week07 codelab02 C72
ss


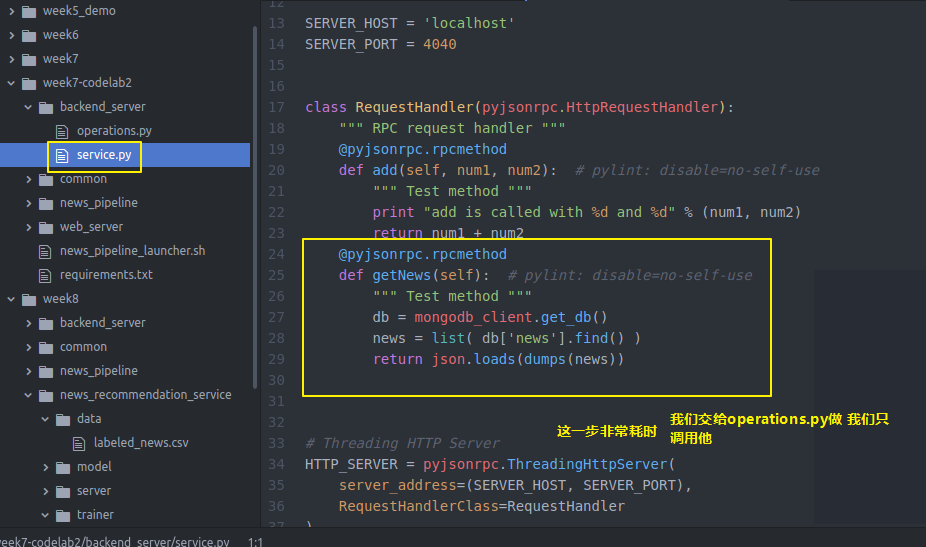
我们要改一下backendserver的service
因为要写几个api还要做很多操作
我们单独写出来 然后由service来调用

import json
import os
import pickle
import random
import redis
import sys from bson.json_util import dumps
from datetime import datetime # import common package in parent directory
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common')) import mongodb_client REDIS_HOST = "localhost"
REDIS_PORT = # NEWS_TABLE_NAME = "news"
NEWS_TABLE_NAME = "news-test"
CLICK_LOGS_TABLE_NAME = 'click_logs' NEWS_LIMIT =
NEWS_LIST_BATCH_SIZE =
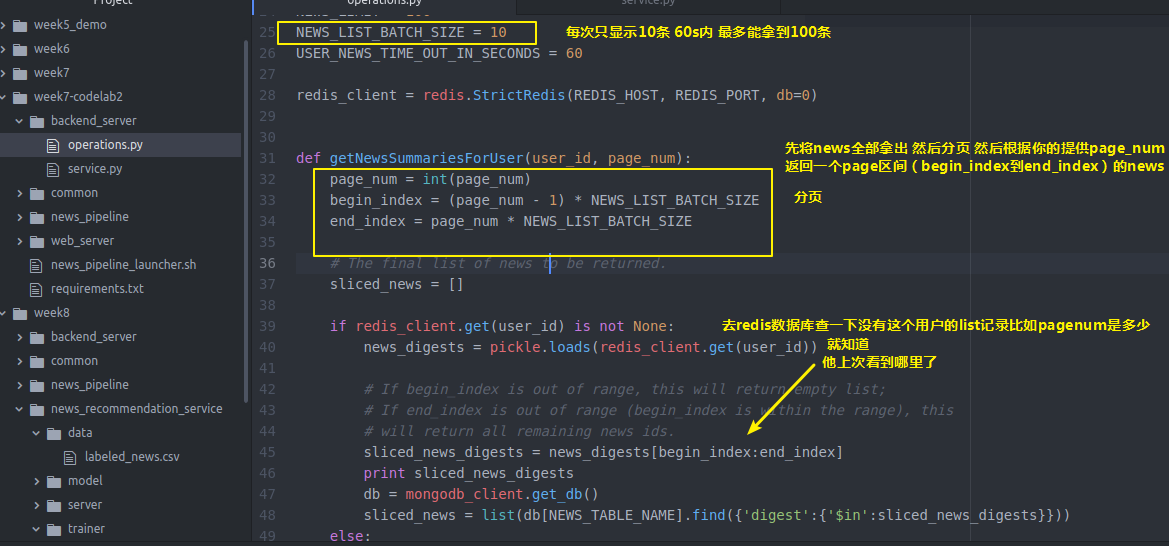
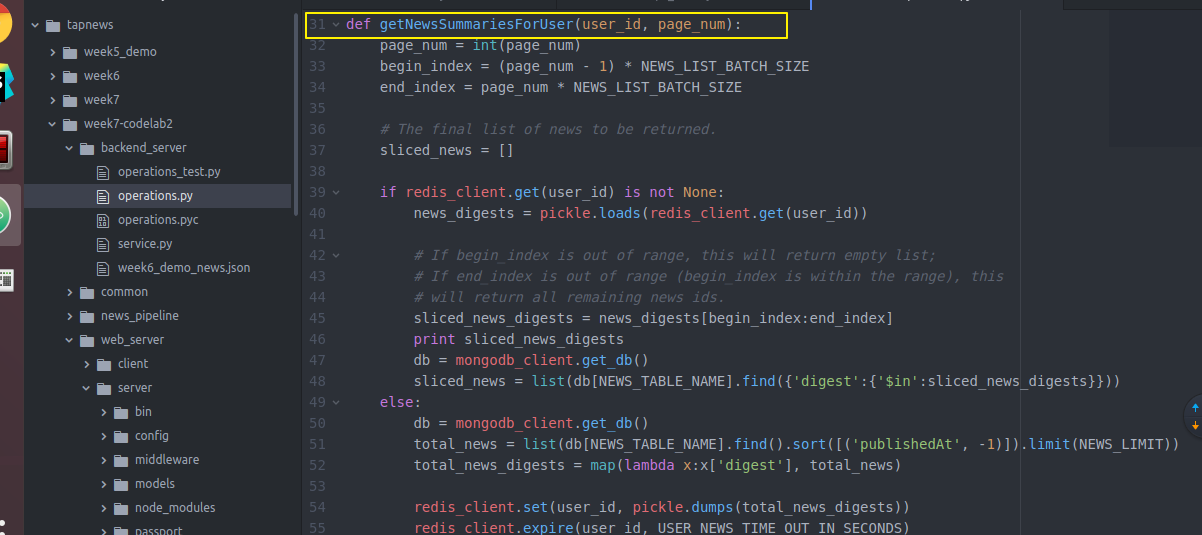
USER_NEWS_TIME_OUT_IN_SECONDS = redis_client = redis.StrictRedis(REDIS_HOST, REDIS_PORT, db=) def getNewsSummariesForUser(user_id, page_num):
page_num = int(page_num)
begin_index = (page_num - ) * NEWS_LIST_BATCH_SIZE
end_index = page_num * NEWS_LIST_BATCH_SIZE # The final list of news to be returned.
sliced_news = [] if redis_client.get(user_id) is not None:
news_digests = pickle.loads(redis_client.get(user_id)) # If begin_index is out of range, this will return empty list;
# If end_index is out of range (begin_index is within the range), this
# will return all remaining news ids.
sliced_news_digests = news_digests[begin_index:end_index]
print sliced_news_digests
db = mongodb_client.get_db()
sliced_news = list(db[NEWS_TABLE_NAME].find({'digest':{'$in':sliced_news_digests}}))
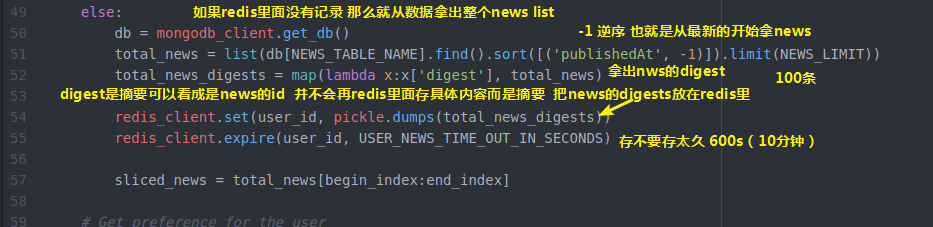
else:
db = mongodb_client.get_db()
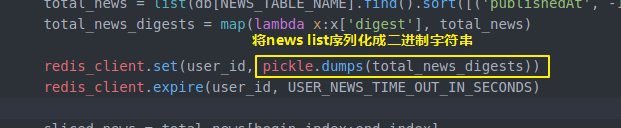
total_news = list(db[NEWS_TABLE_NAME].find().sort([('publishedAt', -)]).limit(NEWS_LIMIT))
total_news_digests = map(lambda x:x['digest'], total_news) redis_client.set(user_id, pickle.dumps(total_news_digests))
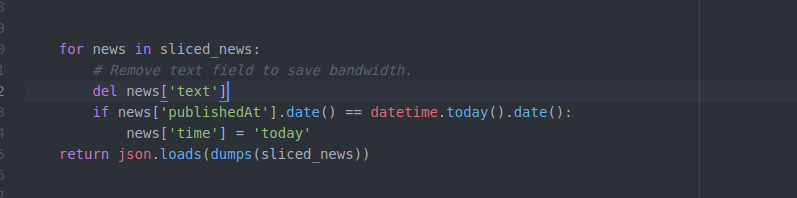
redis_client.expire(user_id, USER_NEWS_TIME_OUT_IN_SECONDS) sliced_news = total_news[begin_index:end_index] for news in sliced_news:
# Remove text field to save bandwidth.
del news['text']
if news['publishedAt'].date() == datetime.today().date():
news['time'] = 'today'
return json.loads(dumps(sliced_news))
operations.py

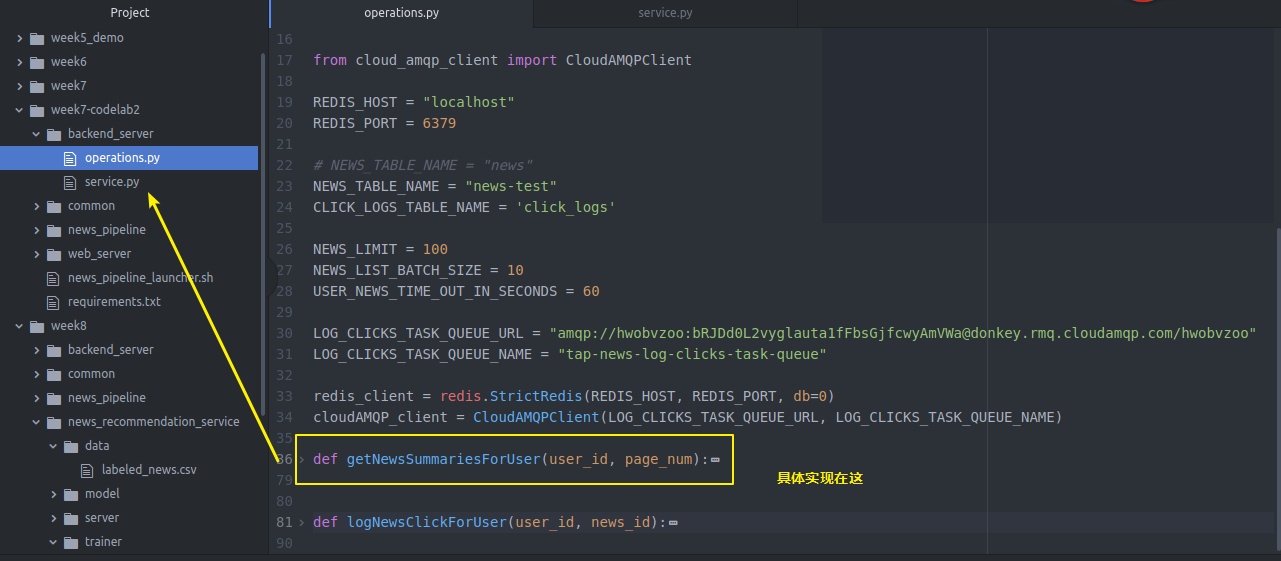
具体实现
可以自己设置这个过期时间

我们都是下拉获得新闻 你也可以设计一个向上拉强制刷新的功能 比如向上拉触发一个函数cleanRedis来强制清空redis(类似新浪知乎)这样 即使100条获取完了没得获取了
也能强制刷新列表(之后写吧)
import json
import os
import pickle
import random
import redis
import sys from bson.json_util import dumps
from datetime import datetime # import common package in parent directory
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common')) import mongodb_client REDIS_HOST = "localhost"
REDIS_PORT = # NEWS_TABLE_NAME = "news"
NEWS_TABLE_NAME = "news-test"
CLICK_LOGS_TABLE_NAME = 'click_logs' NEWS_LIMIT =
NEWS_LIST_BATCH_SIZE =
USER_NEWS_TIME_OUT_IN_SECONDS = redis_client = redis.StrictRedis(REDIS_HOST, REDIS_PORT, db=) def getNewsSummariesForUser(user_id, page_num):
page_num = int(page_num)
begin_index = (page_num - ) * NEWS_LIST_BATCH_SIZE
end_index = page_num * NEWS_LIST_BATCH_SIZE # The final list of news to be returned.
sliced_news = [] if redis_client.get(user_id) is not None:
news_digests = pickle.loads(redis_client.get(user_id)) # If begin_index is out of range, this will return empty list;
# If end_index is out of range (begin_index is within the range), this
# will return all remaining news ids.
sliced_news_digests = news_digests[begin_index:end_index]
print sliced_news_digests
db = mongodb_client.get_db()
sliced_news = list(db[NEWS_TABLE_NAME].find({'digest':{'$in':sliced_news_digests}}))
else:
db = mongodb_client.get_db()
total_news = list(db[NEWS_TABLE_NAME].find().sort([('publishedAt', -)]).limit(NEWS_LIMIT))
total_news_digests = map(lambda x:x['digest'], total_news) redis_client.set(user_id, pickle.dumps(total_news_digests))
redis_client.expire(user_id, USER_NEWS_TIME_OUT_IN_SECONDS) sliced_news = total_news[begin_index:end_index] for news in sliced_news:
# Remove text field to save bandwidth.
del news['text']
if news['publishedAt'].date() == datetime.today().date():
news['time'] = 'today'
return json.loads(dumps(sliced_news))
operations.py
上面代码提到的比如 lamda表达式配合map摘取新闻中的digest字段

还有pickle对字符串序列化和反序列化

配合使用
我们写个test

import operations
import os
import sys from sets import Set # import common package in parent directory
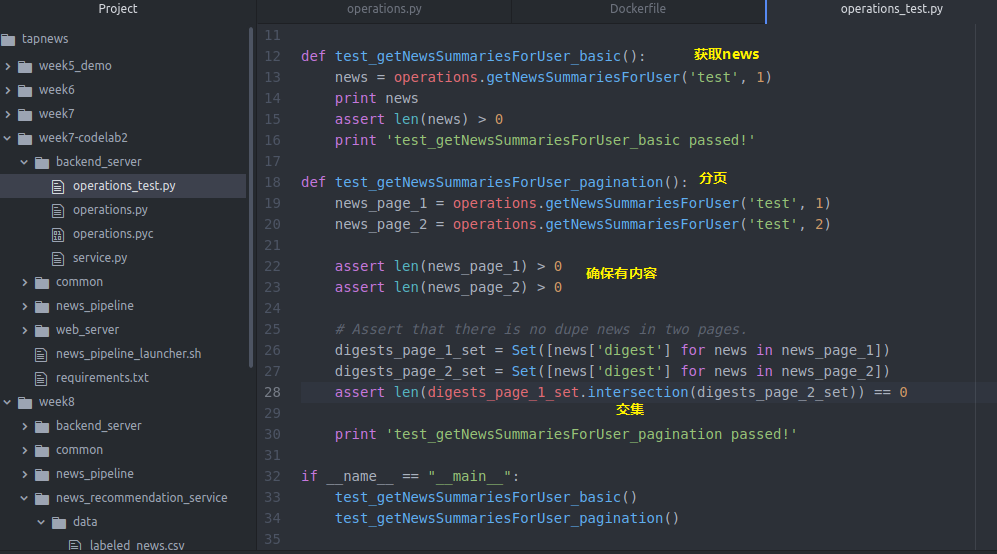
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common')) # Start Redis and MongoDB before running following tests. def test_getNewsSummariesForUser_basic():
news = operations.getNewsSummariesForUser('test', )
print news
assert len(news) >
print 'test_getNewsSummariesForUser_basic passed!' def test_getNewsSummariesForUser_pagination():
news_page_1 = operations.getNewsSummariesForUser('test', )
news_page_2 = operations.getNewsSummariesForUser('test', ) assert len(news_page_1) >
assert len(news_page_2) > # Assert that there is no dupe news in two pages.
digests_page_1_set = Set([news['digest'] for news in news_page_1])
digests_page_2_set = Set([news['digest'] for news in news_page_2])
assert len(digests_page_1_set.intersection(digests_page_2_set)) == print 'test_getNewsSummariesForUser_pagination passed!' if __name__ == "__main__":
test_getNewsSummariesForUser_basic()
test_getNewsSummariesForUser_pagination()
operations_test.py
下面我们来运行一下



后端api完成让那个了
没回到前端webserver的client的Base
将原来的超链接换成router的link to
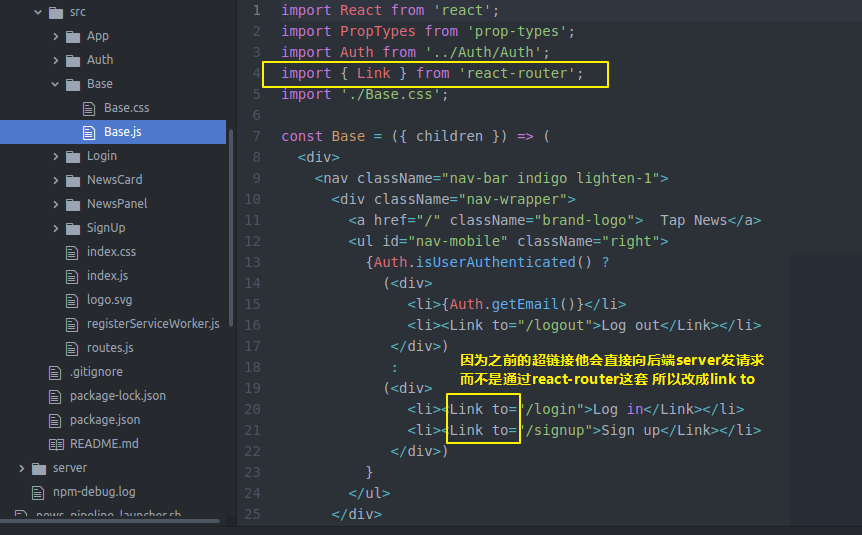
同理 loginForm也要修改

signup也是.

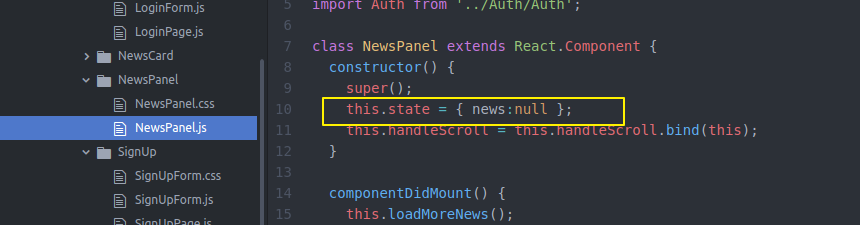
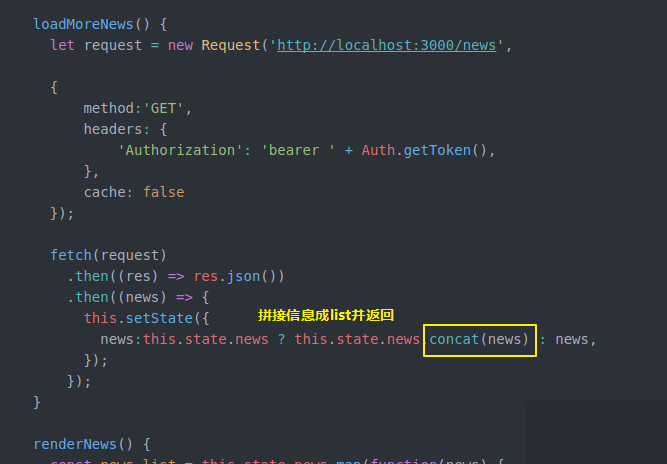
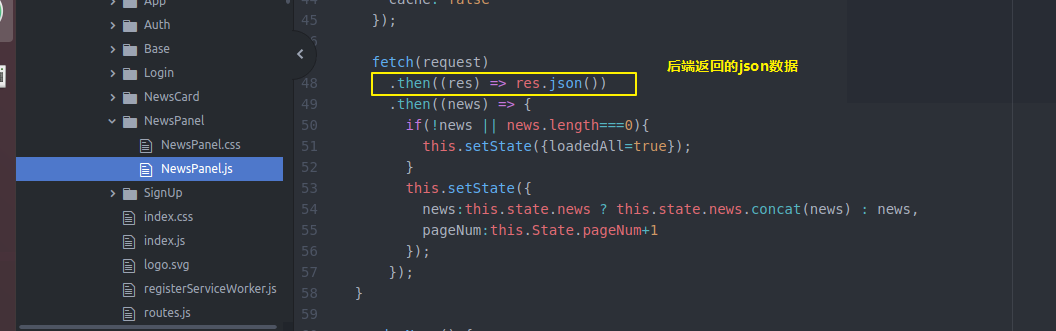
然后还要在NewsPannel做一些工作 之前比较简单 只是state保存一些信息 通过loadmorenews获得更多news
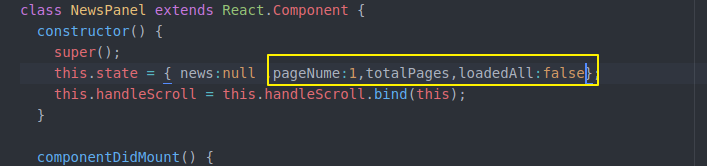
现在我们state除了这些 还要记录分页 总页数 加载完没有
然后loadmorenews

然后做个判断

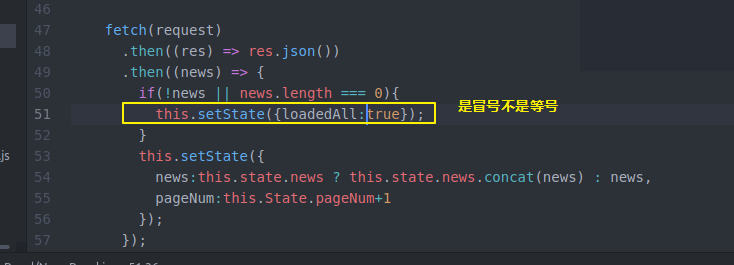
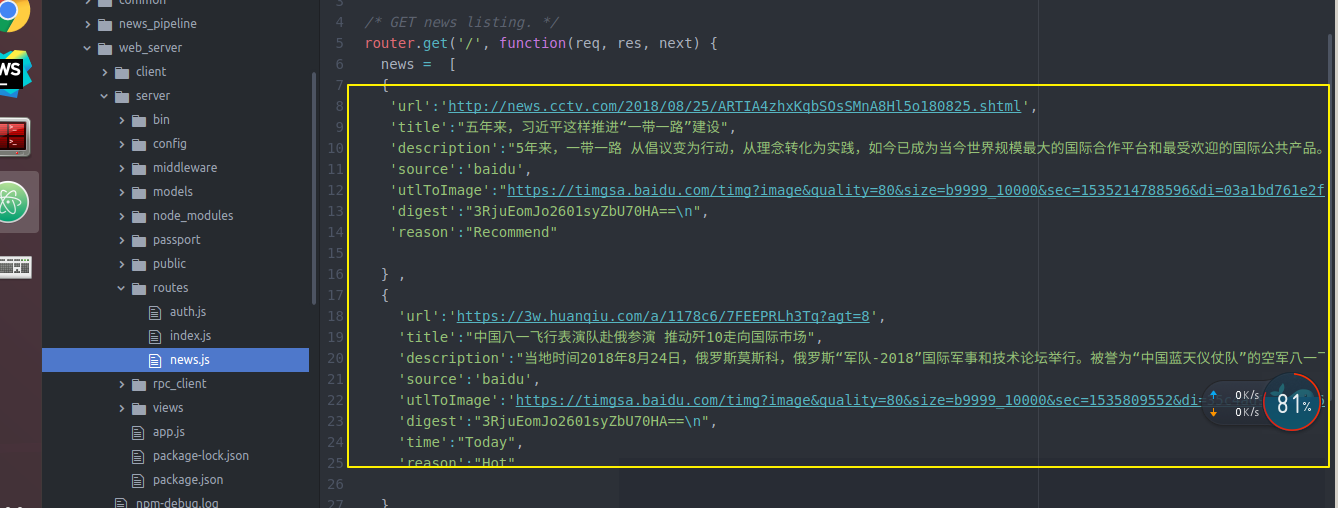
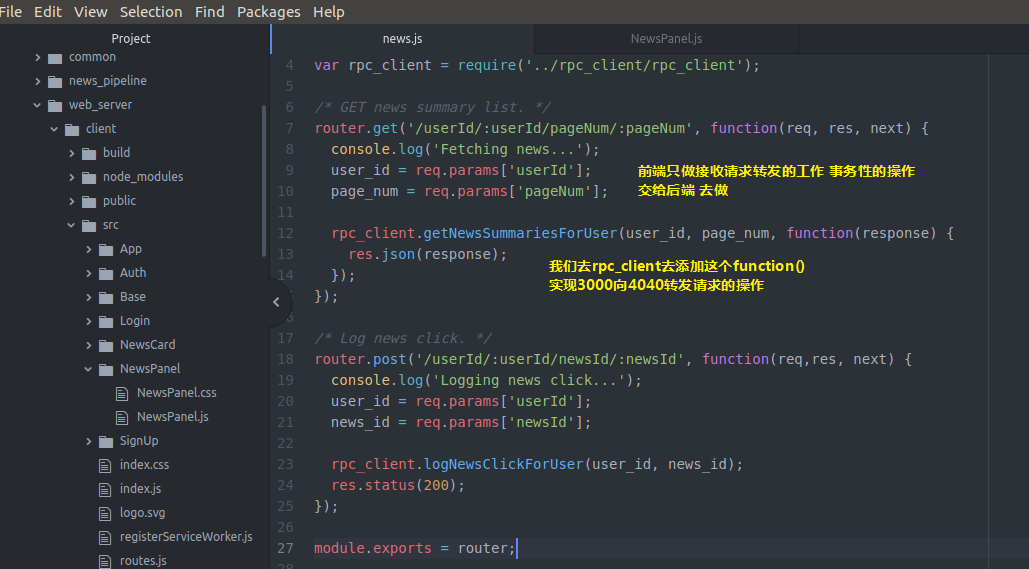
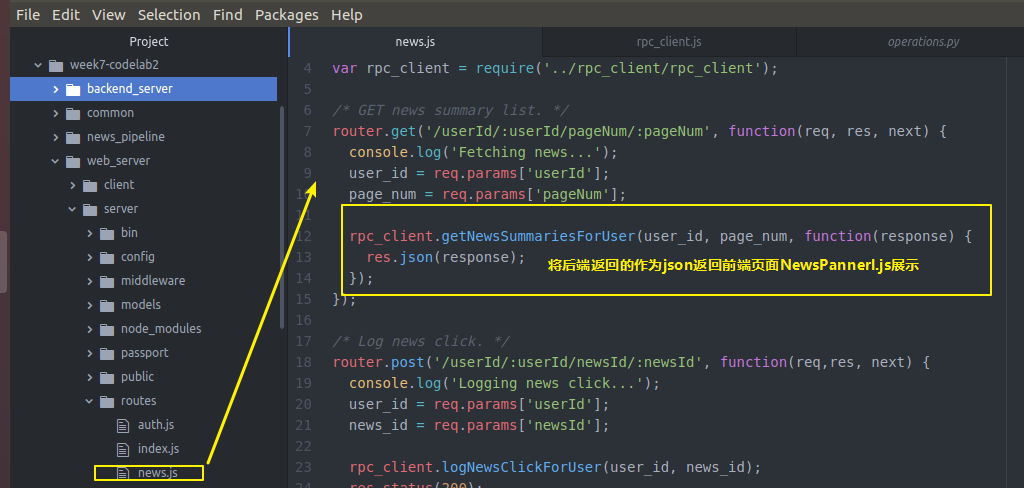
然后 还记得我们的获取新闻的api对象的webserver的server端的news.js是临时数据
news.js吗 我们去修改一下 让他从真正的后端backendserver从数据库拿数据
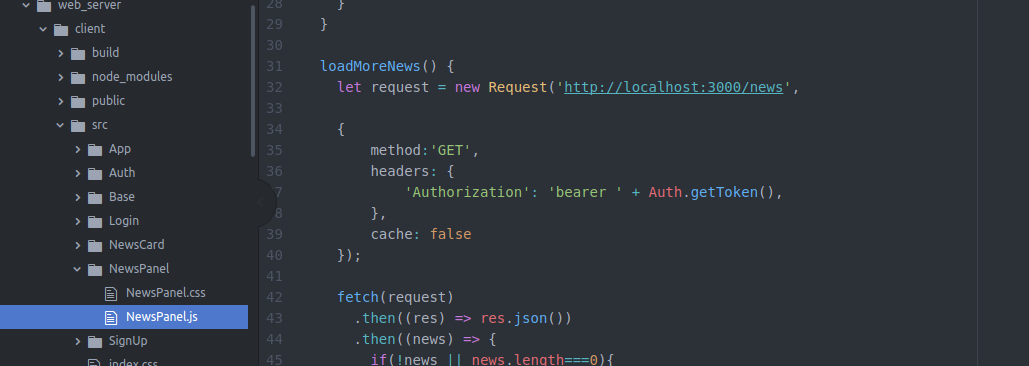
var express = require('express');
var router = express.Router();
var rpc_client = require('../rpc_client/rpc_client');
/* GET news summary list. */
router.get('/userId/:userId/pageNum/:pageNum', function(req, res, next) {
console.log('Fetching news...');
user_id = req.params['userId'];
page_num = req.params['pageNum'];
rpc_client.getNewsSummariesForUser(user_id, page_num, function(response) {
res.json(response);
});
});
/* Log news click. */
router.post('/userId/:userId/newsId/:newsId', function(req,res, next) {
console.log('Logging news click...');
user_id = req.params['userId'];
news_id = req.params['newsId'];
rpc_client.logNewsClickForUser(user_id, news_id);
res.status();
});
module.exports = router;
news.js

所以我们回去带上这两个参数
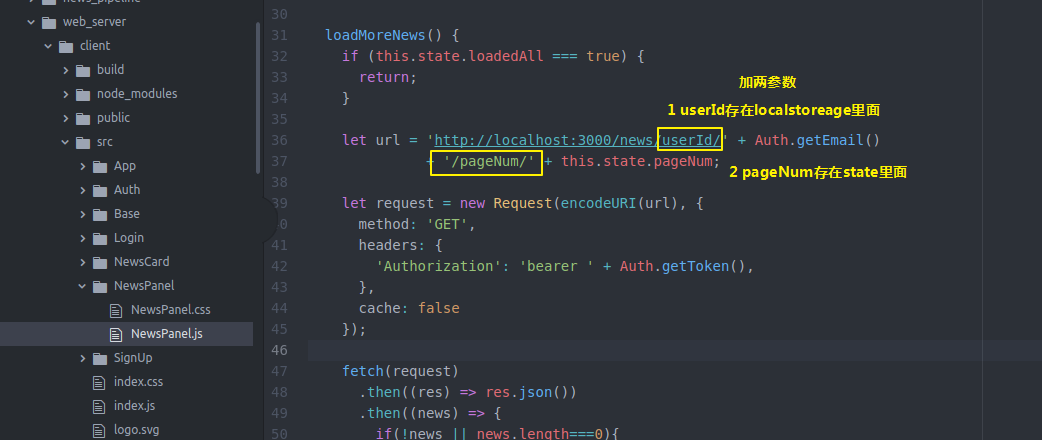
ok
再回到webserver server去
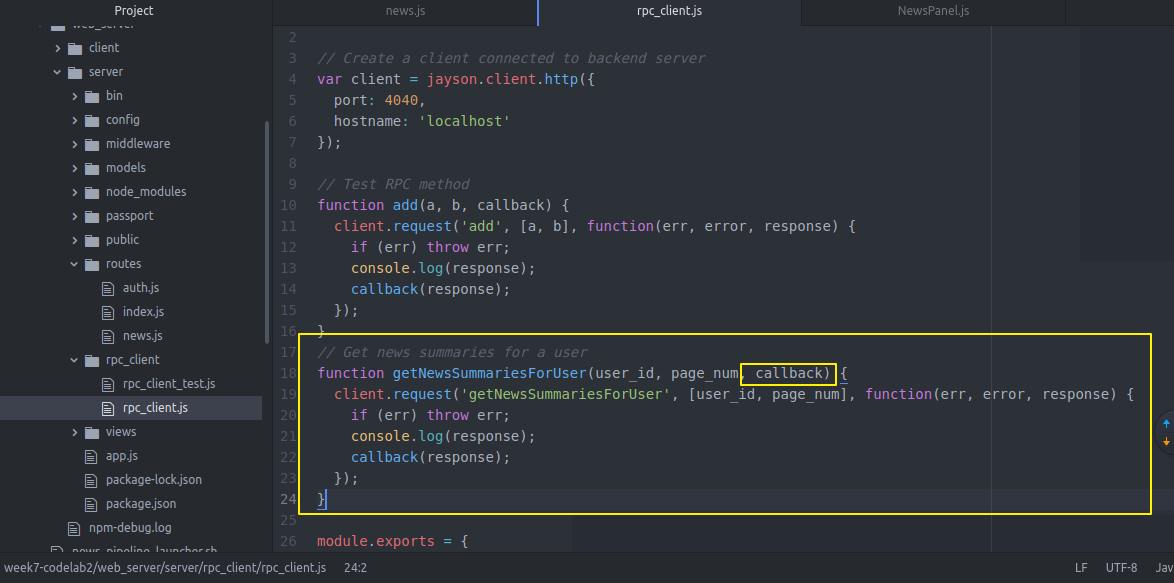
然后我们的真正的后端backend server
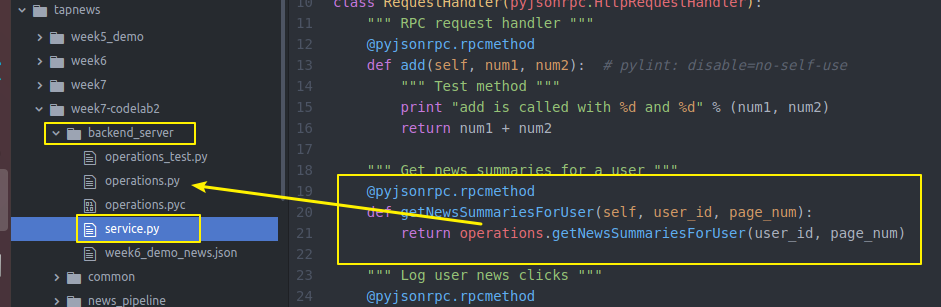
具体实现
等这些操作完成后又回到web server的server去了
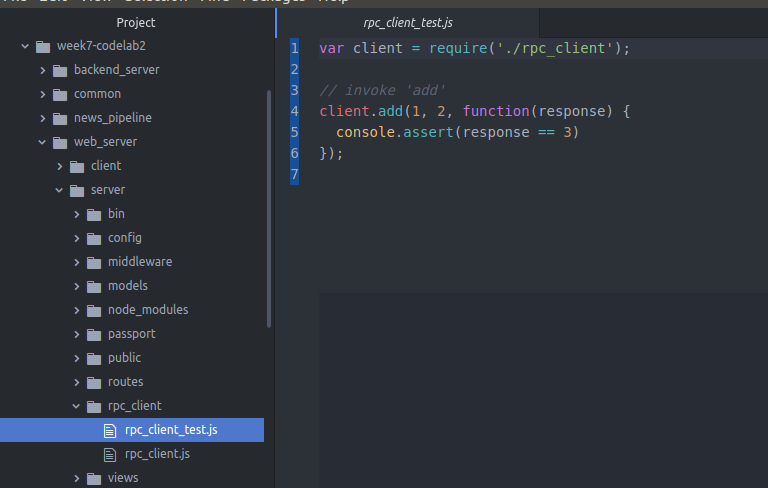
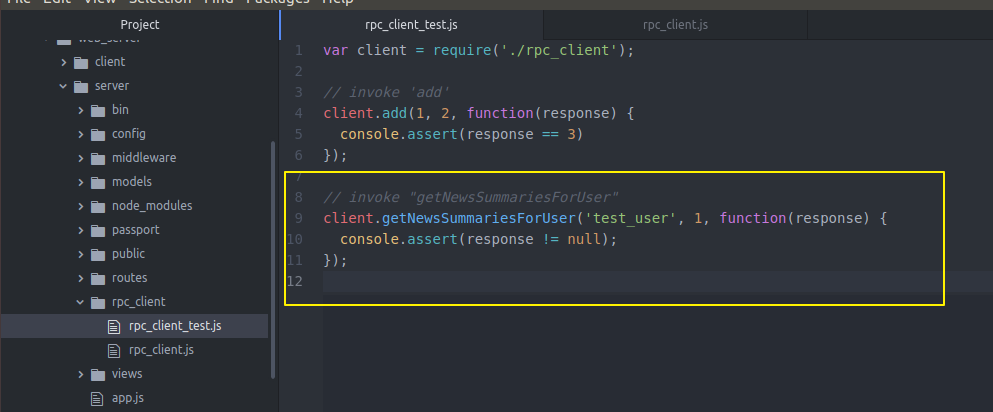
我们洗个test验证一下
我们先将后端骑起来
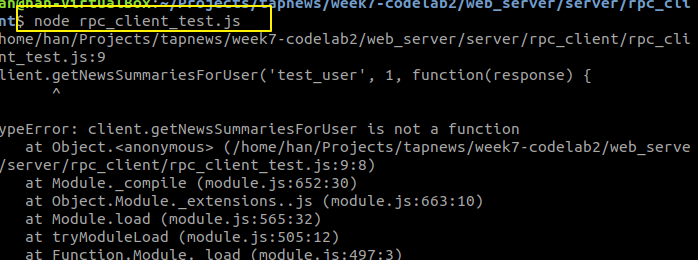
他说找不到这个方法
我们去看看
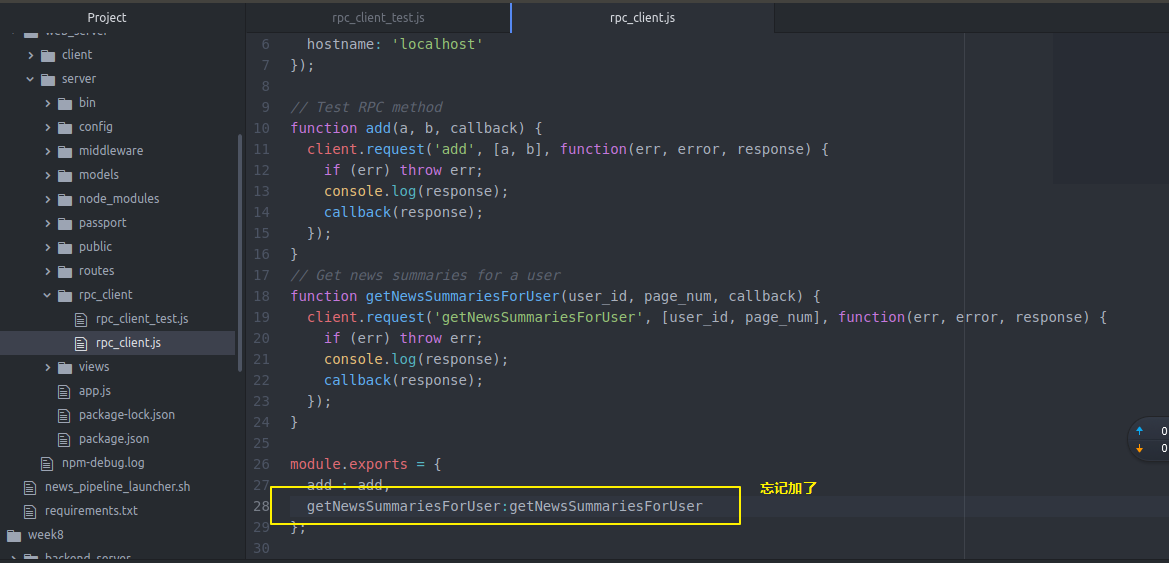
在运行
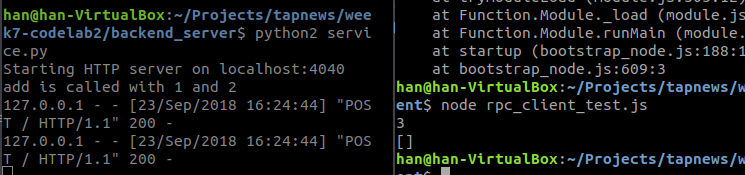
返回空 因为没有这个userid
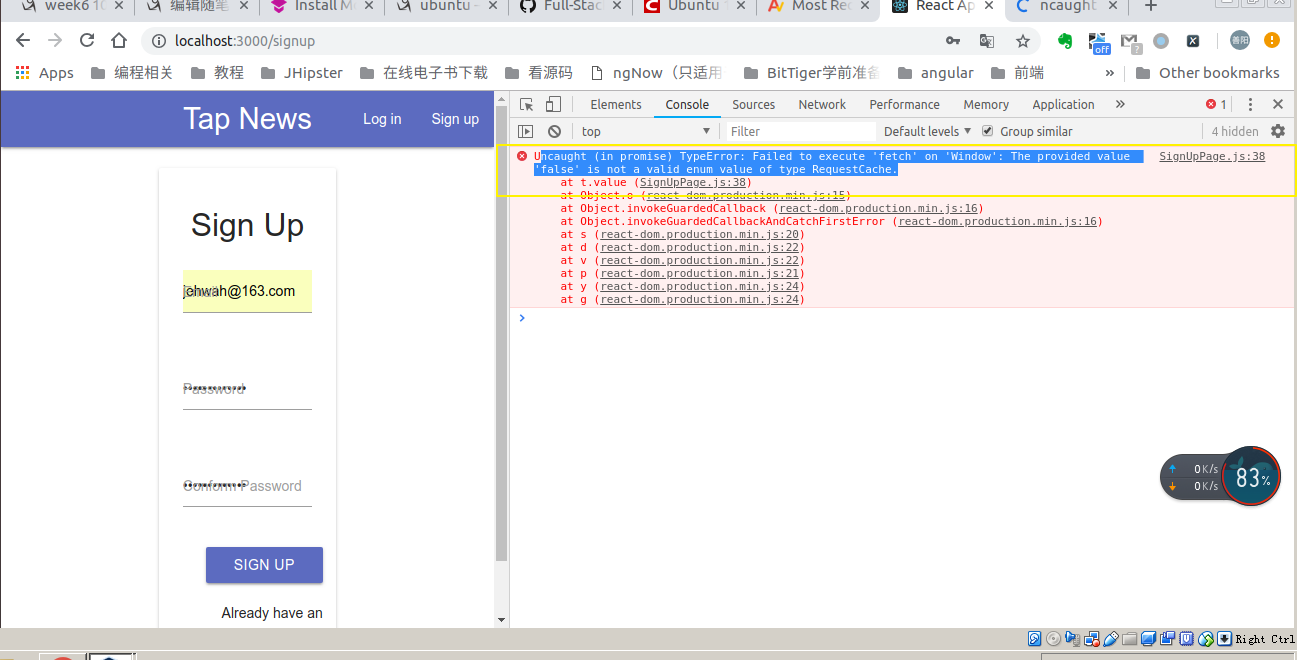
下面前端和后端调通(从网页上看到效果)
首先在web server的client先build一下(将前端页面文件传到build文件中)
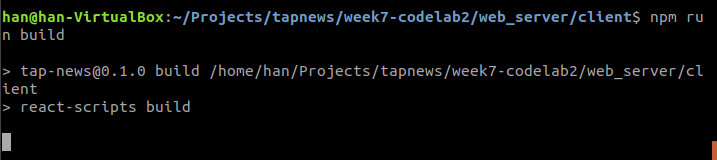
然后去server 起一个端口 npm start 就可以只开一个端口来调试了


week07 codelab02 C72的更多相关文章
- Week07《Java程序设计》第七次作业总结
Week07<Java程序设计>第七次作业总结 1. 本周学习总结 1.1 思维导图:Java图形界面总结 答: 1.2 可选:使用常规方法总结其他上课内容. 答: 1. Swing组件: ...
- 20162328蔡文琛week07
学号 2016-2017-2 <程序设计与数据结构>第X周学习总结 教材学习内容总结 多态引用在不同的时候可以指向不同类型的对象. 多态引用在运行时才将方法调用用于它的定义绑定在一起. 引 ...
- week07 13.3 NewsPipeline之 三News Deduper之 tf_idf 查重
我们运行看结果 安装包sklearn 安装numpy 安装scipy 终于可以啦 我们把安装的包都写在文件里面吧 4行4列 轴对称 只需要看一半就可以 横着看 竖着看都行 数值越接近1 表示越相似 我 ...
- week07 13.4 NewsPipeline之 三 News Deduper
还是循环将Q2中的东西拿出来 然后查重(去mongodb里面把一天之内的新闻都拿出来,然后把拿到的新的新闻和mongodb里一天内的新闻组一个 tf-idf的对比)可看13.3 相似度检查 如果超过一 ...
- week07 13.2 NewsPipeline之 二 News Fetcher - Xpath
我们使用Xpath来专门做一个scrapter 我们专门弄个文件夹 里面全部是 各个新闻源(CNN BBC等)的scraper来抓取网站的text内容 主要函数(就是传入text内容的那个url)然后 ...
- week07 13.1 NewsPipeline之 一 NewsMonitor
我们要重构一下代码 因为我们之前写了utils 我们的NewsPipeline部分也要用到 所以我们把他们单独独立得拿出来 删掉原来的 将requirements.txt也拿出去 现在我们搬家完成 我 ...
- 20162328蔡文琛 大二week07
20162328 2017-2018-1 <程序设计与数据结构>第7周学习总结 教材学习内容总结 树是非线性结构,其元素组织为一个层次结构. 树的度表示树种任意节点的最大子节点数. 有m个 ...
- Python基础-week07 Socket网络编程
一 客户端/服务器架构 1.定义 又称为C/S架构,S 指的是Server(服务端软件),C指的是Client(客户端软件) 本章的中点就是教大写写一个c/s架构的软件,实现服务端软件和客户端软件基于 ...
- shell脚本批量收集linux服务器的硬件信息快速实现
安装ansible批量管理系统.(没有的话,ssh远程命令循环也可以) 在常用的数据库里面新建一张表,用你要收集的信息作为列名,提供可以用shell插入.
随机推荐
- 【爬虫综合作业】猫眼电影TOP100分析
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 一.爬虫对象 猫眼电影TOP100排行榜 二.代码如下 im ...
- python selenium-webdriver 元素操作之键盘操作(五)
上节介绍了模拟鼠标对元素的操作,本节主要介绍键盘对元素的操作,实际过程中鼠标对元素的操作比键盘对元素的操作更经常使用,但是键盘对元素的操作也很重要,本节主要介绍一下键盘对元素的操作. selenium ...
- RocketMQ基本概念及原理介绍
基本概念 ProducerGroup 通常具有同样属性(处理的消息种类-topic.以及消息处理逻辑流程—分布式多个客户端)的一些producer可以归为同一个group.在事务消息机制中,如果某条发 ...
- [ZZ] 多领域视觉数据的转换、关联与自适应学习
哈工大左旺孟教授:多领域视觉数据的转换.关联与自适应学习 http://blog.sciencenet.cn/home.php?mod=space&uid=3291369&do=blo ...
- VS2015 使用GIT同步到github
https://www.cnblogs.com/newP/p/5732431.html(参考) 拉取(Pull):将远程版本库合并到本地版本库,相当于(Fetch+Meger) 获取(Fetch):从 ...
- windows下的端口转发命令netsh
使用下面的命令查看语法 netsh interface portproxy add v4tov4 /? add v4tov4 [listenport=]<integer>|<serv ...
- 如何通过dba_hist_active_sess_history分析数据库历史性能问题
背景在很多情况下,当数据库发生性能问题的时候,我们并没有机会来收集足够的诊断信息,比如system state dump或者hang analyze,甚至问题发生的时候DBA根本不在场.这给我们诊断问 ...
- webservice之jax-rs实现方式
1.什么叫restful风格 restful是一组架构约束条件和原则,满足这些约束条件和原则的应用程序即是restful风格. 2.jax-rs实现步骤 1.创建一个简单应用(略) 2.添加依赖jar ...
- jenkins自动构建站点
jenkins构建iis主要内容, 安装过程百度很多,就不多介绍 看图是主要内容 msbuid功能 1.执行vs的编译过程 2.编译好的文件发布到具体的路径下 批处理功能 1.创建站点 2.创建对应的 ...
- DB2调优摘要
感谢原博主 http://yishueitian326.blog.163.com/blog/static/2858637520106695733719/ 性 能是关系到随需应变型应用程序成功与否的关键 ...