理解http浏览器的协商缓存和强制缓存
阅读目录
- 二:理解协商缓存
一:浏览器缓存的作用是什么?
1. 缓存可以减少冗余的数据传输。节省了网络带宽,从而更快的加载页面。
2. 缓存降低了服务器的要求,从而服务器更快的响应。
那么我们使用缓存,缓存的资源文件到什么地方去了呢?
那么首先来看下 memory cache 和 disk cache 缓存
memory cache: 它是将资源文件缓存到内存中。等下次请求访问的时候不需要重新下载资源,而是直接从内存中读取数据。
disk cache: 它是将资源文件缓存到硬盘中。等下次请求的时候它是直接从硬盘中读取。
那么他们两则的区别是?
memory cache(内存缓存)退出进程时数据会被清除,而disk cache(硬盘缓存)退出进程时数据不会被清除。内存读取比硬盘中读取的速度更快。但是我们也不能把所有数据放在内存中缓存的,因为内存也是有限的。
memory cache(内存缓存)一般会将脚本、字体、图片会存储到内存缓存中。
disk cache(硬盘缓存) 一般非脚本会存放在硬盘中,比如css这些。
缓存读取的原理:先从内存中查找对应的缓存,如果内存中能找到就读取对应的缓存,否则的话就从硬盘中查找对应的缓存,如果有就读取,否则的话,就重新网络请求。
那么浏览器缓存它又分为2种:强制缓存和协商缓存。
协商缓存原理:客户端向服务器端发出请求,服务端会检测是否有对应的标识,如果没有对应的标识,服务器端会返回一个对应的标识给客户端,客户端下次再次请求的时候,把该标识带过去,然后服务器端会验证该标识,如果验证通过了,则会响应304,告诉浏览器读取缓存。如果标识没有通过,则返回请求的资源。
那么协商缓存的标识又有2种:ETag/if-None-Match 和 Last-Modified/if-Modify-Since
协商缓存Last-Modified/if-Modify-Since
浏览器第一次发出请求一个资源的时候,服务器会返回一个last-Modify到hearer中. Last-Modify 含义是最后的修改时间。
当浏览器再次请求的时候,request的请求头会加上 if-Modify-Since,该值为缓存之前返回的 Last-Modify. 服务器收到if-Modify-Since后,根据资源的最后修改时间(last-Modify)和该值(if-Modify-Since)进行比较,如果相等的话,则命中缓存,返回304,否则, 如果 Last-Modify > if-Modify-Since, 则会给出200响应,并且更新Last-Modify为新的值。
下面我们使用node来模拟下该场景。基本的代码如下:
import Koa from 'koa';
import path from 'path'; //静态资源中间件
import resource from 'koa-static';
const app = new Koa();
const host = 'localhost';
const port = 7788; const url = require('url');
const fs = require('fs');
const mime = require('mime'); app.use(async(ctx, next) => {
// 获取文件名
const { pathname } = url.parse(ctx.url, true);
// 获取文件路径
const filepath = path.join(__dirname, pathname);
const req = ctx.req;
const res = ctx.res;
// 判断文件是否存在
fs.stat(filepath, (err, stat) => {
if (err) {
res.end('not found');
} else {
// 获取 if-modified-since 这个请求头
const ifModifiedSince = req.headers['if-modified-since'];
// 获取最后修改的时间
const lastModified = stat.ctime.toGMTString();
// 判断两者是否相等,如果相等返回304读取浏览器缓存。否则的话,重新发请求
if (ifModifiedSince === lastModified) {
res.writeHead(304);
res.end();
} else {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('Last-Modified', stat.ctime.toGMTString());
// fs.createReadStream(filepath).pipe(res);
}
}
});
await next();
}); app.use(resource(path.join(__dirname, './static'))); app.listen(port, () => {
console.log(`server is listen in ${host}:${port}`);
});
当我们第一次访问的时候(清除浏览器的缓存),如下图所示:

当我们继续刷新浏览器的时候,我们再看下如下数据:
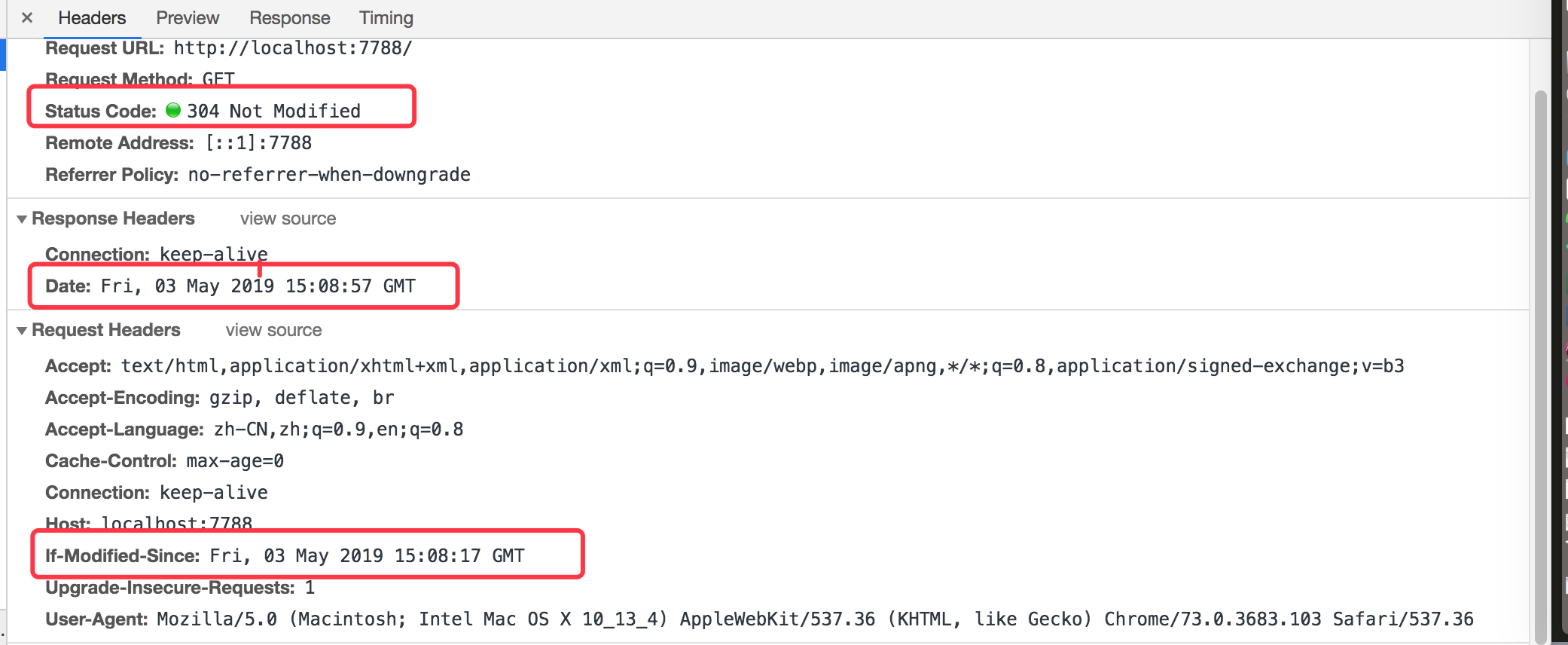
如上可以看到,当我们第二次请求的时候,请求头部加上了 If-Modified-Since 该参数,并且该参数的值该响应头中的时间相同。因此返回304状态。
查看demo,请看github上的源码
协商缓存ETag/if-None-Match
ETag的原理和上面的last-modified是类似的。ETag则是对当前请求的资源做一个唯一的标识。该标识可以是一个字符串,文件的size,hash等。只要能够合理标识资源的唯一性并能验证是否修改过就可以了。ETag在服务器响应请求的时候,返回当前资源的唯一标识(它是由服务器生成的)。但是只要资源有变化,ETag会重新生成的。浏览器再下一次加载的时候会向服务器发送请求,会将上一次返回的ETag值放到request header 里的 if-None-Match里面去,服务器端只要比较客户端传来的if-None-Match值是否和自己服务器上的ETag是否一致,如果一致说明资源未修改过,因此返回304,如果不一致,说明修改过,因此返回200。并且把新的Etag赋值给if-None-Match来更新该值。
last-modified 和 ETag之间对比
1. 在精度上,ETag要优先于 last-modified。
2. 在性能上,Etag要逊于Last-Modified,Last-Modified需要记录时间,而Etag需要服务器通过算法来计算出一个hash值。
3. 在优先级上,服务器校验优先考虑Etag。
下面我们继续使用node来演示下:基本代码如下:
import path from 'path';
import Koa from 'koa'; //静态资源中间件
import resource from 'koa-static';
const app = new Koa();
const host = 'localhost';
const port = 7878; const url = require('url');
const fs = require('fs');
const mime = require('mime');
/*
const crypto = require('crypto');
app.use(async(ctx, next) => {
// 获取文件名
const { pathname } = url.parse(ctx.url, true);
// 获取文件路径
const filepath = path.join(__dirname, pathname);
const req = ctx.req;
const res = ctx.res;
// 判断文件是否存在
fs.stat(filepath, (err, stat) => {
if (err) {
res.end('not found');
} else {
console.log(111);
// 获取 if-none-match 这个请求头
const ifNoneMatch = req.headers['if-none-match'];
const readStream = fs.createReadStream(filepath);
const md5 = crypto.createHash('md5');
// 通过流的方式读取文件并且通过md5进行加密
readStream.on('data', (d) => {
console.log(333);
console.log(d);
md5.update(d);
});
readStream.on('end', () => {
const eTag = md5.digest('hex');
// 验证Etag 是否相同
if (ifNoneMatch === eTag) {
res.writeHead(304);
res.end();
} else {
res.setHeader('Content-Type', mime.getType(filepath));
// 第一次服务器返回的时候,会把文件的内容算出来一个标识,发给客户端
fs.readFile(filepath, (err, content) => {
// 客户端看到etag之后,也会把此标识保存在客户端,下次再访问服务器的时候,发给服务器
res.setHeader('Etag', etag);
// fs.createReadStream(filepath).pipe(res);
});
}
});
}
});
await next();
});
*/
// 我们这边直接使用 现成的插件来简单的演示下。如果要比较的话,可以看上面的代码原理即可
import conditional from 'koa-conditional-get';
import etag from 'koa-etag';
app.use(conditional());
app.use(etag()); app.use(resource(path.join(__dirname, './static'))); app.listen(port, () => {
console.log(`server is listen in ${host}:${port}`);
});
如上基本代码,当我们第一次请求的时候(先清除浏览器缓存),可以看到如下图所示:

如上我们可以看到返回值里面有Etag的值。
然后当我们再次刷新浏览器代码的时候,浏览器将会带上 if-None-Match请求头,并赋值为上一次返回头的Etag的值。
然后和服务器端的Etag的值进行对比,如果相等的话,就会返回304 Not Modified。如下图所示:

我们再来改下html的内容,我们再来刷新下看看,可以看到页面内容发生改变了,因此Etag值是不一样的。如下图所示
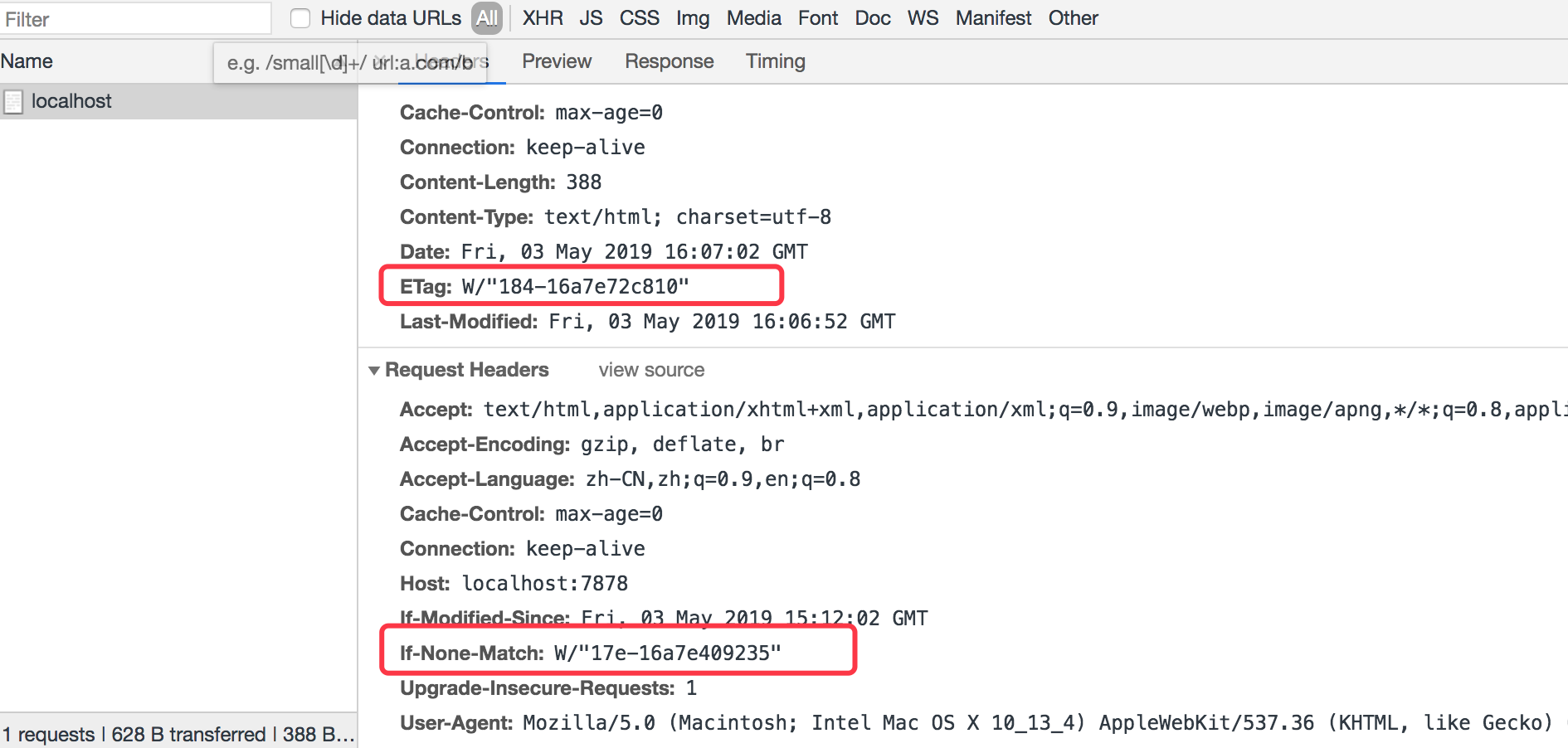
然后我们继续刷新,就会返回304了,因为它会把最新的Etag的值赋值给 if-None-Match请求头,然后请求的时候,会把该最新值带过去,因此如下图所示可以看到。
如上就是协商缓存的基本原理了。下面我们来看下强制缓存。
三:理解强制缓存
基本原理:浏览器在加载资源的时候,会先根据本地缓存资源的header中的信息(Expires 和 Cache-Control)来判断是否需要强制缓存。如果命中的话,则会直接使用缓存中的资源。否则的话,会继续向服务器发送请求。
Expires
Expires 是http1.0的规范,它的值是一个绝对时间的GMT格式的时间字符串。这个时间代表的该资源的失效时间,如果在该时间之前请求的话,则都是从缓存里面读取的。但是使用该规范时,可能会有一个缺点就是当服务器的时间和客户端的时间不一样的情况下,会导致缓存失效。
Cache-Control
Cache-Control 是http1.1的规范,它是利用该字段max-age值进行判断的。该值是一个相对时间,比如 Cache-Control: max-age=3600, 代表该资源的有效期是3600秒。除了该字段外,我们还有如下字段可以设置:
no-cache: 需要进行协商缓存,发送请求到服务器确认是否使用缓存。
no-store:禁止使用缓存,每一次都要重新请求数据。
public:可以被所有的用户缓存,包括终端用户和 CDN 等中间代理服务器。
private:只能被终端用户的浏览器缓存,不允许 CDN 等中继缓存服务器对其缓存。
Cache-Control 与 Expires 可以在服务端配置同时启用,同时启用的时候 Cache-Control 优先级高。
下面我们来看下使用 max-age 设置多少秒后过期来验证下。最基本的代码如下:
import path from 'path';
import Koa from 'koa'; //静态资源中间件
import resource from 'koa-static';
const app = new Koa();
const host = 'localhost';
const port = 7878; app.use(async (ctx, next) => {
// 设置响应头Cache-Control 设置资源有效期为300秒
ctx.set({
'Cache-Control': 'max-age=300'
});
await next();
}); app.use(resource(path.join(__dirname, './static'))); app.listen(port, () => {
console.log(`server is listen in ${host}:${port}`);
});
如上我们设置了300秒后过期,也就是有效期为5分钟,当我们第一次请求页面的时候,我们可以查看下如下所示:

我们可以看到响应头中有Cache-Control字段 max-age=300 这样的,并且状态码是200的状态。
下面我们继续来刷新下页面,可以看到请求如下所示:

请求是200,但是数据是从内存里面读取,如上截图可以看到。
我们现在再把该页面关掉,重新打开新的页面,打开控制台网络,再查看下可以看到如下所示:

因为内存是存在进程中的,当我们关闭页面的时候,内存中的资源就被释放掉了,但是磁盘中的数据是永久的,如上我们可以看到数据从硬盘中读取的。
如上设置的有效期为5分钟,5分钟过后我们再来刷新下页面。如下所示:
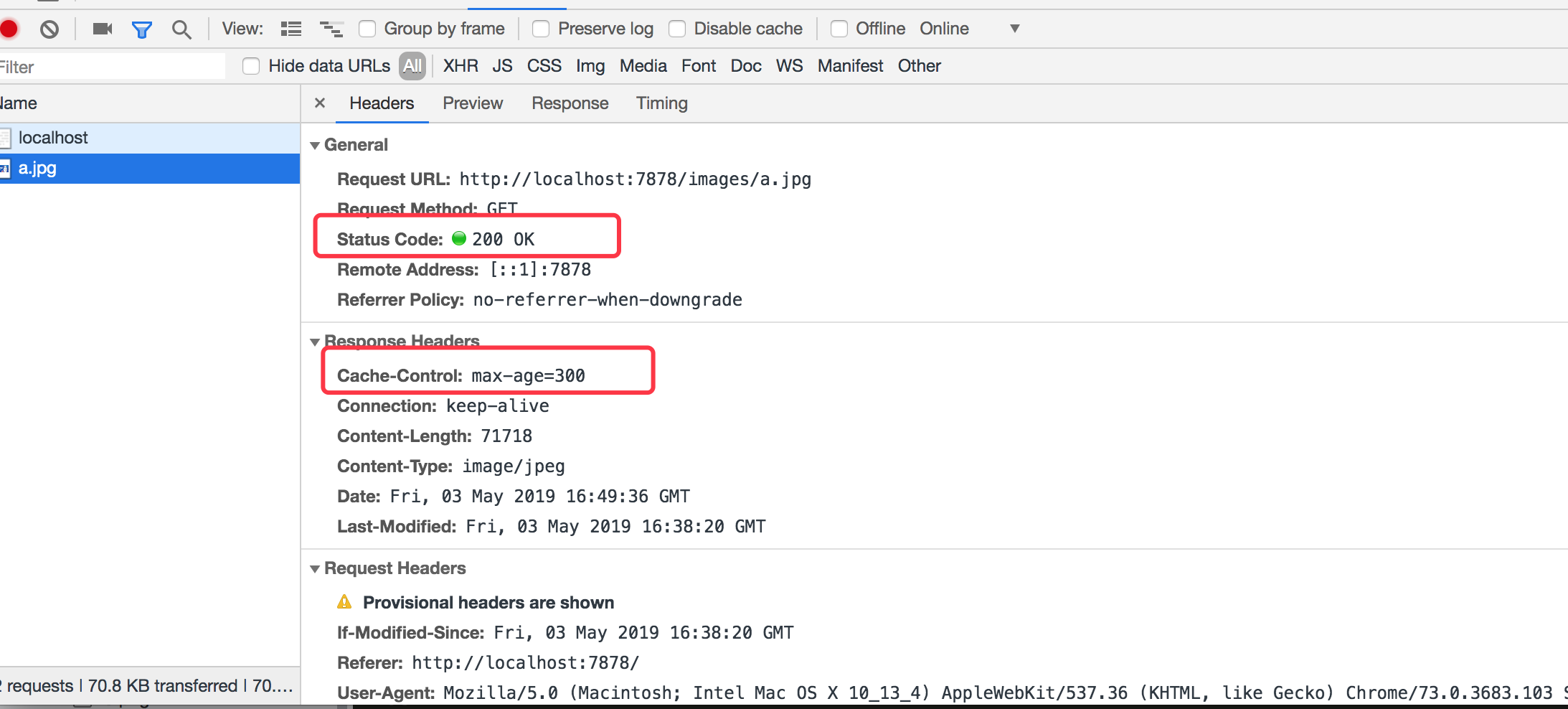
如上可以看到 5分钟过期后,就不会从内存或磁盘中读取了,而是重新请求下服务器的资源。如上就是使用 max-age 来演示强制缓存的了。
查看github源码
理解http浏览器的协商缓存和强制缓存的更多相关文章
- 区分http请求状态码来理解缓存(协商缓存和强制缓存)
什么是http缓存呢,当我们使用chrome浏览器,按F12打开控制台,在网络请求中有时候看到状态码是200,有时候状态码是304,当我们去看这种请求的时候,我们会发现状态码为304的状态结果是:St ...
- http强制缓存、协商缓存、指纹ETag详解
目录 实操目录及步骤 缓存分类 强制缓存 对比缓存 指纹 Etag 摘要及加密算法 缓存总结 每个浏览器都有一个自己的缓存区,使用缓存区的数据有诸多好处,减少冗余的数据传输,节省网络传输.减少服务器负 ...
- 亿级流量客户端缓存之Http缓存与本地缓存对比
客户端缓存分为Http缓存和本地缓存,使用缓存好处很多,例如减少相同数据的重复传输,节省网络带宽资源缓解网络瓶颈,降低了对原始服务器的要求,避免出现过载,这样服务器可以更快响应其他的请求 Http缓存 ...
- HTTP 强制缓存和协商缓存
Web 缓存能够减少延迟与网络阻塞,进而减少显示某个资源所用的时间.借助 HTTP 缓存,Web 站点变得更具有响应性. 缓存优点: 减少不必要的数据传输,节省带宽 减少服务器负担,提升网站性能 加快 ...
- 浏览器缓存_HTTP强缓存和协商缓存
浏览器缓存 浏览器缓存是浏览器在本地磁盘对用户最近请求过的文档进行存储,当访问者再次访问同一页面时,浏览器就可以直接从本地磁盘加载文档. 所以根据上面的特点,浏览器缓存有下面的优点: 减少冗余的数据传 ...
- 浏览器相关,关于强缓存、协商缓存、CDN缓存。
强缓存和协商缓存 在介绍缓存的时候,我们习惯将缓存分为强缓存和协商缓存两种.两者的主要区别是使用本地缓存的时候,是否需要向服务器验证本地缓存是否依旧有效. 顾名思义,协商缓存,就是需要和服务器进行协商 ...
- 缓存(CDN缓存,浏览器(客户端)缓存)
1.什么是缓存? 缓存是一种数据结构,用于快速查找以及执行的操作结果.因此,如果一个操作执行起来很慢,对于常用的输入数据就可以将操作的结果缓存,并在下次调用该操作时使用缓存的数据. 缓存是一个到处都存 ...
- http协商缓存VS强缓存
之前一直对浏览器缓存只能描述一个大概,深层次的原理不能描述上来:终于在前端的两次面试过程中被问倒下,为了泄恨,查阅一些资料最终对其有了一个更深入的理解,废话不多说,赶紧来看看浏览器缓存的那些事吧,有不 ...
- [Web] 深入理解现代浏览器
转载: https://blog.csdn.net/qihoo_tech/article/details/91921777 奇技指南 身为前端,你真正深入理解了浏览器吗? 本文来自公众号奇舞周刊,作者 ...
随机推荐
- SDUTOJ 2475 Power Strings
<pre class="cpp" name="code">#include<iostream> #include<stdio.h& ...
- 在开发过程中,如何在手机上测试vue-cli构建的项目
由于有时候谷歌手机调试与真是的手机环境还是有一定的差距,所以需要在手机上测试项目. 手机上测试vue-cli构建项目方法: 打开项目config/index.js文件,找到module.exports ...
- C语言-- static 全局使用示例
C语言-- static 全局使用示例 前言:看到很多使用Objective-C开发IOS的大牛,有时候会使用static全局变量,相比之下,我却很少用这个,从而很少对其有着比较有实质意义的理解,甚 ...
- The Pilots Brothers' refrigerator-DFS路径打印
I - The Pilots Brothers' refrigerator Time Limit:1000MS Memory Limit:65536KB 64bit IO Format ...
- 在CentOS上把PHP从5.4升级到5.5
在CentOS上把PHP从5.4升级到5.5 摘要:本文记录了在CentOS 6.3上,把PHP从5.4.8升级到5.5.13的过程. 1. 概述 在我做的一个项目中,最近我对生产服务器上的一系列系统 ...
- 关于java及多线程
http://www.w3cschool.cc/java/java-multithreading.html
- Java中有多少种设计模式?请简单画一下三种常见设计模式的类图?
转载:http://blog.csdn.net/longyulu/article/details/9159589 一.设计模式的分类 总体来说设计模式分为三大类: 创建型模式,共五种:工厂方法模式.抽 ...
- CRM 插件奇怪的报错
CRM插件,数据库方式注册.报错 找不到方法:“Void Microsoft.Xrm.Sdk.Entity..ctor(System.String, System.Guid)”. 这个错误让人摸不着头 ...
- go---weichart个人对Golang中并发理解
个人觉得goroutine是Go并行设计的核心,goroutine是协程,但比线程占用更少.golang对并发的处理采用了协程的技术.golang的goroutine就是协程的实现. 十几个gorou ...
- POJ1679 The Unique MST —— 次小生成树
题目链接:http://poj.org/problem?id=1679 The Unique MST Time Limit: 1000MS Memory Limit: 10000K Total S ...