吴恩达课后作业学习2-week1-2正则化
参考:https://blog.csdn.net/u013733326/article/details/79847918
希望大家直接到上面的网址去查看代码,下面是本人的笔记
4.正则化
1)加载数据
仍是问题:
'c' argument has 1 elements, which is not acceptable for use with 'x' with s
解决——直接导入函数:
import scipy.io as sio
def load_2D_dataset(is_plot=True):
data = sio.loadmat('datasets/data.mat')
train_X = data['X'].T
train_Y = data['y'].T
test_X = data['Xval'].T
test_Y = data['yval'].T
if is_plot:
plt.scatter(train_X[0, :], train_X[1, :], c=np.squeeze(train_Y), s=40, cmap=plt.cm.Spectral); return train_X, train_Y, test_X, test_Y
加载数据:
train_X, train_Y, test_X, test_Y = load_2D_dataset(is_plot=True)
图示:

每一个点代表球落下的可能的位置,蓝色代表我方的球员会抢到球,红色代表对手的球员会抢到球
该神经网络目标是:使用模型来画出一条线,来找到适合我方球员能抢到球的位置。
我们要做以下三件事,来对比出不同的模型的优劣:
- 不使用正则化
- 使用正则化
2.1 使用L2正则化
2.2 使用随机节点删除——dropout正则化方法
我们来看一下我们的模型:
- L2正则化模式 - 将lambd输入设置为非零值。 我们使用“lambd”而不是“lambda”,因为“lambda”是Python中的保留关键字。
- dropout正则化—随机删除节点 - 将keep_prob设置为小于1的值
def model(X,Y,learning_rate=0.3,num_iterations=,print_cost=True,is_plot=True,lambd=,keep_prob=):
"""
实现一个三层的神经网络:LINEAR ->RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID 参数:
X - 输入的数据,维度为(, 要训练/测试的数量)
Y - 标签,【(蓝色) | (红色)】,维度为(,对应的是输入的数据的标签)
learning_rate - 学习速率
num_iterations - 迭代的次数
print_cost - 是否打印成本值,每迭代10000次打印一次,但是每1000次记录一个成本值
is_polt - 是否绘制梯度下降的曲线图
lambd - 正则化的超参数,实数
keep_prob - 随机删除节点的概率
返回
parameters - 学习后的参数
"""
grads = {}
costs = []
m = X.shape[]
layers_dims = [X.shape[],,,] #初始化参数
parameters = reg_utils.initialize_parameters(layers_dims) #开始学习
for i in range(,num_iterations):
#前向传播
##是否随机删除节点
if keep_prob == :#设置为1的意思就是不使用dropout正则化
###不随机删除节点
a3 , cache = reg_utils.forward_propagation(X,parameters)
elif keep_prob < :
###随机删除节点
a3 , cache = forward_propagation_with_dropout(X,parameters,keep_prob)
else:
print("keep_prob参数错误!程序退出。")
exit #计算成本
## 是否使用二范数,即L2正则化
if lambd == :
###不使用L2正则化
cost = reg_utils.compute_cost(a3,Y)
else:
###使用L2正则化
cost = compute_cost_with_regularization(a3,Y,parameters,lambd) #反向传播
##可以同时使用L2正则化和随机删除节点,但是本次实验不同时使用。
assert(lambd == or keep_prob ==) ##两个参数的使用情况
if (lambd == and keep_prob == ):
### 不使用L2正则化和不使用随机删除节点
grads = reg_utils.backward_propagation(X,Y,cache)
elif lambd != :
### 使用L2正则化,不使用随机删除节点
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < :
### 使用随机删除节点,不使用L2正则化
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob) #更新参数
parameters = reg_utils.update_parameters(parameters, grads, learning_rate) #记录并打印成本
if i % == :
## 记录成本
costs.append(cost)
if (print_cost and i % == ):
#打印成本
print("第" + str(i) + "次迭代,成本值为:" + str(cost)) #是否绘制成本曲线图
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show() #返回学习后的参数
return parameters
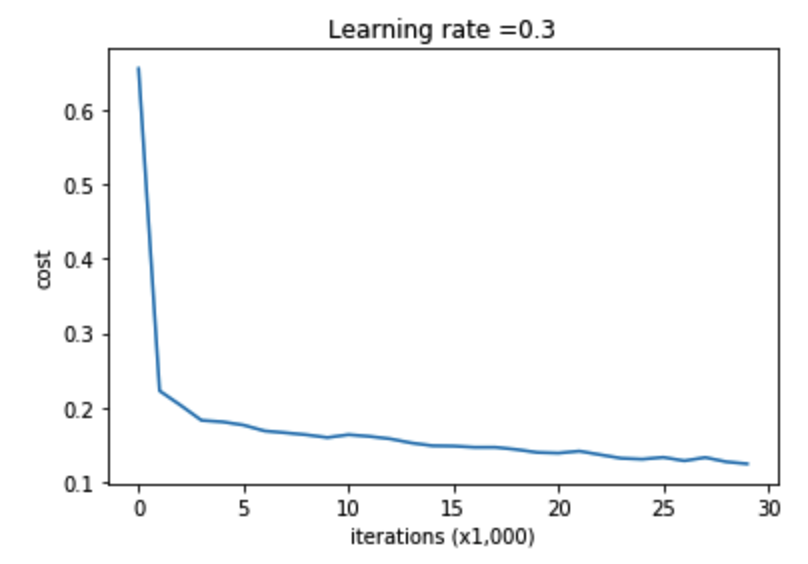
2)不使用正则化
parameters = model(train_X, train_Y,is_plot=True)
print("训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("测试集:")
predictions_test = reg_utils.predict(test_X, test_Y, parameters)
返回:
第0次迭代,成本值为:0.6557412523481002
第10000次迭代,成本值为:0.16329987525724213
第20000次迭代,成本值为:0.1385164242325368 训练集:
Accuracy: 0.9478672985781991
测试集:
Accuracy: 0.915
图示:
将分割曲线画出来:
plt.title("Model without regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
图为:
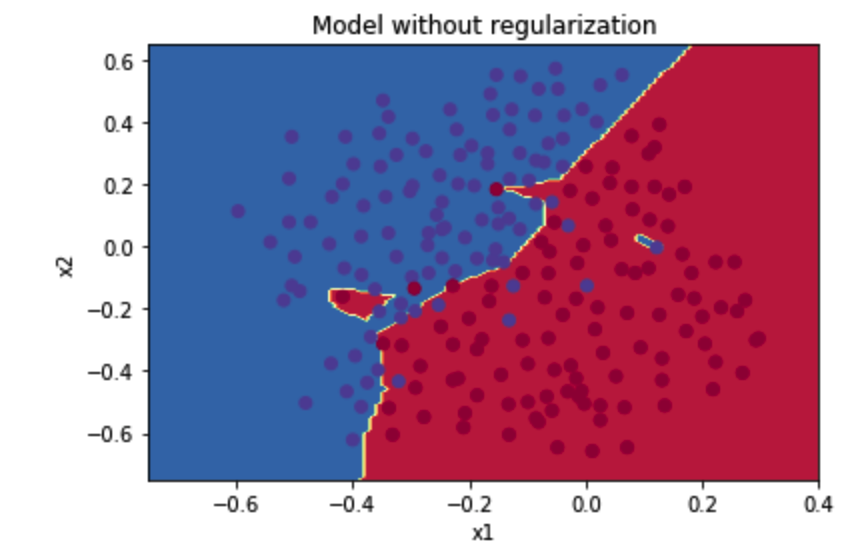
从图中可以看出,在无正则化时,分割曲线有了明显的过拟合特性。接下来,我们使用L2正则化:
3)L2正则化

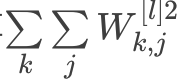 的代码为:
的代码为:
np.sum(np.square(Wl))
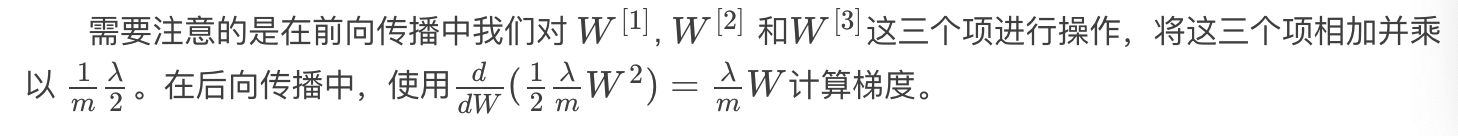
相关函数是:
def compute_cost_with_regularization(A3,Y,parameters,lambd):
"""
实现公式2的L2正则化计算成本 参数:
A3 - 正向传播的输出结果,维度为(输出节点数量,训练/测试的数量)
Y - 标签向量,与数据一一对应,维度为(输出节点数量,训练/测试的数量)
parameters - 包含模型学习后的参数的字典
返回:
cost - 使用公式2计算出来的正则化损失的值 """
m = Y.shape[]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"] cross_entropy_cost = reg_utils.compute_cost(A3,Y) L2_regularization_cost = lambd * (np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3))) / ( * m) cost = cross_entropy_cost + L2_regularization_cost return cost #当然,因为改变了成本函数,我们也必须改变向后传播的函数, 所有的梯度都必须根据这个新的成本值来计算。 def backward_propagation_with_regularization(X, Y, cache, lambd):
"""
实现我们添加了L2正则化的模型的后向传播。 参数:
X - 输入数据集,维度为(输入节点数量,数据集里面的数量)
Y - 标签,维度为(输出节点数量,数据集里面的数量)
cache - 来自forward_propagation()的cache输出
lambda - regularization超参数,实数 返回:
gradients - 一个包含了每个参数、激活值和预激活值变量的梯度的字典
""" m = X.shape[] (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache dZ3 = A3 - Y dW3 = ( / m) * np.dot(dZ3,A2.T) + ((lambd * W3) / m )
db3 = ( / m) * np.sum(dZ3,axis=,keepdims=True) dA2 = np.dot(W3.T,dZ3)
dZ2 = np.multiply(dA2,np.int64(A2 > ))
dW2 = ( / m) * np.dot(dZ2,A1.T) + ((lambd * W2) / m)
db2 = ( / m) * np.sum(dZ2,axis=,keepdims=True) dA1 = np.dot(W2.T,dZ2)
dZ1 = np.multiply(dA1,np.int64(A1 > ))
dW1 = ( / m) * np.dot(dZ1,X.T) + ((lambd * W1) / m)
db1 = ( / m) * np.sum(dZ1,axis=,keepdims=True) gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3, "dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1} return gradients
运行:
parameters = model(train_X, train_Y, lambd=0.7,is_plot=True)
print("使用正则化,训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("使用正则化,测试集:")
predictions_test = reg_utils.predict(test_X, test_Y, parameters)
返回:
第0次迭代,成本值为:0.6974484493131264
第10000次迭代,成本值为:0.2684918873282239
第20000次迭代,成本值为:0.26809163371273004 使用正则化,训练集:
Accuracy: 0.9383886255924171
使用正则化,测试集:
Accuracy: 0.93
图示:

查看下分类的结果:
plt.title("Model with L2-regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
返回图示:

λ的值(即lambd)是可以使用开发集调整时的超参数。L2正则化会使决策边界更加平滑。如果λ太大,也可能会“过度平滑”(即变成了线性),从而导致模型高偏差。
L2正则化实际上在做什么?L2正则化依赖于“较小权重的模型比具有较大权重的模型更简单”这样的假设,因此,通过削减成本函数中权重的平方值,可以将所有权重值逐渐改变到到较小的值。
权值λ数值高的话会有更平滑的模型,其中输入变化时输出变化更慢,但是你需要花费更多的时间。
L2正则化对以下内容有影响:
- 成本计算 : 正则化的计算需要添加到成本函数中
- 反向传播功能 :在权重矩阵方面,梯度计算时也要依据正则化来做出相应的计算
4)dropout正则化——随机删除节点
Dropout的原理就是每次迭代过程中随机将其中的一些节点失效

上面步骤的实现简单展示:
import numpy as np
np.random.seed()
A1 = np.random.randn(,) #为了使用其.shape来设置D1 D1 = np.random.rand(A1.shape[],A1.shape[])
print(D1)
keep_prob=0.5
D1 = D1 < keep_prob
print(D1) A1 = 0.01 #python的广播原理,会将其扩展为D1的格式
print(A1)
A1 = A1 * D1 #相乘时true会转成1,false会传成0
A1 = A1 / keep_prob
print(A1)
返回:
[[ 1.62434536 -0.61175641 -0.52817175]]
[[0.39676747 0.53881673 0.41919451]]
[[ True False True]]
0.01
[[0.02 . 0.02]]
此时前向传播变为:
def forward_propagation_with_dropout(X,parameters,keep_prob=0.5):
"""
实现具有随机舍弃节点的前向传播。
LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID. 参数:
X - 输入数据集,维度为(,示例数)
parameters - 包含参数“W1”,“b1”,“W2”,“b2”,“W3”,“b3”的python字典:
W1 - 权重矩阵,维度为(,)
b1 - 偏向量,维度为(,)
W2 - 权重矩阵,维度为(,)
b2 - 偏向量,维度为(,)
W3 - 权重矩阵,维度为(,)
b3 - 偏向量,维度为(,)
keep_prob - 随机删除的概率,实数
返回:
A3 - 最后的激活值,维度为(,),正向传播的输出
cache - 存储了一些用于计算反向传播的数值的元组
"""
np.random.seed() W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"] #LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1,X) + b1
A1 = reg_utils.relu(Z1) #下面的步骤1-4对应于上述的步骤1-。
D1 = np.random.rand(A1.shape[],A1.shape[]) #步骤1:初始化矩阵D1 = np.random.rand(..., ...)
D1 = D1 < keep_prob #步骤2:将D1的值转换为0或1(使用keep_prob作为阈值)
A1 = A1 * D1 #步骤3:舍弃A1的一些节点(将它的值变为0或False)
A1 = A1 / keep_prob #步骤4:缩放未舍弃的节点(不为0)的值 Z2 = np.dot(W2,A1) + b2
A2 = reg_utils.relu(Z2) #下面的步骤1-4对应于上述的步骤1-。
D2 = np.random.rand(A2.shape[],A2.shape[]) #步骤1:初始化矩阵D2 = np.random.rand(..., ...)
D2 = D2 < keep_prob #步骤2:将D2的值转换为0或1(使用keep_prob作为阈值)
A2 = A2 * D2 #步骤3:舍弃A1的一些节点(将它的值变为0或False)
A2 = A2 / keep_prob #步骤4:缩放未舍弃的节点(不为0)的值 Z3 = np.dot(W3, A2) + b3
A3 = reg_utils.sigmoid(Z3) cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) return A3, cache
其实就是对Ai的值进行更改后再进行前向传播
后向传播变为:使用存储在缓存中的掩码D[1] 和 D[2]将舍弃的节点位置信息添加到第一个和第二个隐藏层,即求出来的梯度也舍弃前向中舍弃的点
def backward_propagation_with_dropout(X,Y,cache,keep_prob):
"""
实现我们随机删除的模型的后向传播。
参数:
X - 输入数据集,维度为(,示例数)
Y - 标签,维度为(输出节点数量,示例数量)
cache - 来自forward_propagation_with_dropout()的cache输出
keep_prob - 随机删除的概率,实数 返回:
gradients - 一个关于每个参数、激活值和预激活变量的梯度值的字典
"""
m = X.shape[]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache dZ3 = A3 - Y
dW3 = ( / m) * np.dot(dZ3,A2.T)
db3 = . / m * np.sum(dZ3, axis=, keepdims=True)
dA2 = np.dot(W3.T, dZ3) dA2 = dA2 * D2 # 步骤1:使用正向传播期间相同的节点,舍弃那些关闭的节点(因为任何数乘以0或者False都为0或者False)
dA2 = dA2 / keep_prob # 步骤2:缩放未舍弃的节点(不为0)的值 dZ2 = np.multiply(dA2, np.int64(A2 > ))
dW2 = . / m * np.dot(dZ2, A1.T)
db2 = . / m * np.sum(dZ2, axis=, keepdims=True) dA1 = np.dot(W2.T, dZ2) dA1 = dA1 * D1 # 步骤1:使用正向传播期间相同的节点,舍弃那些关闭的节点(因为任何数乘以0或者False都为0或者False)
dA1 = dA1 / keep_prob # 步骤2:缩放未舍弃的节点(不为0)的值 dZ1 = np.multiply(dA1, np.int64(A1 > ))
dW1 = . / m * np.dot(dZ1, X.T)
db1 = . / m * np.sum(dZ1, axis=, keepdims=True) gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1} return gradients
我们前向和后向传播的函数都写好了,现在用dropout运行模型(keep_prob = 0.86)跑一波。这意味着在每次迭代中,程序都可以24%的概率关闭第1层和第2层的每个神经元
parameters = model(train_X, train_Y, keep_prob=0.86, learning_rate=0.3,is_plot=True)
print("使用随机删除节点,训练集:")
predictions_train = reg_utils.predict(train_X, train_Y, parameters)
print("使用随机删除节点,测试集:")
reg_utils.predictions_test = reg_utils.predict(test_X, test_Y, parameters)
警告:
/Users/user/pytorch/jupyter/-week1/reg_utils.py:: RuntimeWarning: divide by zero encountered in log
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log( - a3), - Y)
/Users/user/pytorch/jupyter/-week1/reg_utils.py:: RuntimeWarning: invalid value encountered in multiply
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log( - a3), - Y)
返回:
第0次迭代,成本值为:0.6543912405149825
第10000次迭代,成本值为:0.061016986574905605
第20000次迭代,成本值为:0.060582435798513114 使用随机删除节点,训练集:
Accuracy: 0.9289099526066351
使用随机删除节点,测试集:
Accuracy: 0.95
图示:

查看分类情况:
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75, 0.40])
axes.set_ylim([-0.75, 0.65])
plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
图示:
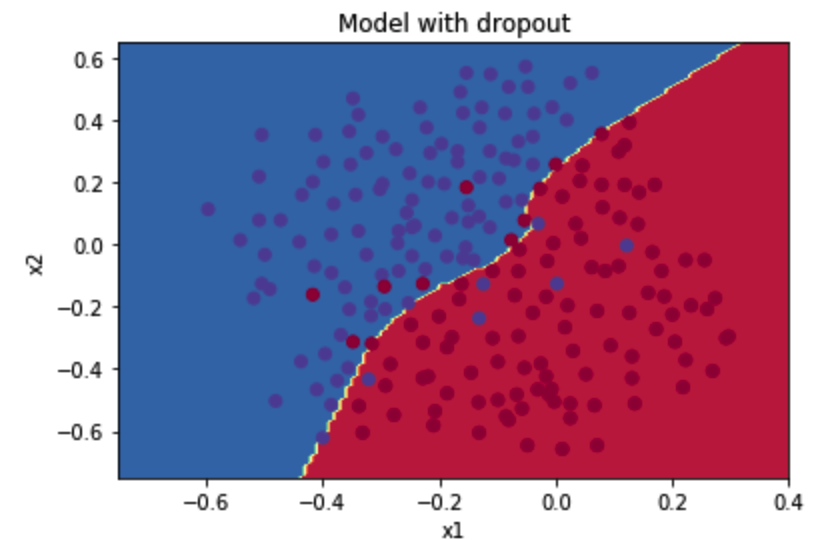
我们可以看到,正则化会把训练集的准确度降低,但是测试集的准确度提高了,所以,我们这个还是成功了。
接下来进行梯度校验,可见吴恩达课后作业学习2-week1-3梯度校验—不发布
吴恩达课后作业学习2-week1-2正则化的更多相关文章
- 吴恩达课后作业学习2-week1-1 初始化
参考:https://blog.csdn.net/u013733326/article/details/79847918 希望大家直接到上面的网址去查看代码,下面是本人的笔记 初始化.正则化.梯度校验 ...
- 吴恩达课后作业学习1-week4-homework-two-hidden-layer -1
参考:https://blog.csdn.net/u013733326/article/details/79767169 希望大家直接到上面的网址去查看代码,下面是本人的笔记 两层神经网络,和吴恩达课 ...
- 吴恩达课后作业学习1-week4-homework-multi-hidden-layer -2
参考:https://blog.csdn.net/u013733326/article/details/79767169 希望大家直接到上面的网址去查看代码,下面是本人的笔记 实现多层神经网络 1.准 ...
- 吴恩达课后作业学习1-week2-homework-logistic
参考:https://blog.csdn.net/u013733326/article/details/79639509 希望大家直接到上面的网址去查看代码,下面是本人的笔记 搭建一个能够 “识别猫” ...
- 吴恩达课后作业学习1-week3-homework-one-hidden-layer
参考:https://blog.csdn.net/u013733326/article/details/79702148 希望大家直接到上面的网址去查看代码,下面是本人的笔记 建立一个带有隐藏层的神经 ...
- 吴恩达课后作业学习2-week3-tensorflow learning-1-基本概念
参考:https://blog.csdn.net/u013733326/article/details/79971488 希望大家直接到上面的网址去查看代码,下面是本人的笔记 到目前为止,我们一直在 ...
- 吴恩达课后作业学习2-week2-优化算法
参考:https://blog.csdn.net/u013733326/article/details/79907419 希望大家直接到上面的网址去查看代码,下面是本人的笔记 我们需要做以下几件事: ...
- 吴恩达课后作业学习2-week3-tensorflow learning-1-例子学习
参考:https://blog.csdn.net/u013733326/article/details/79971488 使用TensorFlow构建你的第一个神经网络 我们将会使用TensorFlo ...
- 吴恩达课后作业学习2-week1-3梯度校验
参考:https://blog.csdn.net/u013733326/article/details/79847918 希望大家直接到上面的网址去查看代码,下面是本人的笔记 5.梯度校验 在我们执行 ...
随机推荐
- 06-HTML-表格标签
<html> <head> <title>表格标签学习</title> <meta charset="utf-8"/> ...
- es6 语法 (函数扩展)
//函数参数默认值(more值后不能有参数) { function test(x,y = 'world'){ console.log('默认值',x,y); } test('hello');// he ...
- java 返回某一天的周日和现在这一周的周日
import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Calendar;import j ...
- LRU(最近最少使用淘汰算法)基本实现
LRU(Least Recently Used) 出发点:在页式存储管理中,如果一页很长时间未被访问,则它在最近一段时间内也不会被访问,即时间局部性,那我们就把它调出(置换出)内存. 为了实现LRU ...
- c++趣味之变量名,颠覆所有教科书的VisualStudio
GCC不参与这次的趣味. 所有的教程都会告诉你,c++的变量名,类名,函数名都应该是字母或下划线开头的字母.数字.下划线组合,像这样: int _abc123; 实际上,VisualStudio并不遵 ...
- [Python][小知识][NO.1] Python字符串前 加 u、r、b 的含义
1.字符串前加 u 例:u"我是含有中文字符组成的字符串." 作用:后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出 ...
- canvas代替imgage,可以有效的提高大图片加载的速度!
//加载zepto插件 <script> //定义图片的数量 var total = 17; //获取屏幕的宽度 var zWin = $(window); //定义渲染图片的方法 var ...
- [译]在Linux上的提高MySQL/MariaDB安全性的12条建议
MySQL 是世界上最流行的开源数据库系统,而MariaDB(MySQL的一个分支)是世界上发展最快的开源数据库系统.安装MySQL服务器之后,它的默认配置是不安全的,保护它是一般数据库管理中的基本任 ...
- apk公钥私钥用法
每个密钥都包含两个文件:一个是扩展名为 .x509.pem 的证书,另一个是扩展名为 .pk8 的私钥.私钥需要加以保密,并用于对 apk 包进行签名.密钥本身也可能受密码保护.相比之下,证书只包含公 ...
- pycharm 中按照文档引包方式,引包错误
* python使用pycharm ide,如果电脑上有多个解释器的,在项目解释器配置的应该是当前使用的解释器: * 可以把当前使用的解释器目录添加到系统环境变量中,这样就不会报错了 另外,如果目录中 ...