扩增子分析解读2提取barcode 质控及样品拆分 切除扩增引物
# 进入工作目录
cd example_PE250
# 提取barcode
extract_barcodes.py -f temp/PE250_join/fastqjoin.join.fastq \
-m mappingfile.txt \
-o temp/PE250_barcode \
-c barcode_paired_stitched --bc1_len 0 --bc2_len 6 -a --rev_comp_bc2
barcodes.fastq # 切下来的barcode,用于后续拆分样品barcodes_not_oriented.fastq # 方向不确定序列的barcode。连引物都不匹配,质量太差,建议不再使用reads1_not_oriented.fastq # 方向不确定序列的序列,可能barcode切错方向。连引物都不匹配,质量太差,不建议使用reads2_not_oriented.fastq # 空文件reads.fastq # 序列文件,与barcode对应,用于下游分析
# 质控及样品拆分
split_libraries_fastq.py -i temp/PE250_barcode/reads.fastq \
-b temp/PE250_barcode/barcodes.fastq \
-m mappingfile.txt \
-o temp/PE250_split/ \
-q 20 --max_bad_run_length 3 --min_per_read_length_fraction 0.75 --max_barcode_errors 0 --barcode_type 6
histograms.txt # 所有序列长度分布数据,可知长度范围308-488,峰值为408seqs.fna # 质控并拆分后的数据,序列按样品编号为SampleID_0/1/2/3split_library_log.txt # 日志文件,有基本统计信息和每个样品的数据量;查看可知每个样品最大数据量为110454,最小值为10189
# 下载,请尽量检查主页下载最新版源码
wget https://pypi.python.org/packages/16/e3/06b45eea35359833e7c6fac824b604f1551c2fc7ba0f2bd318d8dd883eb9/cutadapt-1.14.tar.gz
# 解压
tar xvzf cutadapt-1.14.tar.gz
# 进入程序目录
cd cutadapt-1.14/
# 安装在当前用户目录,不需管理员权限
python setup.py install --user
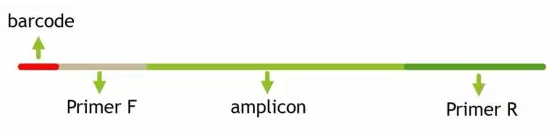
cutadapt -g AACMGGATTAGATACCCKG -a GGAAGGTGGGGATGACGT -e 0.15 -m 300 --discard-untrimmed temp/PE250_split/seqs.fna -o temp/PE250_P5.fa
This is cutadapt 1.14 with Python 3.6.1
Command line parameters: -g AACMGGATTAGATACCCKG -a GGAAGGTGGGGATGACGT -e 0.15 -m 300 --discard-untrimmed temp/PE250_split/seqs.fna -o temp/PE250_P5.fa
Trimming 2 adapters with at most 15.0% errors in single-end mode ...
Finished in 73.83 s (58 us/read; 1.04 M reads/minute).=== Summary ===
Total reads processed: 1,277,436
Reads with adapters: 1,277,194 (100.0%)
Reads that were too short: 8,849 (0.7%)
Reads written (passing filters): 1,268,345 (99.3%)Total basepairs processed: 522,379,897 bp
Total written (filtered): 495,607,409 bp (94.9%)=== Adapter 1 ===
Sequence: GGAAGGTGGGGATGACGT; Type: regular 3'; Length: 18; Trimmed: 202757 times.
No. of allowed errors:
0-5 bp: 0; 6-12 bp: 1; 13-18 bp: 2Bases preceding removed adapters:
A: 96.3%
C: 1.5%
G: 0.8%
T: 1.3%
none/other: 0.0%
WARNING:
The adapter is preceded by "A" extremely often.
The provided adapter sequence may be incomplete.
To fix the problem, add "A" to the beginning of the adapter sequence.Overview of removed sequences
length count expect max.err error counts
3 3 19959.9 0 3
4 4 4990.0 0 4
6 2 311.9 0 2
8 1 19.5 1 1
11 1 0.3 1 1
13 1 0.0 1 1
15 9 0.0 2 9
17 42 0.0 2 42
18 202626 0.0 2 202626
19 56 0.0 2 56
20 1 0.0 2 1
21 1 0.0 2 1
32 1 0.0 2 1
38 1 0.0 2 1
39 1 0.0 2 1
41 1 0.0 2 1
309 2 0.0 2 2
310 1 0.0 2 1
311 3 0.0 2 3=== Adapter 2 ===
Sequence: AACMGGATTAGATACCCKG; Type: regular 5'; Length: 19; Trimmed: 1074437 times.
No. of allowed errors:
0-5 bp: 0; 6-12 bp: 1; 13-19 bp: 2Overview of removed sequences
length count expect max.err error counts
3 2 19959.9 0 2
7 1 78.0 1 0 1
8 2 19.5 1 1 1
10 6 1.2 1 4 2
11 1 0.3 1 1
12 3 0.1 1 2 1
13 5 0.0 1 3 2
14 24 0.0 2 17 7
15 51 0.0 2 32 14 5
16 71 0.0 2 56 12 3
17 134 0.0 2 92 30 12
18 327 0.0 2 189 117 21
19 1059175 0.0 2 1056863 2069 243
20 13846 0.0 2 1817 10955 1074
21 744 0.0 2 5 10 729
22 1 0.0 2 1
23 2 0.0 2 2
24 1 0.0 2 1
25 2 0.0 2 2
27 5 0.0 2 5
28 2 0.0 2 2
29 2 0.0 2 2
30 1 0.0 2 1
31 2 0.0 2 2
32 10 0.0 2 10
49 1 0.0 2 1
51 1 0.0 2 1
166 1 0.0 2 1
291 6 0.0 2 6
401 2 0.0 2 2
409 1 0.0 2 1
443 1 0.0 2 1
460 2 0.0 2 2
465 2 0.0 2 2WARNING:
One or more of your adapter sequences may be incomplete.
Please see the detailed output above.
扩增子分析解读2提取barcode 质控及样品拆分 切除扩增引物的更多相关文章
- 扩增子分析解读5物种注释 OTU表操作
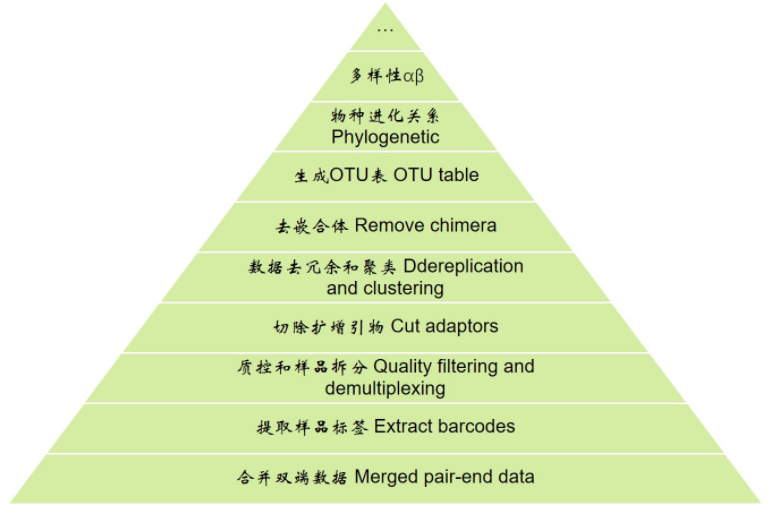
本节课程,需要先完成<扩增子分析解读>系列之前的操作 1质控 实验设计 双端序列合并 2提取barcode 质控及样品拆分 切除扩增引物 3格式转换 去冗余 聚类 4去嵌合体 非细菌序列 ...
- 扩增子分析解读4去嵌合体 非细菌序列 生成代表性序列和OTU表
本节课程,需要先完成 扩增子分析解读1质控 实验设计 双端序列合并 2提取barcode 质控及样品拆分 切除扩增引物 3格式转换 去冗余 聚类 先看一下扩增子分析的整体流程,从下向上逐层分析 分 ...
- 扩增子分析解读6进化树 Alpha Beta多样性
分析前准备 # 进入工作目录 cd example_PE250 上一节回顾:我们的OTU获得了物种注释,并学习OTU表的各种操作————添加信息,格式转换,筛选信息. 接下来我们学习对OTU序列的 ...
- 扩增子分析QIIME2. 1简介和安装
原网站:https://blog.csdn.net/woodcorpse/article/details/75103929 声明:本文为QIIME2官方帮助文档的中文版,由中科院遗传发育所刘永鑫博士翻 ...
- 扩增子图表解读1箱线图:Alpha多样性
箱线图 箱形图(Box-plot)又称为盒须图.盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图.因形状如箱子而得名.在宏基因组领域,常用于展示样品组中各样品Alpha多样性的分布 第一种情 ...
- 扩增子图表解读3热图:差异菌、OTU及功能
热图是使用颜色来展示数值矩阵的图形.通常还会结合行.列的聚类分析,以表达实验数据多方面的结果. 热图在生物学领域应用广泛,尤其在高通量测序的结果展示中很流行,如样品-基因表达,样品-OTU相对丰度矩 ...
- 如何分析解读systemstat dump产生的trc文件
ORACLE数据库的systemstat dump生成trace文件虽然比较简单,但是怎么从trace文件中浩如烟海的信息中提炼有用信息,并作出分析诊断是一件技术活,下面收集.整理如何分析解读syst ...
- LIRe 源代码分析 5:提取特征向量[以颜色布局为例]
===================================================== LIRe源代码分析系列文章列表: LIRe 源代码分析 1:整体结构 LIRe 源代码分析 ...
- pyhanlp 共性分析与短语提取内容详解
pyhanlp 共性分析与短语提取内容详解 简介 HanLP中的词语提取是基于互信息与信息熵.想要计算互信息与信息熵有限要做的是 文本分词进行共性分析.在作者的原文中,有几个问题,为了便于说明,这 ...
随机推荐
- redis 主从 及集群
一.redis 主从架构 搭建redis 主从 (可以用一台主机,也可以两台主机) 环境准备: 一台服务器:192.168.206.6 操作系统:CentOS7.5 redis 版本: redis ...
- C++求解数组中出现超1/4的三个数字。
#include <iostream> using namespace std; //求x!中k因数的个数. int Grial(int x,int k) { int Ret = 0; w ...
- iOS tableview cell 的展开收缩
iOS tableview cell 的展开收缩 #import "ViewController.h" @interface ViewController ()<UITabl ...
- debug 和release 的区别
http://blog.csdn.net/h_wlyfw/article/details/26688677
- linux 经常使用网络命令
1. ifconfig ifconfig主要是能手动启动.观察和改动网络接口的相关參数.能改动的參数许多,包含IP參数及MTU等都能改动,他的语法例如以下: [root@linux ~]# ifco ...
- OSS与文件系统的对比
基本概念介绍_开发指南_对象存储 OSS-阿里云 https://help.aliyun.com/document_detail/31827.html 强一致性 Object 操作在 OSS 上具有 ...
- HDU5806 NanoApe Loves Sequence Ⅱ
NanoApe Loves Sequence Ⅱ Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 262144/131072 K (Ja ...
- ZOJ1450 Minimal Circle 最小圆覆盖
ZOJ1450 给定N个点(N<=100)求最小的圆把这些点全部覆盖 考虑对于三角形,可以唯一的找到外接圆,而多边形又可以分解为三角形,所以对于多边形也可以找到唯一的最小覆盖圆. #includ ...
- 逻辑频道号---DVB NIT LCN
先介绍NIT,NIT描述如下: 有一点要注意,NIT是对大网的描述,即NIT并不是描述当前的流,而是描述大网的某些或者全部流.如下图,TS流描述1-6共对6个频点不同的TS流进行了描述,具体对哪一个流 ...
- 框架-Java:Spring Boot
ylbtech-框架-Java:Spring Boot 1.返回顶部 1. Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该 ...