Oracle 理论到实践之碎碎念
有关 Oracle 的著名谣传
1、如果你想把表中数据复制到另一张表,或者想根据现有表创建一个类似的新表,网上有大量不明所以的帖子告诉你实现该功能的语法是select field1,field2 into tableA from tableB。实际上这个是 T-SQL 的语法,用于 SQL Server,而在 Oracle 支持的 PL/SQL 中的语法是CREATE TABLE tableA AS SELECT * FROM tableB。
我相信这个谣传害过很多人,许多新手搜到 SQL Server 中那个语法后激动不已,以为自己捡到了个宝,结果依葫芦画瓢折腾了半天还是报错。
2、在 SQL Server 中有个计算列的功能,我曾想在 Oracle 中使用类似功能,于是看了大量讲解 Oracle 中计算列的帖子,后来才发现那些帖子都是些不明所以的人瞎发布的。事实上,Oracle 中根本就没有计算列一说。后来我分析,要在 Oracle 实现类似效果,可以通过视图来实现,普通视图和物化视图都是值得考虑的选择。
有关索引失效和全表扫描的
要避免在索引列上使用 NOT,NOT 会产生和在索引列上使用函数相同的影响。当 Oracle 遇到 NOT,他就会停止使用索引转而执行全表扫描。
避免使用 <> 或 != 操作符,对不等于操作符的处理会造成全表扫描,可以用 < 或 > 来替代。
避免对索引列进行计算,在 WHERE 子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描。
如果索引不是基于函数的,那么当在 WHERE 子句中对索引列使用函数时,索引不再起作用。
一般 NOT EXISTS 总是比 NOT IN 要高效,因为 NOT IN 会对子查询中的表执行了一个全表扫描,并在子查询中进行内部的排序和合并。
当通配符 % 或者 _ 作为查询字符串的第一个字符时,会导致索引失效。
避免在索引列上使用 IS NULL 和 IS NOT NULL,事实上应该避免在索引中使用任何可以为空的列,否则 Oracle 将无法使用该索引。因为空值不存在于索引列中(对于单列索引,如果列包含空值,索引中将不存在此记录。对于复合索引,如果每个列都为空,索引中同样不存在此记录。如果至少有一个列不为空,则记录存在于索引中。),所以 WHERE 子句中对索引列进行空值比较将会导致索引失效。
总是使用索引的第一个列,如果索引是建立在多个列上,只有在它的第一个列(leading column)被 WHERE 子句引用时,优化器才会选择使用该索引。这是一条简单而重要的规则,当仅引用索引的第二个列时,优化器会使用全表扫描而忽略索引的存在。
对数据类型不同的列进行比较时,会使索引失效。
概念性的定义或说明
首先从业务角度去简化问题,其次是业务逻辑大于性能要求,再次是限定复杂业务逻辑查询的应用场合。
数据库时间 = 数据库等待时间 + 数据库 CPU 时间。
伪列就是并非在表中真正存在的列,但又可以像表中的列那样被操作,只不过操作只能是 SELECT,不能是 INSERT、UPDATE 和 DELETE。伪列很像一个不带参数的函数,但针对结果集中的每一条记录,通常一个不带参数的函数总会返回一个固定值,而伪列则通常返回不一样的值。
数据的完整性就是指数据库中的数据在逻辑上的一致性和准确性。数据完整性一般分为 3 种:域完整性、实体完整性和参照完整性。完整性约束是通过限制列数据、行数据和表之间的数据来保证数据的完整性。完整性约束定义在表上,存储在数据字典中。
SELECT 子句中应避免使用星号,Oracle 在解析的过程中,会将星号依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间。
要尽可能减少访问数据库的次数,如把多个简单的数据库查询整合到一个查询中(即使它们之间没有关系);因为 Oracle 要在内部完成许多工作,如解析 SQL 语句、估算索引的利用率、绑定变量、读数据块等。
COMMIT 释放的资源有:回滚段上用于恢复数据的信息、被程序语句获得的锁、重做日志缓冲区(redo log buffer)中的空间、Oracle 为管理前面 3 种资源的内部耗费。
如果一个查询条件既可以放在 WHERE 后面,也能放在 ON 后面,还能放在 HAVING 后面,那么优先放在 ON 后面,其次是 WHERE 后面,再次是 HAVING 后面。因为 ON 最先执行,WHERE 次之,HAVING 最后,越早执行就越能减少中间运算需要处理的数据。
使用索引能得到查询效率的提高,但是我们也必须注意到它的代价。索引需要额外的空间来存储和处理,每当有记录在表中增减或索引列被修改时, 索引本身也会被修改。这意味着每条记录的 INSERT、DELETE、UPDATE 将为此多付出 4、5 次的磁盘 I/O。那些非必要的索引反而会使查询反应时间变长,所以定期的维护重构索引是有必要的。
尽可能用 >= 4 替代 > 4,二者的区别在于,前者 DBMS 将直接跳到第一个等于 4 的记录,而后者将首先定位到等于 3 的记录,再向前扫描到第一个大于 3 的记录。
如果所有条件都包含在索引中,则应使用 UNION 替代 OR,因为 OR 将会造成全表扫描。相反,则查询效率可能会因为你没有选择 OR 而降低。如果你坚持要用 OR,那就需要将返回记录最少的索引列写在最前面。
ORDER BY 子句只在两种严格的条件下使用索引。第一,ORDER BY 中所有的列必须包含在相同的索引中并保持在索引中的排列顺序;第二,ORDER BY 中所有的列必须定义为非空。
带有 DISTINCT、UNION、MINUS、INTERSECT、ORDER BY 的 SQL 语句会启动 SQL 引擎执行耗费资源的排序功能。DISTINCT 语句会一次排序操作,其它几个语句至少会执行两次排序。通常,带有 UNION、MINUS、INTERSECT 的 SQL 语句都可以用其它方式重写。当然,如果你的数据库的 SORT_AREA_SIZE 调配的好,使用 UNION、MINUS、INTERSECT 也是可以考虑的,毕竟它们的可读性很强。
根据主子表数据量大小来判断应该使用 EXISTS 还是 IN 。因为 Oracle 在执行 IN 子查询时,首先执行子查询,将查询结果放入临时表再执行主查询;而 EXIST 则是首先检查主查询,然后运行子查询直到找到第一个匹配项。
在通过 || 连接列时,最后一个连接列索引会无效。尽量避免连接,可以分开连接或者使用不作用在列上的函数替代。
UNION 操作符会对结果进行筛选,消除重复,数据量大的情况下可能会引起磁盘排序。如果不需要删除重复记录,应该使用 UNION ALL。
当在 SQL 语句中连接多个表时,使用表的别名来限定每一个列名,能有效减少解析时间,还能避免那些由列名歧义引起的语法错误。
SQL Server 数据库的并发模型是:写会阻塞读,读会阻塞写,而且锁是稀有资源。
Oracle 能够透明的处理分布式事务,这得益于 Oracle 中有数据库链接(database link)。但不能在数据库链接上发出任何事务控制语句,如 COMMIT@remote_site、SAVEPOINT、DDL 等。
2PC(two-phase commit protocol,二段提交协议)是一个分布式协议,如果一个修改影响到多个不同的数据库,2PC 允许原子性地提交这个修改。
锁可以分为保护元数据的锁——TM 锁,和保护普通数据的锁——TX 锁(表级锁和行级锁)。
- 1、锁定数据的锁,也就是行级锁,只有一种——排它锁 exclusive(row)。
2、锁定表上的锁,即锁定元数据的锁 metadata(table),一共有 5 种:RS(row share)、RX(row exclusive)、S(share)、SRX(share row exclusive)、X(exclusive)。
SELECT * FROM V$LOCK;
SELECT * FROM V$LOCK_TYPE t WHERE t.type IN('TM','TX');
SELECT * FROM SYS.SEQ$;
鉴于数据库是存在大量并发访问的,只要存在并发访问,死锁就无法彻底避免,无非是几率大小而已。Oracle 数据库有检测当前会话死锁的功能,当死锁发生时,两个或多个并发事务相互等待,不靠外力就再也无法继续执行完了。数据库检测到死锁时,就会将死锁的各个事务回滚,并抛出 ORA-00060 异常。所以我们访问数据的程序,特别是无人值守的程序,一定要能处理此异常,在数据库发生这个异常之后,将其记录在日志中,并继续(重新)执行访问数据库的操作。当然,我们还可以通过改进程序的效率来减少死锁发生的几率。首先可以提供数据库访问效率,优化数据库,优化 SQL,尽量减少访问数据库的时间,从而降低与其他会话并发死锁的可能性。另外,在业务允许的情况下,应尽可能减少数据库事务的范围,将一个大的事务,分成小的事务,尽早提交。当然,事务的划分这是由业务决定的,不可能随便分开。
表空间使用策略:
- 1、一般较大的表或索引单独分配一个 tablespace。
- 2、Read only 对象或 Read mostly 对象分成一组,存到对应的 tablespace 中。
- 3、若 tablespace 中的对象皆是 read only 对象,可将 tablespace 设置成 read only 模式,在备份时,read only tablespace 只需备份一次。
- 4、高频率 insert 的对象分成一组,存在对应的 tablespace 中。
- 5、增、删、改的对象分成一组,存在对应的 tablespace 中。
- 6、表和索引分别存于不同的 tablespace。
- 7、在同一个 tablespace 中的表(或索引)的 extent 大小最好成倍数关系,有利于空间的重利用和减少碎片。
《Oracle SQL 高级编程》摘抄
不得不说,《Oracle SQL 高级编程》应该是 Oracle 领域最优质的书之一,很多知识点讲得比较通透。两年前我得知该书的时候,当当网、亚马逊、京东、天猫等网站上都卖断货了,后来公司一个实习的测试妹子帮我从她们学校图书馆里借到一本。借到书后那段时间比较忙,领导天天让加班,两个月时间也就看了前两三章的样子。现在想起来感觉还是挺可惜的,因为即使能再借到也没法静下心来看了。下面那会儿看书的时候做的一些摘抄:
Oracle 调用接口(Oracle Call Interface 简称 OCI)提供了一组可对 Oracle 数据库进行存取的接口子例程(函数),通过在第三代程序设计语言(如C语言)中进行调用可达到存取 Oracle 数据库的目的。
OCI 将由 Oracle 内核传送而来的查询语句发送到数据库。当使用某种 Oracle 工具如 SQL*Plus 或者 SQL Developer 时,你都在使用 OCI。
在连接 Oracle 数据库之前,还需要在 $ORACLE_HOME/network/admin/tnsnames.ora 这个文件中登记想要连接的数据库。
你写SQL语句的方法并不仅仅会影响到这一句 SQL 语句本身。数据库中正在执行的所有 SQL 语句结合在一起将会因为它们对共享池(SGA)的影响而对总的性能和可拓展性带来巨大的影响。
共享池是 Oracle 缓存程序数据的地方。执行过的每一句 SQL 语句在共享池中都存有解析后的内容。共享池中存储这些语句的地方称为库高速缓存(library cache)。即在解析每一句语句之前,Oracle 都会检查库高速缓存看其中是否已经存在同样的语句。如果存在,Oracle 就会直接从缓存中读取并使用该信息而不是将同样的语句在解析一遍。对于你运行的任何 PL/SQL 代码,情况也是这样的。非常妙的一点是,不管有多少个用户想要执行同样的 SQL 语句,Oracle 通常都会只解析该语句一次,然后在所有想要使用的用户之间共享。
当你写SQL语句的时候,需要牢记于心的一点是:为了更高效地使用共享池,语句需要可以共享。如果你所写的每一句语句都是唯一的,基本上就违背了设立共享池的初衷。语句共享性越差,你将看到对于响应时间的影响也就会越大。
硬解析比软解析需要 Oracle 做的工作要多得多。每次进行硬解析的时候,在能够实际执行语句之前,Oracle 必须收集它所需的所有信息。为了得到所需信息,Oracle 需要对数据字典进行一连串的查询。
拓展的 SQL 追踪能抓取解析执行过程中所发生的每一个活动,因此你不仅能看到你所执行的语句,还能看到 Oracle 必须要执行的每一个语句。
为了确定一条语句是不是之前执行过,Oracle 会去检查库高速缓存看是不是存在同样的语句。你可以通过查询 V$SQL 视图来查看当前存放在库高速缓存中的语句。
在执行一条语句时,Oracle 会首先将字符串转换为散列值。这个散列值就作为该语句存放到库高速缓存时的关键字。当其它语句执行时,它们的散列值就会与已有的散列值做比较来寻找匹配。产生散列值时,大写字母与小写字母是不同的。在一个语句添加与不添加注释也是不同的。任何不同都会使得语句具有不同的散列值,从而导致 Oracle 对语句进行硬解析。这也就是为什么在你的 SQL 语句中使用绑定变量而不是常量会如此重要的原因。当使用绑定变量时,即使你改变了绑定变量的值,Oracle 还是可以共享这个语句。
锁存器是 Oracle 为了读取存放在库高速缓存或者其它内存结构中的信息时必须获得的一种锁。锁存器可以保护库高速缓存避免被两个同时进行的回话修改,或者一个会话正要读取的信息被另一个会话修改而导致的损坏。在读取库高速缓存中的任何信息之前,Oracle 都会获得一个锁存器,其它所有会话都必须等待,直到改锁存器被释放它们才能获得锁存器以完成工作。需要记住的一点是锁存器是串行的。Oracle 基本上将会迭代轮询,继续去看锁存器是否可用。在这段时间里,Oracle 积极使用 CPU 去进行检查,而你的查询实际上是“被挂起”的,在锁存器可用之前不会做任何事。Oracle 需要获取锁存器的频率越高,就越有可能发生争夺,你也就不得不等待更长的时间。这对性能和可拓展性的影响是巨大的。正确编写你的代码使其较少的使用锁存器(也就是硬解析)是非常关键的。
执行一句数据块不在缓冲区缓存中的查询会需要 Oracle 访问操作系统以获取这些块,然后在将结果集返回给你之前把它们放入缓冲区缓存中。一般来说,任何一个能够满足 SQL 查询的包含数据行的块都必须出现在缓冲区缓存中。当 Oracle 确定一个数据块已经在缓冲区缓存中的时候,这样的访问被认为是一次逻辑读取。如果该块必须从磁盘中获取,则被认为是物理读取。
1、视图合并是一种能将内嵌或储存式视图展开为能够独立分析或者与查询剩余部分合并成总体执行计划的独立查询块的转换。改写的语句基本上不包含视图。视图合并常常发生在当外部查询块的谓语包括下列项的时候。
- 能够在另一个查询块的索引中使用的列。
- 能够在另一个查询块的分区截断中所使用的列。
- 在一个联结视图中能够限制返回行数的条件。
如果一个查询块包含解析函数或聚合函数、集合运算(例如 UNION、INTERSECT、MINUS),ORDER BY 子句或者使用了 ROWNUM,视图合并将会被禁止或限制。
2、子查询解嵌套与视图合并的相似之处在于子查询也是通过一个单独的查询块来表示的。可合并的视图与可以解嵌套的子查询之间的主要区别在于它们的位置不同:子查询位于 WHERE 子句,由转换器进行解嵌套的审查。最典型的转换就是将子查询转变为表联结。如果一个子查询没有解嵌套,将会为它生成一个独立的子计划并作为总的执行计划的一部分按照优化执行速度的次序依次执行。
3、谓语前推用来将谓语从一个内含查询块中应用到不可合并的查询块中。目标就是允许索引的使用或者让其它对于数数据集的筛选在查询中能够更早的进行。一般来说,将不需要的数据行尽可能早地过滤掉是个好主意。
需要注意的是:使用 ROWNUM 会禁止谓语前推。事实上,ROWNUM 不仅会禁止谓语前推,而且也会禁止视图合并。使用 ROWNUM 就如同在查询中加入了 NO_MEREG 和 NO_PUSH_PRED 提示。
4、查询重写是一种发生在当一个查询或查询的一部分已经被保存为一个物化视图,转换器重写该查询以使用预先计算好的物化视图数据而不需要执行当前查询的转换。物化视图与普通视图区别在于查询已经被执行并将结果集存入了一张表中。这样做的好处是预先计算了查询的结果并且在特定查询执行的时候可以直接调取该结果。也就是说所有的确定执行计划、执行查询以及收集所有数据的工作都已经做完了。因此,当同样的查询再一次执行的时候,就不需要在做一遍了。查询转换器将查询与可用的物化视图相匹配,然后重写该查询以直接从物化结果集中选取查询数据。
执行计划就是 Oracle 访问你的查询所使用的对象并返回相应结果数据将会采用的一系列步骤。为了确定该计划,Oracle 将要收集并使用很多信息。Oracle 确定执行计划所用到最关键的信息之一就是统计信息。可以针对对象(如表和索引)收集统计信息,也可以收集系统统计信息。
优化器是 Oracle 内核中的代码路径,负责(使用统计信息)为查询确定最佳执行计划。
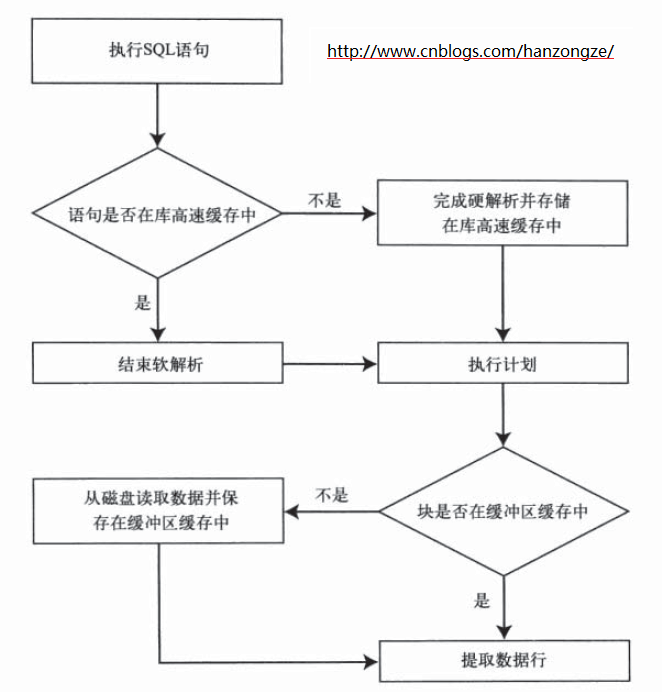
这是一张简化了的图,但封装了所有的步骤。每一个查询都必须完成解析、执行以及提取的步骤。DML 语句(INSERT、UPDATE 及 DELETE)仅需要进行解析和执行。除了这些步骤之外,使用绑定变量的语句作为解析的一部分还需要包含一个步骤来读取绑定值。
全扫描可能是全表扫描,也可能是快速全索引扫描。全扫描是否为高效的选择取决于需要访问的数据块个数以及最终的结果集行数。当对扫描进行多块读取调用时,Oracle将最多读取到位于表中高水位线的数据块。高水位线标出了表中最后一块有数据写入的数据块。为了保持技术上的正确性,这实际上应该被称为“低”高水位线。
当数据行插入一张表的时候,就会为其分配数据块并将数据行放到其中。但即使所有数据行都被删除了并且一些块实际上已经完全变成空的了,高水位线还是保持不变。当进行全扫描运算的时候,到高水位线为止的所有数据块都将被读取并扫描,即使它们是空的。这就意味着许多实际上不需要读取的空数据块也被读取了。
联结的方法有:嵌套循环联结、散列联结、排序-合并联结、以及笛卡尔联结。
每个联结方法都有两个分支。所访问的第一张表通常被称为驱动表(the driving table),访问的第二张表则称为内层表或被驱表(inner 或 driven-to table)。优化器通过使用统计信息和 WHERE 子句中的筛选条件计算每个表分别返回多少行数据来确定那张表是驱动表。预估大小最小(就块、数据行以及字节而言)的表通常被作为驱动表。
嵌套循环联结使用一次访问运算所得到的结果集中的每一行来与另一个表进行对碰。结果集的大小是有限的并且用来联结的列上建有索引的话,这种联结的效率通常是最高的。嵌套循环联结的运算成本主要是读取外层表中的每一行并将其与所匹配的内层表中的行联结所需要的成本。
顾名思义,嵌套循环联结就是一个循环嵌在另一个循环当中。这种类型的联结强大之处在于所使用的内存是非常少的。因为数据行集一次只加工一行,所需开支也是非常小的。
排序-合并联结独立地读取需要联结的两张表,对每张表中的数据行(仅是那些满足 WHERE 子句中条件的数据行)按照联结键进行排序,然后对排序后的数据行进行合并。对这种联结方法来说排序的开销是非常大的。对于不能放入内存中的大的数据源来说,可能会使用临时磁盘空间来完成排序。这是非常耗占内存和时间资源的。
散列联结,与排序-合并联结类似,首先应用WHERE子句中的筛选标准来独立地读取要进行联结的两个表。基于表和索引的统计信息,被确定为返回最少行数的表被完全散列化到内存中。
笛卡尔联结发生在当一张表中的所有行与另一张表中的所有行联结的时候。
外联结返回一张表的所有行以及另一张表中满足联结条件的行数据。Oracle 使用 + 字符来表明进行外联结,+ 号放在一对圆括号中,位于只有匹配才会返回数据行的表联结条件旁。外联结需要外联结表作为驱动表,这意味着有可能不能选用更加优化的联结执行顺序。
其它
数据库未打开的问题解决步骤:
SELECT NAME FROM v$datafile;
ALTER DATABASE DATAFILE 'F:\oracle\product\10.2.0\oradata\orcl\gisqflow.dbf' OFFLINE;
ALTER DATABASE DATAFILE 'F:\oracle\product\10.2.0\oradata\orcl\gisqflow.dbf' OFFLINE DROP;
ALTER DATABASE OPEN;ORA-12154: TNS: 无法解析指定的连接标识符:
http://www.cnblogs.com/psforever/p/3929064.html
本文链接:http://www.cnblogs.com/hanzongze/p/oracle-points.html
版权声明:本文为博客园博主 韩宗泽 原创,作者保留署名权!欢迎通过转载、演绎或其它传播方式来使用本文,但必须在明显位置给出作者署名和本文链接!个人博客,能力有限,若有不当之处,敬请批评指正,谢谢!
Oracle 理论到实践之碎碎念的更多相关文章
- Linux碎碎念
在学习Linux过程中,有许多有用的小技巧.如果放在纸质的笔记本上,平时查阅会相当不方便.现在以一种“碎碎念”的方式,汇集整理在此,目前还不是很多,但随着学习.工作的深入,后续会陆陆续续添加更多的小技 ...
- 最近关于Qt学习的一点碎碎念
最近关于Qt学习的一点碎碎念 一直在使用Qt,但是最近对Qt的认识更加多了一些.所以想把自己的一些想法记录下来. Qt最好的学习资料应该是官方的参考文档了.对Qt的每一个类都有非常详细的介绍.我做了一 ...
- 一些关于Linux入侵应急响应的碎碎念
近半年做了很多应急响应项目,针对黑客入侵.但疲于没有时间来总结一些常用的东西,寄希望用这篇博文分享一些安全工程师在处理应急响应时常见的套路,因为方面众多可能有些杂碎. 个人认为入侵响应的核心无外乎四个 ...
- 一个谷粉和3年的Google Reader重度使用者的碎碎念
2013-03-14 上午看到Andy Rubin辞去Android业务主管职务.由Chrome及应用高级副总裁继任的新闻,还在想这会给Android带来什么,中午刷微博的时候就挨了当头一棒:Goog ...
- Jerry的碎碎念:SAPUI5, Angular, React和Vue
去年我去一个国内客户现场时,曾经和他们IT部门的一位架构师聊到关于在SAP平台上进行UI应用的二次开发时,UI框架是选用UI5还是Vue这个话题. 我们代表SAP, 向客户推荐使用UI5是基于以下六点 ...
- 结对编程ending-我和洧洧的碎碎念
应该是第一次和队友分工合作去完成一个项目,其中也经历了跳进不少坑又被拉回来的过程,总体来说这对于我俩也的确是值得纪念的一次经历. 我的碎碎念时间…… 对比个人项目和结对编程项目二者需求,前者重在面对不 ...
- C语言 · 分分钟的碎碎念
算法提高 分分钟的碎碎念 时间限制:1.0s 内存限制:256.0MB 问题描述 以前有个孩子,他分分钟都在碎碎念.不过,他的念头之间是有因果关系的.他会在本子里记录每一个念头,并用 ...
- Java实现 蓝桥杯VIP 算法提高 分分钟的碎碎念
算法提高 分分钟的碎碎念 时间限制:1.0s 内存限制:256.0MB 问题描述 以前有个孩子,他分分钟都在碎碎念.不过,他的念头之间是有因果关系的.他会在本子里记录每一个念头,并用箭头画出这个念头的 ...
- 碎碎念软件研发02:敏捷之Scrum
一.什么是 Scrum 1.1 Scrum 定义 Scrum 是敏捷开发方法之一,它使用比较广泛. 敏捷的其它开发方法还有 XP(极限编程).FDD(特性驱动开发).Crystal(水晶方法).TDD ...
随机推荐
- https多网站1个IP多个SSL证书的Apache设置办法
这些天接触了解SSL证书后,写了一篇<申请免费的SSL证书,开通https网站>博文,其中简单记录了Apache的设置,后来又涉及到多个域名.泛域名解析.通配符SSL证书.单服务器/多服务 ...
- Java平台
Java的平台无关性 不同的网络环境,操作系统 支持嵌入式设备 减少开发部署时间 Java自身的平台和语言 编译成class文件 可在Java虚拟机中运行,与外部环境无关(对虚拟机的依赖) 通过外部A ...
- MacBook上那些好用的工具们
https://blog.csdn.net/qq_33833327/article/details/78454703
- .net读取excel数据到DataSet中
Dim objExcelFile As Excel.Application Dim objWorkBook As Excel.Workbook Dim objSheet As Excel.Worksh ...
- C++枚举类型Enum及C++11强枚举类型用法
C++中的枚举类型常常和switch配合使用,这里用一个简单的switch控制键盘回调的代码片段来说明枚举的用法: //W A S D 前.后.左.右行走 enum Keydown{ Forward= ...
- Java的this关键字在继承时的作用
1.this.属性 class A{ int a = 10; public void play(){ System.out.println(this.a); } } class B extends A ...
- some knowledge of language
1:编译型语言2:解释型语言编译型:编译形成结果,再整体运行解释型:运行产生结果,边解释运行java 特殊(.class)再解释3:脚本语言是解释语言它的优点是方便阅读,不需要写非常多的类型相关的代码 ...
- MFC中的一些视图
本章主要介绍MFC中主要的视图类,这些继承自Cview类. 继承关系如上图所示. 滚动视图 CscrollView给Cview添加了基本的滚动功能,它包含WM_VSCROLL和WM_HSCROLL消息 ...
- Must Know Tips/Tricks in Deep Neural Networks
Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei) Deep Neural Networks, especially C ...
- {黑掉这个盒子} \\ FluxCapacitor Write-Up
源标题:{Hack the Box} \ FluxCapacitor Write-Up 标签(空格分隔): CTF 好孩子们.今天我们将学习耐心和情绪管理的优点.并且也许有一些关于绕过WEB应用防 ...