一条update语句优化小记

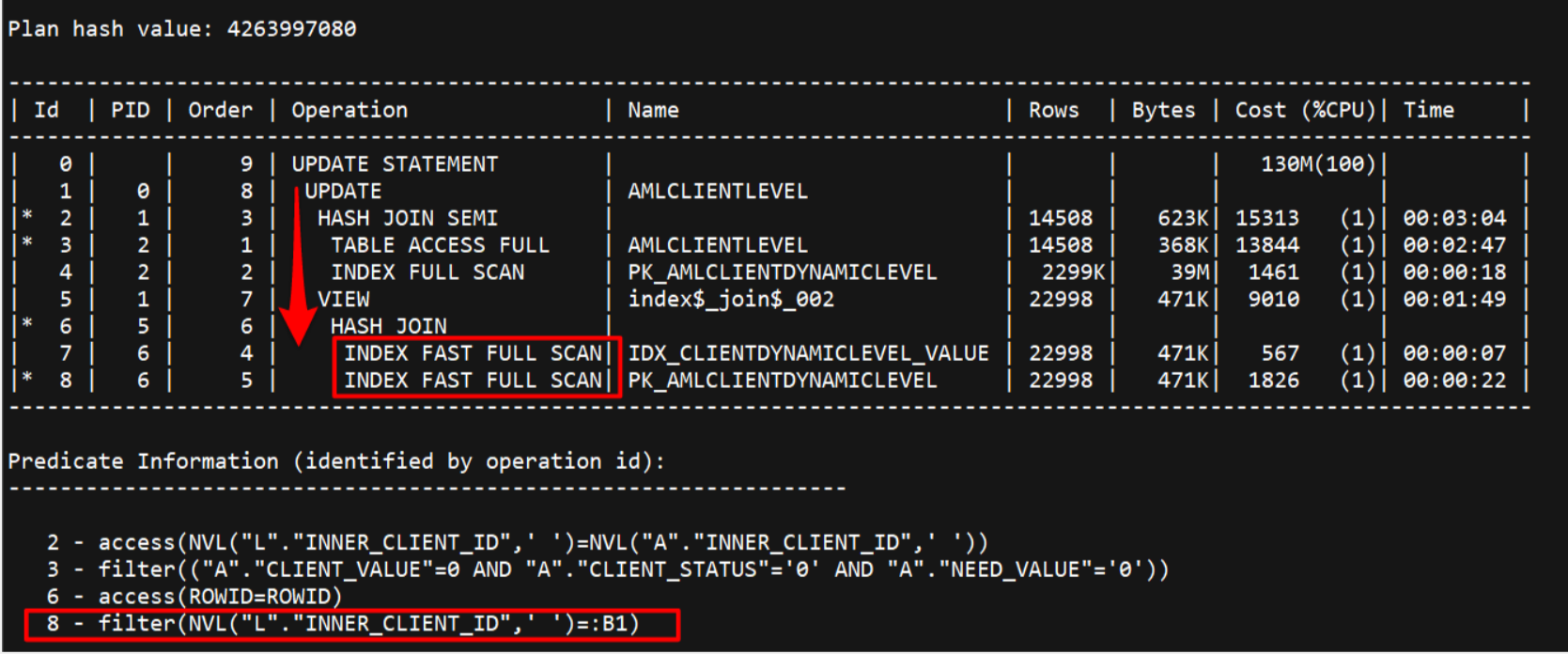




.png)
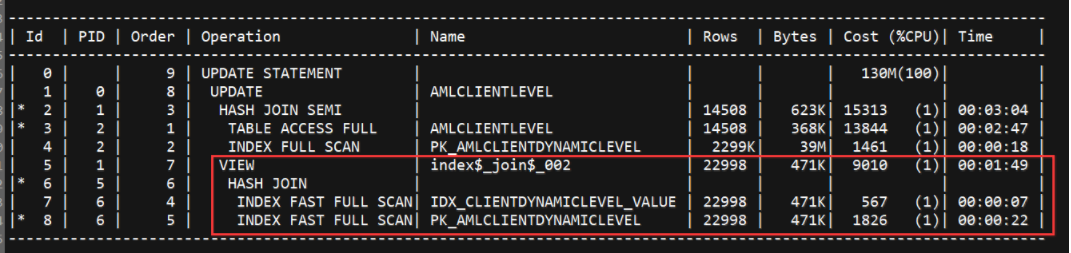
.png)
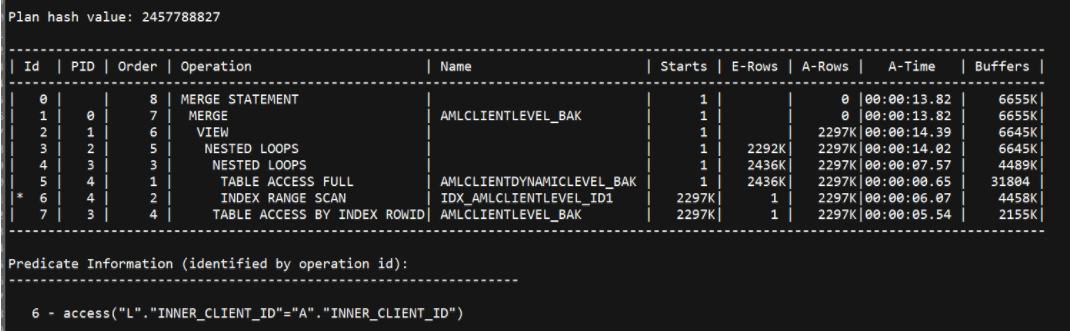
.png)
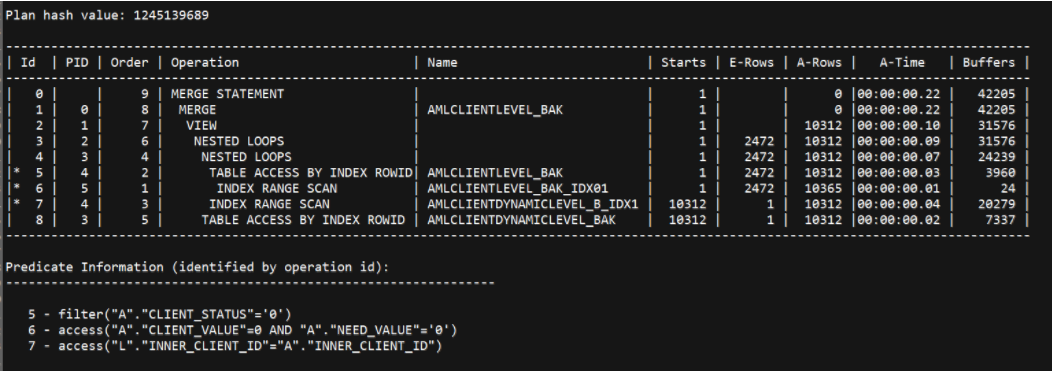
.png)
一条update语句优化小记的更多相关文章
- sql执行万条update语句优化
几个月没有更新笔记了,最近遇到一个坑爹的问题,顺道记录一下.. 需求是这样的:一次性修改上万条数据库. 项目是用MVC+linq的. 本来想着用 直接where() 1 var latentCusto ...
- 完蛋,公司被一条 update 语句干趴了!
大家好,我是小林. 昨晚在群划水的时候,看到有位读者说了这么一件事. 在这里插入图片描述 大概就是,在线上执行一条 update 语句修改数据库数据的时候,where 条件没有带上索引,导致业务直接崩 ...
- 如何将多条update语句合并为一条
需求: 如何将多条update语句合并为一条update语句:如,update table1 set col='2012' where id='2014001' update table1 ...
- 一条update语句到底加了多少锁?带你深入理解底层原理
迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子. 手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:"我爱加班". 面试开始,直 ...
- Oracle的update语句优化研究
最近研究sql优化,以下文章转自互联网: 1. 语法 单表:UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值 如:update t_join_situation s ...
- MySQL45讲:一条update语句是怎样执行的
首先创建一张表: create table T(ID int primary key,c int); 如果要更新ID=2这行+1:应该这样写 update T set c=c+1 where ID=2 ...
- [转]Oracle的update语句优化研究
原文地址:http://blog.csdn.net/u011721927/article/details/39228001 一. update语句的语法与原理 1. 语法 单表 ...
- Sql Server执行一条Update语句很慢,插入数据失败
今天同事要我修改服务器数据库里面的2条数据,查看服务器上的SQL Server数据库的时候,发现这几天数据没有添加成功,然后发现磁盘很快就满了,执行Update语句时,执行半天都提示还在执行,查询语句 ...
- 用一条UPDATE语句交换两列的值
在SQL UPDATE语句中,"="右侧的值在整个UPDATE语句中都是一致的,所有更新同时发生!因此以下语句将在没有临时变量的情况下交换两列的值: UPDATE table SE ...
随机推荐
- linux中用无名管道进行文件的读写
1管道是什么: 水管子大家知道,有两端,在此一端用来读一端用来写,其中一端的输出作为另外一端的输入. 2 函数原型 int pipe(int pipefd[2]);//参数中分别代表的两端 3 例子: ...
- 在Emacs下用C/C++编程(转载)
转自:http://www.caole.net/diary/emacs_write_cpp.html Table of Contents 版权说明和参考文献 参考文献: 版权说明: 序 基本流程 基本 ...
- Codeforces - 814B - An express train to reveries - 构造
http://codeforces.com/problemset/problem/814/B 构造题烦死人,一开始我还记录一大堆信息来构造p数列,其实因为s数列只有两项相等,也正好缺了一项,那就把两种 ...
- HDOJ3231醉
反正一开始就是瞎几把看题,然后题意理解了,什么飞机?只能去看题解了. 呵呵,可惜,题解看了三个小时,还是一知半解,先写了. - -菜鸡超级详细题解,强行掰弯一波,等下再问问别人吧. OK,OK开始!! ...
- 【POJ - 2376】Cleaning Shifts(贪心)
Cleaning Shifts Descriptions: 原文是English,我这就直接上Chinese了,想看原文的点一下链接哦 大表哥分配 N (1 <= N <= 25,000) ...
- Vue 基础指令学习
学习Vue的一些总结,第一次写博客,文笔实在是很差 不过我会不断写的. <template> <!--只能有一个根节点 --> <div> <pre> ...
- SpringAOP和Spring事物管理
Spring AOP : Pointcut表达式: designators-指示器 wildcards-通配符 operators-操作符 wildcards: * -- 匹配任意数量的字符 + -- ...
- 51Nod 1174 区间中最大的数(RMQ)
#include <iostream> #include <algorithm> #include <cstring> using namespace std; + ...
- 用sublime text3 直接编译C/C++,java
首先你得下载好 这是我之前安装codeblocks时留下的里面有cpp,c++,gcc,g++. 第二步就是建立环境变量 这三个配置完成就ok 了 然后进入sublime text 3中,找到工具(t ...
- css width
转载:http://blog.csdn.net/dddddz/article/details/8631655