结巴分词中TFIDF的原理
之前了解TFIDF只是基于公式,今天被阿里面试官问住了,所以深入讨论下TFIDF在结巴分词中原理。
概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
原理
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 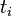 来说,它的重要性可表示为:
来说,它的重要性可表示为:

以上式子中 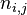 是该词 在文件
是该词 在文件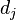 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

其中
- |D|:语料库中的文件总数
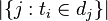 :包含词语的文件数目(即
:包含词语的文件数目(即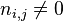 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用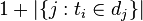
然后
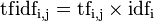
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
结巴中的应用:关键词提取
先上例子:
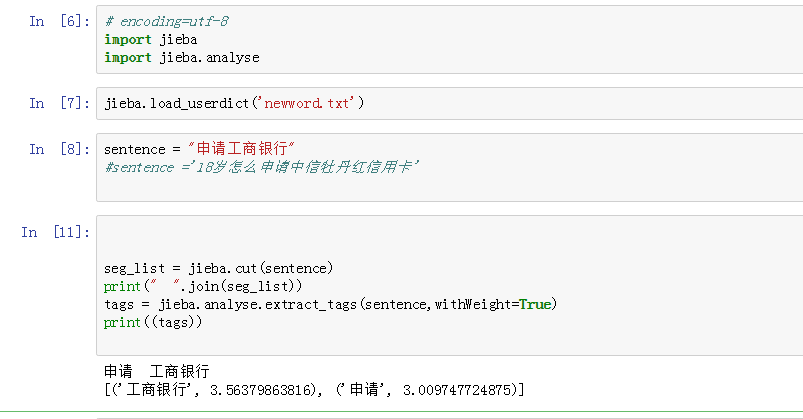
很好奇 这个3.56是怎么算出来的,因为只有一个句子,idf应该是1(总文章数(1)除以 出现"工商银行"的文章数(1))
其实并不是这样的,结巴中自带了定义好的idf文件,如图。
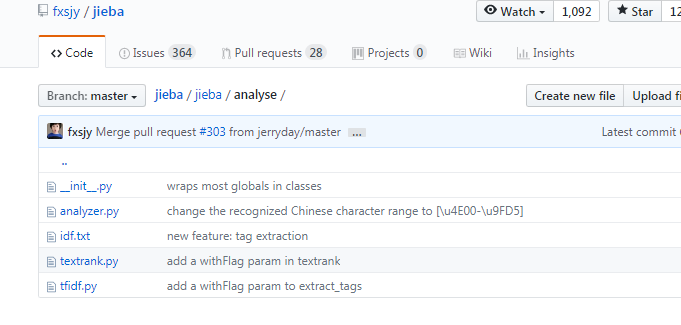
其中 工商银行的idf是7.12
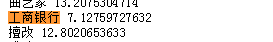
所以 3.56 是 tf=0.5(申请工商银行。里有2个词,工商银行出现1次) idf = 7.12(内置的idf)
tfidf = tf*idf=3.56
下面 把句子换成 工商银行申请工商银行
tf = 2/3 idf = 7.12
tfidf = 2/3*7.12 = 4.75

如果结巴自定义的词典,词语不在idf中,会怎样呢?
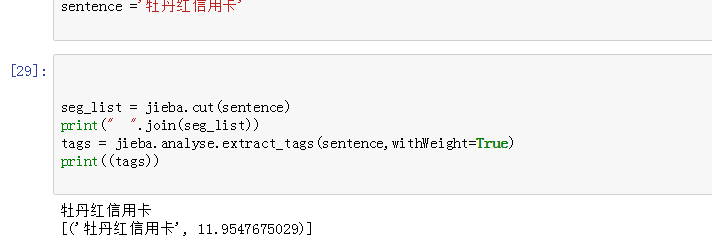
11.95 是咋来的呢?
分析一下idf那个文件:
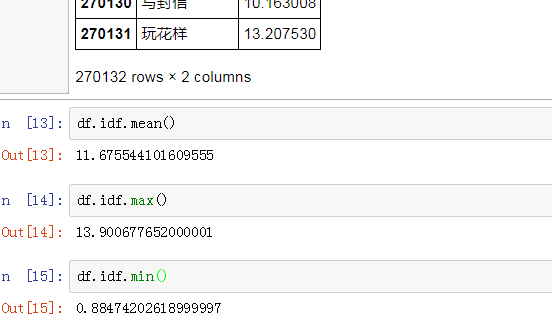
11.95可以看做是idf的平均值!!!!
结巴分词中TFIDF的原理的更多相关文章
- Python3.7+jieba(结巴分词)配合Wordcloud2.js来构造网站标签云(关键词集合)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_138 其实很早以前就想搞一套完备的标签云架构了,迫于没有时间(其实就是懒),一直就没有弄出来完整的代码,说到底标签对于网站来说还是 ...
- Python中结巴分词使用手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
- 结巴分词3--基于汉字成词能力的HMM模型识别未登录词
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 1 算法简介 在 结巴分词2--基于前缀词典及动态规划实现分词 博 ...
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- Python 结巴分词模块
原文链接:http://www.gowhich.com/blog/147?utm_source=tuicool&utm_medium=referral PS:结巴分词支持Python3 源码下 ...
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- python 中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- python结巴分词SEO的应用详解
结巴分词在SEO中可以应用于分析/提取文章关键词.关键词归类.标题重写.文章伪原创等等方面,用处非常多. 具体结巴分词项目:https://github.com/fxsjy/jieba ...
随机推荐
- kubectl get 输出格式
常见的输出格式有: * custom-columns=<spec> # 根据自定义列名进行输出,逗号分隔 * custom-columns-file=<filename> # ...
- linux--GCC简单用法
gcc是linux下最常用的一款c编译器,对应于CPP 有相应的g++工具,debug有gdb,只是还不会用. 个人感觉gcc确实是个好东西,完全可以直接在gedit下编程然后写个shell脚本用gc ...
- NUC972学习历程之NUWRITER使用说明以及烧录模式的说明
3.1 簡介Nu-Writer 工具能幫助使用者透過 USB ISP模式, 將Image檔案放入儲存體中, 例如:SPI Flash設備或 NAND Flash設備.3.2 驅動程式安裝Nu-Writ ...
- C语言之顺序结构
该章内容:这章我们学习三大结构之一:顺序结构,它是程序从上往下顺序执行,是程序运行最简单的方式.printf和scanf函数使用和特例是必考知识.本章是考试的重点章节. 学习方法:从简单的顺序结构题目 ...
- tableview随笔
//获得row NSInteger row = [[self.treeTableViewindexPathForCell:(UITableViewCell *)[[[notification.user ...
- PyQt4关闭窗口
一个显而易见的关闭窗口的方式是但集标题兰有上角的X标记.接下来的示例展示如何用代码来关闭程序,并简要介绍Qt的信号和槽机制. 下面是QPushButton的构造函数,我们将会在下面的示例中使用它. Q ...
- cocos2dx游戏--欢欢英雄传说--添加人物
接下来需要导入精灵帧资源,因为之前下载了TexturePacker,然后通过TexturePacker的"Publish sprite sheet"方法可以生成一个.pvr.ccz ...
- zabbix修改和查看登录密码
author:hendsen chen date : 2018-08-30 16:48:18 1,登陆zabbix的服务器,查看zabbix的登陆密码: [root@jason ~]# mysql ...
- C# 文件夹的常用操作
C#获取文件夹下的所有文件的文件名 string path = @"E:\微课视频大于200M"; DirectoryInfo folder = new DirectoryInfo ...
- jquery.js与sea.js综合使用
jquery.js与sea.js综合使用 目录 模块定义 define id dependencies factory exports require require.async require. ...