scrapy 基础使用以及错误方案
原先用的是selenium(后面有时间再写),这是第一次使用scrapy这个爬虫框架,所以记录一下这个心路历程,制作简单的爬虫其实不难,你需要的一般数据都可以爬取到。
下面是我的目录,除了main.py以外,都是代码自动生成的 :)。
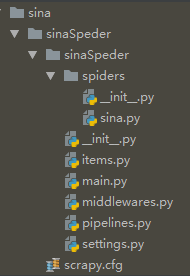
各个目录作用:
1、sina是我自己创建的文件夹用来盛放整个项目的,随便起名字。
2、第一个sinaSpeder文件夹内,有一个scrapy.cfg配置文件和sinaSpeder的文件夹
- scrapy.cfg:配置文件,不需要更改
- sinaSpeder文件夹
3、第二个sinaSpeder文件夹
- init.py :特定文件,指明二级first_spider目录为一个python模块
- item.py:定义需要的item类【实验中需要用到】
- pipelines.py:管道文件,传入item.py中的item类,清理数据,保存或入库
- settings.py:设置文件,例如设置用户代理和初始下载延迟
- spiders目录
4、spiders
- init.py :特定文件,指明二级first_spider目录为一个python模块
- sina.py:盛放自定义爬虫的文件,负责获取html的数据和传入pipline管道中进行数据存放等
废话不多说,开练~~
第一步创建爬虫项目:
- 》scrapy startproject sinaSpeder (sinaSpeder是项目名)
- (用命令创建主要是可以自动生成一个包含默认文件的目录)
第二步输入网址:
- scrapy genspider sina "sina.com.cn" (这个名字是spiders里面的名字,后面的链接是要爬取的链接)
- 注:这个命令会在根目录的同级目录创建sina.py文件(也就是和第一个sinaSpiders同文件夹),需要把它剪切到最里面的spiders文件夹下,
第三步修改代码:参考自:
items.py写入:
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- import sys
- # reload(sys)
- # sys.setdefaultencoding("utf-8")
- class SinaspederItem(scrapy.Item):
- # 大类的标题和url
- parentTitle = scrapy.Field()
- parentUrls = scrapy.Field()
- # 小类的标题和子url
- subTitle = scrapy.Field()
- subUrls = scrapy.Field()
- # 小类目录存储路径
- subFilename = scrapy.Field()
- # 小类下的子链接
- sonUrls = scrapy.Field()
- # 文章标题和内容
- head = scrapy.Field()
- content = scrapy.Field()
sina.py写入:
- # -*- coding: utf-8 -*-
- import scrapy
- import os
- from sinaSpeder.items import SinaspederItem
- import sys
- # reload(sys)
- # sys.setdefaultencoding("utf-8")
- class SinaSpider(scrapy.Spider):
- name = "sina"
- allowed_domains = ["sina.com.cn"]
- start_urls = ['http://news.sina.com.cn/guide/']
- def parse(self, response):
- items = []
- # 所有大类的url 和 标题
- parentUrls = response.xpath('//div[@id="tab01"]/div/h3/a/@href').extract()
- parentTitle = response.xpath('//div[@id="tab01"]/div/h3/a/text()').extract()
- # 所有小类的ur 和 标题
- subUrls = response.xpath('//div[@id="tab01"]/div/ul/li/a/@href').extract()
- subTitle = response.xpath('//div[@id="tab01"]/div/ul/li/a/text()').extract()
- # 爬取所有大类
- for i in range(0, len(parentTitle)):
- # 指定大类目录的路径和目录名
- parentFilename = "./Data/" + parentTitle[i]
- # 如果目录不存在,则创建目录
- if (not os.path.exists(parentFilename)):
- os.makedirs(parentFilename)
- # 爬取所有小类
- for j in range(0, len(subUrls)):
- item = SinaspederItem()
- # 保存大类的title和urls
- item['parentTitle'] = parentTitle[i]
- item['parentUrls'] = parentUrls[i]
- # 检查小类的url是否以同类别大类url开头,如果是返回True (sports.sina.com.cn 和 sports.sina.com.cn/nba)
- if_belong = subUrls[j].startswith(item['parentUrls'])
- # 如果属于本大类,将存储目录放在本大类目录下
- if (if_belong):
- subFilename = parentFilename + '/' + subTitle[j]
- # 如果目录不存在,则创建目录
- if (not os.path.exists(subFilename)):
- os.makedirs(subFilename)
- # 存储 小类url、title和filename字段数据
- item['subUrls'] = subUrls[j]
- item['subTitle'] = subTitle[j]
- item['subFilename'] = subFilename
- items.append(item)
- # 发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理
- for item in items:
- yield scrapy.Request(url=item['subUrls'], meta={'meta_1': item}, callback=self.second_parse)
- # 对于返回的小类的url,再进行递归请求
- def second_parse(self, response):
- # 提取每次Response的meta数据
- meta_1 = response.meta['meta_1']
- # 取出小类里所有子链接
- sonUrls = response.xpath('//a/@href').extract()
- items = []
- for i in range(0, len(sonUrls)):
- # 检查每个链接是否以大类url开头、以.shtml结尾,如果是返回True
- if_belong = sonUrls[i].endswith('.shtml') and sonUrls[i].startswith(meta_1['parentUrls'])
- # 如果属于本大类,获取字段值放在同一个item下便于传输
- if (if_belong):
- item = SinaspederItem()
- item['parentTitle'] = meta_1['parentTitle']
- item['parentUrls'] = meta_1['parentUrls']
- item['subUrls'] = meta_1['subUrls']
- item['subTitle'] = meta_1['subTitle']
- item['subFilename'] = meta_1['subFilename']
- item['sonUrls'] = sonUrls[i]
- items.append(item)
- # 发送每个小类下子链接url的Request请求,得到Response后连同包含meta数据 一同交给回调函数 detail_parse 方法处理
- for item in items:
- yield scrapy.Request(url=item['sonUrls'], meta={'meta_2': item}, callback=self.detail_parse)
- # 数据解析方法,获取文章标题和内容
- def detail_parse(self, response):
- item = response.meta['meta_2']
- content = ""
- head = response.xpath('//h1[@id="main_title"]/text()')
- content_list = response.xpath('//div[@id="artibody"]/p/text()').extract()
- # 将p标签里的文本内容合并到一起
- for content_one in content_list:
- content += content_one
- item['head'] = head
- item['content'] = content
- yield item
pipelines.py写入:
- # -*- coding: utf-8 -*-
- from scrapy import signals
- import sys
- class SinaspederPipeline(object):
- def process_item(self, item, spider):
- sonUrls = item['sonUrls']
- # 文件名为子链接url中间部分,并将 / 替换为 _,保存为 .txt格式
- filename = sonUrls[7:-6].replace('/','_')
- filename += ".txt"
- fp = open(item['subFilename']+'/'+filename, 'w')
- fp.write(item['content'])
- fp.close()
- return item
setting.py写入:
- # 设置管道文件
- ITEM_PIPELINES = {
'sinaSpeder.pipelines.SinaspederPipeline': 300,
}
main.py写入:
- from scrapy import cmdline
- cmdline.execute("scrapy crawl sina".split())
运行有两种方法:
1、这里创建了main。py文件,所以可以直接运行这个文件。
2、通过命令行
- scrapy crawl sina (这个是进入...>sina>sinaSpeder 文件夹后运行的)
第四步:
运行开始后,多出一个data文件夹,这就是要爬取的东西
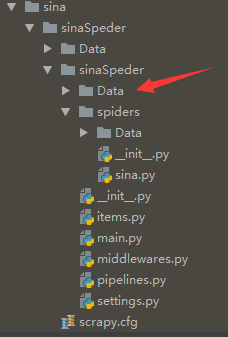
注:问题总结
1、我最初是运行下面这个,发现报错,后来试试spiders中的sina.py文件,结果成功了
- scrapy crawl sinaSpeder
2、如果你建立的工程名字和我的不一样,所有涉及项目名称的文件都要改过来,少一个都会报错。
3、爬虫运行有可能会被封ip使得无法再访问这个网站了!这就需要使用反爬虫技术,以后再讲。
4、错误 twisted.internet.error.DNSLookupError: DNS lookup failed: no results for hostname lookup: http.
原因代码中url出错(修改后就行了)

参考:
https://www.jianshu.com/p/fd443ad67c5b?utm_campaign
https://www.cnblogs.com/xinyangsdut/p/7631163.html
scrapy 基础使用以及错误方案的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- 【笔记-前端】div+css排版基础,以及错误记录
现在的网站对于前端的排版已经逐渐不使用<table>,而是使用div+css. 使用这种方法的最大好处就在于在维护页面时,可以只维护css而不去改动html. 可是这种方式对于初学者来说可 ...
- JavaScript基础——兼容性、错误处理
JavaScript基础-错误处理Throw.Try.Catch try语句执行可能出错的代码 catch语句处理捕捉到的错误 throw语句创建自定义错误语句 发生的常见的错误类型 可能是语法错误, ...
- scrapy 基础
安装略过 创建一个项目 scrapy startproject MySpider #或者创建时存储日志scrapy startproject --logfile='../logf.log' MySpi ...
- Scrapy基础(十三)————ItemLoader的简单使用
ItemLoader的简单使用:目的是解决在爬虫文件中代码结构杂乱,无序,可读性差的缺点 经过之前的基础,我们可以爬取一些不用登录,没有Ajax的,等等其他的简单的爬虫回顾我们的代码,是不是有点冗长, ...
- Scrapy基础(一) ------学习Scrapy之前所要了解的
技术选型: Scrapy vs requsts+beautifulsoup 1,reqests,beautifulsoup都是库,Scrapy是框架 2,Scrapy中可以加入reques ...
- PHP 基础篇 - PHP 错误级别详解
一.前言 最近经常看到工作 2 年左右的童鞋写的代码也会出现以静态方法的形式调用非静态方法,这是个 Deprecated 级别的语法错误,代码里不应该出现的.对方很郁闷,说:为什么我的环境可以正常运行 ...
- scrapy基础知识之 Logging:
修改配置文件settings.py,任意位置添加 LOG_FILE = "XxSpider.log" LOG_LEVEL = "INFO" Log levels ...
随机推荐
- Windows Server 2008 R2 报错事件ID:10之WMI报错
问题描述: Details -Event filter with query "SELECT * FROM __InstanceModificationEvent WITHIN 60 WHE ...
- 安装v2ray+SwitchyOmega使用谷歌***
系统环境:ubuntu18.04 1.安装v2ray 在root用户下执行命令:bash < (curl -L -s https://install.direct/go.sh) $ cd /e ...
- Python-WEB前端-入门到进阶开发之路
HTTP: Python-HTTP 概况 HTML: Python-HTML基础 Python-form表单标签 Python-HTML CSS 练习 CSS: Python-CSS入门 Python ...
- 洛谷P4859 已经没有什么好害怕的了 [DP,容斥]
传送门 思路 大佬都说这是套路题--嘤嘤嘤我又被吊打了\(Q\omega Q\) 显然,这题是要\(DP\)的. 首先思考一下性质: 为了方便,下面令\(k=\frac{n+k}{2}\),即有恰好\ ...
- Confluence 6 垃圾收集性能问题
这个文章与 Oracle 的 Hotspot JVM 虚拟机的内存管理为参照的.这些建议是我们在对大的 Confluence 安装实例用户进行咨询服务的时候得到的最佳配置方案. 请不要在 Conflu ...
- Confluence 6 使用 Velocity 宏
当编辑自定义 Decorator 模板文件的时候,有一些宏可被用来定义页面中复杂或者多变的内容,例如菜单,链接等.你可以插入这些宏到你的模板中.更多的信息,请参考Working With Decora ...
- Netty多人聊天室
在简单聊天室的代码中修改ChatServerHandler类,就可以模拟多人聊天的功能 package com.cppdy.server; import io.netty.channel.Channe ...
- mysql 安装问题一:由于找不到MSVCR120.dll,无法继续执行代码.重新安装程序可能会解决此问题。
这种错误是由于未安装 vcredist 引起的 下载 vcredist 地址:https://www.microsoft.com/zh-CN/download/details.aspx?id= ...
- 《剑指offer》 二进制中1的个数
本题来自<剑指offer> 二进制中1的个数 题目: 输入一个整数,输出该数二进制表示中1的个数.其中负数用补码表示. 思路: 两种思路: 第一种:对n进行左移,检测最后一位是否为1,但考 ...
- bzoj3991 lca+dfs序应用+set综合应用
/* 给定一棵树,树上会出现宝物,也会有宝物消失 规定如果要收集树上所有宝物,就要选择一个点开始,到每个宝物点都跑一次,然后再回到那个点 现在给定m次修改,每次修改后树上就有一个宝物消失,或者一个宝物 ...