5、Tensorflow基础(三)神经元函数及优化方法
1、激活函数
激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络。神经网络之所以能解决非线性问题(如语音、图像识别),本质上就是激活函数加入了非线性因素,弥补了线性模型的表达力,把“激活的神经元的特征”通过函数保留并映射到下一层。
因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也
是可微的。那么激活函数在 TensorFlow 中是如何表达的呢?
激活函数不会更改输入数据的维度,也就是输入和输出的维度是相同的。TensorFlow 中有
如下激活函数,它们定义在 tensorflow-1.1.0/tensorflow/python/ops/nn.py 文件中,这里包括平滑
非线性的激活函数,如 sigmoid、tanh、elu、softplus 和 softsign,也包括连续但不是处处可微的
函数 relu、relu6、crelu 和 relu_x,以及随机正则化函数 dropout:
tf.nn.relu()
tf.nn.sigmoid()
tf.nn.tanh()
tf.nn.elu()
tf.nn.bias_add()
tf.nn.crelu()
tf.nn.relu6()
tf.nn.softplus()
tf.nn.softsign()
tf.nn.dropout()#防止过拟合,用来舍弃某些神经元
上述激活函数的输入均为要计算的 x(一个张量),输出均为与 x 数据类型相同的张量。
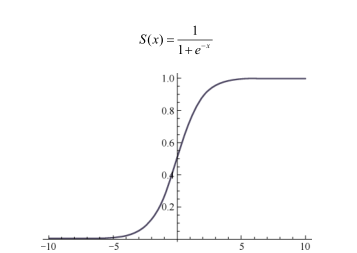
1.1、Sigmoid函数:
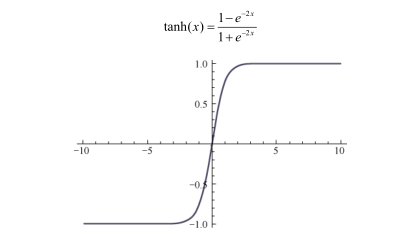
1.2、tanh函数:
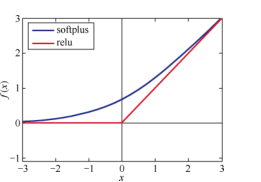
1.3、relu函数:and softplus函数:
2、卷积函数:
卷积函数定义在 tensorflow-1.1.0/tensorflow/python/ops 下的 nn_impl.py 和
nn_ops.py 文件中。
tf.nn.convolution(input, filter, padding, strides=None,dilation_rate=None, name=None, data_format=None)
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,data_format= None, name=None)
tf.nn.depthwise_conv2d (input, filter, strides, padding, rate=None, name=None,data_format=None)
tf.nn.separable_conv2d (input, depthwise_filter, pointwise_filter, strides, padding,rate=None, name=None, data_format=None)
tf.nn.atrous_conv2d(value, filters, rate, padding, name=None)
tf.nn.conv2d_transpose(value, filter, output_shape, strides, padding='SAME',data_format='NHWC', name=None)
tf.nn.conv1d(value, filters, stride, padding, use_cudnn_on_gpu=None,data_format= None, name=None)
tf.nn.conv3d(input, filter, strides, padding, name=None)
tf.nn.conv3d_transpose(value, filter, output_shape, strides, padding='SAME',name=None)
(1)tf.nn.convolution(input, filter, padding, strides=None, dilation_rate=None, name=None,
data_format =None)这个函数计算 N 维卷积的和。
(2)tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None,
name=None)这个函数的作用是对一个四维的输入数据 input 和四维的卷积核 filter 进行操作,然
后对输入数据进行一个二维的卷积操作,最后得到卷积之后的结果。
def conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,data_format=None, name=None)
# 输入:
# input:一个 Tensor。数据类型必须是 float32 或者 float64
# filter:一个 Tensor。数据类型必须是 input 相同
# strides:一个长度是 4 的一维整数类型数组,每一维度对应的是 input 中每一维的对应移动步数,
# 比如,strides[1]对应 input[1]的移动步数
# padding:一个字符串,取值为 SAME 或者 VALID
# padding='SAME':仅适用于全尺寸操作,即输入数据维度和输出数据维度相同
# padding='VALID:适用于部分窗口,即输入数据维度和输出数据维度不同
# use_cudnn_on_gpu:一个可选布尔值,默认情况下是 True
# name:(可选)为这个操作取一个名字
# 输出:一个 Tensor,数据类型是 input 相同 事例; input_data = tf.Variable( np.random.rand(10,9,9,3), dtype = np.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 2), dtype = np.float32)
y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME') 打印出 tf.shape(y)的结果是[10 9 9 2]。
(3)tf.nn.depthwise_conv2d (input, filter, strides, padding, rate=None, name=None,data_format=
None) 这个函数输入张量的数据维度是[batch, in_height, in_width, in_channels],卷积核的维度是
[filter_height, filter_width, in_channels, channel_multiplier],在通道 in_channels 上面的卷积深度是
1,depthwise_conv2d 函数将不同的卷积核独立地应用在 in_channels 的每个通道上(从通道 1
到通道 channel_multiplier),然后把所以的结果进行汇总。最后输出通道的总数是 in_channels *
channel_multiplier。
input_data = tf.Variable( np.random.rand(10, 9, 9, 3), dtype = np.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 5), dtype = np.float32)
y = tf.nn.depthwise_conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME') 这里打印出 tf.shape(y)的结果是[10 9 9 15]。
(4)tf.nn.separable_conv2d (input, depthwise_filter, pointwise_filter, strides, padding, rate=None,
name=None, data_format=None)是利用几个分离的卷积核去做卷积。在这个 API 中,将应用一个
二维的卷积核,在每个通道上,以深度 channel_multiplier 进行卷积。
def separable_conv2d (input, depthwise_filter, pointwise_filter, strides, padding,
rate=None, name=None, data_format=None)
# 特殊参数:
# depthwise_filter:一个张量。数据维度是四维[filter_height, filter_width, in_channels,
# channel_multiplier]。其中,in_channels 的卷积深度是 1
# pointwise_filter:一个张量。数据维度是四维[1, 1, channel_multiplier * in_channels,
# out_channels]。其中,pointwise_filter 是在 depthwise_filter 卷积之后的混合卷积
使用示例如下:
input_data = tf.Variable( np.random.rand(10, 9, 9, 3), dtype = np.float32 )
depthwise_filter = tf.Variable( np.random.rand(2, 2, 3, 5), dtype = np.float32)
pointwise_filter = tf.Variable( np.random.rand(1, 1, 15, 20), dtype = np.float32)
# out_channels >= channel_multiplier * in_channels
y = tf.nn.separable_conv2d(input_data, depthwise_filter, pointwise_filter,strides = [1, 1, 1, 1], padding = 'SAME') 这里打印出 tf.shape(y)的结果是[10 9 9 20]。
(5)tf.nn.atrous_conv2d(value, filters, rate, padding, name=None)计算 Atrous 卷积,又称孔卷
积或者扩张卷积。
使用示例如下:
input_data = tf.Variable( np.random.rand(1,5,5,1), dtype = np.float32 )
filters = tf.Variable( np.random.rand(3,3,1,1), dtype = np.float32)
y = tf.nn.atrous_conv2d(input_data, filters, 2, padding='SAME') 这里打印出 tf.shape(y)的结果是[1 5 5 1]。
(6)tf.nn.conv2d_transpose(value, filter, output_shape, strides, padding='SAME', data_format='NHWC',
name=None)
① 在解卷积网络(deconvolutional network)中有时称为“反卷积”,但实际上是 conv2d
的转置,而不是实际的反卷积。
def conv2d_transpose(value, filter, output_shape, strides, padding='SAME',
data_format='NHWC', name=None)
# 特殊参数:
# output_shape:一维的张量,表示反卷积运算后输出的形状
# 输出:和 value 一样维度的 Tensor
使用示例如下:
x = tf.random_normal(shape=[1,3,3,1])
kernel = tf.random_normal(shape=[2,2,3,1])
y = tf.nn.conv2d_transpose(x,kernel,output_shape=[1,5,5,3],strides=[1,2,2,1],padding="SAME") 这里打印出 tf.shape(y)的结果是[1 5 5 3]。
(7)tf.nn.conv1d(value, filters, stride, padding, use_cudnn_on_gpu=None, data_format=None,
name=None)和二维卷积类似。这个函数是用来计算给定三维的输入和过滤器的情况下的一维卷
积。不同的是,它的输入是三维,如[batch, in_width, in_channels]。卷积核的维度也是三维,少
了一维 filter_height,如 [filter_width, in_channels, out_channels]。stride 是一个正整数,代表卷积
核向右移动每一步的长度。
(8)tf.nn.conv3d(input, filter, strides, padding, name=None)和二维卷积类似。这个函数用来计
算给定五维的输入和过滤器的情况下的三维卷积。和二维卷积相对比:
● input 的 shape 中多了一维 in_depth,形状为 Shape[batch, in_depth, in_height,in_width,in_channels];
● filter 的 shape 中多了一维 filter_depth,由 filter_depth, filter_height, filter_width 构成了卷
积核的大小;
● strides 中多了一维,变为[strides_batch, strides_depth, strides_height, strides_width,
strides_channel],必须保证 strides[0] = strides[4] = 1。
(9)tf.nn.conv3d_transpose(value, filter, output_shape, strides, padding='SAME', name=None)
和二维反卷积类似,不再赘述。
3、池化函数
在神经网络中,池化函数一般跟在卷积函数的下一层,它们也被定义在 tensorflow-1.1.0/
tensorflow/python/ops 下的 nn.py 和 gen_nn_ops.py 文件中。
tf.nn.avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
tf.nn.max_pool_with_argmax(input, ksize, strides, padding, Targmax=None, name=None)
tf.nn.avg_pool3d(input, ksize, strides, padding, name=None)
tf.nn.max_pool3d(input, ksize, strides, padding, name=None)
tf.nn.fractional_avg_pool(value, pooling_ratio, pseudo_random=None, overlapping=None,
deterministic=None, seed=None, seed2=None, name=None)
tf.nn.fractional_max_pool(value, pooling_ratio, pseudo_random=None, overlapping=None,
deterministic=None, seed=None, seed2=None, name=None)
tf.nn.pool(input, window_shape, pooling_type, padding, dilation_rate=None, strides=None,
name=None, data_format=None)
池化操作是利用一个矩阵窗口在张量上进行扫描,将每个矩阵窗口中的值通过取最大值或
平均值来减少元素个数。每个池化操作的矩阵窗口大小是由 ksize 指定的,并且根据步长 strides
决定移动步长。下面就分别来说明
(1)tf.nn.avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None)。这个函
数计算池化区域中元素的平均值。
def avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
# 输入:
# value:一个四维的张量。数据维度是[batch, height, width, channels]
# ksize:一个长度不小于 4 的整型数组。每一位上的值对应于输入数据张量中每一维的窗口对应值
# strides:一个长度不小于 4 的整型数组。该参数指定滑动窗口在输入数据张量每一维上的步长
# padding:一个字符串,取值为 SAME 或者 VALID
# data_format: 'NHWC'代表输入张量维度的顺序,N 为个数,H 为高度,W 为宽度,C 为通道数(RGB 三
# 通道或者灰度单通道)
# name(可选):为这个操作取一个名字
# 输出:一个张量,数据类型和 value 相同 使用示例如下: input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = np.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32)
y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME')
output = tf.nn.avg_pool(value = y, ksize = [1, 2, 2, 1], strides = [1, 1, 1, 1],
padding ='SAME')
上述代码打印出 tf.shape(output)的结果是[10 6 6 10]。计算输出维度的方法是:shape(output) =
(shape(value) - ksize + 1) / strides。
(2)tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)。这个函
数是计算池化区域中元素的最大值。
input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = np.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32)
y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME')
output = tf.nn.max_pool(value = y, ksize = [1, 2, 2, 1], strides = [1, 1, 1, 1],
padding ='SAME') 上述代码打印出 tf.shape(output)的结果是[10 6 6 10]。
(3)tf.nn.max_pool_with_argmax(input, ksize, strides, padding, Targmax = None, name=None)。
这个函数的作用是计算池化区域中元素的最大值和该最大值所在的位置。
在计算位置 argmax 的时候,我们将 input 铺平了进行计算,所以,如果 input = [b, y, x, c],
那么索引位置是(( b * height + y) * width + x) * channels + c。
使用示例如下,该函数只能在 GPU 下运行,在 CPU 下没有对应的函数实现
input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = tf.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32)
y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME')
output, argmax = tf.nn.max_pool_with_argmax(input = y, ksize = [1, 2, 2, 1],
strides = [1, 1, 1, 1], padding = 'SAME')
返回结果是一个张量组成的元组(output, argmax),output 表示池化区域的最大值;argmax
的数据类型是 Targmax,维度是四维。
(4)tf.nn.avg_pool3d()和 tf.nn.max_pool3d()分别是在三维下的平均池化和最大池化。
(5)tf.nn.fractional_avg_pool()和tf.nn.fractional_max_pool()分别是在三维下的平均池化和最大池化。
(6)tf.nn.pool(input, window_shape, pooling_type, padding, dilation_rate=None, strides=None,
name=None, data_format=None)。这个函数执行一个 N 维的池化操作。
4、分类函数:
TensorFlow 中常见的分类函数主要有sigmoid_cross_entropy_with_logits、softmax、log_softmax、softmax_cross_entropy_with_logits 等,它们也主要定义在 tensorflow-1.1.0/tensorflow/python/ops 的nn.py 和 nn_ops.py 文件中。
tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None)
tf.nn.softmax(logits, dim=-1, name=None)
tf.nn.log_softmax(logits, dim=-1, name=None)
tf.nn.softmax_cross_entropy_with_logits(logits, labels, dim=-1, name=None)
tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name=None)
(1)tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None):
def sigmoid_cross_entropy_with_logits(logits, targets, name=None):
# 输入:logits:[batch_size, num_classes],targets:[batch_size, size].logits 用最后一
# 层的输入即可
# 最后一层不需要进行 sigmoid 运算,此函数内部进行了 sigmoid 操作
# 输出:loss [batch_size, num_classes]
这个函数的输入要格外注意,如果采用此函数作为损失函数,在神经网络的最后一层不需
要进行 sigmoid 运算。
(2)tf.nn.softmax(logits, dim=-1, name=None)计算Softmax 激活,也就是 softmax = exp(logits) /
reduce_sum(exp(logits), dim)。
(3)tf.nn.log_softmax(logits, dim=-1, name=None)计算 log softmax 激活,也就是 logsoftmax =
logits - log(reduce_sum(exp(logits), dim))。
(4)tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1,
name =None):
def softmax_cross_entropy_with_logits(logits, targets, dim=-1, name=None):
# 输入:logits and labels 均为[batch_size, num_classes]
# 输出: loss:[batch_size], 里面保存的是 batch 中每个样本的交叉熵
(5)tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name=None) :
def sparse_softmax_cross_entropy_with_logits(logits, labels, name=None):
# logits 是神经网络最后一层的结果
# 输入:logits: [batch_size, num_classes] labels: [batch_size],必须在[0, num_classes]
# 输出:loss [batch_size],里面保存是 batch 中每个样本的交叉熵
5、优化方法:
TensorFlow 提供了很多优化器(optimizer),我们重点介绍下面这 8 个:
class tf.train.GradientDescentOptimizer
class tf.train.AdadeltaOptimizer
class tf.train.AdagradOptimizer
class tf.train.AdagradDAOptimizer
class tf.train.MomentumOptimizer
class tf.train.AdamOptimizer
class tf.train.FtrlOptimizer
class tf.train.RMSPropOptimizer
这 8 个优化器对应 8 种优化方法,分别是梯度下降法(BGD 和 SGD)、Adadelta 法、Adagrad
法(Adagrad 和 AdagradDAO)、Momentum 法(Momentum 和 Nesterov Momentum)、Adam、
Ftrl 法和 RMSProp 法,其中 BGD、SGD、Momentum 和 Nesterov Momentum 是手动指定学习
率的,其余算法能够自动调节学习率。
(1)BGD 法
BGD 的全称是 batch gradient descent,即批梯度下降。这种方法是利用现有参数对训练集
中的每一个输入生成一个估计输出 y i ,然后跟实际输出 y i 比较,统计所有误差,求平均以后得
到平均误差,以此作为更新参数的依据。它的迭代过程为:
(1)提取训练集中的所有内容{x 1 , …, x n },以及相关的输出 y i ;
(2)计算梯度和误差并更新参数。
这种方法的优点是,使用所有训练数据计算,能够保证收敛,并且不需要逐渐减少学习率;
缺点是,每一步都需要使用所有的训练数据,随着训练的进行,速度会越来越慢。
那么,如果将训练数据拆分成一个个批次(batch),每次抽取一批数据来更新参数,是不
是会加速训练呢?这就是最常用的 SGD。
2.SGD 法
SGD 的全称是 stochastic gradient descent,即随机梯度下降。因为这种方法的主要思想是将
数据集拆分成一个个批次(batch),随机抽取一个批次来计算并更新参数,所以也称为 MBGD
(minibatch gradient descent)。
SGD 在每一次迭代计算 mini-batch 的梯度,然后对参数进行更新。与 BGD 相比,SGD 在
训练数据集很大时,仍能以较很的速度收敛。但是,它仍然会有下面两个缺点。
(1)由于抽取不可避免地梯度会有误差,需要手动调整学习率(learning rate),但是选择
合适的学习率又比较困难。尤其在训练时,我们常常想对常出现的特征更新速度很一些,而对
不常出现的特征更新速度慢一些,而 SGD 在更新参数时对所有参数采用一样的学习率,因此无法满足要求。
(2)SGD 容易收敛到局部最优,并且在某些情况下可能被困在鞍点。
为了解决学习率固定的问题,又引入了 Momentum 法。
3.Momentum 法
Momentum 是模拟物理学中动量的概念,更新时在一定程度上保留之前的更新方向,利用
当前的批次再微调本次的更新参数,因此引入了一个新的变量 v(速度),作为前几次梯度的累
加。因此,Momentum 能够更新学习率,在下降初期,前后梯度方向一致时,能够加速学习;
在下降的中后期,在局部最小值的附近来回震荡时,能够抑制震荡,加很收敛。
4.Nesterov Momentum 法
Nesterov Momentum 法由Ilya Sutskever 在Nesterov 工作的启发下提出的,是对传统Momentum
法的一项改进,其基本思路如图

标准 Momentum 法首先计算一个梯度(短的 1 号线),然后在加速更新梯度的方向进行一
个大的跳跃(长的 1 号线);Nesterov 项首先在原来加速的梯度方向进行一个大的跳跃(2 号线),
然后在该位置计算梯度值(3 号线),然后用这个梯度值修正最终的更新方向(4 号线)。
上面介绍的优化方法都需要我们自己设定学习率,接下来介绍几种自适应学习率的优化
方法。
5.Adagrad 法
Adagrad 法能够自适应地为各个参数分配不同的学习率,能够控制每个维度的梯度方向。
这种方法的优点是能够实现学习率的自动更改:如果本次更新时梯度大,学习率就衰减得很一
些;如果这次更新时梯度小,学习率衰减得就慢一些。
6.Adadelta 法
Adagrad 法仍然存在一些问题:其学习率单调递减,在训练的后期学习率非常小,并且需
要手动设置一个全局的初始学习率。Adadelta 法用一阶的方法,近似模拟二阶牛顿法,解决了
这些问题。
7.RMSprop 法
RMSProp 法与 Momentum 法类似,通过引入一个衰减系数,使每一回合都衰减一定比例。
在实践中,对循环神经网络(RNN)效果很好。
8.Adam 法
Adam 的名称来源于自适应矩估计
① (adaptive moment estimation)。Adam 法根据损失函数
针对每个参数的梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
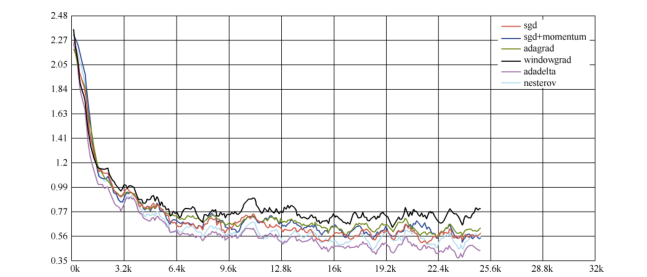
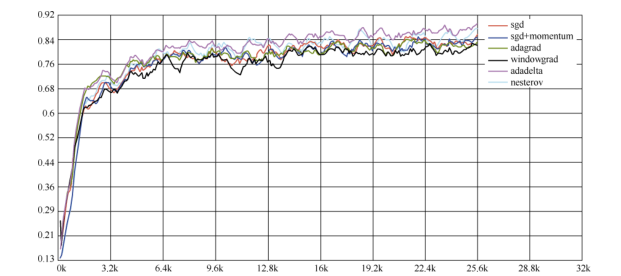
9.各个方法的比较
Karpathy 在 MNIST 数据集上用上述几个优化器做了一些性能比较,发现如下规律
② :在不
怎么调整参数的情况下,Adagrad 法比 SGD 法和 Momentum 法更稳定,性能更优;精调参数的
情况下,精调的 SGD 法和 Momentum 法在收敛速度和准确性上要优于 Adagrad 法。
各个优化器的损失值比较结果如图
各个优化器的测试准确率比较如图
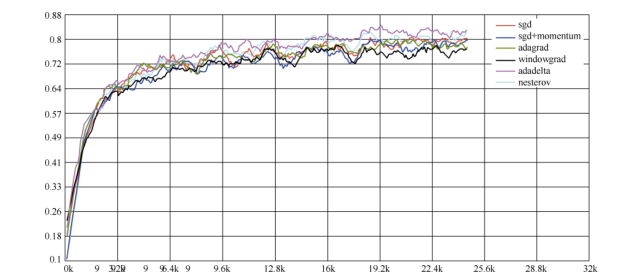
各个优化器的训练准确率比较如图
5、Tensorflow基础(三)神经元函数及优化方法的更多相关文章
- TensorFlow基础三(Scope)
用到变量名了,就涉及到了名字域的概念.通过不同的域来区别变量名,毕竟给所有变量都直接取不同名字还是有点辛苦的. 主要是name_scope和variable_scope,name_scope 作用于操 ...
- DP 优化方法大杂烩 & 做题记录 I.
标 * 的是推荐阅读的部分 / 做的题目. 1. 动态 DP(DDP)算法简介 动态动态规划. 以 P4719 为例讲一讲 ddp: 1.1. 树剖解法 如果没有修改操作,那么可以设计出 DP 方案 ...
- RF实现多次失败重跑结果合并的基础方法和优化方法
实现思路:通过分次执行失败案例重跑,然后通过结果文件合并命令实现多次失败重跑结果文件的合并,并输出合并后的log和report文件: 说明:具体失败案例重跑命令和结果文件合并命令请参考本博客其他相关章 ...
- TensorFlow+实战Google深度学习框架学习笔记(10)-----神经网络几种优化方法
神经网络的优化方法: 1.学习率的设置(指数衰减) 2.过拟合问题(Dropout) 3.滑动平均模型(参数更新,使模型在测试数据上更鲁棒) 4.批标准化(解决网络层数加深而产生的问题---如梯度弥散 ...
- HBase性能优化方法总结(三):读表操作
本文主要是从HBase应用程序设计与开发的角度,总结几种常用的性能优化方法.有关HBase系统配置级别的优化,可参考:淘宝Ken Wu同学的博客. 下面是本文总结的第三部分内容:读表操作相关的优化方法 ...
- Deep Learning基础--参数优化方法
1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Preprocessing) ...
- HBase性能优化方法总结(三):读表操作(转)
转自:http://www.cnblogs.com/panfeng412/archive/2012/03/08/hbase-performance-tuning-section3.html 本文主要是 ...
- 26种提高ASP.NET网站访问性能的优化方法 .
1. 数据库访问性能优化 数据库的连接和关闭 访问数据库资源需要创建连接.打开连接和关闭连接几个操作.这些过程需要多次与数据库交换信息以通过身份验证,比较耗费服务器资源. ASP.NET中提供了连接池 ...
- CSS两列及三列自适应布局方法整理
布局 自适应 两列 三列 在传统方法的基础上加入了Flex布局并阐述各方法的优缺点,希望对大家有所帮助.先上目录: 两列布局:左侧定宽,右侧自适应 方法一:利用float和负外边距 方法二:利用外边距 ...
随机推荐
- SSM整合中每一框架需要做的基本操作简述
1.dao层的工作 pojo和映射文件以及接口(使用逆向工程) SqlMapConfig.xml(Mybaits核心配置文件) ApplicationContext-dao.xml 整合后Sprin ...
- 简单拼接图像的tile_images和tile_images_offset算子
有时候通常需要简单的拼图,不涉及图像融合之类的,仅仅是简单的平移将多张图拼接成一张图.tile_images和tile_images_offset就是用于简单拼图的2个算子. 谈到拼图,肯定有以下问题 ...
- Golang之排序算法
冒泡排序 package main //冒泡排序 import "fmt" func bsort(a []int) { ; i < len(a); i++ { ; j < ...
- 利率计算v2.0--web版--软件工程
.客户说:帮我开发一个复利计算软件. .如果按照单利计算,本息又是多少呢? .假如30年之后要筹措到300万元的养老金,平均的年回报率是3%,那么,现在必须投入的本金是多少呢? .利率这么低,复利计算 ...
- scala 排序
sortBy() 定义: def sortBy[B](fun: (A) =>B) 栗子1: val words = "the quick brown fox jumped over t ...
- ORACLE DBLINK 使用
CREATE PUBLIC DATABASE LINK MYDBLINK CONNECT TO RAMS IDENTIFIED BY RAMS USING '(DESCRIPTION =(ADDRES ...
- 超级详细的解决方法 (CentOS7) :永久修改 mysql read-only 问题 could not retrieve transation read-only status server
一.查看mysql的事物隔离级别 SHOW VARIABLES LIKE '%iso%'; 二.临时修改事物隔离级别 SET GLOBAL tx_isolation='READ-COMMITTED'; ...
- UVaLive 4128 Steam Roller (多决策最短路)
题意:给定一个图,r 根横线, c 根竖线.告诉你起点和终点,然后从起点走,每条边有权值,如果是0,就表示无法通行.走的规则是:如果你在下个路要转弯,会使这段路的时间加倍,但是如果一条路同时是这样,那 ...
- C++ 类 & 对象-C++ 内联函数-C++ this 指针-C++ 类的静态成员
C++ 内联函数 C++ 内联函数是通常与类一起使用.如果一个函数是内联的,那么在编译时,编译器会把该函数的代码副本放置在每个调用该函数的地方. 对内联函数进行任何修改,都需要重新编译函数的所有客户端 ...
- 论DATASNAP远程方法支持自定义对象作参数
论DATASNAP远程方法支持自定义对象作参数 DATASNAP远程方法已经可以支持自定义对象作参数,这是非常方便的功能. 1)自定义对象 type TMyInfo = class(TObject) ...