Go语言语法说明
Go语言语法说明
go语言中的go func(){}() 表示以并发的方式调用匿名函数func
深入讲解Go语言中函数new与make的使用和区别
前言
本文主要给大家介绍了Go语言中函数new与make的使用和区别,关于Go语言中new和make是内建的两个函数,主要用来创建分配类型内存。在我们定义生成变量的时候,可能会觉得有点迷惑,其实他们的规则很简单,下面我们就通过一些示例说明他们的区别和使用,话不多说了,来一起看看详细的介绍吧。
变量的声明
var i int
var s string
变量的声明我们可以通过var关键字,然后就可以在程序中使用。当我们不指定变量的默认值时,这些变量的默认值是他们的零值,比如int类型的零值是0,string类型的零值是"",引用类型的零值是nil。
对于例子中的两种类型的声明,我们可以直接使用,对其进行赋值输出。但是如果我们换成引用类型呢?
package main
import (
"fmt"
)
func main() {
var i *int
*i=10
fmt.Println(*i)
}
这个例子会打印出什么?0还是10?。以上全错,运行的时候会painc,原因如下:
panic: runtime error: invalid memory address or nil pointer dereference
从这个提示中可以看出,对于引用类型的变量,我们不光要声明它,还要为它分配内容空间,否则我们的值放在哪里去呢?这就是上面错误提示的原因。
对于值类型的声明不需要,是因为已经默认帮我们分配好了。
要分配内存,就引出来今天的new和make。
new
对于上面的问题我们如何解决呢?既然我们知道了没有为其分配内存,那么我们使用new分配一个吧。
func main() {
var i *int
i=new(int)
*i=10
fmt.Println(*i)
}
现在再运行程序,完美PASS,打印10。现在让我们看下new这个内置的函数。
// The new built-in function allocates memory. The first argument is a type,
// not a value, and the value returned is a pointer to a newly
// allocated zero value of that type.
func new(Type) *Type
它只接受一个参数,这个参数是一个类型,分配好内存后,返回一个指向该类型内存地址的指针。同时请注意它同时把分配的内存置为零,也就是类型的零值。
我们的例子中,如果没有*i=10,那么打印的就是0。这里体现不出来new函数这种内存置为零的好处,我们再看一个例子。
func main() {
u:=new(user)
u.lock.Lock()
u.name = "张三"
u.lock.Unlock()
fmt.Println(u)
}
type user struct {
lock sync.Mutex
name string
age int
}
示例中的user类型中的lock字段我不用初始化,直接可以拿来用,不会有无效内存引用异常,因为它已经被零值了。
这就是new,它返回的永远是类型的指针,指向分配类型的内存地址。
make
make也是用于内存分配的,但是和new不同,它只用于chan、map以及切片的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
注意,因为这三种类型是引用类型,所以必须得初始化,但是不是置为零值,这个和new是不一样的。
func make(t Type, size ...IntegerType) Type
从函数声明中可以看到,返回的还是该类型。
二者异同
所以从这里可以看的很明白了,二者都是内存的分配(堆上),但是make只用于slice、map以及channel的初始化(非零值);而new用于类型的内存分配,并且内存置为零。所以在我们编写程序的时候,就可以根据自己的需要很好的选择了。
make返回的还是这三个引用类型本身;而new返回的是指向类型的指针。
其实new不常用
所以有new这个内置函数,可以给我们分配一块内存让我们使用,但是现实的编码中,它是不常用的。我们通常都是采用短语句声明以及结构体的字面量达到我们的目的,比如:
i:=0
u:=user{}
这样更简洁方便,而且不会涉及到指针这种比麻烦的操作。
make函数是无可替代的,我们在使用slice、map以及channel的时候,还是要使用make进行初始化,然后才才可以对他们进行操作。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
Golang select的使用及典型用法
select是Go中的一个控制结构,类似于switch语句,用于处理异步IO操作。select会监听case语句中channel的读写操作,当case中channel读写操作为非阻塞状态(即能读写)时,将会触发相应的动作。
select中的case语句必须是一个channel操作
select中的default子句总是可运行的。
- 如果有多个case都可以运行,select会随机公平地选出一个执行,其他不会执行。
- 如果没有可运行的case语句,且有default语句,那么就会执行default的动作。
- 如果没有可运行的case语句,且没有default语句,select将阻塞,直到某个case通信可以运行
Go语言的goroutines、信道和死锁
goroutine
Go语言中有个概念叫做goroutine, 这类似我们熟知的线程,但是更轻。
以下的程序,我们串行地去执行两次loop函数:
func loop() {
for i := 0; i < 10; i++ {
fmt.Printf("%d ", i)
}
}
func main() {
loop()
loop()
}
毫无疑问,输出会是这样的:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9下面我们把一个loop放在一个goroutine里跑,我们可以使用关键字go来定义并启动一个goroutine:
func main() {
go loop() // 启动一个goroutine loop()
}
这次的输出变成了:
0 1 2 3 4 5 6 7 8 9可是为什么只输出了一趟呢?明明我们主线跑了一趟,也开了一个goroutine来跑一趟啊。
原来,在goroutine还没来得及跑loop的时候,主函数已经退出了。
main函数退出地太快了,我们要想办法阻止它过早地退出,一个办法是让main等待一下:
func main() {
go loop()
loop()
time.Sleep(time.Second) // 停顿一秒}
这次确实输出了两趟,目的达到了。
可是采用等待的办法并不好,如果goroutine在结束的时候,告诉下主线说"Hey, 我要跑完了!"就好了,即所谓阻塞主线的办法,回忆下我们Python里面等待所有线程执行完毕的写法:
for thread in threads:
thread.join()
是的,我们也需要一个类似join的东西来阻塞住主线。那就是信道
信道
信道是什么?简单说,是goroutine之间互相通讯的东西。类似我们Unix上的管道(可以在进程间传递消息),用来goroutine之间发消息和接收消息。其实,就是在做goroutine之间的内存共享。
使用make来建立一个信道:
var channel chan
int = make(chan
int)
// 或channel := make(chan
int)
那如何向信道存消息和取消息呢?一个例子:
func main() {
var messages chan
string = make(chan
string)
go
func(message string) {
messages <- message // 存消息 }("Ping!")
fmt.Println(<-messages) // 取消息}
默认的,信道的存消息和取消息都是阻塞的 (叫做无缓冲的信道,不过缓冲这个概念稍后了解,先说阻塞的问题)。
也就是说, 无缓冲的信道在取消息和存消息的时候都会挂起当前的goroutine,除非另一端已经准备好。
比如以下的main函数和foo函数:
var ch chan
int = make(chan
int)
func foo() {
ch <- 0
// 向ch中加数据,如果没有其他goroutine来取走这个数据,那么挂起foo, 直到main函数把0这个数据拿走}
func main() {
go foo()
<- ch // 从ch取数据,如果ch中还没放数据,那就挂起main线,直到foo函数中放数据为止}
那既然信道可以阻塞当前的goroutine, 那么回到上一部分「goroutine」所遇到的问题「如何让goroutine告诉主线我执行完毕了」的问题来, 使用一个信道来告诉主线即可:
var complete chan
int = make(chan
int)
func loop() {
for i := 0; i < 10; i++ {
fmt.Printf("%d ", i)
}
complete <- 0
// 执行完毕了,发个消息}
func main() {
go loop()
<- complete // 直到线程跑完, 取到消息. main在此阻塞住}
如果不用信道来阻塞主线的话,主线就会过早跑完,loop线都没有机会执行、、、
其实,无缓冲的信道永远不会存储数据,只负责数据的流通,为什么这么讲呢?
- 从无缓冲信道取数据,必须要有数据流进来才可以,否则当前线阻塞
- 数据流入无缓冲信道, 如果没有其他goroutine来拿走这个数据,那么当前线阻塞
所以,你可以测试下,无论如何,我们测试到的无缓冲信道的大小都是0 (len(channel))
如果信道正有数据在流动,我们还要加入数据,或者信道干涩,我们一直向无数据流入的空信道取数据呢?就会引起死锁
死锁
一个死锁的例子:
func main() {
ch := make(chan
int)
<- ch // 阻塞main goroutine, 信道c被锁}
执行这个程序你会看到Go报这样的错误:
fatal error: all goroutines are asleep - deadlock!何谓死锁? 操作系统有讲过的,所有的线程或进程都在等待资源的释放。如上的程序中, 只有一个goroutine, 所以当你向里面加数据或者存数据的话,都会锁死信道,并且阻塞当前 goroutine, 也就是所有的goroutine(其实就main线一个)都在等待信道的开放(没人拿走数据信道是不会开放的),也就是死锁咯。
我发现死锁是一个很有意思的话题,这里有几个死锁的例子:
- 只在单一的goroutine里操作无缓冲信道,一定死锁。比如你只在main函数里操作信道:
func main() {
ch := make(chan
int)
ch <- 1
// 1流入信道,堵塞当前线, 没人取走数据信道不会打开fmt.Println("This line code wont run") //在此行执行之前Go就会报死锁}
- 如下也是一个死锁的例子:
var ch1 chan
int = make(chan
int)
var ch2 chan
int = make(chan
int)
func say(s string) {
fmt.Println(s)
ch1 <- <- ch2 // ch1 等待 ch2流出的数据}
func main() {
go say("hello")
<- ch1 // 堵塞主线}
其中主线等ch1中的数据流出,ch1等ch2的数据流出,但是ch2等待数据流入,两个goroutine都在等,也就是死锁。
- 其实,总结来看,为什么会死锁?非缓冲信道上如果发生了流入无流出,或者流出无流入,也就导致了死锁。或者这样理解 Go启动的所有goroutine里的非缓冲信道一定要一个线里存数据,一个线里取数据,要成对才行 。所以下面的示例一定死锁:
c, quit := make(chan
int), make(chan
int)
go
func() {
c <- 1
// c通道的数据没有被其他goroutine读取走,堵塞当前goroutinequit <- 0
// quit始终没有办法写入数据}()
<- quit // quit 等待数据的写仔细分析的话,是由于:主线等待quit信道的数据流出,quit等待数据写入,而func被c通道堵塞,所有goroutine都在等,所以死锁。
简单来看的话,一共两个线,func线中流入c通道的数据并没有在main线中流出,肯定死锁。
但是,是否果真 所有不成对向信道存取数据的情况都是死锁?
如下是个反例:
func main() {
c := make(chan
int)
go
func() {
c <- }()
}
程序正常退出了,很简单,并不是我们那个总结不起作用了,还是因为一个让人很囧的原因,main又没等待其它goroutine,自己先跑完了,所以没有数据流入c信道,一共执行了一个goroutine, 并且没有发生阻塞,所以没有死锁错误。
那么死锁的解决办法呢?
最简单的,把没取走的数据取走,没放入的数据放入,因为无缓冲信道不能承载数据,那么就赶紧拿走!
具体来讲,就死锁例子3中的情况,可以这么避免死锁:
c, quit := make(chan
int), make(chan
int)
go
func() {
c <- quit <- }()
<- c // 取走c的数据!<-quit
另一个解决办法是缓冲信道, 即设置c有一个数据的缓冲大小:
c := make(chan
int, 1)
这样的话,c可以缓存一个数据。也就是说,放入一个数据,c并不会挂起当前线, 再放一个才会挂起当前线直到第一个数据被其他goroutine取走, 也就是只阻塞在容量一定的时候,不达容量不阻塞。
这十分类似我们python中的队列Queue不是吗?
无缓冲信道的数据进出顺序
我们已经知道,无缓冲信道从不存储数据,流入的数据必须要流出才可以。
观察以下的程序:
var ch chan
int = make(chan
int)
func foo(id int) { //id: 这个routine的标号 ch <- id
}
func main() {
// 开启5个routine
for i := 0; i < 5; i++ {
go foo(i)
}
// 取出信道中的数据
for i := 0; i < 5; i++ {
fmt.Print(<- ch)
}
}
我们开了5个goroutine,然后又依次取数据。其实整个的执行过程细分的话,5个线的数据依次流过信道ch, main打印之, 而宏观上我们看到的即 无缓冲信道的数据是先到先出,但是无缓冲信道并不存储数据,只负责数据的流通
缓冲信道
终于到了这个话题了, 其实缓存信道用英文来讲更为达意: buffered channel.
缓冲这个词意思是,缓冲信道不仅可以流通数据,还可以缓存数据。它是有容量的,存入一个数据的话 , 可以先放在信道里,不必阻塞当前线而等待该数据取走。
当缓冲信道达到满的状态的时候,就会表现出阻塞了,因为这时再也不能承载更多的数据了,「你们必须把数据拿走,才可以流入数据」。
在声明一个信道的时候,我们给make以第二个参数来指明它的容量(默认为0,即无缓冲):
var ch chan
int = make(chan
int, 2) // 写入2个元素都不会阻塞当前goroutine, 存储个数达到2的时候会阻塞如下的例子,缓冲信道ch可以无缓冲的流入3个元素:
func main() {
ch := make(chan
int, 3)
ch <- ch <- ch <- }
如果你再试图流入一个数据的话,信道ch会阻塞main线, 报死锁。
也就是说,缓冲信道会在满容量的时候加锁。
其实,缓冲信道是先进先出的,我们可以把缓冲信道看作为一个线程安全的队列:
func main() {
ch := make(chan
int, 3)
ch <- ch <- ch <- fmt.Println(<-ch) // 1 fmt.Println(<-ch) // 2 fmt.Println(<-ch) // 3}
信道数据读取和信道关闭
你也许发现,上面的代码一个一个地去读取信道简直太费事了,Go语言允许我们使用range来读取信道:
func main() {
ch := make(chan
int, 3)
ch <- ch <- ch <-
for v := range ch {
fmt.Println(v)
}
}
如果你执行了上面的代码,会报死锁错误的,原因是range不等到信道关闭是不会结束读取的。也就是如果缓冲信道干涸了,那么range就会阻塞当前goroutine, 所以死锁咯。
那么,我们试着避免这种情况,比较容易想到的是读到信道为空的时候就结束读取:
ch := make(chan
int, 3)
ch <- ch <- ch <- for v := range ch {
fmt.Println(v)
if
len(ch) <= 0 { // 如果现有数据量为0,跳出循环
break }
}
以上的方法是可以正常输出的,但是注意检查信道大小的方法不能在信道存取都在发生的时候用于取出所有数据,这个例子是因为我们只在ch中存了数据,现在一个一个往外取,信道大小是递减的。
另一个方式是显式地关闭信道:
ch := make(chan
int, 3)
ch <- ch <- ch <- // 显式地关闭信道close(ch)
for v := range ch {
fmt.Println(v)
}
被关闭的信道会禁止数据流入, 是只读的。我们仍然可以从关闭的信道中取出数据,但是不能再写入数据了。
等待多gorountine的方案
那好,我们回到最初的一个问题,使用信道堵塞主线,等待开出去的所有goroutine跑完。
这是一个模型,开出很多小goroutine, 它们各自跑各自的,最后跑完了向主线报告。
我们讨论如下2个版本的方案:
- 只使用单个无缓冲信道阻塞主线
- 使用容量为goroutines数量的缓冲信道
对于方案1, 示例的代码大概会是这个样子:
var quit chan
int
// 只开一个信道func foo(id int) {
fmt.Println(id)
quit <- 0
// ok, finished}
func main() {
count := quit = make(chan
int) // 无缓冲
for i := 0; i < count; i++ {
go foo(i)
}
for i := 0; i < count; i++ {
<- quit
}
}
对于方案2, 把信道换成缓冲1000的:
quit = make(chan
int, count) // 容量1000其实区别仅仅在于一个是缓冲的,一个是非缓冲的。
对于这个场景而言,两者都能完成任务, 都是可以的。
- 无缓冲的信道是一批数据一个一个的「流进流出」
- 缓冲信道则是一个一个存储,然后一起流出去
Go语言的并发和并行
不知道你有没有注意到一个现象,还是这段代码,如果我跑在两个goroutines里面的话:
var quit chan
int = make(chan
int)
func loop() {
for i := 0; i < 10; i++ {
fmt.Printf("%d ", i)
}
quit <- }
func main() {
// 开两个goroutine跑函数loop, loop函数负责打印10个数
go loop()
go loop()
for i := 0; i < 2; i++ {
<- quit
}
}
我们观察下输出:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9这是不是有什么问题??
以前我们用线程去做类似任务的时候,系统的线程会抢占式地输出,表现出来的是乱序地输出。而goroutine为什么是这样输出的呢?
goroutine是在并行吗?
我们找个例子测试下:
package main
import
"fmt"import
"time"var quit chan
intfunc foo(id int) {
fmt.Println(id)
time.Sleep(time.Second) // 停顿一秒 quit <- 0
// 发消息:我执行完啦!}
func main() {
count := quit = make(chan
int, count) // 缓冲1000个数据
for i := 0; i < count; i++ { //开1000个goroutine
go foo(i)
}
for i :=0 ; i < count; i++ { // 等待所有完成消息发送完毕。 <- quit
}
}
让我们跑一下这个程序(之所以先编译再运行,是为了让程序跑的尽量快,测试结果更好):
go build test.go
time ./test
./test 0.01s user 0.01s system 1% cpu 1.016 total
我们看到,总计用时接近一秒。貌似并行了!
我们需要首先考虑下什么是并发, 什么是并行
并行和并发
从概念上讲,并发和并行是不同的, 简单来说看这个图片(原图来自这里)


- 两个队列,一个Coffee机器,那是并发
- 两个队列,两个Coffee机器,那是并行
更多的资料: 并发不是并行, 当然Google上有更多关于并行和并发的区别。
那么回到一开始的疑问上,从上面的两个例子执行后的表现来看,多个goroutine跑loop函数会挨个goroutine去进行,而sleep则是一起执行的。
这是为什么?
默认地, Go所有的goroutines只能在一个线程里跑 。
也就是说,以上两个代码都不是并行的,但是都是是并发的。
如果当前goroutine不发生阻塞,它是不会让出CPU给其他goroutine的, 所以例子一中的输出会是一个一个goroutine进行的,而sleep函数则阻塞掉了当前goroutine, 当前goroutine主动让其他goroutine执行, 所以形成了逻辑上的并行, 也就是并发。
真正的并行
为了达到真正的并行,我们需要告诉go我们允许同时最多使用多个核。
回到起初的例子,我们设置最大开2个原生线程, 我们需要用到runtime包(runtime包是goroutine的调度器):
import (
"fmt"
"runtime")
var quit chan
int = make(chan
int)
func loop() {
for i := 0; i < 100; i++ { //为了观察,跑多些 fmt.Printf("%d ", i)
}
quit <- }
func main() {
runtime.GOMAXPROCS(2) // 最多使用2个核
go loop()
go loop()
for i := 0; i < 2; i++ {
<- quit
}
}
这下会看到两个goroutine会抢占式地输出数据了。
我们还可以这样显式地让出CPU时间:
func loop() {
for i := 0; i < 10; i++ {
runtime.Gosched() // 显式地让出CPU时间给其他goroutine fmt.Printf("%d ", i)
}
quit <- }
func main() {
go loop()
go loop()
for i := 0; i < 2; i++ {
<- quit
}
}
观察下结果会看到这样有规律的输出:
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9其实,这种主动让出CPU时间的方式仍然是在单核里跑。但手工地切换goroutine导致了看上去的"并行"。
其实作为一个Python程序员,goroutine让我更多地想到的是gevent的协程,而不是原生线程。
关于runtime包对goroutine的调度,在stackoverflow上有一个不错的答案:http://stackoverflow.com/questions/13107958/what-exactly-does-runtime-gosched-do
一个小问题
我在Segmentfault看到了这个问题: http://segmentfault.com/q/1010000000207474
题目说,如下的程序,按照理解应该打印下5次 "world"呀,可是为什么什么也没有打印
package main
import (
"fmt")
func say(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
}
}
func main() {
go say("world") //开一个新的Goroutines执行
for {
}
}
楼下的答案已经很棒了,这里Go仍然在使用单核,for死循环占据了单核CPU所有的资源,而main线和say两个goroutine都在一个线程里面,所以say没有机会执行。解决方案还是两个:
- 允许Go使用多核(runtime.GOMAXPROCS)
- 手动显式调动(runtime.Gosched)
runtime调度器
runtime调度器是个很神奇的东西,但是我真是但愿它不存在,我希望显式调度能更为自然些,多核处理默认开启。
关于runtime包几个函数:
- Gosched 让出cpu
- NumCPU 返回当前系统的CPU核数量
- GOMAXPROCS 设置最大的可同时使用的CPU核数
- Goexit 退出当前goroutine(但是defer语句会照常执行)
总结
我们从例子中可以看到,默认的, 所有goroutine会在一个原生线程里跑,也就是只使用了一个CPU核。
在同一个原生线程里,如果当前goroutine不发生阻塞,它是不会让出CPU时间给其他同线程的goroutines的,这是Go运行时对goroutine的调度,我们也可以使用runtime包来手工调度。
本文开头的两个例子都是限制在单核CPU里执行的,所有的goroutines跑在一个线程里面,分析如下:
- 对于代码例子一(loop函数的那个),每个goroutine没有发生堵塞(直到quit流入数据), 所以在quit之前每个goroutine不会主动让出CPU,也就发生了串行打印
- 对于代码例子二(time的那个),每个goroutine在sleep被调用的时候会阻塞,让出CPU, 所以例子二并发执行。
那么关于我们开启多核的时候呢?Go语言对goroutine的调度行为又是怎么样的?
我们可以在Golang官方网站的这里 找到一句话:
When a coroutine blocks, such as by calling a blocking system call, the run-time automatically moves other coroutines on the same operating system thread to a different, runnable thread so they won't be blocked.
也就是说:
当一个goroutine发生阻塞,Go会自动地把与该goroutine处于同一系统线程的其他goroutines转移到另一个系统线程上去,以使这些goroutines不阻塞
开启多核的实验
仍然需要做一个实验,来测试下多核支持下goroutines的对原生线程的分配, 也验证下我们所得到的结论"goroutine不阻塞不放开CPU"。
实验代码如下:
package main
import (
"fmt"
"runtime")
var quit chan
int = make(chan
int)
func loop(id int) { // id: 该goroutine的标号
for i := 0; i < 10; i++ { //打印10次该goroutine的标号 fmt.Printf("%d ", id)
}
quit <- }
func main() {
runtime.GOMAXPROCS(2) // 最多同时使用2个核
for i := 0; i < 3; i++ { //开三个goroutine
go loop(i)
}
for i := 0; i < 3; i++ {
<- quit
}
}
多跑几次会看到类似这些输出(不同机器环境不一样):
0 0 0 0 0 1 1 0 0 1 0 0 1 0 1 2 1 2 1 2 1 2 1 2 1 2 2 2 2 2
0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2
0 0 0 0 0 0 0 1 1 1 1 1 0 1 0 1 0 1 2 1 2 1 2 2 2 2 2 2 2 2
0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 2 0 2 0 2 2 2 2 2 2 2 2
0 0 0 0 0 0 0 1 0 0 1 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 2 2
执行它我们会发现以下现象:
- 有时会发生抢占式输出(说明Go开了不止一个原生线程,达到了真正的并行)
- 有时会顺序输出, 打印完0再打印1, 再打印2(说明Go开一个原生线程,单线程上的goroutine不阻塞不松开CPU)
那么,我们还会观察到一个现象,无论是抢占地输出还是顺序的输出,都会有那么两个数字表现出这样的现象:
- 一个数字的所有输出都会在另一个数字的所有输出之前
原因是, 3个goroutine分配到至多2个线程上,就会至少两个goroutine分配到同一个线程里,单线程里的goroutine 不阻塞不放开CPU, 也就发生了顺序输出。
Go语言并发的设计模式和应用场景
以下设计模式和应用场景来自Google IO上的关于Goroutine的PPT:https://talks.golang.org/2012/concurrency.slide
本文的示例代码在: https://github.com/hit9/Go-patterns-with-channel
生成器
在Python中我们可以使用yield关键字来让一个函数成为生成器,在Go中我们可以使用信道来制造生成器(一种lazy load类似的东西)。
当然我们的信道并不是简单的做阻塞主线的功能来使用的哦。
下面是一个制作自增整数生成器的例子,直到主线向信道索要数据,我们才添加数据到信道
func xrange() chan
int{ // xrange用来生成自增的整数
var ch chan
int = make(chan
int)
go
func() { // 开出一个goroutine
for i := 0; ; i++ {
ch <- i // 直到信道索要数据,才把i添加进信道 }
}()
return ch
}
func main() {
generator := xrange()
for i:=0; i < 1000; i++ { // 我们生成1000个自增的整数! fmt.Println(<-generator)
}
}
这不禁叫我想起了python中可爱的xrange, 所以给了生成器这个名字!
服务化
比如我们加载一个网站的时候,例如我们登入新浪微博,我们的消息数据应该来自一个独立的服务,这个服务只负责返回某个用户的新的消息提醒。
如下是一个使用示例:
func get_notification(user string) chan
string{
/* * 此处可以查询数据库获取新消息等等.. */ notifications := make(chan
string)
go
func() { // 悬挂一个信道出去 notifications <- fmt.Sprintf("Hi %s, welcome to weibo.com!", user)
}()
return notifications
}
func main() {
jack := get_notification("jack") // 获取jack的消息 joe := get_notification("joe") // 获取joe的消息
// 获取消息的返回 fmt.Println(<-jack)
fmt.Println(<-joe)
}
多路复合
上面的例子都使用一个信道作为返回值,可以把信道的数据合并到一个信道的。不过这样的话,我们需要按顺序输出我们的返回值(先进先出)。
如下,我们假设要计算很复杂的一个运算 100-x , 分为三路计算,最后统一在一个信道中取出结果:
func do_stuff(x int) int { // 一个比较耗时的事情,比如计算 time.Sleep(time.Duration(rand.Intn(10)) * time.Millisecond) //模拟计算
return
100 - x // 假如100-x是一个很费时的计算}
func branch(x int) chan
int{ // 每个分支开出一个goroutine做计算并把计算结果流入各自信道 ch := make(chan
int)
go
func() {
ch <- do_stuff(x)
}()
return ch
}
func fanIn(chs... chan
int) chan
int {
ch := make(chan
int)
for _, c := range chs {
// 注意此处明确传值
go
func(c chan
int) {ch <- <- c}(c) // 复合 }
return ch
}
func main() {
result := fanIn(branch(1), branch(2), branch(3))
for i := 0; i < 3; i++ {
fmt.Println(<-result)
}
}
select监听信道
go有一个语句叫做select,用于监测各个信道的数据流动。
如下的程序是select的一个使用例子,我们监视三个信道的数据流出并收集数据到一个信道中。
func foo(i int) chan
int {
c := make(chan
int)
go
func () { c <- i }()
return c
}
func main() {
c1, c2, c3 := foo(1), foo(2), foo(3)
c := make(chan
int)
go
func() { // 开一个goroutine监视各个信道数据输出并收集数据到信道c
for {
select { // 监视c1, c2, c3的流出,并全部流入信道c
case v1 := <- c1: c <- v1
case v2 := <- c2: c <- v2
case v3 := <- c3: c <- v3
}
}
}()
// 阻塞主线,取出信道c的数据
for i := 0; i < 3; i++ {
fmt.Println(<-c) // 从打印来看我们的数据输出并不是严格的1,2,3顺序 }
}
有了select, 我们在多路复合中的示例代码中的函数fanIn还可以这么来写(这样就不用开好几个goroutine来取数据了):
func fanIn(branches ... chan
int) chan
int {
c := make(chan
int)
go
func() {
for i := 0 ; i < len(branches); i++ { //select会尝试着依次取出各个信道的数据
select {
case v1 := <- branches[i]: c <- v1
}
}
}()
return c
}
使用select的时候,有时需要超时处理, 其中的timeout信道相当有趣:
timeout := time.After(1 * time.Second) // timeout 是一个计时信道, 如果达到时间了,就会发一个信号出来for is_timeout := false; !is_timeout; {
select { // 监视信道c1, c2, c3, timeout信道的数据流出
case v1 := <- c1: fmt.Printf("received %d from c1", v1)
case v2 := <- c2: fmt.Printf("received %d from c2", v2)
case v3 := <- c3: fmt.Printf("received %d from c3", v3)
case <- timeout: is_timeout = true
// 超时 }
}
结束标志
在Go并发与并行笔记一我们已经讲过信道的一个很重要也很平常的应用,就是使用无缓冲信道来阻塞主线,等待goroutine结束。
这样我们不必再使用timeout。
那么对上面的timeout来结束主线的方案作个更新:
func main() {
c, quit := make(chan
int), make(chan
int)
go
func() {
c <- 2
// 添加数据 quit <- 1
// 发送完成信号 } ()
for is_quit := false; !is_quit; {
select { // 监视信道c的数据流出
case v := <-c: fmt.Printf("received %d from c", v)
case <-quit: is_quit = true
// quit信道有输出,关闭for循环 }
}
}
菊花链


简单地来说,数据从一端流入,从另一端流出,看上去好像一个链表,不知道为什么要取这么个尴尬的名字。。
菊花链的英文名字叫做: Daisy-chain, 它的一个应用就是做过滤器,比如我们来筛下100以内的素数(你需要先知道什么是筛法)
程序有详细的注释,不再说明了。
/* * 利用信道菊花链筛法求某一个整数范围的素数 * 筛法求素数的基本思想是:把从1开始的、某一范围内的正整数从小到大顺序排列, * 1不是素数,首先把它筛掉。剩下的数中选择最小的数是素数,然后去掉它的倍数。 * 依次类推,直到筛子为空时结束 */package main
import
"fmt"func xrange() chan
int{ // 从2开始自增的整数生成器
var ch chan
int = make(chan
int)
go
func() { // 开出一个goroutine
for i := 2; ; i++ {
ch <- i // 直到信道索要数据,才把i添加进信道 }
}()
return ch
}
func filter(in chan
int, number int) chan
int {
// 输入一个整数队列,筛出是number倍数的, 不是number的倍数的放入输出队列
// in: 输入队列 out := make(chan
int)
go
func() {
for {
i := <- in // 从输入中取一个
if i % number != 0 {
out <- i // 放入输出信道 }
}
}()
return out
}
func main() {
const max = 100
// 找出100以内的所有素数 nums := xrange() // 初始化一个整数生成器 number := <-nums // 从生成器中抓一个整数(2), 作为初始化整数
for number <= max { // number作为筛子,当筛子超过max的时候结束筛选 fmt.Println(number) // 打印素数, 筛子即一个素数 nums = filter(nums, number) //筛掉number的倍数 number = <- nums // 更新筛子 }
}
随机数生成器
信道可以做生成器使用,作为一个特殊的例子,它还可以用作随机数生成器。如下是一个随机01生成器:
func rand01() chan
int {
ch := make(chan
int)
go
func () {
for {
select { //select会尝试执行各个case, 如果都可以执行,那么随机选一个执行
case ch <- 0:
case ch <- 1:
}
}
}()
return ch
}
func main() {
generator := rand01() //初始化一个01随机生成器
//测试,打印10个随机01
for i := 0; i < 10; i++ {
fmt.Println(<-generator)
}
}
定时器
我们刚才其实已经接触了信道作为定时器, time包里的After会制作一个定时器。
看看我们的定时器吧!
/* * 利用信道做定时器 */package main
import (
"fmt"
"time")
func timer(duration time.Duration) chan
bool {
ch := make(chan
bool)
go
func() {
time.Sleep(duration)
ch <- true
// 到时间啦! }()
return ch
}
func main() {
timeout := timer(time.Second) // 定时1s
for {
select {
case <- timeout:
fmt.Println("already 1s!") // 到时间
return
//结束程序 }
}
}
TODO
Google的应用场景例子。

本篇主要总结了使用信道, goroutine的一些设计模式。
Go语言 Channel <- 箭头操作符 详解
2017年07月05日 16:12:12
阅读数:6093
Channel是Go中的一个核心类型,你可以把它看成一个管道,通过它并发核心单元就可以发送或者接收数据进行通讯(communication)。
它的操作符是箭头 <- 。
ch <- v // 发送值v到Channel ch中
v := <-ch // 从Channel ch中接收数据,并将数据赋值给v
(箭头的指向就是数据的流向)
就像 map 和 slice 数据类型一样, channel必须先创建再使用:
ch := make(chan int)
Channel类型
Channel类型的定义格式如下:
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
它包括三种类型的定义。可选的<-代表channel的方向。如果没有指定方向,那么Channel就是双向的,既可以接收数据,也可以发送数据。
chan T // 可以接收和发送类型为 T 的数据
chan<- float64 // 只可以用来发送 float64 类型的数据
<-chan int // 只可以用来接收 int 类型的数据
<-总是优先和最左边的类型结合。(The <- operator associates with the leftmost chan possible)
chan<- chan int // 等价 chan<- (chan int)
chan<- <-chan int // 等价 chan<- (<-chan int)
<-chan <-chan int // 等价 <-chan (<-chan int)
chan (<-chan int)
使用make初始化Channel,并且可以设置容量:
make(chan int, 100)
容量(capacity)代表Channel容纳的最多的元素的数量,代表Channel的缓存的大小。
如果没有设置容量,或者容量设置为0, 说明Channel没有缓存,只有sender和receiver都准备好了后它们的通讯(communication)才会发生(Blocking)。如果设置了缓存,就有可能不发生阻塞,只有buffer满了后 send才会阻塞,而只有缓存空了后receive才会阻塞。一个nil channel不会通信。
可以通过内建的close方法可以关闭Channel。
你可以在多个goroutine从/往一个channel 中 receive/send 数据, 不必考虑额外的同步措施。
Channel可以作为一个先入先出(FIFO)的队列,接收的数据和发送的数据的顺序是一致的。
channel的 receive支持 multi-valued assignment,如
v, ok := <-ch
它可以用来检查Channel是否已经被关闭了。
- send语句
send语句用来往Channel中发送数据,如ch <- 3。
它的定义如下: SendStmt = Channel "<-" Expression .
Channel = Expression .
在通讯(communication)开始前channel和expression必选先求值出来(evaluated),比如下面的(3+4)先计算出7然后再发送给channel。
c := make(chan int)
defer close(c)
go func() { c <- 3 + 4 }()
i := <-c
fmt.Println(i)
send被执行前(proceed)通讯(communication)一直被阻塞着。如前所言,无缓存的channel只有在receiver准备好后send才被执行。如果有缓存,并且缓存未满,则send会被执行。
往一个已经被close的channel中继续发送数据会导致run-time panic。
往nil channel中发送数据会一致被阻塞着。
- receive 操作符
<-ch用来从channel ch中接收数据,这个表达式会一直被block,直到有数据可以接收。
从一个nil channel中接收数据会一直被block。
从一个被close的channel中接收数据不会被阻塞,而是立即返回,接收完已发送的数据后会返回元素类型的零值(zero value)。
如前所述,你可以使用一个额外的返回参数来检查channel是否关闭。
x, ok := <-ch
x, ok = <-ch
var x, ok = <-ch
如果OK 是false,表明接收的x是产生的零值,这个channel被关闭了或者为空。
blocking
缺省情况下,发送和接收会一直阻塞着,直到另一方准备好。这种方式可以用来在gororutine中进行同步,而不必使用显示的锁或者条件变量。
如官方的例子中x, y := <-c, <-c这句会一直等待计算结果发送到channel中。
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // send sum to c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c // receive from c
fmt.Println(x, y, x+y)
}
Buffered Channels
make的第二个参数指定缓存的大小:ch := make(chan int, 100)。
通过缓存的使用,可以尽量避免阻塞,提供应用的性能。
Range
for …… range语句可以处理Channel。
func main() {
go func() {
time.Sleep(1 * time.Hour)
}()
c := make(chan int)
go func() {
for i := 0; i < 10; i = i + 1 {
c <- i
}
close(c)
}()
for i := range c {
fmt.Println(i)
}
fmt.Println("Finished")
}
range c产生的迭代值为Channel中发送的值,它会一直迭代直到channel被关闭。上面的例子中如果把close(c)注释掉,程序会一直阻塞在for …… range那一行。
select
select语句选择一组可能的send操作和receive操作去处理。它类似switch,但是只是用来处理通讯(communication)操作。
它的case可以是send语句,也可以是receive语句,亦或者default。
receive语句可以将值赋值给一个或者两个变量。它必须是一个receive操作。
最多允许有一个default case,它可以放在case列表的任何位置,尽管我们大部分会将它放在最后。
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
如果有同时多个case去处理,比如同时有多个channel可以接收数据,那么Go会伪随机的选择一个case处理(pseudo-random)。如果没有case需要处理,则会选择default去处理,如果default case存在的情况下。如果没有default case,则select语句会阻塞,直到某个case需要处理。
需要注意的是,nil channel上的操作会一直被阻塞,如果没有default case,只有nil channel的select会一直被阻塞。
select语句和switch语句一样,它不是循环,它只会选择一个case来处理,如果想一直处理channel,你可以在外面加一个无限的for循环:
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
timeout
select有很重要的一个应用就是超时处理。因为上面我们提到,如果没有case需要处理,select语句就会一直阻塞着。这时候我们可能就需要一个超时操作,用来处理超时的情况。
下面这个例子我们会在2秒后往channel c1中发送一个数据,但是select设置为1秒超时,因此我们会打印出timeout 1,而不是result 1。
import "time"
import "fmt"
func main() {
c1 := make(chan string, 1)
go func() {
time.Sleep(time.Second * 2)
c1 <- "result 1"
}()
select {
case res := <-c1:
fmt.Println(res)
case <-time.After(time.Second * 1):
fmt.Println("timeout 1")
}
}
其实它利用的是time.After方法,它返回一个类型为<-chan Time的单向的channel,在指定的时间发送一个当前时间给返回的channel中。
Timer和Ticker
我们看一下关于时间的两个Channel。
timer是一个定时器,代表未来的一个单一事件,你可以告诉timer你要等待多长时间,它提供一个Channel,在将来的那个时间那个Channel提供了一个时间值。下面的例子中第二行会阻塞2秒钟左右的时间,直到时间到了才会继续执行。
timer1 := time.NewTimer(time.Second * 2)
<-timer1.C
fmt.Println("Timer 1 expired")
当然如果你只是想单纯的等待的话,可以使用time.Sleep来实现。
你还可以使用timer.Stop来停止计时器。
timer2 := time.NewTimer(time.Second)
go func() {
<-timer2.C
fmt.Println("Timer 2 expired")
}()
stop2 := timer2.Stop()
if stop2 {
fmt.Println("Timer 2 stopped")
}
ticker是一个定时触发的计时器,它会以一个间隔(interval)往Channel发送一个事件(当前时间),而Channel的接收者可以以固定的时间间隔从Channel中读取事件。下面的例子中ticker每500毫秒触发一次,你可以观察输出的时间。
ticker := time.NewTicker(time.Millisecond * 500)
go func() {
for t := range ticker.C {
fmt.Println("Tick at", t)
}
}()
类似timer, ticker也可以通过Stop方法来停止。一旦它停止,接收者不再会从channel中接收数据了。
close
内建的close方法可以用来关闭channel。
总结一下channel关闭后sender的receiver操作。
如果channel c已经被关闭,继续往它发送数据会导致panic: send on closed channel:
import "time"
func main() {
go func() {
time.Sleep(time.Hour)
}()
c := make(chan int, 10)
c <- 1
c <- 2
close(c)
c <- 3
}
但是从这个关闭的channel中不但可以读取出已发送的数据,还可以不断的读取零值:
c := make(chan int, 10)
c <- 1
c <- 2
close(c)
fmt.Println(<-c) //1
fmt.Println(<-c) //2
fmt.Println(<-c) //0
fmt.Println(<-c) //0
但是如果通过range读取,channel关闭后for循环会跳出:
c := make(chan int, 10)
c <- 1
c <- 2
close(c)
for i := range c {
fmt.Println(i)
}
通过i, ok := <-c可以查看Channel的状态,判断值是零值还是正常读取的值。
c := make(chan int, 10)
close(c)
i, ok := <-c
fmt.Printf("%d, %t", i, ok) //0, false
同步
channel可以用在goroutine之间的同步。
下面的例子中main goroutine通过done channel等待worker完成任务。 worker做完任务后只需往channel发送一个数据就可以通知main goroutine任务完成。
import (
"fmt"
"time"
)
func worker(done chan bool) {
time.Sleep(time.Second)
// 通知任务已完成
done <- true
}
func main() {
done := make(chan bool, 1)
go worker(done)
// 等待任务完成
<-done
}
golang学习笔记之—WaitGroup
自己毕业工作过后,由于时间有限,一度中断了写学习笔记。
最近心血来潮,逛CSDN发现博客已经改版了,添加了对Markdown语法的支持。加之最近在学习google的go语言,因此想借写博客的机会学习Markdown语言,同时梳理所学的go语言知识。
本文主要讲解go标准库sync中的WaitGroup的用法。
WaitGroup的作用
WaitGroup用于goroutine的同步,当需要阻塞当前执行线程,等待一组goroutine执行完毕之后再继续执行当前线程时,就需要用到WaitGroup。
WaitGroup的定义
type WaitGroup struct {
state1 [12]byte
sema uint32
}
WaitGroup的定义比较简单,由一个12字节额 state1 字段和一个32位的 sema 组成。
WaitGroup的API
1.Add(delta int)
Add的原型声明如下:
func (wg *WaitGroup) Add(delta int)
Add函数接受一个int型的参数delta,用于设置WaitGroup实例(wg)的计数器,当计数器变为0时,所有因为在该wg上调用Wait而阻塞的goroutine的都会被唤醒。
若调用Add导致计数器变为负数,会引起panic。
2.Done()
Done的原型声明如下:
func (wg *WaitGroup) Done()
Done函数的作用很简单,就是将wg的计数器减一。该函数等同于wg.Add(-1),从go的源码中可以看到Done()就是用wg.Add(-1)实现的。
// Done decrements the WaitGroup counter.
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
3.Wait()
Wait的原型声明如下:
func (wg *WaitGroup) Wait()
Wait会阻塞调用该函数的goroutine,直到wg的计数器变为1。
WaitGroup的用法
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int){
fmt.Println("Hello world",i)
wg.Done()
}(i)
}
wg.Wait()
}
该程序启动了十个goroutine,并在main函数中使用wg.Wait等待这些goroutine执行结束。该程序的输出如下:
Hello world 9
Hello world 2
Hello world 3
Hello world 4
Hello world 5
Hello world 6
Hello world 7
Hello world 0
Hello world 8
Hello world 1
若去掉示例代码中wg的使用,则不会输出任何信息,因为main函数在goroutine执行之前就结束了。
Go语言WaitGroup使用时需要注意的坑
Go语言中WaitGroup的用途是它能够一直等到所有的goroutine执行完成,并且阻塞主线程的执行,直到所有的goroutine执行完成。之前一直使用也没有问题,但最近通过同事的一段代码引起了关于WaitGroup的注意,下面这篇文章就介绍了WaitGroup使用时需要注意的坑及填坑。
前言
WaitGroup在go语言中,用于线程同步,单从字面意思理解,wait等待的意思,group组、团队的意思,WaitGroup就是指等待一组,等待一个系列执行完成后才会继续向下执行。Golang 中的 WaitGroup 一直是同步 goroutine 的推荐实践。自己用了两年多也没遇到过什么问题。
直到最近的一天同事扔过来一段奇怪的代码:
第一个坑
复制代码 代码如下:
package main
import (
"log"
"sync"
)
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 5; i++ {
go func(wg sync.WaitGroup, i int) {
wg.Add(1)
log.Printf("i:%d", i)
wg.Done()
}(wg, i)
}
wg.Wait()
log.Println("exit")
}
撇了一眼,觉得没什么问题。
然而,它的运行结果是这样:
复制代码 代码如下:
2016/11/27 15:12:36 exit
[Finished in 0.7s]
或这样:
复制代码 代码如下:
2016/11/27 15:21:51 i:2
2016/11/27 15:21:51 exit
[Finished in 0.8s]
或这样:
复制代码 代码如下:
2016/11/27 15:22:51 i:3
2016/11/27 15:22:51 i:2
2016/11/27 15:22:51 exit
[Finished in 0.8s]
一度让我以为手上的 mac 也没睡醒……
这个问题如果理解了 WaitGroup 的设计目的就非常容易 fix 啦。因为 WaitGroup 同步的是 goroutine, 而上面的代码却在 goroutine 中进行 Add(1) 操作。因此,可能在这些 goroutine 还没来得及 Add(1) 已经执行 Wait 操作了。
于是代码改成了这样:
第二个坑
复制代码 代码如下:
package main
import (
"log"
"sync"
)
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 5; i++ {
wg.Add(1)
go func(wg sync.WaitGroup, i int) {
log.Printf("i:%d", i)
wg.Done()
}(wg, i)
}
wg.Wait()
log.Println("exit")
}
然而,mac 又睡了过去,而且是睡死了过去:
复制代码 代码如下:
2016/11/27 15:25:16 i:1
2016/11/27 15:25:16 i:2
2016/11/27 15:25:16 i:4
2016/11/27 15:25:16 i:0
2016/11/27 15:25:16 i:3
fatal error: all goroutines are asleep - deadlock!
wg 给拷贝传递到了 goroutine 中,导致只有 Add 操作,其实 Done操作是在 wg 的副本执行的。因此 Wait 就死锁了。
于是代码改成了这样:
填坑
复制代码 代码如下:
package main
import (
"log"
"sync"
)
func main() {
wg := &sync.WaitGroup{}
for i := 0; i < 5; i++ {
wg.Add(1)
go func(wg *sync.WaitGroup, i int) {
log.Printf("i:%d", i)
wg.Done()
}(wg, i)
}
wg.Wait()
log.Println("exit")
}
总结
好了,到这里终于解决了,以上就是关于Go语言WaitGroup使用时需要注意的一些坑,希望本文中提到的这些问题对大家学习或者使用Go语言的时候能有所帮助,如果有疑问大家可以留言交流。
0x01 map基本操作
// 1. 声明
var m map[string]int
// 2. 初始化,声明之后必须初始化才能使用
// 向未初始化的map赋值引起 panic: assign to entry in nil map.
m = make(map[string]int)
m = map[string]int{}
// 1&2. 声明并初始化
m := make(map[string]int)
m := map[string]int{}
// 3. 增删改查
m["route"] = 66
delete(m, "route") // 如果key不存在什么都不做
i := m["route"] // 三种查询方式,如果key不存在返回value类型的零值
i, ok := m["route"]
_, ok := m["route"]
// 4. 迭代(顺序不确定)
for k, v := range m {
use(k, v)
}
// 5. 有序迭代
import "sort"
var keys []string
for k, _ := range m {
keys = append(keys, k)
}
sort.Strings(keys)
for _, k := range keys {
use(k, m[k]
}
0x02 map键类型
支持 == 操作符的类型有:
- boolean,
- numeric,
- string,
- pointer,
- channel,
- interface(as long as dynamic type supports equality),
- 以及只包含上述类型的array和struct
不支持 == 操作符的类型有:
- slice,
- map,
- func,
补充
- 不像Java可以为class自定义hashcode方法,以及C++可以重载==操作符,golang map**不支持**==重载或者使用自定义的hash方法。因此,如果想要把struct用作map的key,就必须保证struct不包含slice, map, func
- golang为uint32、uint64、string提供了fast access,使用这些类型作为key可以提高map访问速度,详见hashmap_fast.go
0x03 map并发
map不是并发安全的,通常使用sync.RWMutex保护并发map
// 声明&初始化
var counter = struct {
sync.RWMutex // gard m
m map[string]int
}{m:make(map[string]int)}
// 读锁
counter.RLock()
counter.m["route"]
counter.RUnlock()
// 写锁
counter.Lock()
counter.m["route"]++
counter.Unlock()
0x04 map小技巧
4.1. 利用value类型的零值
visited := map[*Node]bool
if visited[node] { // bool类型0值为false,所以不需要检查ok
return
}
likes := make(map[string][]*Person)
for _, p range people {
for _, l range p.Likes {
// 向一个nil的slice增加值,会自动allocate一个slice
likes[l] = append(likes[l], p)
}
}
4.2. map[k1]map[k2]v 对比 map[struct{k1, k2}]v
// map[k1]map[k2]v
hits := make(map[string]map[string]int)
func add(m map[string]map[string]int, path, country string) {
mm, ok := m[path]
if !ok {
mm = make(map[string]int) // 需要检查、创建子map
m[path] = mm
}
mm[country]++
}
add(hits, "/", "cn")
n := hits["/"]["cn"]
// map[struct{k1, k2}]v
type Key struct {
Path, Country string
}
hits := make(map[Key]int)
hits[Key{"/", "cn"}]++
n := hits[Key{"/", "cn"}]
}
0x05 map实现细节浅析
5.1. 如何计算hash值
golang为每个类型定义了类型描述器_type,并实现了hashable类型的_type.alg.hash和_type.alg.equal。
type typeAlg struct {
// function for hashing objects of this type
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
}
5.2. map实现结构
map的实现主要有三个struct,
- maptype用来保存map的类型信息,包括key、elem(value)的类型描述器,keysize,valuesize,bucketsize等;
- hmap - A header for a Go map. hmap保存了map的实例信息,包括count,buckets,oldbuckets等;buckets是bucket的首地址,用hash值的低h.B位hash & (uintptr(1)<<h.B - 1)计算出key所在bucket的index;
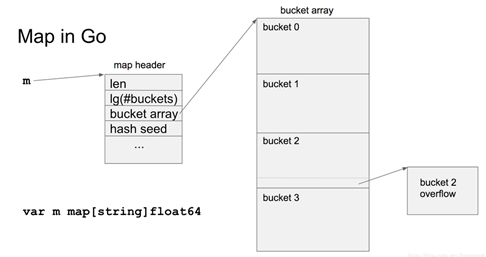
bmap - A bucket for a go map. bmap只有一个域tophash [bucketCnt]uint8,它保存了key的hash值的高8位uint8(hash >> (sys.PtrSize*8 - 8));一个bucket包括一个bmap(tophash数组),紧跟的bucketCnt个keys和bucketCnt个values,以及一个overfolw指针。

makemap根据maptype中的信息初始化hmap
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
...
// initialize Hmap
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.count = 0
h.B = B
h.flags = 0
h.hash0 = fastrand()
h.buckets = buckets
h.oldbuckets = nil
h.nevacuate = 0
h.noverflow = 0
return h
}
5.3. 如何访问map
golang的maptype保存了key的类型描述器,以供访问map时调用key.alg.hash, key.alg.equal。
type maptype struct {
key *_type
elem *_type
...
}
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 并发访问检查
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 计算key的hash值
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0)) // alg.hash
// 计算key所在的bucket的index
m := uintptr(1)<<h.B - 1
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 计算tophash
top := uint8(hash >> (sys.PtrSize*8 - 8))
...
for {
for i := uintptr(0); i < bucketCnt; i++ {
// 检查top值
if b.tophash[i] != top {
continue
}
// 取key的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) { // alg.equal
// 取value得地址
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
}
...
if b == nil {
// 返回零值
return unsafe.Pointer(&zeroVal[0])
}
}
}
5.4. map扩张
这部分留待以后有机会再续。这里暂时附上Keith Randall的slide作为参考。

0x06 map建议
- 如果知道size,预先分配资源make(map[int]int, 1000)
- uint32, uint64, string作为键,非常快
- 清理map:for k:= range m { delete(m, k) }
- key和value中没有指针可以使GC scanning更快
GO结构体组合函数
结构体定义
上面我们说过Go的指针和C的不同,结构体也是一样的。Go是一门删繁就简的语言,一切令人困惑的特性都必须去掉。
简单来讲,Go提供的结构体就是把使用各种数据类型定义的不同变量组合起来的高级数据类型。闲话不多说,看例子:
type Rect struct {
width float64
length float64
}
上面我们定义了一个矩形结构体,首先是关键是type表示要定义一个新的数据类型了,然后是新的数据类型名称Rect,最后是struct关键字,表示这个高级数据类型是结构体类型。在上面的例子中,因为width和length的数据类型相同,还可以写成如下格式:
type Rect struct {
width, length float64
}
好了,来用结构体干点啥吧,计算一下矩形面积。
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func main() {
var rect Rect
rect.width = 100
rect.length = 200
fmt.Println(rect.width * rect.length)
}
从上面的例子看到,其实结构体类型和基础数据类型使用方式差不多,唯一的区别就是结构体类型可以通过.来访问内部的成员。包括给内部成员赋值和读取内部成员值。
在上面的例子中,我们是用var关键字先定义了一个Rect变量,然后对它的成员赋值。我们也可以使用初始化的方式来给Rect变量的内部成员赋值。
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func main() {
var rect = Rect{width: 100, length: 200}
fmt.Println(rect.width * rect.length)
}
当然如果你知道结构体成员定义的顺序,也可以不使用key:value的方式赋值,直接按照结构体成员定义的顺序给它们赋值。
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func main() {
var rect = Rect{100, 200}
fmt.Println("Width:", rect.width, "* Length:",
rect.length, "= Area:", rect.width*rect.length)
}
输出结果为
Width: 100 * Length: 200 = Area: 20000
结构体参数传递方式
我们说过,Go函数的参数传递方式是值传递,这句话对结构体也是适用的。
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func double_area(rect Rect) float64 {
rect.width *= 2
rect.length *= 2
return rect.width * rect.length
}
func main() {
var rect = Rect{100, 200}
fmt.Println(double_area(rect))
fmt.Println("Width:", rect.width, "Length:", rect.length)
}
上面的例子输出为:
80000
Width: 100 Length: 200
也就说虽然在double_area函数里面我们将结构体的宽度和长度都加倍,但仍然没有影响main函数里面的rect变量的宽度和长度。
结构体组合函数
上面我们在main函数中计算了矩形的面积,但是我们觉得矩形的面积如果能够作为矩形结构体的"内部函数"提供会更好。这样我们就可以直接说这个矩形面积是多少,而不用另外去取宽度和长度去计算。现在我们看看结构体"内部函数"定义方法:
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func (rect Rect) area() float64 {
return rect.width * rect.length
}
func main() {
var rect = Rect{100, 200}
fmt.Println("Width:", rect.width, "Length:", rect.length,
"Area:", rect.area())
}
咦?这个是什么"内部方法",根本没有定义在Rect数据类型的内部啊?
确实如此,我们看到,虽然main函数中的rect变量可以直接调用函数area()来获取矩形面积,但是area()函数确实没有定义在Rect结构体内部,这点和C语言的有很大不同。Go使用组合函数的方式来为结构体定义结构体方法。我们仔细看一下上面的area()函数定义。
首先是关键字func表示这是一个函数,第二个参数是结构体类型和实例变量,第三个是函数名称,第四个是函数返回值。这里我们可以看出area()函数和普通函数定义的区别就在于area()函数多了一个结构体类型限定。这样一来Go就知道了这是一个为结构体定义的方法。
这里需要注意一点就是定义在结构体上面的函数(function)一般叫做方法(method)。
结构体和指针
我们在指针一节讲到过,指针的主要作用就是在函数内部改变传递进来变量的值。对于上面的计算矩形面积的例子,我们可以修改一下代码如下:
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func (rect *Rect) area() float64 {
return rect.width * rect.length
}
func main() {
var rect = new(Rect)
rect.width = 100
rect.length = 200
fmt.Println("Width:", rect.width, "Length:", rect.length,
"Area:", rect.area())
}
上面的例子中,使用了new函数来创建一个结构体指针rect,也就是说rect的类型是*Rect,结构体遇到指针的时候,你不需要使用*去访问结构体的成员,直接使用.引用就可以了。所以上面的例子中我们直接使用rect.width=100 和rect.length=200来设置结构体成员值。因为这个时候rect是结构体指针,所以我们定义area()函数的时候结构体限定类型为*Rect。
其实在计算面积的这个例子中,我们不需要改变矩形的宽或者长度,所以定义area函数的时候结构体限定类型仍然为Rect也是可以的。如下:
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func (rect Rect) area() float64 {
return rect.width * rect.length
}
func main() {
var rect = new(Rect)
rect.width = 100
rect.length = 200
fmt.Println("Width:", rect.width, "Length:", rect.length,
"Area:", rect.area())
}
这里Go足够聪明,所以rect.area()也是可以的。
至于使不使用结构体指针和使不使用指针的出发点是一样的,那就是你是否试图在函数内部改变传递进来的参数的值。再举个例子如下:
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func (rect *Rect) double_area() float64 {
rect.width *= 2
rect.length *= 2
return rect.width * rect.length
}
func main() {
var rect = new(Rect)
rect.width = 100
rect.length = 200
fmt.Println(*rect)
fmt.Println("Double Width:", rect.width, "Double Length:", rect.length,
"Double Area:", rect.double_area())
fmt.Println(*rect)
}
这个例子的输出是:
{100 200}
Double Width: 200 Double Length: 400 Double Area: 80000
{200 400}
结构体内嵌类型
我们可以在一个结构体内部定义另外一个结构体类型的成员。例如iPhone也是Phone,我们看下例子:
package main
import (
"fmt"
)
type Phone struct {
price int
color string
}
type IPhone struct {
phone Phone
model string
}
func main() {
var p IPhone
p.phone.price = 5000
p.phone.color = "Black"
p.model = "iPhone 5"
fmt.Println("I have a iPhone:")
fmt.Println("Price:", p.phone.price)
fmt.Println("Color:", p.phone.color)
fmt.Println("Model:", p.model)
}
输出结果为
I have a iPhone:
Price: 5000
Color: Black
Model: iPhone 5
在上面的例子中,我们在结构体IPhone里面定义了一个Phone变量phone,然后我们可以像正常的访问结构体成员一样访问phone的成员数据。但是我们原来的意思是"iPhone也是(is-a)Phone",而这里的结构体IPhone里面定义了一个phone变量,给人的感觉就是"iPhone有一个(has-a)Phone",挺奇怪的。当然Go也知道这种方式很奇怪,所以支持如下做法:
package main
import (
"fmt"
)
type Phone struct {
price int
color string
}
type IPhone struct {
Phone
model string
}
func main() {
var p IPhone
p.price = 5000
p.color = "Black"
p.model = "iPhone 5"
fmt.Println("I have a iPhone:")
fmt.Println("Price:", p.price)
fmt.Println("Color:", p.color)
fmt.Println("Model:", p.model)
}
输出结果为
I have a iPhone:
Price: 5000
Color: Black
Model: iPhone 5
在这个例子中,我们定义IPhone结构体的时候,不再定义Phone变量,直接把结构体Phone类型定义在那里。然后IPhone就可以像访问直接定义在自己结构体里面的成员一样访问Phone的成员。
上面的例子中,我们演示了结构体的内嵌类型以及内嵌类型的成员访问,除此之外,假设结构体A内部定义了一个内嵌结构体B,那么A同时也可以调用所有定义在B上面的函数。
package main
import (
"fmt"
)
type Phone struct {
price int
color string
}
func (phone Phone) ringing() {
fmt.Println("Phone is ringing...")
}
type IPhone struct {
Phone
model string
}
func main() {
var p IPhone
p.price = 5000
p.color = "Black"
p.model = "iPhone 5"
fmt.Println("I have a iPhone:")
fmt.Println("Price:", p.price)
fmt.Println("Color:", p.color)
fmt.Println("Model:", p.model)
p.ringing()
}
输出结果为:
I have a iPhone:
Price: 5000
Color: Black
Model: iPhone 5
Phone is ringing...
接口
我们先看一个例子,关于Nokia手机和iPhone手机都能够打电话的例子。
package main
import (
"fmt"
)
type NokiaPhone struct {
}
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func main() {
var nokia NokiaPhone
nokia.call()
var iPhone IPhone
iPhone.call()
}
我们定义了NokiaPhone和IPhone,它们都有各自的方法call(),表示自己都能够打电话。但是我们想一想,是手机都应该能够打电话,所以这个不算是NokiaPhone或是IPhone的独特特点。否则iPhone不可能卖这么贵了。
再仔细看一下接口的定义,首先是关键字type,然后是接口名称,最后是关键字interface表示这个类型是接口类型。在接口类型里面,我们定义了一组方法。
Go语言提供了一种接口功能,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口,不一定非要显式地声明要去实现哪些接口啦。比如上面的手机的call()方法,就完全可以定义在接口Phone里面,而NokiaPhone和IPhone只要实现了这个接口就是一个Phone。
package main
import (
"fmt"
)
type Phone interface {
call()
}
type NokiaPhone struct {
}
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func main() {
var phone Phone
phone = new(NokiaPhone)
phone.call()
phone = new(IPhone)
phone.call()
}
在上面的例子中,我们定义了一个接口Phone,接口里面有一个方法call(),仅此而已。然后我们在main函数里面定义了一个Phone类型变量,并分别为之赋值为NokiaPhone和IPhone。然后调用call()方法,输出结果如下:
I am Nokia, I can call you!
I am iPhone, I can call you!
以前我们说过,Go语言式静态类型语言,变量的类型在运行过程中不能改变。但是在上面的例子中,phone变量好像先定义为Phone类型,然后是NokiaPhone类型,最后成为了IPhone类型,真的是这样吗?
原来,在Go语言里面,一个类型A只要实现了接口X所定义的全部方法,那么A类型的变量也是X类型的变量。在上面的例子中,NokiaPhone和IPhone都实现了Phone接口的call()方法,所以它们都是Phone,这样一来是不是感觉正常了一些。
我们为Phone添加一个方法sales(),再来熟悉一下接口用法。
package main
import (
"fmt"
)
type Phone interface {
call()
sales() int
}
type NokiaPhone struct {
price int
}
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
func (nokiaPhone NokiaPhone) sales() int {
return nokiaPhone.price
}
type IPhone struct {
price int
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func (iPhone IPhone) sales() int {
return iPhone.price
}
func main() {
var phones = [5]Phone{
NokiaPhone{price: 350},
IPhone{price: 5000},
IPhone{price: 3400},
NokiaPhone{price: 450},
IPhone{price: 5000},
}
var totalSales = 0
for _, phone := range phones {
totalSales += phone.sales()
}
fmt.Println(totalSales)
}
输出结果:
14200
上面的例子中,我们定义了一个手机数组,然后计算手机的总售价。可以看到,由于NokiaPhone和IPhone都实现了sales()方法,所以它们都是Phone类型,但是计算售价的时候,Go会知道调用哪个对象实现的方法。
接口类型还可以作为结构体的数据成员。
假设有个败家子,iPhone没有出的时候,买了好几款Nokia,iPhone出来后,又买了好多部iPhone,老爸要来看看这小子一共花了多少钱。
package main
import (
"fmt"
)
type Phone interface {
sales() int
}
type NokiaPhone struct {
price int
}
func (nokiaPhone NokiaPhone) sales() int {
return nokiaPhone.price
}
type IPhone struct {
price int
}
func (iPhone IPhone) sales() int {
return iPhone.price
}
type Person struct {
phones []Phone
name string
age int
}
func (person Person) total_cost() int {
var sum = 0
for _, phone := range person.phones {
sum += phone.sales()
}
return sum
}
func main() {
var bought_phones = [5]Phone{
NokiaPhone{price: 350},
IPhone{price: 5000},
IPhone{price: 3400},
NokiaPhone{price: 450},
IPhone{price: 5000},
}
var person = Person{name: "Jemy", age: 25, phones: bought_phones[:]}
fmt.Println(person.name)
fmt.Println(person.age)
fmt.Println(person.total_cost())
}
这个例子纯为演示接口作为结构体数据成员,如有雷同,纯属巧合。这里面我们定义了一个Person结构体,结构体内部定义了一个手机类型切片。另外我们定义了Person的total_cost()方法用来计算手机花费总额。输出结果如下:
Jemy
25
14200
小结
Go的结构体和接口的实现方法可谓删繁就简,去除了很多别的语言令人困惑的地方,而且学习难度也不大,很容易上手。不过由于思想比较独到,也有可能会有人觉得功能太简单而无用,这个就各有看法了,不过在逐渐的使用过程中,我们会慢慢领悟到这种设计所带来的好处,以及所避免的问题。
函数参数传递详解
参数传递是指在程序的传递过程中,实际参数就会将参数值传递给相应的形式参数,然后在函数中实现对数据处理和返回的过程。比较常见的参数传递有:值传递,按地址传递参数或者按数组传递参数。
1、常规传递
使用普通变量作为函数参数的时候,在传递参数时只是对变量值得拷贝,即将实参的值复制给变参,当函数对变参进行处理时,并不会影响原来实参的值。
例如:
package main
import (
"fmt"
)
func swap(a int, b int) {
var temp int
temp = a
a = b
b = temp
}
func main() {
x := 5
y := 10
swap(x, y)
fmt.Print(x, y)
}
输出结果:5 10
传递给swap的是x,y的值得拷贝,函数对拷贝的值做了交换,但却没有改变x,y的值。
2、指针传递
函数的变量不仅可以使用普通变量,还可以使用指针变量,使用指针变量作为函数的参数时,在进行参数传递时将是一个地址看呗,即将实参的内存地址复制给变参,这时对变参的修改也将会影响到实参的值。
我们还是用上面的的例子,稍作修改如下:
package main
import (
"fmt"
)
func swap(a *int, b *int) {
var temp int
temp = *a
*a = *b
*b = temp
}
func main() {
x := 5
y := 10
swap(&x, &y)
fmt.Print(x, y)
}
输出结果:10 5
3、数组元素作为函数参数
使用数组元素作为函数参数时,其使用方法和普通变量相同,即是一个"值拷贝"。
例:
package main
import (
"fmt"
)
func function(a int) {
a += 100
}
func main() {
var s = [5]int{1, 2, 3, 4, 5}
function(s[2])
fmt.Print(s[2])
}
输出结果:3
可以看到将数组元素s[2]的值作为函数的实参,不管对形参做什么操作,实参都没有改变。
4、数组名作为函数参数
和其他语言不同的是,go语言在将数组名作为函数参数的时候,参数传递即是对数组的复制。在形参中对数组元素的修改都不会影响到数组元素原来的值。这个和上面的类似,就不贴代码了,有兴趣的自行编写代码测试下吧。
5、slice作为函数参数
在使用slice作为函数参数时,进行参数传递将是一个地址拷贝,即将底层数组的内存地址复制给参数slice。这时,对slice元素的操作就是对底层数组元素的操作。例如:
package main
import (
"fmt"
)
func function(s1 []int) {
s1[0] += 100
}
func main() {
var a = [5]int{1, 2, 3, 4, 5}
var s []int = a[:]
function(s)
fmt.Println(s[0])
}
运行结果:101
6、函数作为参数
在go语言中,函数也作为一种数据类型,所以函数也可以作为函数的参数来使用。例如:
package main
import (
"fmt"
)
func function(a, b int, sum func(int, int) int) {
fmt.Println(sum(a, b))
}
func sum(a, b int) int {
return a + b
}
func main() {
var a, b int = 5, 6
f := sum
function(a, b, f)
}
运行结果:11
函数sum作为函数function的形参,而变量f是一个函数类型,作为function()调用时的实参。
golang 使用 iota
iota是golang语言的常量计数器,只能在常量的表达式中使用。
iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。
使用iota能简化定义,在定义枚举时很有用。
举例如下:
1、iota只能在常量的表达式中使用。
fmt.Println(iota)
编译错误: undefined: iota
2、每次 const 出现时,都会让 iota 初始化为0.
const a = iota // a=0
const (
b = iota //b=0
c //c=1
)
3、自定义类型
自增长常量经常包含一个自定义枚举类型,允许你依靠编译器完成自增设置。
type Stereotype int
const (
TypicalNoob Stereotype = iota // 0
TypicalHipster // 1
TypicalUnixWizard // 2
TypicalStartupFounder // 3
)
4、可跳过的值
设想你在处理消费者的音频输出。音频可能无论什么都没有任何输出,或者它可能是单声道,立体声,或是环绕立体声的。
这可能有些潜在的逻辑定义没有任何输出为 0,单声道为 1,立体声为 2,值是由通道的数量提供。
所以你给 Dolby 5.1 环绕立体声什么值。
一方面,它有6个通道输出,但是另一方面,仅仅 5 个通道是全带宽通道(因此 5.1 称号 - 其中 .1 表示的是低频效果通道)。
不管怎样,我们不想简单的增加到 3。
我们可以使用下划线跳过不想要的值。
type AudioOutput int
const (
OutMute AudioOutput = iota // 0
OutMono // 1
OutStereo // 2
_
_
OutSurround // 5
)
5、位掩码表达式
type Allergen int
const (
IgEggs Allergen = 1 << iota // 1 << 0 which is 00000001
IgChocolate // 1 << 1 which is 00000010
IgNuts // 1 << 2 which is 00000100
IgStrawberries // 1 << 3 which is 00001000
IgShellfish // 1 << 4 which is 00010000
)
这个工作是因为当你在一个 const 组中仅仅有一个标示符在一行的时候,它将使用增长的 iota 取得前面的表达式并且再运用它,。在 Go 语言的 spec 中, 这就是所谓的隐性重复最后一个非空的表达式列表。
如果你对鸡蛋,巧克力和海鲜过敏,把这些 bits 翻转到 "on" 的位置(从左到右映射 bits)。然后你将得到一个 bit 值 00010011,它对应十进制的 19。
fmt.Println(IgEggs | IgChocolate | IgShellfish)
// output:
// 19
6、定义数量级
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
7、定义在一行的情况
const (
Apple, Banana = iota + 1, iota + 2
Cherimoya, Durian
Elderberry, Fig
)
iota 在下一行增长,而不是立即取得它的引用。
// Apple: 1
// Banana: 2
// Cherimoya: 2
// Durian: 3
// Elderberry: 3
// Fig: 4
8、中间插队
const (
i = iota
j = 3.14
k = iota
l
)
那么打印出来的结果是 i=0,j=3.14,k=2,l=3
Go语言语法说明的更多相关文章
- Go语言语法汇总(转)
Go语言语法汇总 分类: 技术2013-09-16 14:21 3007人阅读 评论(0) 收藏 举报 go语言golang并发语法 目录(?)[+] 最近看了看GoLang,把Go语言的语法 ...
- C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | IT宅.com
原文:C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | IT宅.com C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | I ...
- R语言语法基础二
R语言语法基础二 重塑数据 增加行和列 # 创建向量 city = c("Tampa","Seattle","Hartford"," ...
- R语言语法基础一
R语言语法基础一 Hello world #这里是注释 myString = "hello world" print(myString) [1] "hello world ...
- L脚本语言语法手冊 0.10版
L脚本语言语法手冊 0.10版 简 介 L脚本语言是一个轻量级的,旨在接近自然语言的编程语言,眼下支持在中文.英文基础上的编程.并可扩展为随意语种.L脚本语言的语法结构简单.程序结构相对 ...
- 嵌入式C语言自我修养 01:Linux 内核中的GNU C语言语法扩展
1.1 Linux 内核驱动中的奇怪语法 大家在看一些 GNU 开源软件,或者阅读 Linux 内核.驱动源码时会发现,在 Linux 内核源码中,有大量的 C 程序看起来“怪怪的”.说它是C语言吧, ...
- PL真有意思(二):程序设计语言语法
前言 虽然标题是程序语言的语法,但是讲的是对词法和语法的解析,其实关于这个前面那个写编译器系列的描述会更清楚,有关语言语法的部分应该是穿插在整个设计当中的,也看语言设计者的心情了 和英语汉语这些自然语 ...
- Neo4j-Cypher语言语法
Neo4j-Cypher语言语法 梦飞扬 2018-03-15 264 阅读 Neo4j 本文是记录Neo4j图数据库中实用的Cypher语言语法. Cypher是什么 "Cypher&qu ...
- XPAND模板语言语法1.0
XPAND模板语言语法1.0 Xpand模板语言一般写在以.xpt为结尾的文本文件中 ,以"« »" 作为开头和结尾 .Xpand语言主要包括以下几个标签: «IMPORT», ...
随机推荐
- JAVA接口和抽象类的特点
接口的特点: 1:接口不可实例化,可结合多态进行使用(接口 对象=new 对象()) 2:接口里的成员属性全部是以 public(公开).static(静态).final(最终) 修饰符修饰 3:接口 ...
- 选择语言之switch case
程序语言-选择语言之switch case 多选一,类似if else if else if else 模版: Switch(选择条件) { Case(条件一)//相当于if Conso ...
- Appium环境部署
Appium 是一个开源.跨平台的自动化测试工具,用于测试原生和轻量移动应用,支持 iOS, Android平台. 需要部署的软件:python环境.nodejs..net framework4.5. ...
- text-shadow的用法详解
1.兼容性:text-shadow 和 box-shadow 这两个属性在主流现代浏览器上得到了很好的支持( > Chrome 4.0, > Firefox 3.5, > Safar ...
- js获取地址栏参数2种最简单方法
NO1:(本人最喜欢) //普通参数 function GetQueryString(name) { var reg = new RegExp("(^|&)"+ name ...
- 北大ACM(POJ1020-Anniversary Cake)
Question:http://poj.org/problem?id=1020 问题点:DFS. Memory: 260K Time: 47MS Language: C++ Result: Accep ...
- 在自学css开始就遇到问题,“链入外部样式表”在多浏览器显示问题
在自学css开始就遇到问题,“链入外部样式表”的习题,代码如下:A.被链入的CSS文件代码.css<style type="text/css"><!--h1{b ...
- 没搞错吧,我只是个web前端工程师,不是manager,也不是leader...
那个时候,我只想好好的学习web前端技术,恨不得把有限的时间和精力都放在提升技术上. 然而,让自己在坑里茁壮成长,要先适应坑内的环境. 首当其冲我们要弄明白的事情有: 团队成员的技术能力和状态 Lea ...
- c3p0参数详解
<!--当连接池中的连接耗尽的时候c3p0一次同时获取的连接数.Default: 3 --> <property name="acquireIncrement"& ...
- node遍历给定目录下特定文件,内容合并到一个文件
遍历目录用了fs.readdir这个异步方法,得到当前目录下所有的文件和目录的一个数组.然后判断: if文件,并且后缀符合设定的规则(本文例子是符合后缀ts,js)直接用同步方法写入, if目录,继续 ...