配置个人Ip代理池
做爬虫最害怕的两件事一个是被封账户一个是被封IP地址,IP地址可以使用代理来解决,网上有许多做IP代理的服务,他们提供大量的IP地址,不过这些地址不一定都是全部可用,因为这些IP地址可能被其他人做爬虫使用,所以随时可能被一些网站封禁,所以对于一些不可用的IP地址,使用之后就会影响程序运行效率,使用在获得IP地址之后,对这些地址做筛选,去除一些不可用的地址,再进行爬虫,效率就大大提升。通过爬取网上一些高匿IP来自建代理池。
1.准备工作
搭建代理池需要一些库的支持,包括安装Redis数据库,安装requests,apihttp,redis-py,pyquery,Flask,这些工具自行安装
2.搭建代理池,需要干什么
可以通过先下面的图了解一些(这个图网上找的。。。。。),图中可以分为4个部分:获取模块(爬虫调度器,代理获取爬虫),存储模块(Redis数据库),检测模块(代理验证爬虫),接口模块(web api)
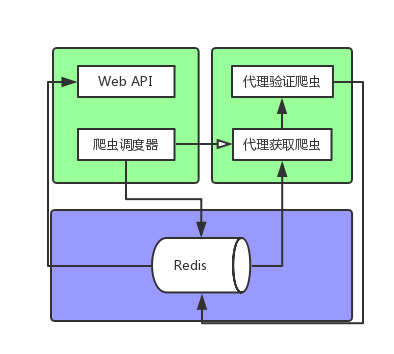
3.代理池的实现
存储模块:使用Redis的有序集合,为什么要使用有序集合,优点:有序集合能够保证数据不重复,有序集合自带分数字段,分数可以重复,能够帮助把每一个元素进行排序,数值小的在前面,数值大的在后面,对于后面的接口模块非常有用,可以通过分数值来判断代理是否可用,100代表最可用,0代表不可用,从接口获取的肯定分数是100的IP地址,保证每一个都可用,提高效率。下面来实现存储模块 (db.py)
import redisfrom random import choice
import re
# Redis数据库地址
REDIS_HOST = '127.0.0.1'
# Redis端口
REDIS_PORT = 6379
# Redis密码,如无填None
REDIS_PASSWORD = None
REDIS_KEY = 'proxies'
# 代理分数
MAX_SCORE = 100
MIN_SCORE = 0
INITIAL_SCORE = 10
class RedisClient(object):
def __init__(self, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD):
"""
初始化
:param host: Redis 地址
:param port: Redis 端口
:param password: Redis密码
"""
self.db = redis.StrictRedis(host=host, port=port, password=password, decode_responses=True) def add(self, proxy, score=INITIAL_SCORE):
"""
添加代理,设置分数为最高
:param proxy: 代理
:param score: 分数
:return: 添加结果
"""
if not re.match('\d+\.\d+\.\d+\.\d+\:\d+', proxy):
print('代理不符合规范', proxy, '丢弃')
return
if not self.db.zscore(REDIS_KEY, proxy):
return self.db.zadd(REDIS_KEY, score, proxy) def random(self):
"""
随机获取有效代理,首先尝试获取最高分数代理,如果不存在,按照排名获取,否则异常
:return: 随机代理
"""
result = self.db.zrangebyscore(REDIS_KEY, MAX_SCORE, MAX_SCORE)
if len(result):
return choice(result)
else:
result = self.db.zrevrange(REDIS_KEY, 0, 100)
if len(result):
return choice(result)
else:
raise PoolEmptyError def decrease(self, proxy):
"""
代理值减一分,小于最小值则删除
:param proxy: 代理
:return: 修改后的代理分数
"""
score = self.db.zscore(REDIS_KEY, proxy)
if score and score > MIN_SCORE:
print('代理', proxy, '当前分数', score, '减1')
return self.db.zincrby(REDIS_KEY, proxy, -1)
else:
print('代理', proxy, '当前分数', score, '移除')
return self.db.zrem(REDIS_KEY, proxy) def exists(self, proxy):
"""
判断是否存在
:param proxy: 代理
:return: 是否存在
"""
return not self.db.zscore(REDIS_KEY, proxy) == None def max(self, proxy):
"""
将代理设置为MAX_SCORE
:param proxy: 代理
:return: 设置结果
"""
print('代理', proxy, '可用,设置为', MAX_SCORE)
return self.db.zadd(REDIS_KEY, MAX_SCORE, proxy) def count(self):
"""
获取数量
:return: 数量
"""
return self.db.zcard(REDIS_KEY) def all(self):
"""
获取全部代理
:return: 全部代理列表
"""
return self.db.zrangebyscore(REDIS_KEY, MIN_SCORE, MAX_SCORE) def batch(self, start, stop):
"""
批量获取
:param start: 开始索引
:param stop: 结束索引
:return: 代理列表
"""
return self.db.zrevrange(REDIS_KEY, start, stop - 1)
定义了一个RedisClient类,定义了一些操作数据库的方法,这里设置了代理的分数,默认添加进去的IP地址都是10分,在后面检测IP地址是否的时候,如果可用就直接设置为 100,在检测代理不可用的时候,分数减1,直到分数为0,删除这个不可用的IP地址,调用的是decrease()方法.max()方法设置分数为100,ranfom()方法是随机获取有效代理。
2.获取模块
获取各大网站上的IP地址(crawler.py)
import json
import re
from .utils import get_page
from pyquery import PyQuery as pq
import requests
from requests.exceptions import ConnectionError base_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
} def get_page(url, options={}):
"""
抓取代理
:param url:
:param options:
:return:
"""
headers = dict(base_headers, **options)
print('正在抓取', url)
try:
response = requests.get(url, headers=headers)
print('抓取成功', url, response.status_code)
if response.status_code == 200:
return response.text
except ConnectionError:
print('抓取失败', url)
return None
class ProxyMetaclass(type):
def __new__(cls, name, bases, attrs):#定义了一个元类,attrs包含类的一些属性,包括类的所有方法
count = 0
attrs['__CrawlFunc__'] = []
for k, v in attrs.items():遍历类的方法
if 'crawl_' in k:#满足以crawl开头的类的方法就添加到__CrawlFunc__属性中
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs) class Crawler(object, metaclass=ProxyMetaclass):
def get_proxies(self, callback):
proxies = []
for proxy in eval("self.{}()".format(callback)):
print('成功获取到代理', proxy)
proxies.append(proxy)
return proxies def crawl_daili66(self, page_count=4):
"""
获取代理66
:param page_count: 页码
:return: 代理
"""
start_url = 'http://www.66ip.cn/{}.html'
urls = [start_url.format(page) for page in range(1, page_count + 1)]
for url in urls:
print('Crawling', url)
html = get_page(url)
if html:
doc = pq(html)
#第一个li节点之后的节点
trs = doc('.containerbox table tr:gt(0)').items()
for tr in trs:
#选择第一个td
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
yield ':'.join([ip, port]) def crawl_qydaili(self):
"""
获取代理
:param page_count: 页码
:return: 代理
"""
for i in range(1,11):
start_url = 'http://www.qydaili.com/free/?action=china&page={}'.format(i)
html = get_page(start_url)
if html:
doc = pq(html)
#第一个li节点之后的节点
trs = doc('.container .table-bordered tbody tr').items()
for tr in trs:
#选择第一个td
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
yield ':'.join([ip, port]) def crawl_kuaidaili(self):
for i in range(1, 20):
start_url = 'http://www.kuaidaili.com/free/inha/{}/'.format(i)
html = get_page(start_url)
if html:
ip_address = re.compile('<td data-title="IP">(.*?)</td>')
re_ip_address = ip_address.findall(html)
port = re.compile('<td data-title="PORT">(.*?)</td>')
re_port = port.findall(html)
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','') def crawl_xicidaili(self):
for i in range(1, 21):
start_url = 'http://www.xicidaili.com/nn/{}'.format(i)
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Cookie':'_free_proxy_session=BAh7B0kiD3Nlc3Npb25faWQGOgZFVEkiJWRjYzc5MmM1MTBiMDMzYTUzNTZjNzA4NjBhNWRjZjliBjsAVEkiEF9jc3JmX3Rva2VuBjsARkkiMUp6S2tXT3g5a0FCT01ndzlmWWZqRVJNek1WanRuUDBCbTJUN21GMTBKd3M9BjsARg%3D%3D--2a69429cb2115c6a0cc9a86e0ebe2800c0d471b3',
'Host':'www.xicidaili.com',
'Referer':'http://www.xicidaili.com/nn/3',
'Upgrade-Insecure-Requests':'',
}
html = get_page(start_url, options=headers)
if html:
find_trs = re.compile('<tr class.*?>(.*?)</tr>', re.S)
trs = find_trs.findall(html)
for tr in trs:
find_ip = re.compile('<td>(\d+\.\d+\.\d+\.\d+)</td>')
re_ip_address = find_ip.findall(tr)
find_port = re.compile('<td>(\d+)</td>')
re_port = find_port.findall(tr)
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','') def crawl_ip3366(self):
for i in range(1, 20):
start_url = 'http://www.ip3366.net/free/?stype=1&page={}'.format(i)
html = get_page(start_url)
if html:
find_tr = re.compile('<tr>(.*?)</tr>', re.S)
trs = find_tr.findall(html)
for s in range(1, len(trs)):
find_ip = re.compile('<td>(\d+\.\d+\.\d+\.\d+)</td>')
re_ip_address = find_ip.findall(trs[s])
find_port = re.compile('<td>(\d+)</td>')
re_port = find_port.findall(trs[s])
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','') def crawl_iphai(self):
url = ['http://www.iphai.com/','http://www.iphai.com/free/ng','http://www.iphai.com/free/np','http://www.iphai.com/free/wg','http://www.iphai.com/free/wp']
for start_url in url:
html = get_page(start_url)
if html:
find_tr = re.compile('<tr>(.*?)</tr>', re.S)
trs = find_tr.findall(html)
for s in range(1, len(trs)):
find_ip = re.compile('<td>\s+(\d+\.\d+\.\d+\.\d+)\s+</td>', re.S)
re_ip_address = find_ip.findall(trs[s])
find_port = re.compile('<td>\s+(\d+)\s+</td>', re.S)
re_port = find_port.findall(trs[s])
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','') def crawl_89ip(self):
for i in range(1,20):
start_url = 'http://www.89ip.cn/index_{}'.format(i)
html = get_page(start_url)
if html:
find_tr = re.compile('<tr>(.*?)</tr>', re.S)
trs = find_tr.findall(html)
for s in range(1, len(trs)):
find_ip = re.compile('<td>\s+(\d+\.\d+\.\d+\.\d+)\s+</td>', re.S)
re_ip_address = find_ip.findall(trs[s])
find_port = re.compile('<td>\s+(\d+)\s+</td>', re.S)
re_port = find_port.findall(trs[s])
for address,port in zip(re_ip_address, re_port):
address_port = address+':'+port
yield address_port.replace(' ','') def crawl_data5u(self):
start_url = 'http://www.data5u.com/free/gngn/index.shtml'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'JSESSIONID=47AA0C887112A2D83EE040405F837A86',
'Host': 'www.data5u.com',
'Referer': 'http://www.data5u.com/free/index.shtml',
'Upgrade-Insecure-Requests': '',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
}
html = get_page(start_url, options=headers)
if html:
ip_address = re.compile('<span><li>(\d+\.\d+\.\d+\.\d+)</li>.*?<li class=\"port.*?>(\d+)</li>', re.S)
re_ip_address = ip_address.findall(html)
for address, port in re_ip_address:
result = address + ':' + port
yield result.replace(' ', '')
在这里为每一个方法都定义了一个以crawl开头的方法,这样方便拓展,比如你想添加其他的IP网站,只要定义以crawl开头就可以了,这里给的网站目前都是可用的,唯一的缺点就是IP可用的不多。定义了Crawler类,还要定义一个Getter 类,动态调用所有crawl开头的方法,获取IP,存储到数据库。(getter.py)
from proxypool.tester import Tester
from proxypool.db import RedisClient
from proxypool.crawler import Crawler
import sys #代理池数量上限
POOL_UPPER_THRESHOLD = 20000
class Getter():
def __init__(self):
self.redis = RedisClient()
self.crawler = Crawler() def is_over_threshold(self):
"""
判断是否达到了代理池限制
"""
if self.redis.count() >= POOL_UPPER_THRESHOLD:
return True
else:
return False def run(self):
print('获取器开始执行')
if not self.is_over_threshold():
for callback_label in range(self.crawler.__CrawlFuncCount__):
callback = self.crawler.__CrawlFunc__[callback_label]
# 获取代理
proxies = self.crawler.get_proxies(callback)
sys.stdout.flush()
for proxy in proxies:
self.redis.add(proxy)
3.检测模块
获取到代理之后,就是从数据库中提取出来,检测是否可用,这里使用异步请求apihttp 来检测,效率比较高 ( tester.py)
import asyncio
import aiohttp
import time
import sys
try:
from aiohttp import ClientError
except:
from aiohttp import ClientProxyConnectionError as ProxyConnectionError
from proxypool.db import RedisClient
# 检查周期
TESTER_CYCLE = 20
# 获取周期
GETTER_CYCLE = 300
# 测试API,建议抓哪个网站测哪个
TEST_URL = 'https://weibo.cn/'
class Tester(object):
def __init__(self):
self.redis = RedisClient() async def test_single_proxy(self, proxy):
"""
测试单个代理
:param proxy:
:return:
"""
conn = aiohttp.TCPConnector(verify_ssl=False)
async with aiohttp.ClientSession(connector=conn) as session:
try:
if isinstance(proxy, bytes):
proxy = proxy.decode('utf-8')
real_proxy = 'http://' + proxy
print('正在测试', proxy)
async with session.get(TEST_URL, proxy=real_proxy, timeout=15, allow_redirects=False) as response:
if response.status in VALID_STATUS_CODES:
self.redis.max(proxy)
print('代理可用', proxy)
else:
self.redis.decrease(proxy)
print('请求响应码不合法 ', response.status, 'IP', proxy)
except (ClientError, aiohttp.client_exceptions.ClientConnectorError, asyncio.TimeoutError, AttributeError):
self.redis.decrease(proxy)
print('代理请求失败', proxy) def run(self):
"""
测试主函数
:return:
"""
print('测试器开始运行')
try:
count = self.redis.count()
print('当前剩余', count, '个代理')
for i in range(0, count, BATCH_TEST_SIZE):
start = i
stop = min(i + BATCH_TEST_SIZE, count)
print('正在测试第', start + 1, '-', stop, '个代理')
test_proxies = self.redis.batch(start, stop)
loop = asyncio.get_event_loop()
tasks = [self.test_single_proxy(proxy) for proxy in test_proxies]
loop.run_until_complete(asyncio.wait(tasks))
sys.stdout.flush()
time.sleep(5)
except Exception as e:
print('测试器发生错误', e.args)
TEST_URL网站设置为你要进行爬虫的网站,这里是weibo地址
4.接口模块
接口模块就是从数据库中获取可用的IP地址,通过Flask来实现,这样可以方便部署在服务器上 (api.py)
from flask import Flask, g from .db import RedisClient __all__ = ['app'] app = Flask(__name__) def get_conn():
if not hasattr(g, 'redis'):
g.redis = RedisClient()
return g.redis @app.route('/')
def index():
return '<h2>Welcome to Proxy Pool System</h2>' @app.route('/random')
def get_proxy():
"""
Get a proxy
:return: 随机代理
"""
conn = get_conn()
return conn.random() @app.route('/count')
def get_counts():
"""
Get the count of proxies
:return: 代理池总量
"""
conn = get_conn()
return str(conn.count()) if __name__ == '__main__':
app.run()
再实现一个调度模块,来调用上面的3个模块,通过多进程方式运行(scheduler.py)
import time
from multiprocessing import Process
from proxypool.api import app
from proxypool.getter import Getter
from proxypool.tester import Tester
from proxypool.db import RedisClient
#开关
TESTER_ENABLED = True
GETTER_ENABLED = True
API_ENABLED = True
# 检查周期
TESTER_CYCLE = 20
# 获取周期
GETTER_CYCLE = 300 class Scheduler():
def schedule_tester(self, cycle=TESTER_CYCLE):
"""
定时测试代理
"""
tester = Tester()
while True:
print('测试器开始运行')
tester.run()
time.sleep(cycle) def schedule_getter(self, cycle=GETTER_CYCLE):
"""
定时获取代理
"""
getter = Getter()
while True:
print('开始抓取代理')
getter.run()
time.sleep(cycle) def schedule_api(self):
"""
开启API
"""
app.run(API_HOST, API_PORT) def run(self):
print('代理池开始运行') if TESTER_ENABLED:
tester_process = Process(target=self.schedule_tester)
tester_process.start() if GETTER_ENABLED:
getter_process = Process(target=self.schedule_getter)
getter_process.start() if API_ENABLED:
api_process = Process(target=self.schedule_api)
api_process.start()
调用 run()方法就可以启动代理池了(run.py)
from proxypool.scheduler import Scheduler
import sys
import io sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') def main():
try:
s = Scheduler()
s.run()
except:
main() if __name__ == '__main__':
main()
运行效果
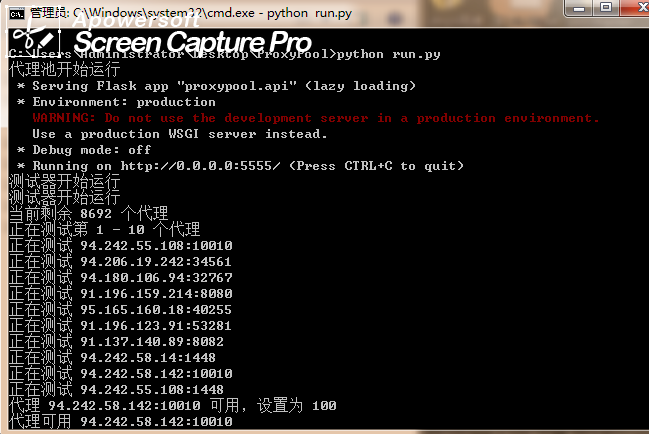
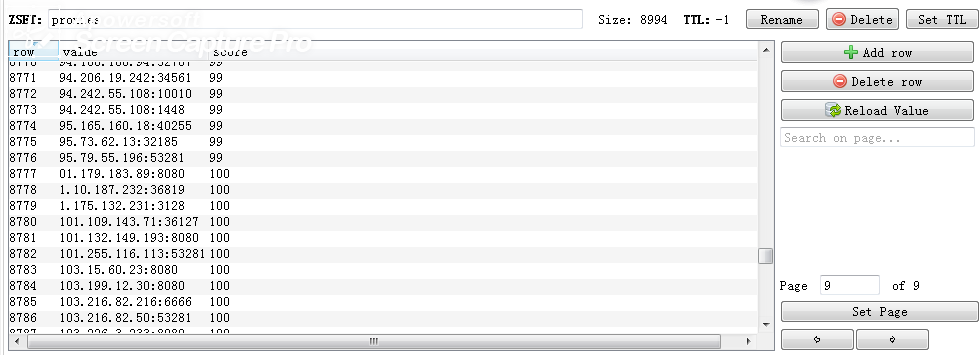
可以使用Redis Desktop Manager 查看爬取到的地址,可以看到爬了8994个地址,可用的也就200多个,有点惨啊
GitHub:https://github.com/jzxsWZY/IPProxyPool
配置个人Ip代理池的更多相关文章
- 开源IP代理池续——整体重构
开源IP代理池 继上一篇开源项目IPProxys的使用之后,大家在github,我的公众号和博客上提出了很多建议.经过两周时间的努力,基本完成了开源IP代理池IPProxyPool的重构任务,业余时间 ...
- scrapy_随机ip代理池
什么是ip代理? 我们电脑访问网站,其实是访问远程的服务器,通过ip地址识别是那个机器访问了服务器,服务器就知道数据该返回给哪台机器,我们生活中所用的网络是局域网,ip是运营商随机分配的,是一种直接访 ...
- 5 使用ip代理池爬取糗事百科
从09年读本科开始学计算机以来,一直在迷茫中度过,很想学些东西,做些事情,却往往陷进一些技术细节而蹉跎时光.直到最近几个月,才明白程序员的意义并不是要搞清楚所有代码细节,而是要有更宏高的方向,要有更专 ...
- python开源IP代理池--IPProxys
今天博客开始继续更新,谢谢大家对我的关注和支持.这几天一直是在写一个ip代理池的开源项目.通过前几篇的博客,我们可以了解到突破反爬虫机制的一个重要举措就是代理ip.拥有庞大稳定的ip代理,在爬虫工作中 ...
- 反爬虫之搭建IP代理池
反爬虫之搭建IP代理池 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部.可惜加了header请求头,加了cookie 还是被限制爬取了.这时就得祭出IP代理池!!! 下面就是requ ...
- Scrapy学习-13-使用DownloaderMiddleware设置IP代理池及IP变换
设置IP代理池及IP变换方案 方案一: 使用国内免费的IP代理 http://www.xicidaili.com # 创建一个tools文件夹,新建一个py文件,用于获取代理IP和PORT from ...
- python爬虫18 | 就算你被封了也能继续爬,使用IP代理池伪装你的IP地址,让IP飘一会
我们上次说了伪装头部 ↓ python爬虫17 | 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部 让自己的 python 爬虫假装是浏览器 小帅b主要是想让你知道 在爬取网站的时候 ...
- ip代理池的爬虫编写、验证和维护
打算法比赛有点累,比赛之余写点小项目来提升一下工程能力.顺便陶冶一下情操 本来是想买一个服务器写个博客或者是弄个什么FQ的东西 最后刷知乎看到有一个很有意思的项目,就是维护一个「高可用低延迟的高匿IP ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
随机推荐
- python 闭包变量不允许write,要使用nonlocal
以下是一段简单的闭包代码示例: def foo(): m=3 n=5 def bar(): a=4 return m+n+a return bar >>>bar = foo() &g ...
- BZOJ3282:Tree(TCL基础题)
给定N个点以及每个点的权值,要你处理接下来的M个操作. 操作有4种.操作从0到3编号.点从1到N编号. 0:后接两个整数(x,y),代表询问从x到y的路径上的点的权值的xor和. 保证x到y是联通的. ...
- gunicorn部署Flask服务
作为一个Python选手,工作中需要的一些服务接口一般会用Flask来开发. Flask非常容易上手,它自带的app.run(host="0.0.0.0", port=7001)用 ...
- bzoj3769
树形dp %%%popoqqq 设dp[i][j]表示当前i个节点的树,深度小于等于j的树的个数 那么dp[i][j] = sigma(dp[k][j-1]*dp[n-k-1][j-1]) 比较好理解 ...
- Rails bootstrap导入
创建: 2018/03/24 完成: 2018/03/24 适用于Sass, Scss. Less的自己网上搜吧 如何判断是不是Sass/Scss?项目里搜 gem 'sass-rails' ,gem ...
- MySQL(调优慢查询、explain profile) 转
转自http://www.linuxidc.com/Linux/2012-09/70459.htm mysql profile explain slow_query_log分析优化查询 在做性能测试中 ...
- Akka源码分析-Persistence Query
Akka Persistence Query是对akka持久化的一个补充,它提供了统一的.异步的流查询接口.今天我们就来研究下这个Persistence Query. 前面我们已经分析过Akka Pe ...
- CodeForces 923C Perfect Security
C. Perfect Security time limit per test3.5 seconds memory limit per test512 megabytes inputstandard ...
- 数学 Codeforces Round #308 (Div. 2) B. Vanya and Books
题目传送门 /* 水题:求总数字个数,开long long竟然莫名其妙WA了几次,也没改啥又对了:) */ #include <cstdio> #include <iostream& ...
- ACM_查找ACM(加强版)
查找ACM(加强版) Time Limit: 2000/1000ms (Java/Others) Problem Description: 作为一个acmer,应该具备团队合作能力和分析问题能力.给你 ...