rest_framework之视图及源码剖析
最初形态(工作中可能会使用)
引子
Django的CBV我们应该都有所了解及使用,大体概括一下就是通过定义类并在类中定义get post put delete等对应于请求方法的方法,当请求来的时候会自动对应相应的方法并执行,urls.py中需要类点as_view()的方式来配置路由,至于如何拿到请求方法并对应执行我们自定义类中的方法,前面的博客中已经有了源码解析,这里不再陈述~
APIView
我们写的类不再继承Django的View类而是继承rest提供给我们的APIView类,这里对于一个数据表的增删改查我们需要定义两个类来处理
class AuthorView(APIView):
def get():#批量查询
pass
def post():#新增一条数据
pass
class AuthorDetailView(APIView):
def get():#查询一条数据
pass
def delete():#删除一条数据
pass
def put():#修改一条数据
pass
对应urls.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^authors/$',views.AuthorView.as_view()),
url(r'^authors/(\d+)/$',views.AuthorDetail.as_view())
]
过渡
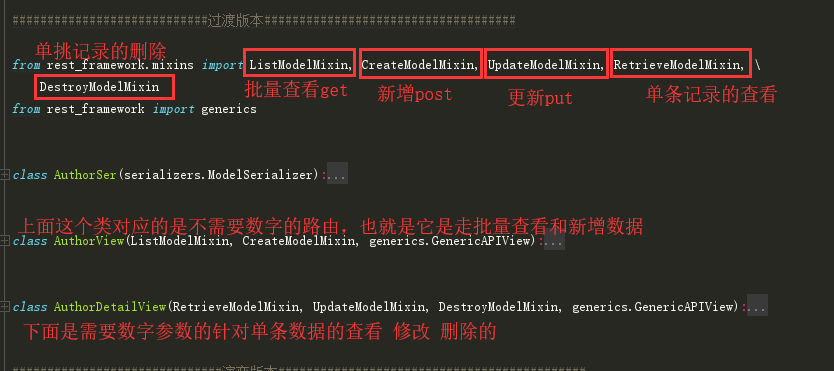
我们来思考一个问题,假设我有十张表,那么根据上面的方法,我需要重复写二十次这样的代码,并且类里面的逻辑路由都是一模一样的,不同的仅仅是表名影响的数据部分,这样的情况是不能允许的,老是重复代码~~~那有没有一种方式可以让我们避免写重复代码,思路就是将这写处理逻辑封装成类方法,我写的类只需要继承封装的类就能调用这些方法即可,还真有对应于我们上面的增删改查封装了这些功能的类
rest_framework.mixins混合类下:
ListModelMixin ————————>>>批量查询(get)
CreateModelMixin ————————>>>新增数据(post)
UpdateModelMixin ————————>>>更新数据(put/patch)
RetrieveModelMixin ————————>>>查看单条数据(get)
DestroyModelMixin ————————>>>删除单条数据(delete)
那么我们自己写的类只需要继承这些类就可以直接调用他们下面的方法,这样就省去了相同的增删改查逻辑
class AuthorSer(serializers.ModelSerializer):
class Meta:
model = models.Author
fields = '__all__'
class AuthorView(ListModelMixin, CreateModelMixin, generics.GenericAPIView):
queryset = models.Author.objects.all()
serializer_class = AuthorSer
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
class AuthorDetailView(RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin, generics.GenericAPIView):
queryset = models.Author.objects.all()
serializer_class = AuthorSer
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
对应的urls.py路由
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'authors/$',views.AuthorView.as_view()),
url(r'authors/(?P<pk>\d+)/$',views.AuthorDetailView.as_view())
]
#这里必须注意需要给后面这个匹配数字的匹配式起一个别名'pk'有且只能叫'pk'这个名字,不然会包缺少pk这个关键参数
演变
上面的过渡确实让我们省去了重复写增删改查逻辑,但是依然有较多的重复代码~~~站在面向对象的思想高度上,能不能再对其进行一层封装让我们连定义方法都不用了呢?
初步思想就是一个类封装了批量查看和新增方法,另一个类封装了针对单条数据的查,改和删。。。。。。
唉~还真有哦,只有你想不到没有我们程序员做不到的~还是继承类,并且这个类你一眼就能看出它想干嘛
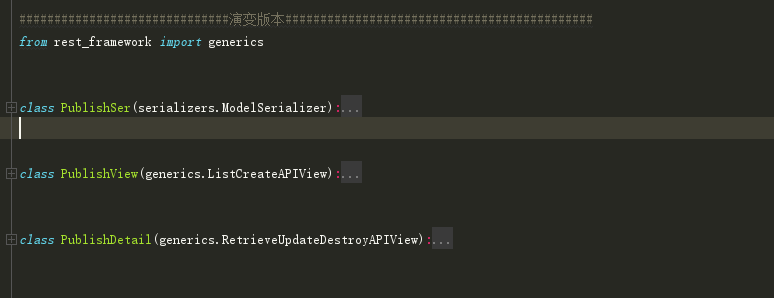
from rest_framework import generics
class PublishSer(serializers.ModelSerializer):
class Meta:
model = models.Publish
fields = '__all__'
class PublishView(generics.ListCreateAPIView):
'''
ListCreateAPIView:集成了List Create APIView于一身
'''
queryset = models.Publish.objects.all()
serializer_class = PublishSer
class PublishDetail(generics.RetrieveUpdateDestroyAPIView):
'''
RetrieveUpdateDestroyAPIView:集成了Retrieve Update Destroy APIView于一身
'''
queryset = models.Publish.objects.all()
serializer_class = PublishSer
相当于在过渡阶段的基础上对类又做了一层封装~~~
究极进化版
如果你认为上面的演变版本已经是最终版本,那你怕是小看了程序员的偷懒能力了,能少敲一个字母绝不会多敲一个!!!
上面的演变版本仍然有重复的代码部分,并且对于一张表我们需要写两个类,这样太麻烦了,能不能将两个类合成一个类呢?
你可能会想合成一个类的话,那我的批量查看get和单条查看get怎么区分???
别急 我们先把最终版本写上,一会儿我们去看看从上之下,从最终的屌丝版本怎么一步步封装成了究极恐怖版本!
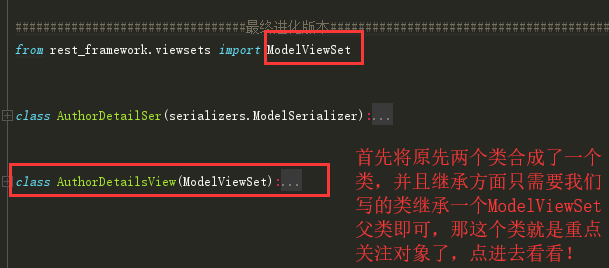
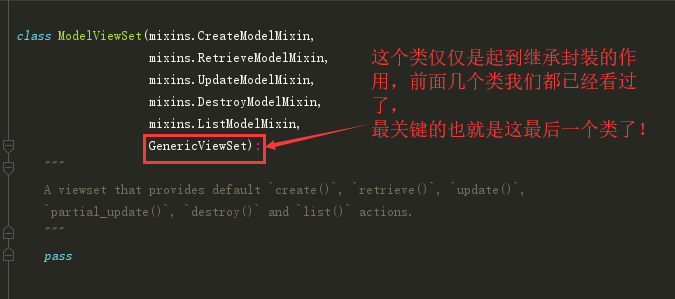
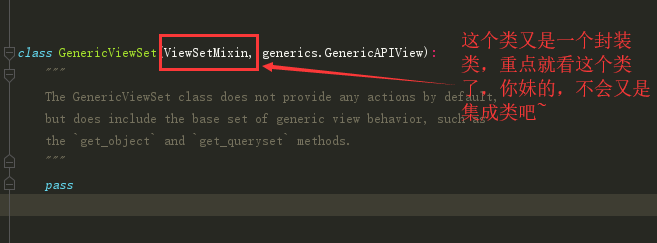
from rest_framework.viewsets import ModelViewSet
class AuthorDetailSer(serializers.ModelSerializer):
class Meta:
model = models.AuthorDetail
fields = '__all__'
class AuthorDetailsView(ModelViewSet):
queryset = models.AuthorDetail.objects.all()
serializer_class = AuthorDetailSer
上述例子所有的路由
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^books/$',views.BookView.as_view()),
url(r'^books/(?P<pk>\d+)/$',views.BookDetail.as_view()),
url(r'^authors/$',views.AuthorView.as_view()),
url(r'^authors/(?P<pk>\d+)/$',views.AuthorDetailView.as_view()),
url(r'^publishes/$',views.PublishView.as_view()),
url(r'^publishes/(?P<pk>\d+)/$',views.PublishDetail.as_view()),
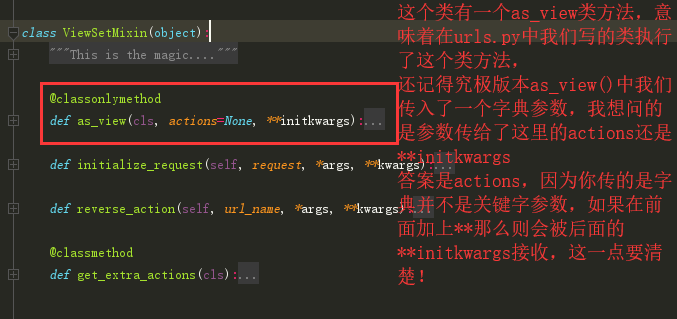
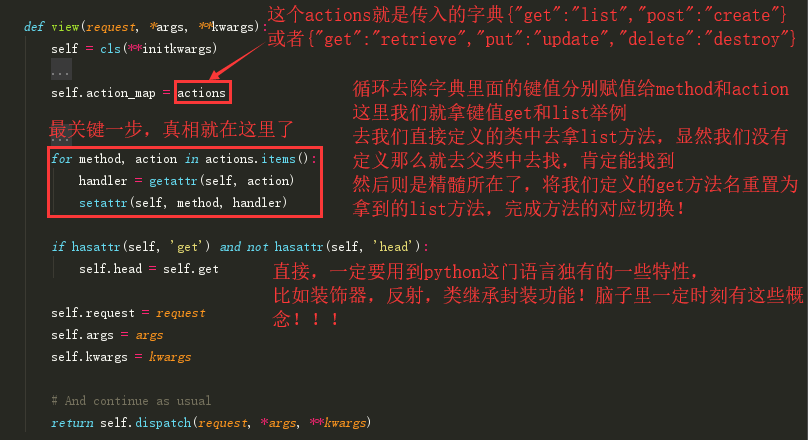
url(r'^authordetail/$',views.AuthorDetailsView.as_view({"get":"list","post":"create"})),
url(r'^authordetail/(?P<pk>\d+)/$',views.AuthorDetailsView.as_view({"get":"retrieve","put":"update","delete":"destroy"}))
]
这里需要着重拿出来说的就是,它是怎么做到区分两个不同get的,一会儿看源码就知道他是将原本的方法都起了别名
get批量查询 ————对应————— list方法 post新增数据 ————对应————— create方法 get单挑数据查询 ————对应————— retrieve方法 put单条数据更新 —————对应———— update方法 delete删除单条数据 —————对应————destroy方法
在路由是两条的情况下,这已经是究极体了,路由不能也不可能简化成一条!!!
源码剖析
APIView源码部分之前的博客已经解析过了,这里就不再赘述,直接从过渡版本开始~
需要知道是为什么会有过渡版本,是站在我们想简化代码,封装相同的逻辑代码块,首先就是对方法的封装,一个类封装一个方法~
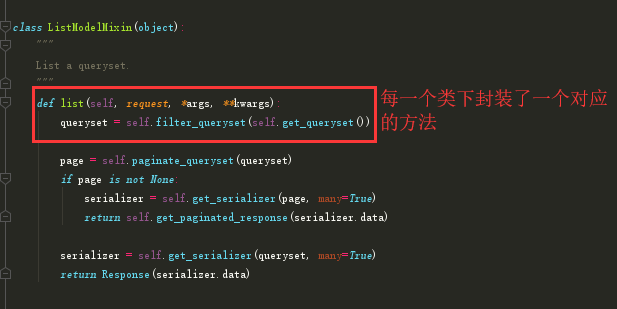
下面我们就去这些类里面看看它们做了什么~

那过渡版本的书写格式的由来就阐述清楚了,接下来看演变版本又是怎么做的

上面几个好像并不能解释清楚到底怎么回事,接下来的究极版本就会有清晰的认识!!!
同样这个类方法返回的是view函数名,也就意味着只有不访问到这个路由,函数view就不会被执行,但是一旦开始访问了,那么就会去执行view函数内的代码
rest_framework之视图及源码剖析的更多相关文章
- Django Rest Framework源码剖析(八)-----视图与路由
一.简介 django rest framework 给我们带来了很多组件,除了认证.权限.序列化...其中一个重要组件就是视图,一般视图是和路由配合使用,这种方式给我们提供了更灵活的使用方法,对于使 ...
- Rest_Framework之认证、权限、频率组件源码剖析
一:使用RestFramwork,定义一个视图 from rest_framework.viewsets import ModelViewSet class BookView(ModelViewSet ...
- Django----djagorest-framwork源码剖析
restful(表者征状态转移,面向资源编程)------------------------------------------->约定 从资源的角度审视整个网络,将分布在网络中某个节点的资源 ...
- RestFramework——API基本实现及dispatch基本源码剖析
基于Django实现 在使用RestFramework之前我们先用Django自己实现以下API. API完全可以有我们基于Django自己开发,原理是给出一个接口(URL),前端向URL发送请求以获 ...
- Django Rest Framework源码剖析(七)-----分页
一.简介 分页对于大多数网站来说是必不可少的,那你使用restful架构时候,你可以从后台获取数据,在前端利用利用框架或自定义分页,这是一种解决方案.当然django rest framework提供 ...
- Django Rest Framework源码剖析(六)-----序列化(serializers)
一.简介 django rest framework 中的序列化组件,可以说是其核心组件,也是我们平时使用最多的组件,它不仅仅有序列化功能,更提供了数据验证的功能(与django中的form类似). ...
- Django Rest Framework源码剖析(五)-----解析器
一.简介 解析器顾名思义就是对请求体进行解析.为什么要有解析器?原因很简单,当后台和前端进行交互的时候数据类型不一定都是表单数据或者json,当然也有其他类型的数据格式,比如xml,所以需要解析这类数 ...
- Django Rest Framework源码剖析(四)-----API版本
一.简介 在我们给外部提供的API中,可会存在多个版本,不同的版本可能对应的功能不同,所以这时候版本使用就显得尤为重要,django rest framework也为我们提供了多种版本使用方法. 二. ...
- Django Rest Framework源码剖析(三)-----频率控制
一.简介 承接上篇文章Django Rest Framework源码剖析(二)-----权限,当服务的接口被频繁调用,导致资源紧张怎么办呢?当然或许有很多解决办法,比如:负载均衡.提高服务器配置.通过 ...
随机推荐
- Jupyter Notebook默认工作路径的修改
相信每一个学习Python的童鞋,都尝试过Jupyter Notebook,所以我也就不多介绍,真的还不错哎这软件. 不过美中不足的,就是它的默认工作路径,每次打开都是系统盘的Administrato ...
- [20180904]工作中一个错误.txt
[20180904]工作中一个错误.txt --//昨天看我提交一份修改建议,发现自己写的sql语句存在错误.--//链接:http://blog.itpub.net/267265/viewspace ...
- 洗礼灵魂,修炼python(71)--爬虫篇—【转载】xpath/lxml模块,爬虫精髓讲解
Xpath,lxml模块用法 转载的原因和前面的一样,我写的没别人写的好,所以我也不浪费时间了,直接转载这位崔庆才大佬的 原帖链接:传送门 以下为转载内容: --------------------- ...
- 自动化测试基础篇--Selenium等待时间
摘自https://www.cnblogs.com/sanzangTst/p/8376221.html 当你觉得你的定位没有问题,但是却直接报了元素不可见,那你就可以考虑是不是因为程序运行太快或者页面 ...
- Elasticsearch-精确查找
转译:(https://www.elastic.co/guide/en/elasticsearch/guide/current/_finding_exact_values.html#_finding_ ...
- WinForm设置注册表自动启动
string path = Application.StartupPath; SetAutoRun(path + @"\AppName.exe", true); /// <s ...
- LeetCode算法题-Add Strings(Java实现)
这是悦乐书的第223次更新,第236篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第90题(顺位题号是415).给定两个非负整数num1和num2表示为字符串,返回num ...
- spring boot +RabbitMQ +InfluxDB+Grafara监控实践
本文需要有相关spring boot 或spring cloud 相关微服务框架的基础,如果您具备相关基础可以很容易的实现下述过程!!!!!!! 希望本文的所说对需要的您有所帮助 从这里我们开始进入闲 ...
- Lingo求解线性规划案例4——下料问题
凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 造纸厂接到定单,所需卷纸的宽度和长度如表 卷纸的宽度 长度 5 7 9 10000 30000 20000 工 ...
- 【大数据技术】HBase与Solr系统架构设计
如何在保证存储量的情况下,又能保证数据的检索速度. HBase提供了完善的海量数据存储机制,Solr.SolrCloud提供了一整套的数据检索方案. 使用HBase搭建结构数据存储云,用来存储海量数据 ...