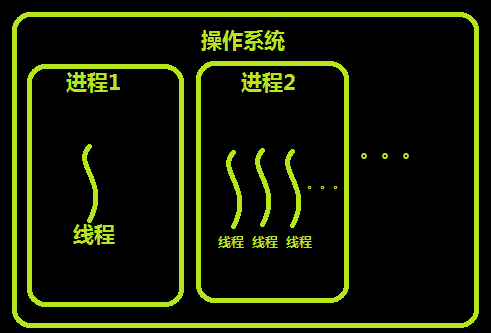
python--(十步代码学会线程)
python--(十步代码学会线程)
一.线程的创建
Thread实例对象的方法
# isAlive(): 返回线程是否活动的.
# getname(): 返回线程名.
# setName(): 设置线程名. threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果
from threading import Thread
from multiprocessing import Process #第一种方法
def func(n):
print(n)
if __name__ == '__main__': t = Thread(target=func, args=("我是线程",))
t.start()
# p = Process(target=func, args=("我是进程",))
# p.start()
print("主进程结束.") #第二种方法
class MyThread(Thread):
def run(self):
print("辉哥牛逼")
if __name__ == "__main__":
t = MyThread()
t.start()
print("主线程结束")
线程的两种创建方式
import time
from threading import Thread
from multiprocessing import Process
def func(n):
num = 0
for n1 in range(n):
num += n1
print("num",num)
if __name__ == '__main__':
t_s_t = time.time()
t_list = []
for i in range(10):
t = Thread(target=func, args=(10,))
t.start() #速度特别快
t_list.append(t)
[tt.join() for tt in t_list]
t_e_t = time.time()
t_dif_t = t_s_t - t_e_t #获取了线程的执行时间 p_s_t = time.time()
p_list = []
for ii in range(10):
p = Process(target=func, args=(10,))
p.start() #速度非常快
p_list.append(p)
[pp.join() for pp in p_list]
p_e_t = time.time() #结束时间
p_dif_t = p_e_t - p_s_t #获取进程执行时间 print('线程>>>>', t_dif_t)
print('进程....', p_dif_t)
print('主线程结束')
线程和进程的效率对比
线程的其他方法
# 线程的一些其他方法
# from threading import Thread
# import threading
# import time
# from multiprocessing import Process
# import os
#
# def work():
# import time
# time.sleep(1)
# print(threading.current_thread().getName()) #Thread-1
# print(threading.current_thread()) #Thtrad-1
#
# if __name__ == '__main__':
# #在主进程下开启线程
# t = Thread(target=work)
# t.start()
#
# # print(threading.current_thread()) #主线程对象
# # print(threading.current_thread().getName()) #主线程名称
# # print(threading.current_thread().ident) #主线程ID
# # print(threading.get_ident()) #主线程ID
#
# time.sleep(3)
# print(threading.enumerate()) #连同主线程在内有两个运行的线程
# print(threading.active_count()) #进程数
# print("主线程/主进程")
二.数据共享
from threading import Thread
from multiprocessing import Process num = 100
def func():
global num
num = 0
if __name__ == '__main__':
t = Thread(target=func,)
t.start()
t.join()
print(num) # p = Process(target=func,)
# p.start()
# p.join()
# print(num)
线程的数据是共享的
mport time
from threading import Thread,Lock #演示共享资源的时候,数据不安全的问题
# num = 100
# def func():
# global num
# num -= 1
# mid = num
# mid = mid - 1
# time.sleep(0.00001)
# num = mid
# if __name__ == '__main__':
# t_list = []
# for i in range(10):
# t = Thread(target=func,)
# t.start()
# t_list.append(t)
# [tt.join() for tt in t_list]
# print("主进程>>>>", num) #通过锁来解决数据不安全的问题,线程模块里面引入的锁
num = 100
def func(t_lock):
global num
t_lock.acquire()
mid = num
mid = mid - 1
time.sleep(0.0001)
num = mid
t_lock.release()
if __name__ == '__main__':
t_lock = Lock() #锁对象(同步锁,互斥锁)
t_list = []
for i in range(10):
t = Thread(target=func,args=(t_lock,))
t.start()
t_list.append(t)
[tt.join() for tt in t_list]
print("主进程>>>>",num)
线程共享资源不安全,加锁解决
三.守护进程
守护进程 :
主进程代码结束程序并没有结束,并且主进程还存在,进程等待其他的子进程执行结束以后,为子进程收尸,注意一个问题:主进程的代码运行结束守护进程跟着结束,
守护线程:
主线程等待所有非守护线程的结束才结束,主线程的代码运行结束,还要等待非守护线程的执行完毕.这个过程中守护线程还存在
import time
from threading import Thread
from multiprocessing import Process
def func1(n):
time.sleep(5)
print(n)
def func2(n):
time.sleep(3)
print(n)
if __name__ == '__main__':
# p1 = Process(target=func1,args=("我是子进程1号",))
# #设置守护进程,在start之前加
# p1.start()
# p2 = Process(target=func2,args=("我是子进程2号",))
# p2.daemon = True
# p2.start()
# print("子进程结束")
线程与进程守护进程对比
四.死锁现象
锁(同步锁\互斥锁): 保证数据安全,但是牺牲了效率,同步执行锁内的代码
死锁现象 : 互相抢到了对方的需要的锁,导致双方相互等待,程序没法进行
解决死锁: 递归锁,RLock #可以多次acquire,通过一个计数器来记录被锁了多少次,只有计数器为0的时候,大 家才能继续抢锁
import time
from threading import Thread,Lock class MyThread(Thread): def __init__(self,lockA,lockB):
super().__init__()
self.lockA = lockA
self.lockB = lockB def run(self):
self.f1()
self.f2()
def f1(self): self.lockA.acquire()
print('我拿了A锁') self.lockB.acquire()
print('我是一个很好的客户!')
self.lockB.release() self.lockA.release() def f2(self):
self.lockB.acquire()
time.sleep(0.1)
print('我拿到了B锁')
self.lockA.acquire()
print('我是一名合格的技师')
self.lockA.release() self.lockB.release() if __name__ == '__main__':
lockA = Lock()
lockB = Lock() t1 = MyThread(lockA,lockB)
t1.start() t2 = MyThread(lockA,lockB)
t2.start() print('我是经理')
死锁现象
import time
from threading import Thread,Lock,RLock #递归锁 class MyThread(Thread): def __init__(self,lockA,lockB):
super().__init__()
self.lockA = lockA
self.lockB = lockB def run(self):
self.f1()
self.f2()
def f1(self): self.lockA.acquire()
print('我拿了A锁') self.lockB.acquire()
print('我是一个很好的客户!')
self.lockB.release() self.lockA.release() def f2(self):
self.lockB.acquire()
time.sleep(0.1)
print('我拿到了B锁')
self.lockA.acquire()
print('我是一名合格的技师')
self.lockA.release() self.lockB.release() if __name__ == '__main__':
# lockA = Lock()
# lockB = Lock()
# lockA = lockB = Lock() #不要这么写,别自己玩自己,锁自己
lockA = lockB = RLock() t1 = MyThread(lockA,lockB)
t1.start() t2 = MyThread(lockA,lockB)
t2.start() print('我是经理')
解决死锁线程方法
五.信号量
信号量: 控制同时能够进入锁内去执行代码的线程数量(进程数量),维护了一个计数器,刚开始创建信号量的时候假如设置的是4个房间,进入一次acquire就减1 ,出来一个就+1,如果计数器为0,那么其他的任务等待,这样其他的任务和正在执行的任务是一个同步的状态,而进入acquire里面去执行的那4个任务是异步执行的.
import time
from threading import Thread, Semaphore def func1(s):
s.acquire()
time.sleep(1)
print('大宝剑!!!')
s.release() if __name__ == '__main__':
s = Semaphore(4)
for i in range(10):
t = Thread(target=func1,args=(s,))
t.start()
信号量
六.事件
# # 事件
# from threading import Thread,Event
# e = Event() #e的状态有两种,False Ture,当事件对象的状态为False的时候,wait的位置会阻塞
#
# e.set() #将事件对象的状态改为Ture
# e.clear() #将事件对象的状态改为False
# print("在这里等待")
# e.wait() #阻塞
# print("还没好")
七.队列
mport queue #先进先出 FIFO
# q=queue.Queue()
# q.put('first')
# q.put('second')
# q.put('third')
# # q.put_nowait() #没有数据就报错,可以通过try来搞
# print(q.get())
# print(q.get())
# print(q.get())
# # q.get_nowait() #没有数据就报错,可以通过try来搞 # '''
# first
# second
# third
# ''' # 先进后出
# import queue # q = queue.LifoQueue() #队列类似于栈,先进后出的顺序
# q.put('first')
# q.put('second')
# q.put('third')
# q.put_nowait() # print(q.get())
# print(q.get())
# print(q.get())
# # q.get_nowait() #没有数据就报错 # '''
# third
# second
# first
# ''' # # 优先级队列
# import queue
# q = queue.PriorityQueue()
# #put进入一个元祖,元祖的第一个元素是优先级(通常是数字,也可以是非数字之间的比较,数字越小优先级越高
# q.put((-10,"a"))
# q.put((-5,"a")) #负数也可以
#
# # q.put((20,'b')) #如果第一个参数数字的优先级一样,那么按照后面的字符串acsii来排序
# # q.put((20,'c'))
#
# # q.put((20,{'a':11})) #TypeError: unorderable types: dict() < dict() 不能是字典
# # q.put((20,('w',1))) #优先级相同的两个数据,他们后面的值必须是相同的数据类型才能比较,可以是元祖,也是通过元素的ascii码顺序来排序
#
# print(q.get())
# print(q.get())
# """结果:数字越小优先级越高,优先级高的优先出队"""
八.线程池
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class. #2 基本方法
#submit(fn, *args, **kwargs)
异步提交任务 #map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作 #shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前 #result(timeout=None)
取得结果 #add_done_callback(fn)
回调函数
# 线程池
# import time
# from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
# #ProcessPoolExecutor 进程池
# from threading import current_thread
#
# def func(n):
# time.sleep(1)
# # print(n,current_thread().ident)
# return n**2
# if __name__ == '__main__':
# t_p = ThreadPoolExecutor(max_workers = 4)
# map_res = t_p.map(func,range(10)) #异步执行的,map自带join功能
# print(map_res)
# print([i for i in map_res])
线程池的一些其他方法
# 线程池的一些其他方法
# import time
# from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
# from threading import current_thread
# def func(n):
# time.sleep(1)
# #print(n,current_thread().ident)
# return n**2
# def func2(n):
# print(n)
# if __name__ == '__main__':
# t_p = ThreadPoolExecutor(max_workers=4)
# t_p_list = []
# for i in range(10):
# res_obj = t_p.submit(func, i) #异步提交了这10个任务
# # res_obj.result() #他和get一样
# t_p_list.append(res_obj)
# t_p.shutdown() #close + join 等待全部完成之后关闭子线程,防止后面数据进入
# # print('t_res_list',t_p_list)
# for e_res in t_p_list:
# print(e_res.result())
九.回调函数
rom concurrent.futures import ThreadPoolExecutor
from threading import current_thread def func(n):
time.sleep(1)
print(n**2)
# print(n,current_thread().getName())
# return n**2
def func2(n):
# print("current_thread>>>>",current_thread().getName())
print(n.result()) #result() 相当于 get()
if __name__ == '__main__':
t_p = ThreadPoolExecutor(max_workers=1)
for i in range(3):
t_p.submit(func, i).add_done_callback(func2) print('主进程结束')
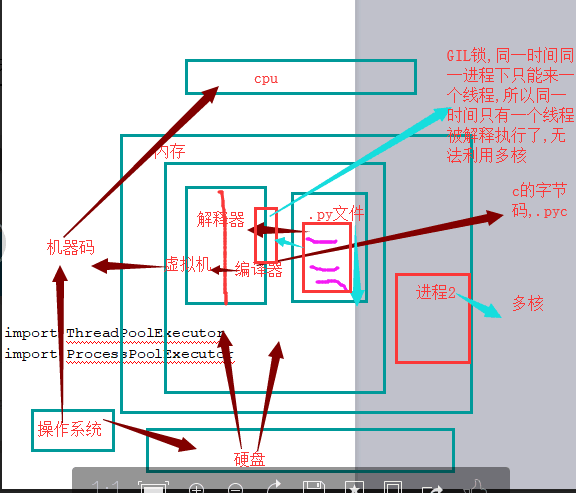
十.GIL锁
#保证数据安全,锁的是整个线程,每次只能有一个线程使用cpu,是CPython解释器的特性
python--(十步代码学会线程)的更多相关文章
- python--(十五步代码学会进程)
python--(十五步代码学会进程) 一.进程的创建 import time import os #os.getpid() 获取自己进程的id号 #os.getppid() 获取自己进程的父进程id ...
- python 装饰器 第十步:装饰器来装饰器一个类
第十步:装饰器来装饰一个类 def kuozhan(cls): print(cls) #声明一个类并且返回 def newHuman(): # 扩展类的功能1 cls.cloth = '漂亮的小裙子' ...
- 使用Python一步一步地来进行数据分析总结
原文链接:Step by step approach to perform data analysis using Python译文链接:使用Python一步一步地来进行数据分析--By Michae ...
- Android NDK开发之从环境搭建到Demo级十步流
写在正文之前: 几个月没有更新博客,感觉有点生疏了,所以说不能断,一断人就懒. 其实这几个月也并不是什么事也没有做,俺可是时刻想着今年的任务呢,10本书,30篇博文...,这几个月间断性的也是在学习中 ...
- Android系统--输入系统(十四)Dispatcher线程情景分析_dispatch前处理
Android系统--输入系统(十四)Dispatcher线程情景分析_dispatch前处理 1. 回顾 我们知道Android输入系统是Reader线程通过驱动程序得到上报的输入事件,还要经过处理 ...
- (转)SQLServer_十步优化SQL Server中的数据访问五
第九步:合理组织数据库文件组和文件 创建SQL Server数据库时,数据库服务器会自动在文件系统上创建一系列的文件,之后创建的每一个数据库对象实际上都是存储在这些文件中的.SQL Server有下面 ...
- python 常忘代码查询 和autohotkey补括号脚本和一些笔记和面试常见问题
笔试一些注意点: --,23点43 今天做的京东笔试题目: 编程题目一定要先写变量取None的情况.今天就是因为没有写这个边界条件所以程序一直不对.以后要注意!!!!!!!!!!!!!!!!!!!!! ...
- 一步一步创建JAVA线程
(一)创建线程 要想明白线程机制,我们先从一些基本内容的概念下手. 线程和进程是两个完全不同的概念,进程是运行在自己的地址空间内的自包容的程序,而线程是在进程中的一个单一的顺序控制流,因此,单个进程可 ...
- 【python】-- GIL锁、线程锁(互斥锁)、递归锁(RLock)
GIL锁 计算机有4核,代表着同一时间,可以干4个任务.如果单核cpu的话,我启动10个线程,我看上去也是并发的,因为是执行了上下文的切换,让看上去是并发的.但是单核永远肯定时串行的,它肯定是串行的, ...
随机推荐
- jsp 中声明方法的使用
1.在"<%!"和"%>"之间声明方法,该方法在整个JSP页面有效.可是该方法内定义的变量仅仅在该方法内有效. 这些方法将在Java程序片中被调用, ...
- jQuery--编辑表格
表格操作是我们常常遇到的,还记得刚開始学习牛腩新闻公布系统时.跟着视频进行表格的一些基本操作.而对它的原理与概念全然不懂,不过跟着老师的操作而进行操作. 通过这次学习,对表格的操作有了进一步的了解与掌 ...
- Codesys——TON和TOF的使用方法
1. 引言 介绍延迟导通.延迟关闭函数的使用方法. 2. 函数描述 TON: 当IN为FALSE时,输出Q为FALSE: 当IN为由FALSE变为TRUE时,延迟导通过程中Q为FALSE,当时间到Q变 ...
- bzoj3545
线段树合并+离线+启发式合并 半年前这道题t成狗... 离线的做法比较好想,按照边的权值排序,询问的权值排序,然后枚举询问不断加边,加到上限后查找第k大值,这里平衡树,权值线段树都可以实现. 那么我们 ...
- MySQL 1071错误解决办法
今天在使用mysql时,又遇到了如博文标题所示的问题,以前针对该问题未进行记录,今天特意进行说明存档. 该问题是由键值字段长度过长导致.mysql支持数据库表单一键值的最大长度不能超过 ...
- Flink之Window Operation
目录 Configuring Time Characteristics Process Functions Window Operators Applying Functions on Windows ...
- css - 所有的a标签设置为新窗口打开
前言 由于工作的需要,需要把某个页面下的所有a标签都设置为新开新窗口,即:<a href="XXX">增加target:<a href="XXX&quo ...
- skiing 暴力搜索 + 动态规划
我的代码上去就是 直接纯粹的 暴力 . 居然没有超时 200ms 可能数据比较小 一会在优化 #include<stdio.h> #include<string.h ...
- 331 Verify Preorder Serialization of a Binary Tree 验证二叉树的前序序列化
序列化二叉树的一种方法是使用前序遍历.当我们遇到一个非空节点时,我们可以记录这个节点的值.如果它是一个空节点,我们可以使用一个标记值,例如 #. _9_ / \ 3 2 ...
- javascript:void(0);什么意思
js里面void是一个操作符,该操作符计算表达式的值,但是不返回任何内容. <a href="javascript:void(0);"> 这里用到void(0)表示取消 ...