hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令;业务系统中日志生成机制,HDFS的java客户端api基本使用。
1、什么是大数据
基本概念
《数据处理》
在互联网技术发展到现今阶段,大量日常、工作等事务产生的数据都已经信息化,人类产生的数据量相比以前有了爆炸式的增长,以前的传统的数据处理技术已经无法胜任,需求催生技术,一套用来处理海量数据的软件工具应运而生,这就是大数据!
处理海量数据的核心技术:
海量数据存储:分布式
海量数据运算:分布式
大数据的海量数据的存储和运算,核心技术就是分布式。
这些核心技术的实现是不需要用户从零开始造轮子的
存储和运算,都已经有大量的成熟的框架来用
存储框架:
HDFS——分布式文件存储系统(HADOOP中的存储框架)
HBASE——分布式数据库系统
KAFKA——分布式消息缓存系统(实时流式数据处理场景中应用广泛)
文件系统中的数据以非结构化居多,没有直观的结构,数据库中的信息多以表的形式存在,具有结构化,存在规律;
查询的时候文本文件只能一行一行扫描,而数据库效率高很多,可以利用sql查询语法,数据库在存和取方便的多。
数据库和文件系统相比,数据库相当于在特定的文件系统上的软件封装。其实HBASE就是对HDFS的进一层封装,它的底层文件系统就是HDFS。
分布式消息缓存系统,既然是分布式,那就意味着横跨很多机器,意味着容量可以很大。和前两者相比它的数据存储形式是消息(不是表,也不是文件),消息可以看做有固定格式的一条数据,比如消息头,消息体等,消息体可以是json,数据库的一条记录,一个序列化对象等。消息最终存放在kafaka内部的特定的文件系统里。
运算框架:(要解决的核心问题就是帮用户将处理逻辑在很多机器上并行)
MAPREDUCE—— 离线批处理/HADOOP中的运算框架
SPARK —— 离线批处理/实时流式计算
STORM —— 实时流式计算
离线批处理:数据是静态的,一次处理一大批数据。
实时流式:数据在源源不断的生成,边生成,边计算
这些运算框架的思想都差不多,特别是mapreduce和spark,简单来看spark是对mapreduce的进一步封装;
运算框架和存储框架之间没有强耦合关系,spark可以读HDFS,HBASE,KAFKA里的数据,当然需要存储框架提供访问接口。
辅助类的工具(解放大数据工程师的一些繁琐工作):
HIVE —— 数据仓库工具:可以接收sql,翻译成mapreduce或者spark程序运行
FLUME——数据采集
SQOOP——数据迁移
ELASTIC SEARCH —— 分布式的搜索引擎
flume用于自动采集数据源机器上的数据到大数据集群中。
HIVE看起来像一个数据库,但其实不是,Hive中存了一些需要分析的数据,然后在直接写sql进行分析,hive接收sql,翻译成mapreduce或者spark程序运行;
hive本质是mapreduce或spark,我们只需要写sql逻辑而不是mapreduce逻辑,Hive自动完成对sql的翻译,而且还是在海量数据集上。
.......
换个角度说,大数据是:
1、有海量的数据
2、有对海量数据进行挖掘的需求
3、有对海量数据进行挖掘的软件工具(hadoop、spark、storm、flink、tez、impala......)
大数据在现实生活中的具体应用
数据处理的最典型应用:公司的产品运营情况分析
电商推荐系统:基于海量的浏览行为、购物行为数据,进行大量的算法模型的运算,得出各类推荐结论,以供电商网站页面来为用户进行商品推荐
精准广告推送系统:基于海量的互联网用户的各类数据,统计分析,进行用户画像(得到用户的各种属性标签),然后可以为广告主进行有针对性的精准的广告投放
2、什么是hadoop
hadoop中有3个核心组件:
分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上
分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运算
分布式资源调度平台:YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
3、hdfs整体运行机制
hdfs:分布式文件系统
hdfs有着文件系统共同的特征:
1、有目录结构,顶层目录是: /
2、系统中存放的就是文件
3、系统可以提供对文件的:创建、删除、修改、查看、移动等功能
hdfs跟普通的单机文件系统有区别:
1、单机文件系统中存放的文件,是在一台机器的操作系统中
2、hdfs的文件系统会横跨N多的机器
3、单机文件系统中存放的文件,是在一台机器的磁盘上
4、hdfs文件系统中存放的文件,是落在n多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统)
hdfs的工作机制:
1、客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:data node)<准确来说:切块的行为是由客户端决定的>
2、一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node)
3、为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本(到底存几个副本,是由当时存入该文件的客户端指定的)
综述:一个hdfs系统,由一台运行了namenode的服务器,和N台运行了datanode的服务器组成!
4、搭建hdfs分布式集群
4.1 hdfs集群组成结构:

4.2 安装hdfs集群的具体步骤:
4.2.1、首先需要准备N台linux服务器
学习阶段,用虚拟机即可!
先准备4台虚拟机:1个namenode节点 + 3 个datanode 节点
4.2.2、修改各台机器的主机名和ip地址
主机名:hdp-01 对应的ip地址:192.168.33.11
主机名:hdp-02 对应的ip地址:192.168.33.12
主机名:hdp-03 对应的ip地址:192.168.33.13
主机名:hdp-04 对应的ip地址:192.168.33.14
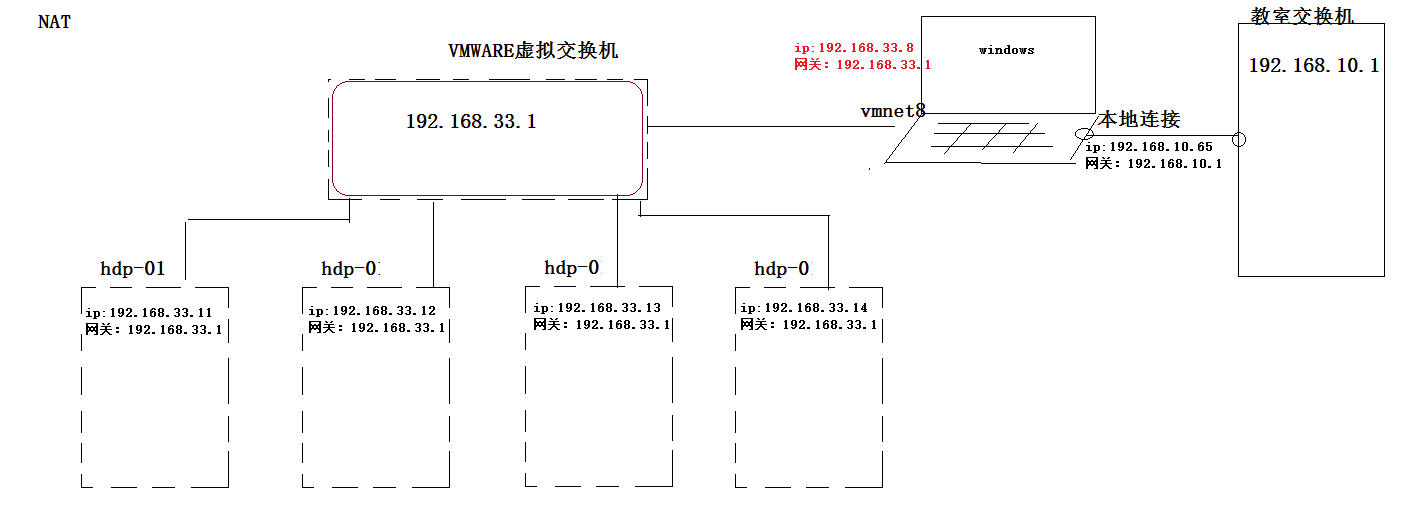
4.2.3、从windows中用CRT软件进行远程连接
在windows中将各台linux机器的主机名配置到的windows的本地域名映射文件中:
c:/windows/system32/drivers/etc/hosts
|
192.168.33.11 hdp-01 192.168.33.12 hdp-02 192.168.33.13 hdp-03 192.168.33.14 hdp-04 |
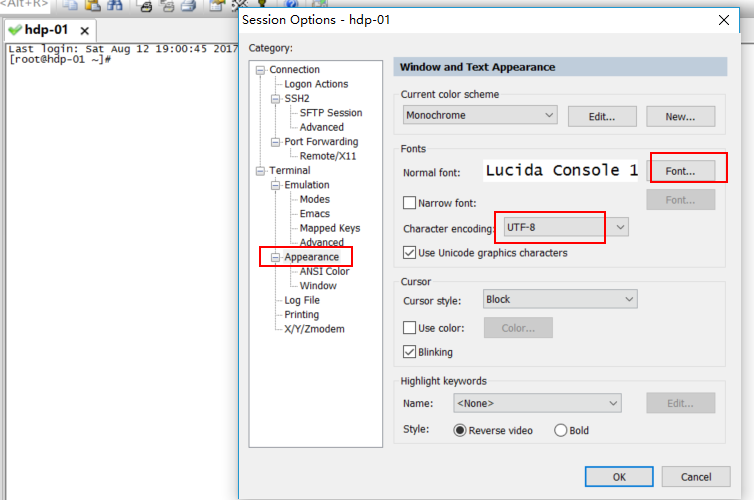
用crt连接上后,修改一下crt的显示配置(字号,编码集改为UTF-8):
4.2.3、配置linux服务器的基础软件环境
- 防火墙
关闭防火墙:service iptables stop
关闭防火墙自启: chkconfig iptables off
- 安装jdk:(hadoop体系中的各软件都是java开发的)
1) 利用alt+p 打开sftp窗口,然后将jdk压缩包拖入sftp窗口
2) 然后在linux中将jdk压缩包解压到/root/apps 下
3) 配置环境变量:JAVA_HOME PATH
vi /etc/profile 在文件的最后,加入:
export JAVA_HOME=/root/apps/jdk1..0_60 export PATH=$PATH:$JAVA_HOME/bin
4) 修改完成后,记得 source /etc/profile使配置生效
5) 检验:在任意目录下输入命令: java -version 看是否成功执行
6) 将安装好的jdk目录用scp命令拷贝到其他机器
7) 将/etc/profile配置文件也用scp命令拷贝到其他机器并分别执行source命令
- 集群内主机的域名映射配置
在hdp-01上,vi /etc/hosts
|
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.33.11 hdp-01 192.168.33.12 hdp-02 192.168.33.13 hdp-03 192.168.33.14 hdp-04 |
然后,将hosts文件拷贝到集群中的所有其他机器上
scp /etc/hosts hdp-02:/etc/
scp /etc/hosts hdp-03:/etc/
scp /etc/hosts hdp-04:/etc/
|
补 充 提示: |
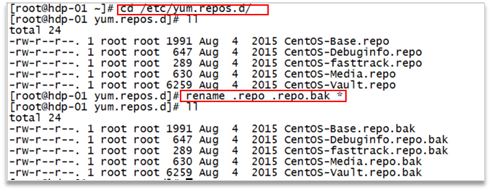
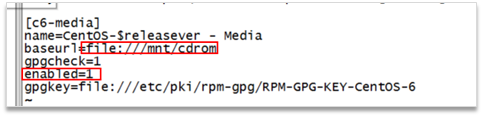
如果在执行scp命令的时候,提示没有scp命令,则可以配置一个本地yum源来安装 1、先在虚拟机中配置cdrom为一个centos的安装镜像iso文件 2、在linux系统中将光驱挂在到文件系统中(某个目录) 3、mkdir /mnt/cdrom 4、mount -t iso9660 -o loop /dev/cdrom /mnt/cdrom 5、检验挂载是否成功: ls /mnt/cdrom 6、3、配置yum的仓库地址配置文件 7、yum的仓库地址配置文件目录: /etc/yum.repos.d 8、先将自带的仓库地址配置文件批量更名:
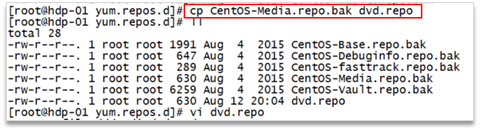
9、然后,拷贝一个出来进行修改
10、修改完配置文件后,再安装scp命令: 11、yum install openssh-clients -y |
4.2.4、安装hdfs集群
1、上传hadoop安装包到hdp-01
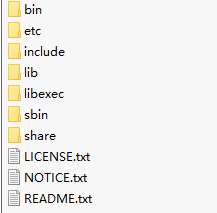
bin文件为hadoop功能命令,sbin中为集群管理命令。
2、修改配置文件
|
要 点 提 示 |
核心配置参数: 1) 指定hadoop的默认文件系统为:hdfs 2) 指定hdfs的namenode节点为哪台机器 3) 指定namenode软件存储元数据的本地目录 4) 指定datanode软件存放文件块的本地目录 |
hadoop的配置文件在:/root/apps/hadoop安装目录/etc/hadoop/
hadoop中的其他组件如mapreduce,yarn等,这些组将会去读数据,指定hadoop的默认文件系统为:hdfs,就是告诉这些组件去hdfs中读数据;该项配置意味dadoop中的组件可以访问各种文件系统。
若不指定数据的存放目录,hadoop默认将数据存放在/temp下。
可以参考官网的默认配置信息。
1) 修改hadoop-env.sh
export JAVA_HOME=/root/apps/jdk1..0_60
2) 修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-01:9000/</value> </property> </configuration>
<value>hdfs://hdp-01:9000</value>包含两层意思:
1、指定默认的文件系统。
2、指明了namenode是谁。
value中的值是URI风格

3) 修改hdfs-site.xml
配置namenode和datanode的工作目录,添加secondary name node。
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/root/hdpdata/name/</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/root/hdpdata/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hdp-02:50090</value> </property> </configuration>
4) 拷贝整个hadoop安装目录到其他机器
scp -r /root/apps/hadoop-2.8. hdp-:/root/apps/ scp -r /root/apps/hadoop-2.8. hdp-:/root/apps/ scp -r /root/apps/hadoop-2.8. hdp-:/root/apps/
5) 启动HDFS
所谓的启动HDFS,就是在对的机器上启动对的软件
|
要 点 提示: |
要运行hadoop的命令,需要在linux环境中配置HADOOP_HOME和PATH环境变量 vi /etc/profile
|
首先,初始化namenode的元数据目录
要在hdp-01上执行hadoop的一个命令来初始化namenode的元数据存储目录
hadoop namenode -format
创建一个全新的元数据存储目录
生成记录元数据的文件fsimage
生成集群的相关标识:如:集群id——clusterID
该步骤叫做namenode的初始化也叫格式化,本质是建立namenode运行所需要的目录以及一些必要的文件,所以该操作一般只在集群第一次启动之前执行。
然后,启动namenode进程(在hdp-01上)
hadoop-daemon.sh start namenode
启动完后,首先用jps查看一下namenode的进程是否存在
namenode就是一个java软件,我们知道启动一个java软件需要主类的main方法 java xxx.java - 若干参数,处于方便的考虑,hadoop中提供了一个通用的软件启动脚本hadoop-daemon.sh,脚本可以接受参数,专门用来启动hadoop中的软件。

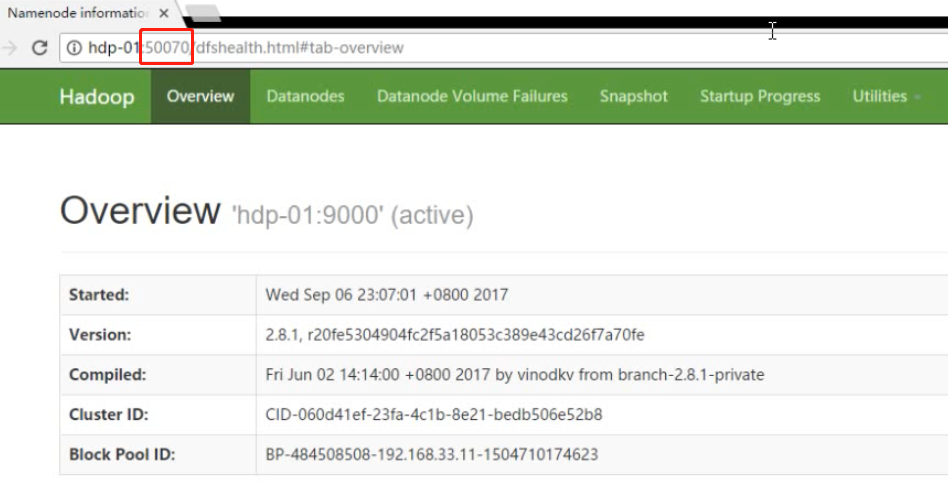
可以看到namenode在监听两个端口,9000用来和客户端通信(9000为RPC端口号,内部进程之间互相通信的端口,datanode和namenode的通信),接受hdfs客户端的请求,50070是web服务端口,也就是说namenode内置一个web服务器,http客户端可以通过次端口发送请求。
然后,在windows中用浏览器访问namenode提供的web端口:50070
http://hdp-01:50070
然后,启动众datanode们(在任意地方)
hadoop-daemon.sh start datanode
下图是datanode的一下信息展示,可以看到datanode内部通信的端口号是50010,而且datanode也提供了问访问端口50075.


6) 用自动批量启动脚本来启动HDFS
hdfs其实就是一堆java软件,我们可以自己手动hadoop-daemon.sh逐个启动,也可以使用hadoop提供的批量启动脚本。
1) 先配置hdp-01到集群中所有机器(包含自己)的免密登陆
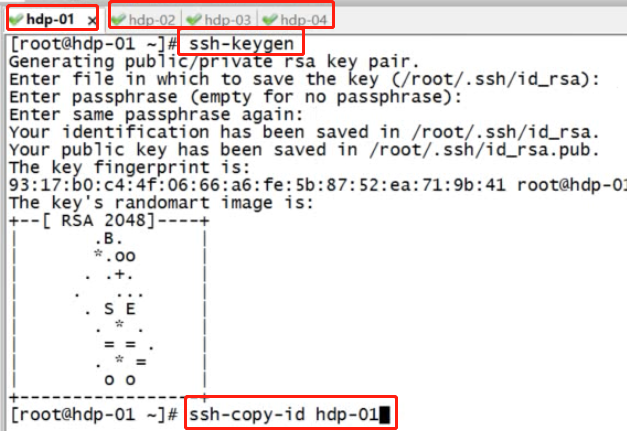
2) 配完免密后,可以执行一次 ssh 0.0.0.0
3) 修改hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入)
|
hdp-01 hdp-02 hdp-03 hdp-04 |
core-site.xml中配置过namenode,但是需要批量启动那些datanode呢,该文件/etc/hadoop/slaves的配置就是解决这个问题的,该文件就是给启动脚本看的。
4) 在hdp-01上用脚本:start-dfs.sh 来自动启动整个集群
5) 如果要停止,则用脚本:stop-dfs.sh
start-dfs.sh、stop-dfs.sh会启动、关闭namenode,datanode和secondnamenode
当然你也可以自己写脚本来做上述的事情 ,如下所示。

5、hdfs的客户端操作
hdfs装好之后,接下来的工作就是hdfs里传东西,去东西,由客户端来完成。
5.1、客户端的理解
hdfs的客户端有多种形式:
1、网页形式
2、命令行形式
3、客户端在哪里运行,没有约束,只要运行客户端的机器能够跟hdfs集群联网们
对于客户端来讲,hdfs是一个整体,网页版的客户端主要是用来查看hdfs信息的,可以创建目录,但是需要权限


命令行客户端
bin命令中的 hadoop 和 hdfs 都可以启动 hdfs 客户端,hadoop和hdfs都是脚本,都会去启动一个hdfs的java客户端。java客户端在安装包的jar包中
./hadoop fs -ls /
表示hadoop要访问hdfs,该脚本就会去启动hdfs客户端,客户端可以接收参数,比如查看hdfs根目录。
文件的切块大小和存储的副本数量,都是由客户端决定!
所谓的由客户端决定,是通过配置参数来定的
hdfs的客户端会读以下两个参数,来决定切块大小(默认128M)、副本数量(默认3):
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
如果使用命令行客户端时,上面两个参数应该配置在客户端机器的hadoop目录中的hdfs-site.xml中配置,(命令行客户端本质就是启动了一个java客户端,这个客户端在启动的时候会将它依赖的所有jar包加入classpath中,客户端会从jar包中,加载xx-default.xml来获得默认的配置文件,也可以在hadoop/etc/xxx-site.xml中配置具体的参数来覆盖默认值。此时的/etc下的配置文件就是客户自定义的配置文件,也会被java客户端加载【客户端可以运行在任何地方】);
当然也可以在具体代码中指定,见6节中的核心代码
<property>
<name>dfs.blocksize</name>
<value>64m</value>
</property> <property>
<name>dfs.replication</name>
<value>2</value>
</property>
5.1.1、上传过程
下图为datanode中的数据,.meta是该block的校验和信息。我们可以通过linux cat命令将两个块合并,会发现与原来的文件是一样的。
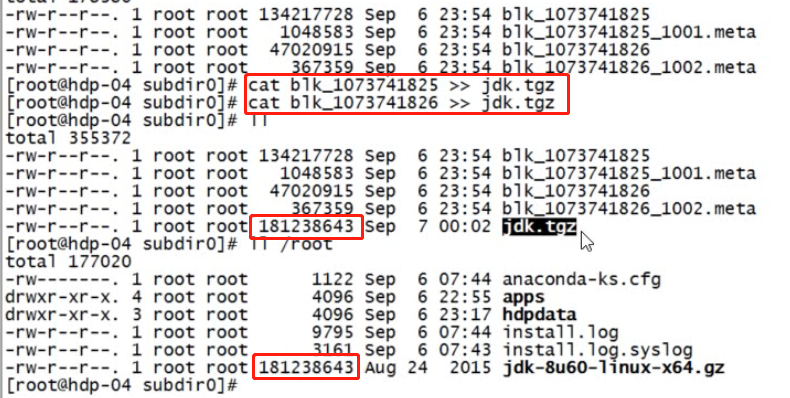
5.1.2、下载过程
客户端首先回去namenode上去查找,有没有请求的hdfs路径下的文件,有的话都有该文件被切割成几块,每块有几个副本,这些副本都存放在集群中的哪些机器上,然后去存放了第一块数据的某一台机器上去下载第一块数据,将数据追加到本地,然后去下载下一块数据,继续追加到本地文件,知道下载完所有的块。

5.2、hdfs客户端的常用操作命令
1、上传文件到hdfs中
hadoop fs -put /本地文件 /aaa
2、下载文件到客户端本地磁盘
hadoop fs -get /hdfs中的路径 /本地磁盘目录
3、在hdfs中创建文件夹
hadoop fs -mkdir -p /aaa/xxx
4、移动hdfs中的文件(更名)
hadoop fs -mv /hdfs的路径1 /hdfs的另一个路径2
复制hdfs中的文件到hdfs的另一个目录
hadoop fs -cp /hdfs路径_1 /hdfs路径_2
5、删除hdfs中的文件或文件夹
hadoop fs -rm -r /aaa
6、查看hdfs中的文本文件内容
hadoop fs -cat /demo.txt
hadoop fs -tail /demo.txt
hadoop fs -tail -f /demo.txt
hadoop fs -text /demo.txt
7、查看hdfs目录下有哪些文件
hadoop fs –ls /
8、追加本地文件到hdfs中的文件
hadoop fs -appendToFile 本地路径 /hdfs路径
9、权限修改
hadoop fs -chmod username1:usergroup1 /hdfs路径
要说明的是,hdfs中的用户和用户组这是一个名字称呼,与linux不一样,linux中不能将选线分配给一个不存在的用户。
可以查看hadoop fs 不带任何参数,来查看hdfs所支持的命令
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
6、hdfs的java客户端编程
HDFS客户端编程应用场景:数据采集
业务系统中日志生成机制
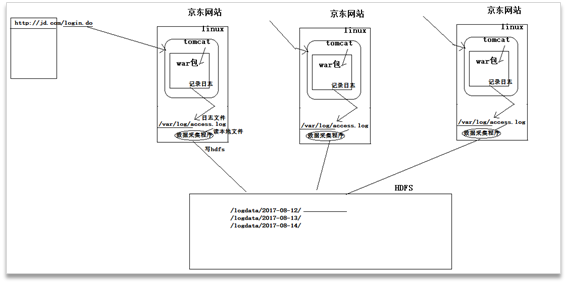
数据采集程序其实就是通过对java客户端编程,将数据不断的上传到hdfs。
在windows开发环境中做一些准备工作:
1、在windows的某个路径中解压一份windows版本的hadoop安装包
2、将解压出的hadoop目录配置到windows的环境变量中:HADOOP_HOME
原因:若不配置环境变量,会在下载hdfs文件是出错,是由于使用hadoop的FileSystem保存文件到本地的时候出于效率的考虑,会使用hadoop安装包中的c语言库,显然没有配置hadoop环境变量时是找不到该c语言类库中的文件的;然而上传文件到hdfs没有类似问题;
6.1、核心代码
1、将hdfs客户端开发所需的jar导入工程(jar包可在hadoop安装包中找到common和hdfs)
2、写代码
6.1.1、获取hdfs客户端
要点:要对hdfs中的文件进行操作,代码中首先需要获得一个hdfs的客户端对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"),conf,"root");
完整代码如下:
/**
* Configuration参数对象的机制:
* 构造时,会加载jar包中的默认配置 xx-default.xml(core-default.xmlhdfs-default.xml)
* 再加载 用户配置xx-site.xml ,覆盖掉默认参数
* 构造完成之后,还可以conf.set("p","v"),会再次覆盖用户配置文件中的参数值
*/
// new Configuration()会从项目的classpath中加载core-default.xml hdfs-default.xml core-site.xml hdfs-site.xml等文件
Configuration conf = new Configuration(); // 指定本客户端上传文件到hdfs时需要保存的副本数为:2
conf.set("dfs.replication", "2");
// 指定本客户端上传文件到hdfs时切块的规格大小:64M
conf.set("dfs.blocksize", "64m"); // 构造一个访问指定HDFS系统的客户端对象: 参数1:——HDFS系统的URI,参数2:——客户端要特别指定的参数,参数3:客户端的身份(用户名)
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000/"), conf, "root"); // 上传一个文件到HDFS中
fs.copyFromLocalFile(new Path("D:/install-pkgs/hbase-1.2.1-bin.tar.gz"), new Path("/aaa/")); fs.close();
6.1.2、对文件进行操作
上传、下载文件;文件夹的创建和删除、文件的移动和复制、查看文件夹和文件等。
3、利用fs对象的方法进行文件操作
方法均与命令行方法对应,比如:
上传文件
fs.copyFromLocalFile(new Path("本地路径"),new Path("hdfs的路径"));
下载文件
fs.copyToLocalFile(new Path("hdfs的路径"),new Path("本地路径"))
对文件的增删改查如下,对文件数据的操作后续介绍。
FileSystem fs = null;
@Before
public void init() throws Exception{
Configuration conf = new Configuration();
conf.set("dfs.replication", "2");
conf.set("dfs.blocksize", "64m");
fs = FileSystem.get(new URI("hdfs://hdp-01:9000/"), conf, "root");
}
/**
* 从HDFS中下载文件到客户端本地磁盘
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testGet() throws IllegalArgumentException, IOException{
fs.copyToLocalFile(new Path("/hdp20-05.txt"), new Path("f:/"));
fs.close();
}
/**
* 在hdfs内部移动文件\修改名称
*/
@Test
public void testRename() throws Exception{
fs.rename(new Path("/install.log"), new Path("/aaa/in.log"));
fs.close();
}
/**
* 在hdfs中创建文件夹
*/
@Test
public void testMkdir() throws Exception{
fs.mkdirs(new Path("/xx/yy/zz"));
fs.close();
}
/**
* 在hdfs中删除文件或文件夹
*/
@Test
public void testRm() throws Exception{
fs.delete(new Path("/aaa"), true);
fs.close();
}
/**
* 查询hdfs指定目录下的文件信息
*/
@Test
public void testLs() throws Exception{
// 只查询文件的信息,不返回文件夹的信息
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/"), true);
while(iter.hasNext()){
LocatedFileStatus status = iter.next();
System.out.println("文件全路径:"+status.getPath());
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication());
System.out.println("块信息:"+Arrays.toString(status.getBlockLocations()));
System.out.println("--------------------------------");
}
fs.close();
}
/**
* 查询hdfs指定目录下的文件和文件夹信息
*/
@Test
public void testLs2() throws Exception{
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus status:listStatus){
System.out.println("文件全路径:"+status.getPath());
System.out.println(status.isDirectory()?"这是文件夹":"这是文件");
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication());
System.out.println("--------------------------------");
}
fs.close();
}
6.1.3、对文件数据进行操作
同过客户端使用open打开流对象来读取hdfs中文件的具体数据,包括指定偏移量来读取特定范围的数据;通过客户端向hdfs文件追加数据。
/**
* 读取hdfs中的文件的内容
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testReadData() throws IllegalArgumentException, IOException { FSDataInputStream in = fs.open(new Path("/test.txt")); BufferedReader br = new BufferedReader(new InputStreamReader(in, "utf-8")); String line = null;
while ((line = br.readLine()) != null) {
System.out.println(line);
} br.close();
in.close();
fs.close(); } /**
* 读取hdfs中文件的指定偏移量范围的内容
*
*
* 作业题:用本例中的知识,实现读取一个文本文件中的指定BLOCK块中的所有数据
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testRandomReadData() throws IllegalArgumentException, IOException { FSDataInputStream in = fs.open(new Path("/xx.dat")); // 将读取的起始位置进行指定
in.seek(12); // 读16个字节
byte[] buf = new byte[16];
in.read(buf); System.out.println(new String(buf)); in.close();
fs.close(); }
写数据,create提供了丰富的重载函数,轻松实现覆盖,追加,以及指定缓存大小,副本数量等等信息。
/**
* 往hdfs中的文件写内容
*
* @throws IOException
* @throws IllegalArgumentException
*/ @Test
public void testWriteData() throws IllegalArgumentException, IOException { FSDataOutputStream out = fs.create(new Path("/zz.jpg"), false); // D:\images\006l0mbogy1fhehjb6ikoj30ku0ku76b.jpg FileInputStream in = new FileInputStream("D:/images/006l0mbogy1fhehjb6ikoj30ku0ku76b.jpg"); byte[] buf = new byte[1024];
int read = 0;
while ((read = in.read(buf)) != -1) {
out.write(buf,0,read);
} in.close();
out.close();
fs.close(); }
7、HDFS实例
hdfs版本wordcount程序。
任务描述:
1、从hdfs文件中读取数据,每次读取一行数据;
2、将数据交给具体的单词统计业务去作业(使用面向接口编程,当业务逻辑改变时,无需修改主程序代码);
3、并将该行数据产生的结果存入缓存中(可以用hashmap模拟)
数据采集设计:
1、流程
启动一个定时任务:
——定时探测日志源目录
——获取需要采集的文件
——移动这些文件到一个待上传临时目录
——遍历待上传目录中各文件,逐一传输到HDFS的目标路径,同时将传输完成的文件移动到备份目录
启动一个定时任务:
——探测备份目录中的备份数据,检查是否已超出最长备份时长,如果超出,则删除
2、规划各种路径
日志源路径: d:/logs/accesslog/
待上传临时目录: d:/logs/toupload/
备份目录: d:/logs/backup/日期/
HDFS存储路径: /logs/日期
HDFS中的文件的前缀:access_log_
HDFS中的文件的后缀:.log
将路径配置写入属性文件
MAPPER_CLASS=cn.edu360.hdfs.wordcount.CaseIgnorWcountMapper
INPUT_PATH=/wordcount/input
OUTPUT_PATH=/wordcount/output2
主程序代码示例:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Properties;
import java.util.Set; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator; public class HdfsWordcount { public static void main(String[] args) throws Exception{ /**
* 初始化工作
*/
Properties props = new Properties();
props.load(HdfsWordcount.class.getClassLoader().getResourceAsStream("job.properties")); Path input = new Path(props.getProperty("INPUT_PATH"));
Path output = new Path(props.getProperty("OUTPUT_PATH")); Class<?> mapper_class = Class.forName(props.getProperty("MAPPER_CLASS"));
Mapper mapper = (Mapper) mapper_class.newInstance(); Context context = new Context(); /**
* 处理数据
*/ FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"), new Configuration(), "root");
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(input, false); while(iter.hasNext()){
LocatedFileStatus file = iter.next();
FSDataInputStream in = fs.open(file.getPath());
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String line = null;
// 逐行读取
while ((line = br.readLine()) != null) {
// 调用一个方法对每一行进行业务处理
mapper.map(line, context); } br.close();
in.close(); } /**
* 输出结果
*/
HashMap<Object, Object> contextMap = context.getContextMap(); if(fs.exists(output)){
throw new RuntimeException("指定的输出目录已存在,请更换......!");
} FSDataOutputStream out = fs.create(new Path(output,new Path("res.dat"))); Set<Entry<Object, Object>> entrySet = contextMap.entrySet();
for (Entry<Object, Object> entry : entrySet) {
out.write((entry.getKey().toString()+"\t"+entry.getValue()+"\n").getBytes());
} out.close(); fs.close(); System.out.println("恭喜!数据统计完成....."); } }
自定义的业务接口
public interface Mapper {
public void map(String line,Context context);
}
业务实现类1
public class WordCountMapper implements Mapper{
@Override
public void map(String line, Context context) {
String[] words = line.split(" ");
for (String word : words) {
Object value = context.get(word);
if(null==value){
context.write(word, 1);
}else{
int v = (int)value;
context.write(word, v+1);
}
}
}
}
业务实现类2
public class CaseIgnorWcountMapper implements Mapper {
@Override
public void map(String line, Context context) {
String[] words = line.toUpperCase().split(" ");
for (String word : words) {
Object value = context.get(word);
if (null == value) {
context.write(word, 1);
} else {
int v = (int) value;
context.write(word, v + 1);
}
}
}
}
缓存模拟
import java.util.HashMap;
public class Context {
private HashMap<Object,Object> contextMap = new HashMap<>();
public void write(Object key,Object value){
contextMap.put(key, value);
}
public Object get(Object key){
return contextMap.get(key);
}
public HashMap<Object,Object> getContextMap(){
return contextMap;
}
}
8、实战描述
需求描述:
在业务系统的服务器上,业务程序会不断生成业务日志(比如网站的页面访问日志)
业务日志是用log4j生成的,会不断地切出日志文件
需要定期(比如每小时)从业务服务器上的日志目录中,探测需要采集的日志文件(access.log,不是直接采集数据),发往HDFS
注意点:业务服务器可能有多台(hdfs上的文件名不能直接用日志服务器上的文件名)
当天采集到的日志要放在hdfs的当天目录中
采集完成的日志文件,需要移动到到日志服务器的一个备份目录中
定期检查(一小时检查一次)备份目录,将备份时长超出24小时的日志文件清除
Timer timer = new Timer() timer.schedual()
简易版日志采集主程序
import java.util.Timer;
public class DataCollectMain {
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new CollectTask(), 0, 60*60*1000L);
timer.schedule(new BackupCleanTask(), 0, 60*60*1000L);
}
}
日志收集定时任务类
import java.io.File;
import java.io.FilenameFilter;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.Properties;
import java.util.TimerTask;
import java.util.UUID; import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.log4j.Logger; public class CollectTask extends TimerTask { @Override
public void run() { /**
* ——定时探测日志源目录 ——获取需要采集的文件 ——移动这些文件到一个待上传临时目录
* ——遍历待上传目录中各文件,逐一传输到HDFS的目标路径,同时将传输完成的文件移动到备份目录
*
*/
try {
// 获取配置参数
Properties props = PropertyHolderLazy.getProps(); // 构造一个log4j日志对象
Logger logger = Logger.getLogger("logRollingFile"); // 获取本次采集时的日期
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd-HH");
String day = sdf.format(new Date()); File srcDir = new File(props.getProperty(Constants.LOG_SOURCE_DIR)); // 列出日志源目录中需要采集的文件
File[] listFiles = srcDir.listFiles(new FilenameFilter() { @Override
public boolean accept(File dir, String name) {
if (name.startsWith(props.getProperty(Constants.LOG_LEGAL_PREFIX))) {
return true;
}
return false;
}
}); // 记录日志
logger.info("探测到如下文件需要采集:" + Arrays.toString(listFiles)); // 将要采集的文件移动到待上传临时目录
File toUploadDir = new File(props.getProperty(Constants.LOG_TOUPLOAD_DIR));
for (File file : listFiles) {
FileUtils.moveFileToDirectory(file, toUploadDir, true);
} // 记录日志
logger.info("上述文件移动到了待上传目录" + toUploadDir.getAbsolutePath()); // 构造一个HDFS的客户端对象 FileSystem fs = FileSystem.get(new URI(props.getProperty(Constants.HDFS_URI)), new Configuration(), "root");
File[] toUploadFiles = toUploadDir.listFiles(); // 检查HDFS中的日期目录是否存在,如果不存在,则创建
Path hdfsDestPath = new Path(props.getProperty(Constants.HDFS_DEST_BASE_DIR) + day);
if (!fs.exists(hdfsDestPath)) {
fs.mkdirs(hdfsDestPath);
} // 检查本地的备份目录是否存在,如果不存在,则创建
File backupDir = new File(props.getProperty(Constants.LOG_BACKUP_BASE_DIR) + day + "/");
if (!backupDir.exists()) {
backupDir.mkdirs();
} for (File file : toUploadFiles) {
// 传输文件到HDFS并改名access_log_
Path destPath = new Path(hdfsDestPath + "/" + UUID.randomUUID() + props.getProperty(Constants.HDFS_FILE_SUFFIX));
fs.copyFromLocalFile(new Path(file.getAbsolutePath()), destPath); // 记录日志
logger.info("文件传输到HDFS完成:" + file.getAbsolutePath() + "-->" + destPath); // 将传输完成的文件移动到备份目录
FileUtils.moveFileToDirectory(file, backupDir, true); // 记录日志
logger.info("文件备份完成:" + file.getAbsolutePath() + "-->" + backupDir); } } catch (Exception e) {
e.printStackTrace();
} } }
定期清理过时备份日志
import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.TimerTask; import org.apache.commons.io.FileUtils; public class BackupCleanTask extends TimerTask { @Override
public void run() { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd-HH");
long now = new Date().getTime();
try {
// 探测本地备份目录
File backupBaseDir = new File("d:/logs/backup/");
File[] dayBackDir = backupBaseDir.listFiles(); // 判断备份日期子目录是否已超24小时
for (File dir : dayBackDir) {
long time = sdf.parse(dir.getName()).getTime();
if(now-time>24*60*60*1000L){
FileUtils.deleteDirectory(dir);
}
}
} catch (Exception e) {
e.printStackTrace();
} } }
配置信息提取到属性配置文件中,并写成常量,以单例设计模式去加载配置信息。
LOG_SOURCE_DIR=d:/logs/accesslog/
LOG_TOUPLOAD_DIR=d:/logs/toupload/
LOG_BACKUP_BASE_DIR=d:/logs/backup/
LOG_BACKUP_TIMEOUT=24
LOG_LEGAL_PREFIX=access.log. HDFS_URI=hdfs://hdp-01:9000/
HDFS_DEST_BASE_DIR=/logs/
HDFS_FILE_PREFIX=access_log_
HDFS_FILE_SUFFIX=.log
public class Constants {
/**
* 日志源目录参数key
*/
public static final String LOG_SOURCE_DIR = "LOG_SOURCE_DIR";
/**
* 日志待上传目录参数key
*/
public static final String LOG_TOUPLOAD_DIR = "LOG_TOUPLOAD_DIR";
public static final String LOG_BACKUP_BASE_DIR = "LOG_BACKUP_BASE_DIR";
public static final String LOG_BACKUP_TIMEOUT = "LOG_BACKUP_TIMEOUT";
public static final String LOG_LEGAL_PREFIX = "LOG_LEGAL_PREFIX";
public static final String HDFS_URI = "HDFS_URI";
public static final String HDFS_DEST_BASE_DIR = "HDFS_DEST_BASE_DIR";
public static final String HDFS_FILE_PREFIX = "HDFS_FILE_PREFIX";
public static final String HDFS_FILE_SUFFIX = "HDFS_FILE_SUFFIX";
}
import java.util.Properties; /**
* 单例模式:懒汉式——考虑了线程安全
* @author ThinkPad
*
*/ public class PropertyHolderLazy { private static Properties prop = null; public static Properties getProps() throws Exception {
if (prop == null) {
synchronized (PropertyHolderLazy.class) {
if (prop == null) {
prop = new Properties();
prop.load(PropertyHolderLazy.class.getClassLoader().getResourceAsStream("collect.properties"));
}
}
}
return prop;
} }
import java.util.Properties; /**
* 单例设计模式,方式一: 饿汉式单例
* @author ThinkPad
*
*/
public class PropertyHolderHungery { private static Properties prop = new Properties(); static {
try {
prop.load(PropertyHolderHungery.class.getClassLoader().getResourceAsStream("collect.properties"));
} catch (Exception e) { }
} public static Properties getProps() throws Exception { return prop;
} }
9、总结
hdfs有服务端和客户端;
服务端:
成员:namenode 管理元数据,datanode存储数据
配置:需要指定使用的文件系统(默认的配置在core-default.xml,为本地文件系统,需要修改服务器core-site.xml修改为hdfs文件系统,并指定namenode),namenode和datanode的工作目录(服务器的默认配置在hdfs-default.xml中,默认是在/temp下,需要就该hdfs-site.xml来覆盖默认值。);
细节:第一次启动集群时需要格式化namenode
客户端:
形式:网页端,命令行,java客户端api;客户端可以运行在任何地方。
功能:指定上传文件的信息报括切块大小(hdfs-default.xml中默认值128m,可以在hdfs-site.xml中修改,也可以咋java api 中创建客户端对象的时候指定,总之由客户端来指定),副本数量(hdfs-default.xml中默认值3,同样可以修改覆盖);完成hdfs中文件的系列操作,如上传,下载
虽然服务端和客户端的共用配置 core-default.xml core-site.xml;hdfs-default.xml hdfs-site.xml,但是不同的程序所需要的参数不同,只不过为了方便,所有参数都写在一个文件中了。即是在服务器的hdfs-site.xml中配置了切块大小和副本数量,服务器的namenode和datanode根本不关心也不使用这些参数,只有启动服务器上的命令行客户端时,该参数才可能起作用。

hadoop之HDFS学习笔记(一)的更多相关文章
- hadoop之HDFS学习笔记(二)
主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制:数据上传下载流程 1.hdfs的核心工作原理 1.1.namenode元数据管理要点 1.什么是元数据? h ...
- Hadoop源码学习笔记(6)——从ls命令一路解剖
Hadoop源码学习笔记(6) ——从ls命令一路解剖 Hadoop几个模块的程序我们大致有了点了解,现在我们得细看一下这个程序是如何处理命令的. 我们就从原头开始,然后一步步追查. 我们先选中ls命 ...
- Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构
Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构 之前我们简要的看过了DataNode的main函数以及整个类的大至,现在结合前面我们研究的线程和RPC,则可以进一步 ...
- Hadoop源码学习笔记(1) ——第二季开始——找到Main函数及读一读Configure类
Hadoop源码学习笔记(1) ——找到Main函数及读一读Configure类 前面在第一季中,我们简单地研究了下Hadoop是什么,怎么用.在这开源的大牛作品的诱惑下,接下来我们要研究一下它是如何 ...
- Hadoop源码学习笔记(4) ——Socket到RPC调用
Hadoop源码学习笔记(4) ——Socket到RPC调用 Hadoop是一个分布式程序,分布在多台机器上运行,事必会涉及到网络编程.那这里如何让网络编程变得简单.透明的呢? 网络编程中,首先我们要 ...
- Hadoop源码学习笔记(3) ——初览DataNode及学习线程
Hadoop源码学习笔记(3) ——初览DataNode及学习线程 进入了main函数,我们走出了第一步,接下来看看再怎么走: public class DataNode extends Config ...
- Hadoop源码学习笔记(2) ——进入main函数打印包信息
Hadoop源码学习笔记(2) ——进入main函数打印包信息 找到了main函数,也建立了快速启动的方法,然后我们就进去看一看. 进入NameNode和DataNode的主函数后,发现形式差不多: ...
- Hadoop - HDFS学习笔记(详细)
第1章 HDFS概述 hdfs背景意义 hdfs是一个分布式文件系统 使用场景:适合一次写入,多次读出的场景,且不支持文件的修改. 优缺点 高容错性,适合处理大数据(数据PB级别,百万规模文件),可部 ...
- Hadoop权威指南学习笔记一
Hadoop简单介绍 声明:本文是本人基于Hadoop权威指南学习的一些个人理解和笔记,仅供学习參考,有什么不到之处还望指出.一起学习一起进步. 转载请注明:http://blog.csdn.net/ ...
随机推荐
- CF86D
题解: 莫队分块 分块大小为sqrt(n) 代码: #include<bits/stdc++.h> using namespace std; ; typedef long long ll; ...
- 第十一次作业 - Alpha 事后诸葛亮
拖鞋旅游队团队事后诸葛亮会议 前言 队名:拖鞋旅游队 组长博客:https://www.cnblogs.com/Sulumer/p/10054510.html 时间:2018-12-1 20:00 地 ...
- HDU 1535
http://acm.hdu.edu.cn/showproblem.php?pid=1535 水题 单向图,从1到P所有点,再从所有点回到1,问最小花费 先求一遍1的最短路,然后反向建图,再求一遍1的 ...
- BZOJ2938: [Poi2000]病毒(AC自动机)
2938: [Poi2000]病毒 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 1678 Solved: 849[Submit][Status][D ...
- Android中关于JNI 的学习(一)对于JNIEnv的一些认识
一个简单的样例让我们初步地了解JNI的作用.可是关于JNI中的一些概念还是需要了解清楚,才干够更好的去利用它来实现我们想要做的事情. 那么C++和Java之间的是怎样通过JNI来进行互相调用的呢? 我 ...
- 建立dblink(database link)
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/bisal/article/details/26730993 database linke是建立一个数 ...
- MYSQL中写SQL语句,取到表中按ID降序排列(最新纪录排在第一行)
'select * from bugdata where id>0 order by id desc'
- C++ Primer第五版答案
Downloads Download the source files for GCC 4.7.0. Download the source code files for MS Visual Stud ...
- OneProxy常用参数说明
5.2.OneProxy常用参数说明 OneProxy的所有可用参数可通过oneproxy --help-all查看.所有参数均可以写入文件中,由OneProxy启动时加载 5.2.1.基本参数 -- ...
- Accessing data in Hadoop using dplyr and SQL
If your primary objective is to query your data in Hadoop to browse, manipulate, and extract it into ...