // testPut();
- // testGet();
- // testConf();
- // testDelete();
- // testRename();
- // testList();
- close();
- }
- public static void testConf(){
- /**
- * 给我们要操作的hdfs集群设置配置信息的方式有三种:
- * 第一种:通过代码,用conf.set()
- * 第二种:直接接在jar里面所携带的默认的core-default.xml
- * 第三种:加载我们项目自带的关于集群配置相关的xml
- */
- /**
- * 1 > 3 > 2 加载级别高低,也就是谁后生效
- * 加载顺序:默认配置 , 集群安装配置=项目配置文件, 代码里面设置的配置信息
- */
- String fileSystem = conf.get("fs.defaultFS");
- String string = conf.get("dfs.replication");
- System.out.println(fileSystem);
- System.out.println(string);
- // conf.addResource(new Path("./myxmltext.xml"));
- // conf.addResource("myxmltext.xml");
- // System.out.println(conf.get("myname"));
- }
- /**
- * 初始化fs链接
- * @throws IOException
- */
- public static void init() throws IOException{
- conf = new Configuration();
- conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
- System.setProperty("HADOOP_USER_NAME", "hadoop");
- fs = FileSystem.get(conf);
- }
- /**
- * 关闭fs链接
- * @throws IOException
- */
- public static void close() throws IOException{
- fs.close();
- }
- /**
- * 删除文件夹或者文件
- * @throws IOException
- */
- public static void testDelete() throws IOException{
- fs.delete(new Path("/abcd"), true);
- }
- /**
- * 重命名
- * @throws IOException
- */
- public static void testRename() throws IOException{
- fs.rename(new Path("/txt1.txt"), new Path("/huangbo.txt"));
- }
- /**
- * 遍历文件
- * @throws IOException
- */
- public static void testList() throws IOException{
- // 遍历某个路径下所有的文件节点。包括文件和文件夹
- /*FileStatus[] listStatus = fs.listStatus(new Path("/"));
- for(FileStatus fss: listStatus){
- boolean directory = fss.isDirectory();
- if(directory){
- System.out.println(fss.getPath()+" -- 文件夹");
- }else{
- System.out.println(fss.getPath()+" -- 文件");
- }
- }*/
- // 只遍历文件
- RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
- while(listFiles.hasNext()){
- LocatedFileStatus next = listFiles.next();
- boolean directory = next.isDirectory();
- // next.getBlockSize()
- BlockLocation[] blockLocations = next.getBlockLocations();
- for(BlockLocation bl: blockLocations){
- String[] hosts = bl.getHosts();
- System.out.println("长度:"+bl.getLength());
- for(String s: hosts){
- System.out.print(s + "\t");
- }
- System.out.println(next.getPath());
- }
- /*if(directory){
- System.out.println(next.getPath()+" -- 文件夹"+ blockLocations.length);
- }else{
- System.out.println(next.getPath()+" -- 文件"+ blockLocations.length);
- }*/
- }
- }
- /**
- * s上传文件
- * @throws IOException
- */
- public static void testMkdirs() throws IOException{
- boolean mkdirs = fs.mkdirs(new Path("/abcd/nnn/mmm/uuu/jjj"));
- System.out.println(mkdirs);
- }
- /**
- * 上传文件
- * @throws IOException
- */
- public static void testPut() throws IOException{
- fs.copyFromLocalFile(new Path("C:/wdata/student.txt"), new Path("/abcd"));
- }
- /**
- * 下载文件
- * @throws IOException
- */
- public static void testGet() throws IOException{
- fs.copyToLocalFile(new Path("/abcd/student.txt"), new Path("C:/ss.txt"));
- System.out.println("is done");
- }
- }
5、HDFS流式数据访问
相对那些封装好的方法而言的更底层一些的操作方式 上层那些 mapreduce spark 等运算 框架,去 hdfs 中获取数据的时候,就是调的这种底层的 api
- package com.ghgj.hdfs;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FSDataOutputStream;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IOUtils;
- public class TestHDFSStream {
- static Configuration conf = null;
- static FileSystem fs = null;
- public static void main(String[] args) throws Exception {
- init();
- // getHDFSFileByStream();
- putFileToHDFS();
- close();
- }
- /**
- * 通过流的方式,去HDFS上下载一个文件下来
- * 实现思路:
- * 1、利用一个输入流读取该文件的数据
- * FSI = fs.open(path);
- * 2、......
- * 3、获取文件输出流,把输入流的数据给存到本地
- */
- public static void getHDFSFileByStream() throws Exception{
- // 获取数据输入流
- Path path = new Path("hdfs://hadoop02:9000/hadoop-2.6.4-centos-6.5.tar.gz");
- FSDataInputStream open = fs.open(path);
- // 获取文件输出流
- FileOutputStream fos = new FileOutputStream(new File("c:/myhadoop.txt"));
- // 作用:让输入流和输出流对接,进行数据的传输(复制)
- // IOUtils.copyBytes(open, fos, conf);
- IOUtils.copyBytes(open, fos, conf.getInt("io.file.buffer.size", 4096), true);
- }
- /**
- * 实现思路:
- * 1、获取一个本地文件的输入流
- * 2、、、
- * 3、在hdfs的客户端创建一个输出流,把输入流上的数据复制到hdfs文件系统里面去
- */
- public static void putFileToHDFS() throws Exception{
- // 获取一个本地文件的输入流
- FileInputStream fin = new FileInputStream(new File("c:/myhadoop.txt"));
- // 准备一个hdfs的输出流
- Path path = new Path("/myhadoop.tar.gz");
- FSDataOutputStream create = fs.create(path);
- IOUtils.copyBytes(fin, create, conf);
- }
- public static void init() throws Exception{
- conf = new Configuration();
- conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
- System.setProperty("HADOOP_USER_NAME","hadoop");
- fs = FileSystem.get(conf);
- }
- public static void close() throws Exception{
- fs.close();
- }
- }
经典案例:
在 mapreduce 、 spark 等运算框架中,有一个核心思想就是将运算移往数据,或者说,就是 要在并发计算中尽可能让运算本地化,这就需要获取数据所在位置的信息并进行相应范围读 取。 以下模拟实现:获取一个文件的所有 block 位置信息,然后读取指定 block 中的内容
- @Test
- public void testCat() throws IllegalArgumentException, IOException {
- FSDataInputStream in = fs.open(new Path("/weblog/input/access.log.10"));
- // 拿到文件信息
- FileStatus[] listStatus = fs.listStatus(new Path(
- "/weblog/input/access.log.10"));
- // 获取这个文件的所有 block 的信息
- BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(
- listStatus[0], 0L, listStatus[0].getLen());
- // 第一个 block 的长度
- long length = fileBlockLocations[0].getLength();
- // 第一个 block 的起始偏移量
- long offset = fileBlockLocations[0].getOffset();
- System.out.println(length);
- System.out.println(offset);
- // 获取第一个 block 写入输出流
- // IOUtils.copyBytes(in, System.out, (int)length);
- byte[] b = new byte[4096];
- FileOutputStream os = new FileOutputStream(new File("d:/block0"));
- while (in.read(offset, b, 0, 4096) != -1) {
- os.write(b);
- offset += 4096;
- if (offset > length)
- return;
- }
- os.flush();
- os.close();
- in.close();
- }
案例:
- package com.ghgj.hdfs;
- import java.io.File;
- import java.io.FileOutputStream;
- import java.net.URI;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.BlockLocation;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FileStatus;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IOUtils;
- public class TestRandomStream {
- public static void main(String[] args) throws Exception {
- // testSeek();
- getSecondBlock();
- }
- /**
- * 通过HDFS api 取到对应数据对应数据块的数据
- * 作用:
- * @throws Exception
- */
- public static void getSecondBlock() throws Exception{
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get(new URI("hdfs://hadoop02:9000"), conf, "hadoop");
- FSDataInputStream open = fs.open(new Path("/hadoop-2.6.4-centos-6.5.tar.gz"));
- // 134217728
- // 46595337
- long offset = 0;
- long length = 0;
- FileStatus[] listStatus = fs.listStatus(new Path("/hadoop-2.6.4-centos-6.5.tar.gz"));
- length = listStatus[0].getLen();
- BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(listStatus[0], 0, length);
- // 想要获取到hadoop安装包第二块数据的数据块的起始偏移量
- offset = fileBlockLocations[1].getOffset();
- // 设置起始偏移量
- open.seek(offset);
- long seekLength = fileBlockLocations[1].getLength();
- System.out.println(offset+"\t"+seekLength);
- // 构建文件输出流
- FileOutputStream fout = new FileOutputStream(new File("c:/secondHadoop.tar.gz"));
- // 把输入流数据,复制到输出流
- IOUtils.copyBytes(open, fout, seekLength, true);
- fs.close();
- }
- /**
- * 从随机位置offset读取任意长度length的数据
- * @throws Exception
- */
- public static void testSeek() throws Exception{
- Configuration conf = new Configuration();
- // System.setProperty("HADOOP_USER_NAME", "hadoop");
- FileSystem fs = FileSystem.get(new URI("hdfs://hadoop02:9000"), conf, "hadoop");
- FSDataInputStream open = fs.open(new Path("hdfs://hadoop02:9000/shuzi.txt"));
- long offset = 12;
- long length = 23L;
- // 设置起始偏移量
- open.seek(offset);
- FileOutputStream fout = new FileOutputStream(new File("c:/myshuzi.txt"));
- // 注意第三个参数:它是long类型。表示取数据的长度
- IOUtils.copyBytes(open, fout, length, true);
- fs.close();
- }
- }
hadoop(三)HDFS基础使用的更多相关文章
- 每天收获一点点------Hadoop之HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop系列-HDFS基础
基本原理 HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方: 数据分块存储在多台主机 数据块采取冗余 ...
- hadoop(三):hdfs 机架感知
client 向 Active NN 发送写请求时,NN为这些数据分配DN地址,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影响.一个简单但非优化的副本放置策略是,把副本分别放在不同机架 ...
- Hadoop(1): HDFS基础架构
1. What's HDFS? Hadoop Distributed File System is a block-structured file system where each file is ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- 零基础学习hadoop开发所必须具体的三个基础知识
大数据hadoop无疑是当前互联网领域受关注热度最高的词之一,大数据技术的应用正在潜移默化中对我们的生活和工作产生巨大的改变.这种改变给我们的感觉是“水到渠成”,更为让人惊叹的是大数据已经仅仅是互联网 ...
- hadoop - hdfs 基础操作
hdfs --help # 所有参数 hdfs dfs -help # 运行文件系统命令在Hadoop文件系统 hdfs dfs -ls /logs # 查看 hdfs dfs -ls /user/ ...
- 非常不错 Hadoop 的HDFS (Hadoop集群(第8期)_HDFS初探之旅)
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- 快速学习hadoop只有这些基础可不行
“学习hadoop需要什么基础”这已经不是一个新鲜的话题了,随便上网搜索一下就能找出成百上千篇的文章在讲学习hadoop需要掌握的基础.再直接的一点的问题就是——学Hadoop难吗?用一句特别让人无语 ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
随机推荐
- Android 不同分辨率下调整界面
Android Settings中有修改Disaply size的界面,通过修改Display size,能够修改屏幕分辨率. 由于修改了屏幕分辨率,有可能导致同一界面在不同的分辨率下显示出错(内容显 ...
- xampp服务器搭建和使用
1.安装完XAMPP后会出现Apache端口被占用的问题,一下方法解决 错误信息如下: Error: Apache shutdown unexpectedly. 9:37:01 [Apache] T ...
- 一学就会pip换镜像源
首先介绍一个国内好用的镜像站 阿里云 http://mirrors.aliyun.com/pypi/simple/ 豆瓣 http://pypi.douban.com/simple/ 清华大学 htt ...
- Fulfilling Work: The Shippers More entrepreneurs hire 'fulfillment' outfits to store and ship their products
By Stu Woo June 23, 2011 Brett Teper faced a logistical problem when he and a partner founded ModPro ...
- Alpha阶段中间产物——GUI Prototype、WBS及PSP
作业地址:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/1224 内容: GUI Prototype 我的书架 我的书架→添加图书 ...
- 模仿qq列表信息滑动删除效果
这个效果的完成主要分为两个部分 自定义view作为listview的列表项 一个view里面包括 显示头像,名字,消息内容等的contentView和滑动才能显示出来的删除,置顶的右边菜单menuVi ...
- YQCB项目介绍
YQCB记账本软件 制作人:YQCB团队 团队简介:团队成立于2017年11月21日,由陈美琪,张晨阳,邢全阳,刘昭为四人组成. 陈美琪:团队灵魂人物,背负着巨大的压力带起整个团队. 张晨阳:团队领军 ...
- 第一阶段android学习笔记
1.学习<第一行代码> 第一个android项目: 项目的注意点,如创建项目时包名具有唯一性,在做项目的时候要手动改成Project模式.还知道了引用字符串的两种方式. AS项目的三种依赖 ...
- Jquery获取属性值
jq获取某个标签内的属性值:$("#TeamPerformanceYearUl li:eq(0)").attr('data') jq获取li或者td第一个属性(索引值从零开始)$( ...
- React Native 学习-组件说明和生命周期
组件的详细说明(Component Specifications) 当通过调用 React.createClass() 来创建组件的时候,你应该提供一个包含 render 方法的对象,并且也可以包含其 ...