Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase
2数据模型基本概念:
表:habse是一个稀疏、多维、持久化存储的映射表,采用行健RowKey、列族Column Family、列限定符、时间戳进行索引,每个值都是一个未经解释的字节数组。
Region:Hbase会将一个大表的数据基于Rowkey的不同范围分配到不通的Region中,每个Region负责一定范围的数据访问和存储。这样即使是一张巨大的表,由于被切割到不通的region,访问起来的时延也很低。
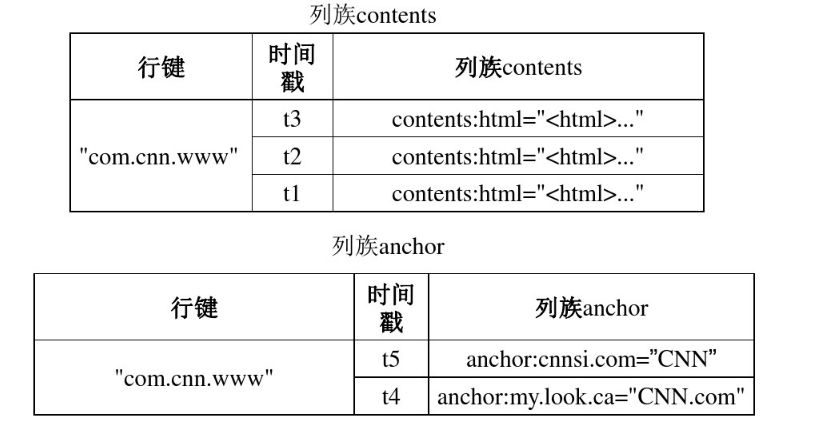
Column Family:列族,Hbase通过列族划分数据的存储,列族下面可以包含任意多的列。Hbase表的创建的时候就必须指定列族。Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。存储在一个列族的数据通常具有相同的数据类型
Rowkey:Rowkey的概念和mysql中的主键是完全一样的,Hbase使用Rowkey来唯一的区分某一行的数据。
由于Hbase只支持3中查询方式:
基于Rowkey的单行查询、基于Rowkey的范围扫描、全表扫描
TimeStamp:时间戳,在写入数据的时候,如果用户没有指定对应的timestamp,Hbase会自动添加一个timestamp,timestamp和服务器时间保持一致。在Hbase中,相同rowkey的数据按照timestamp倒序排列。默认查询的是最新的版本,用户可同指定timestamp的值来读取旧版本的数据。
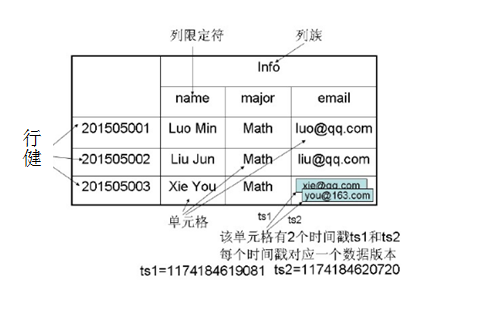
概念视图:
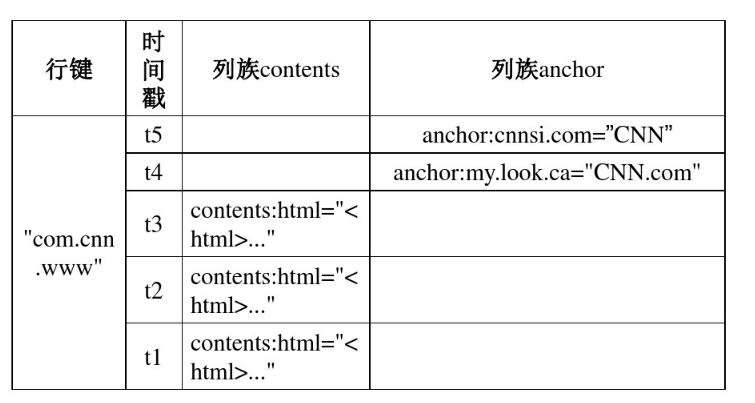
物理视图
3HBse实现原理
3.1功能组件:
a:一个master服务器:1、负载均衡,管理和分配HRegion;2、DDL增删改;3、管理维护HBase表的分区信息;4、ACL权限控制;
b:许多Region服务器 :1、存储维护分配给自己的Region;2、处理客户端的读写请求;3、本地化:HResion的数据尽量和数据所属的datanode在一块,但是这个本地化不能够总是满足。(合并)
c:库函数
3.2表和Region:
在一个HBase中,存储了许多的表。对于每个HBase表而言,表会根据行健的值最表进行分区,每个行区间构成一个分区,称为Region。初始时,每个表只包含一个Region,但是随着数据的不断插入,Region会持续变大,当一个Region中的行数量达到某一个阈值时,就会自动分裂为2个新的region。
每个Region的默认大小是100M到200M,是HBase中负载均衡的和数据分发的基本单位。每台Region server一般会放置10~1000个Region。
3.3Region定位:
标识:每个Region都有一个Region标识符:“表名+开始主键+RegionID”
位置定位:
7.HBase运行机制
7.1HBase系统架构
1、客户端:缓存已经访问过的Region位置信息,加速数据的访问
2、zookeeper服务器:可能是1台机器,也可能是一个zookeeper集群(实际中只有一台在起作用)。master是Hbase集群中的总管,负责管理Region服务器。每个Region服务器都需要在Zookeeper中注册,并且zookeeper服务器可以实时感知Region服务器的状态,实时传送给Master。habse可以启用多个master,zookeeper可以帮助选举出一个master作为集群的主管,并保证在任何时刻总有一个唯一一个master在运行,避免了master的单点失效问题。客户端访问HBase的数据需要通过zookeeper获得表地址。
3、master:1、DDL,管理用户对表的增删改查;2、负载均衡;3、Region分裂后,重新调整Region分布;4、对发生故障失效的Region服务器上的Region进行迁移。
4、Region服务器:维护分给自己的Region,响应用户的读写请求。
7.2Region服务器工作原理:
Region服务器维护了一个了一个Hlog文件和一系列的Region对象,
7.3Store工作原理:
7.4HLog工作原理:
三、实践:
1、hbase shell
常用命令
进入hbase自带的shell命令行界面:
#hbase shell
#查看状态:status,一共3个server
hbase(main)::> status active master, backup masters, servers, dead, 19.3333 average load
#创建一张表create 'm_table',声明2个列族'meta_data'、'ation'
hbase(main)::> create 'm_table','meta_data','action'
#查看表结构信息desc,发现一共2个列族
hbase(main)::>desc 'm_table'
#删除某个列族:alter
hbase(main)::>alter 'm_table' {NAME => 'action', METHOD => 'delete'}
#删除表:先disable禁用表然后drop删除表<=====>使表生效enable
hbase(main)::>disable 'm_table' hbase(main)::>drop 'm_table'
#查看当前有什么表list hbase(main)::>list 'm_table'
#查看某表是否存在exists hbase(main)::>exists 'm_table'
#重新创建一个新表create
hbase(main)::>create 'm_table','meta_data','action‘
#写入数据put
hbase(main)::>put 'm_table','','meta_data:name','zhangshan'
#读取数据
hbase(main)::>get 'm_table',''
#扫描表(不要轻易使用)
hbase(main)::>scan 'm_table'
#扫描表的前条数
hbase(main)::>scan 'm_table',{LIMIT => }
#清空表(先把表删除,再新建表)
hbase(main)::>truncate 'm_table'
#合并region(region的id是页面的最后一位)
hbase(main)::>merge_region 'id1xxxxx','id2xxxx', true
#清空缓存(删除的时候会等一会文件才消失)
hbase(main)::>flush
#分裂Region
hbase(main)::>split 'idx'
2.python对hbase的读写:
准备工作:
启动 ThriftServer 于 HBASE hbase-deamn.sh start thrift/thrift2
在此,HBASE提供两种 thrift/thrift2 由于种种原因,语法并不兼容,其中 2 的语法封装更优雅,但部分 DDL 操作不完善,而且 thrift API 资料相对多一些,所以先使用thrift 尝试
jps 应该有 ThriftServer 进程
2.1安装thrift:
#yum install automake libtool flex bison pkgconfig gcc-c++ boost-devel libevent-devel zlib-devel python-devel ruby-devel openssl-devel
#yum install boost-devel.x86_64
#yum install libevent-devel.x86_64
#tar xzf thrift-0.8.0.tar.gz
#cd thrift-0.8.0
#./configure --with-cpp=no --with-ruby=no
#make
#make install
2.2生成针对Python的Hbase的API
#获取源码
#wget http://mirros.hust.edu.cn/apache/hbase/0.98.24/hbase-0.98.24.tar.gz
#找到Hbase.thrift
#find . -name Hbase.thrift
./hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift/Hbase.thrift
#cd ./hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift #thrift -gen py Hbase.thrift
#生成一个py模块hbase拷贝到自己的目录待用
#cp -raf gen-py/habse /home/dip/test
拷贝thrift模块拷贝到自己的目录待用
#cp -r thrift-0.8.0/lib/py/build/lib.linux-x86_64-2.6/thrift /home/dip/test
2.3启动Thrift服务:
hbase-daemon.sh start thrift
#查看到9090端口启动
2.4python创建表
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol from habse import Hbase
from habse.ttypes import *
transport = TSocket.TSocket('master', '')
transport = TTransport.TBufferedTransport(transport)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.client(protocol) transport.open() #########**************************** base_info_contents = ColumnDescriptor(name='meta_data:',maxVersions=1) other_info_contents = ColumnDescriptor(name='flags:',maxVersions=1) client.createTable('new_music_table',[base_info_contents,other_info_contents]) print client.getTableNames()
2.5python对Hbase插入数据
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol from hbase import Hbase from hbase.ttypes import * transport = TSocket.TSocket('master',9090)
transport = TTransport.TBufferedTransport(transport) protocol = TBinaryProtocol.TBinaryProtocol(transport) client = Hbase.Client(protocol)
transport.open()
#********************
tablename = 'new_music_table'
rowkey = '1200'
mutations = [Mutation(cloumn = "meta_data:name", value="wangqingshui"),\
Mutation(column = "meta_data:tag", value="pop")\
Mutation(column = "flags:is_valid",value="true")]
client.mutateRow(tablename,rowkey,mutations,None)
2.6python读取Hbase数据(读取1行;读取多行)
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol from hbase import Hbase from hbase.ttypes import * transport = TSocket.TSocket('master',9090)
transport = TTransport.TBufferedTransport(transport) protocol = TBinaryProtocol.TBinaryProtocol(transport) client = Hbase.Client(protocol)
transport.open()
tableName = 'new_music_table'
rowkey = '' for r in result:
print "the row is ",r.row
print "the name is ",r.columns.get('meta_data:name').value
print "the flag is ",r.columns.get('flags:is_valid').value
2.7python读取多行数据,类似于can
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol from hbase import Hbase from hbase.ttypes import * transport = TSocket.TSocket('master',9090)
transport = TTransport.TBufferedTransport(transport) protocol = TBinaryProtocol.TBinaryProtocol(transport) client = Hbase.Client(protocol) transport.open()
tableName = 'new_music_table'
scan = TScan()
id = client.scannerOpenWithScan(tableName,scan,None)
result = client.scannerGetList(id,10)
for r in result:
print "-----"
print "the row is" , r.row
for k,v in r.columns.items():
print "\t".join([k,v,values])
Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase的更多相关文章
- Hbase快速开始——shell操作
一. 介绍 HBase是一个分布式的.面向列的开源数据库,源于google的一篇论文<bigtable:一个结构化数据的分布式存储系统>.HBase是Google Bigtable的开源实 ...
- HBase学习之路 (三)HBase集群Shell操作
进入HBase命令行 在你安装的随意台服务器节点上,执行命令:hbase shell,会进入到你的 hbase shell 客 户端 [hadoop@hadoop1 ~]$ hbase shell S ...
- Hbase(二)【shell操作】
目录 一.基础操作 1.进入shell命令行 2.帮助查看命令 二.命名空间操作 1.创建namespace 2.查看namespace 3.删除命名空间 三.表操作 1.查看所有表 2.创建表 3. ...
- hbase学习一 shell命令操作
基本操作: #命名空间级别: #列出所有命名空间 hbase> list_namespace #新建命名空间 hbase> create_namespace 'ns1' #删除命名空间 h ...
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
- 海量列式非关系数据库HBase 架构,shell与API
HBase的特点: 海量存储: 底层基于HDFS存储海量数据 列式存储:HBase表的数据是基于列族进行存储的,一个列族包含若干列 极易扩展:底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加Da ...
- HBase总结(二十)HBase经常使用shell命令具体说明
进入hbase shell console $HBASE_HOME/bin/hbase shell 假设有kerberos认证,须要事先使用对应的keytab进行一下认证(使用kinit命令),认证成 ...
- Mapreduce操作HBase
这个操作和普通的Mapreduce还不太一样,比如普通的Mapreduce输入可以是txt文件等,Mapreduce可以直接读取Hive中的表的数据(能够看见是以类似txt文件形式),但Mapredu ...
- hbase使用MapReduce操作2(微博表实现)
package com.yjsj.weibo; import java.io.IOException; import java.util.ArrayList; import java.util.Ite ...
随机推荐
- C++使用libcurl
1.下载地址https://curl.haxx.se/download.html 2.选择zip压缩包下载 3.选择合适自己的vc版本 4.启动项目选择libcurl 5.因为暂时不需要ssh2,预处 ...
- 【bzoj 4764】弹飞大爷
Description 自从WC退役以来,大爷是越来越懒惰了.为了帮助他活动筋骨,也是受到了弹飞绵羊一题的启发,机房的小伙伴们决定齐心合力构造一个下面这样的序列.这个序列共有N项,每项都代表了一个小伙 ...
- arcgis中的geodatabase模型
简介Geodatabase是ESRI公司定义的一个为ArcGIS所用的数据框架,该框架定义了ArcGIS中用到的所有的数据类型.不管ArcGIS的数据存储到何处.以什么格式存储,都脱离不了该框架.也可 ...
- Python的参数类型
参数类型: 1.必填参数,位置参数(positional arguments,官方定义,就是其他语言所说的参数) 2.默认值参数,非必传 3.可变参数,非必传,不限制参数个数,比如说给多个人发邮件,发 ...
- 对Tomcat部署web应用的方式总结
对Tomcat部署web应用的方式总结,常见的有以下四种: 1.[使用控制台部署] 访问Http://localhost:8080,并通过Tomcat Manager登录,进入部署界面即可. 2.[利 ...
- 读书笔记 Facebook在移动端都干了啥,居然让用户爱上广告
文章来源:http://news.cnblogs.com/n/513297/ Facebook武器: Facebook 的武器只有一个:让广告主基于目标用户群投放个性化的精准广告.基于高质量的广告内容 ...
- ListBox、ListCtrl
设置编辑框滚动条在最新的位置 //CEdit* editBox=(CEdit*)GetDlgItem(IDC_EDIT_RECV); //(editBox->LineScroll(editBox ...
- 推荐前端框架 & 模板
BootStrap Semantic UI Pure Amazeui(前后端都有,很丰富) amazeui http://tpl.amazeui.org AdminLTE AdminLTE https ...
- tomcat BIO / NIO
BIO NIO ref https://www.jianshu.com/p/76ff17bc6dea http://gearever.iteye.com/blog/1841586
- Microsoft SQL - 学习总目录
Microsoft SQL - 数据库管理系统 Microsoft SQL - 数据类型 Microsoft SQL - 查询与更新 Microsoft SQL - 操作语句 Microsoft SQ ...