有关 Azure 机器学习的 Net# 神经网络规范语言的指南
Net# 是由 Microsoft 开发的一种用于定义神经网络体系结构的语言。 使用 Net# 定义神经网络的结构使定义复杂结构(如深层神经网络或任意维度的卷积)变得可能,这些复杂结构被认为可提高对数据的学习,如映像、音频或视频。
在下列上下文中,可以使用 Net# 体系结构规范:
- Microsoft Azure 机器学习工作室中的所有网络模块:多类神经网络、两类神经网络和神经网络回归
- MicrosoftML 中的神经网络函数:R 语言的 NeuralNet 和 rxNeuralNet,以及 Python 的 rx_neural_network。
本文介绍了使用 Net# 开发自定义神经网络的基本概念和所需语法:
- 神经网络要求以及如何定义主要组件
- Net# 规范语言的语法和关键字
- 使用 Net# 创建的自定义神经网络的示例
神经网络基础知识
神经网络结构包括了在层中组织的节点,以及节点之间的加权连接(或边缘)。 连接是有方向的,每个连接具有一个源节点和一个目标节点。
每个可训练层(隐藏或输出层)具有一个或多个连接捆绑。 连接捆绑包括一个源层和该源层中的连接规范。 给定捆绑中的所有连接共享同一源层和同一目标层。 在 Net # 中,连接捆绑将视为属于捆绑的目标层。
Net # 支持各种类型的连接捆绑,可自定义映射到隐藏层和映射到输出的输入方式。
默认或标准捆绑是一个完整捆绑,其中源层中的每个节点都连接到目标层中的每个节点。
此外,Net# 支持以下四种高级连接捆绑:
筛选捆绑。 用户可通过使用源层节点和目标层节点的位置来定义一个谓词。 每当谓词为 Ture,节点即连接。
卷积捆绑。 用户可在源层中定义节点的小范围邻域。 目标层中的每个节点连接到源层中节点的一个邻域。
池捆绑和响应规范化捆绑。 这些与卷积捆绑类似,用户可在其中定义源层中小范围的邻域。 不同之处在于这些捆绑中边缘的权重不可训练。 相反,为源节点值应用预定义的函数可确定目标节点值。
支持的自定义项
在 Azure 机器学习中创建的神经网络模型的体系结构可通过使用 Net# 广泛自定义。 可以:
- 创建隐藏层并控制每层的节点数。
- 指定如何相互连接层。
- 定义特殊的连接结构,如卷积和权重共享捆绑。
- 指定不同的激活函数。
有关规范语言语法的详细信息,请参阅 结构规范。
有关为某些常见机器学习任务定义神经网络的示例(从单一到复杂),请参阅示例。
一般要求
- 必须正好是一个输出层,至少一个输入层,以及零个或多个隐藏层。
- 每层都有固定节点数,在任意维度的举行数组中按概念排列。
- 输入层没有关联的训练参数,并表示实例数据进入网络的点。
- 可训练层(隐藏和输出层)具有关联的培训参数,称为权重和偏差。
- 源和目标节点必须处于不同的层。
- 连接必须是非循环的;换句话说,不能有导回初始源节点的连接链。
- 输出层不能是连接捆绑的源层。
结构规范
神经网络结构规范由三部分组成:常数声明、层声明、连接声明。 还有另一可选部分:共享声明。 可以按任意顺序指定这些部分。
常数声明
常数声明是可选的。 它提供了一种方法来定义神经网络定义中其他位置使用的值。 声明语句包含标识符(后跟一个等号和值表达式)。
例如,下面的语句定义一个常量 x:
Const X = 28;
要同时定义两个或多个常量,可将标识符名称和值括在括号内,并使用分号隔开。 例如:
Const { X = 28; Y = 4; }
每个赋值表达式的右侧可以是整数、实数、 布尔值(True 或 False)或数学表达式。 例如:
Const { X = 17 * 2; Y = true; }
层声明
层声明是必需的。 它定义层的大小和源,包括其连接捆绑和属性。 声明语句以层(输入、隐藏或输出)名称为开头,后跟层的维度(正整数的元组)。 例如:
input Data auto;
hidden Hidden[,] from Data all;
output Result[] from Hidden all;
- 维度的乘积是层中节点数。 在此示例中,有两个维度 [5,20],这意味着层中有 100 个节点。
- 层可按任意顺序进行声明,但有一个例外:如果定义了多个输入层,那么声明的顺序必须与输入数据中的功能顺序匹配。
若要指定自动确定层中节点数,请使用 auto 关键字。 auto 关键字具有不同的效果,具体取决于层:
- 在输入层声明中,节点数是输入数据中的功能数。
- 在隐藏层声明中,节点数是隐藏节点数的参数值指定的数。
- 在输出层声明中,双类分类的节点数是 2,回归的节点数是 1,最多分类的节点数与输出节点数相等。
例如,以下网络定义可自动确定所有层的大小:
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
可训练层(隐藏或输出层)的层声明可选择包括输出函数(也称为激活函数),这会分类模型默认为 sigmoid,回归模型默认为 linear。 即使使用默认值,为了清楚起见,也可以显式声明激活函数。
支持以下输出函数:
- sigmoid
- linear
- softmax
- rlinear
- square
- sqrt
- srlinear
- abs
- tanh
- brlinear
例如,下面的声明使用 softmax 函数:
output Result [] softmax from Hidden all;
连接声明
定义可训练层之后,必须声明已定义的层中的连接。 连接捆绑以关键字 from 开头,后跟捆绑的源层名称以及要创建的连接捆绑的种类。
当前支持五种类型的连接捆绑:
- 完整捆绑,由关键字
all指示 - 经筛选的捆绑,由后跟谓词表达式的关键字
where指示 - 卷积捆绑,由后跟卷积属性的关键字
convolve指示 - 池捆绑,由关键字 max pool 或 mean pool 指示
- 响应规范捆绑,由关键字 response norm 指示
完整捆绑
完整捆绑包括源层中每个节点到目标层中每个节点的连接。 这是默认网络连接类型。
筛选捆绑
筛选连接捆绑规范包含一个谓词,在语法表达上,更类似 C# lambda 表达式。 下面的示例定义两个筛选捆绑:
input Pixels [, ];
hidden ByRow[, ] from Pixels where (s,d) => s[] == d[];
hidden ByCol[, ] from Pixels where (s,d) => abs(s[] - d[]) <= ;
在
ByRow的谓词中,s是输入层Pixels的节点的矩形数组中表示索引的参数,d是隐藏层ByRow的节点的数组中表示索引的参数。s和d的类型是长度为 2 的整数元组。 从概念上讲,s涵盖了0 <= s[0] < 10且0 <= s[1] < 20的所有整数对,d涵盖了0 <= d[0] < 10且0 <= d[1] < 12的所有整数对。在谓词表达式的右侧端上有一个条件。 在本例中,对于
s和d的每个值,该条件为 True,从源层节点到目标层节点有一个边缘。 因此,在所有 s[0] 等于 d[0] 的情况下,此筛选表达式指示捆绑包括从由s定义的节点到由d定义的节点的连接。
或者,可以为筛选的捆绑指定一组权重。 Weights 属性的值必须是浮点值的元组,其长度与捆绑定义的连接数匹配。 默认情况下,权重是随机生成的。
权重值按照目标节点索引进行分组。 也就是说,在源索引顺序中,如果第一个目标节点连接到 K 源节点,则 Weights 元组的前 K 个元素为第一个目标节点的权重。 这同样适用于其他目标节点。
可直接将权重指定为常量值。 例如,如果以前了解权重,则可以使用此语法将其指定为常量:
const Weights_1 = [0.0188045055, 0.130500451, ...]
卷积捆绑
如果训练数据具有同类结构,则通常使用卷积捆绑来了解数据的高级功能。 例如,映像、音频或视频数据中的空间或临时维数可以很统一。
卷积捆绑使用通过维度滑动的矩形内核。 实质上,每个内核定义一组在本地邻域中应用的权重,称为内核应用程序。 每个内核应用程序对应一个源层中的节点,称为内核节点。 内核的权重在多个连接中共享。 在卷积捆绑中,每个内核都是矩形状的,并且所有内核应用程序都具有相同大小。
卷积捆绑支持一下属性:
InputShape 可定义用于此卷积捆绑的源层维数。 值必须是正整数的元组。 整数的乘积必须等于源层中的节点数,否则,不需要与源层声明的维数匹配。 此元组的长度会成为卷积捆绑的实参数量值。 通常,实参数量表示函数可采用的参数或操作的数量。
若要定义内核的形状和位置,可使用属性 KernelShape、Stride、Padding、LowerPad 或 UpperPad:
KernelShape:(必需)为卷积捆绑定义每个内核的维数。 值必须是正整数的元组,其长度等于捆绑的实参数量。 此元组的每个组件必须不超过 InputShape 的相应组件。
Stride:(可选)定义卷积的滑动步大小(每个维度的每步大小),即中央节点之间的距离。 值必须是正整数的元组,其长度为捆绑的实参数量。 此元组的每个组件必须不超过 KernelShape 的相应组件。 默认值为一个元组,其所有组件都等于 1。
Sharing:(可选)定义卷积的每个维度的权重共享。 值可以是单个布尔值或布尔值的元组(其长度为捆绑的实参数量)。 单个布尔值扩展为正确长度的元组,所有组件都等于指定值。 默认值为包含所有 True 值的元组。
MapCount:(可选)为卷积捆绑定义功能映射数。 值可以是单个正整数或正整数的元组(其长度为捆绑的实参数量)。 单个整数值扩展为正确长度的元组,第一个组件等于指定值,其他所有组件等于 1. 默认值为 1。 功能映射的总数是元组组件的乘积。组件之间的总数的因数分解可确定目标节点中功能映射值的分组方式。
Weights:(可选)定义捆绑的初始权重。 值必须是浮点值的元组,其长度为内核数乘以每个内核的权重数,会在本文后面部分中定义。 默认权重是随机生成的。
有两组控制填充的属性,这两个属性相互排斥:
Padding:(可选)确定是否应该使用默认填充方案来填充输入。 值可以是单个布尔值或布尔值的元组(其长度为捆绑的实参数量)。
单个布尔值扩展为正确长度的元组,所有组件都等于指定值。
如果维度值为 True,则使用零值单元格将源按逻辑填充到维度以支持其他内核应用程序,从而使该维度中第一个和最后一个内核的中央节点称为源层的维度中的第一个和最后一个节点。 因此,每个维度中的“虚拟”节点数将自动确定,以使
(InputShape[d] - 1) / Stride[d] + 1内核完全符合填充的源层。如果维度值为 False,则将定义内核,使留出的每个端上的节点数都相同(最大差值为 1)。 此属性的默认值为一个元组,其所有组件都等于 False。
UpperPad 和 LowerPad:(可选)对大量要使用的填充提供更好的控制。 重要提示: 当且仅当没有定义上述的 Padding 属性时,才能定义这些属性。 值必须是正整数值的元组,其长度为绑定的实参数量。 指定这些属性后,“虚拟”节点将添加到输入层的每个维度的上下两端。 每个维度的上下两端添加的节点数分别由 LowerPad[i] 和 UpperPad[i] 确定。
若要确保内核只对应“真实”节点而不是“虚拟”节点,则必须符合以下条件:
- LowerPad 的每个组件必须严格小于
KernelShape[d]/2。 - UpperPad 的每个组件不能大于
KernelShape[d]/2。 这些属性的默认值为一个元组,其所有组件都等于 0。
设置 Padding = true 允许尽可能多的填充,使内核的“中心”保持在“真实”输入内。 这会对数学做出一些更改,以便计算输出大小。 通常情况下,输出大小 D 计算为
D = (I - K) / S + 1,其中I是输入大小,K是内核大小,S是 stride,/表示整数除法(向零舍入)。 如果设置 UpperPad = [1, 1],则输入大小I实际上是 29,因此D = (29 - 5) / 2 + 1 = 13。 但是,当 Padding = true 时,I实际上增长K - 1,因此D = ((28 + 4) - 5) / 2 + 1 = 27 / 2 + 1 = 13 + 1 = 14。 通过为 UpperPad 和 LowerPad 指定值,相比只设置 Padding = true,可以更好地控制填充。
- LowerPad 的每个组件必须严格小于
有关卷积网络及其应用程序的详细信息,请参阅这些文章:
- http://deeplearning.net/tutorial/lenet.html
- http://research.microsoft.com/pubs/68920/icdar03.pdf
- http://people.csail.mit.edu/jvb/papers/cnn_tutorial.pdf
池捆绑
池捆绑适用于类似卷积连接的几何,但是它使用源节点的预定义函数来派生目标节点值。 因此,池捆绑不具有可训练状态(权重或偏差)。 池捆绑支持所有卷积属性,除了 Sharing、MapCount 和 Weights。
通常情况下,按相邻池单位汇总的内核不会重叠。 如果在每个维度中 Stride[d] 等于KernelShape[d] ,那么获取的层为传统本地池层,其广泛应用于卷积神经网络。 每个目标节点将计算源层中其内核的最大活动数或平均值。
以下示例对池捆绑进行了说明:
hidden P1 [, , ]
from C1 max pool {
InputShape = [ , , ];
KernelShape = [ , , ];
Stride = [ , , ];
}
- 捆绑的实参数量为 3,也就是元组
InputShape、KernelShape和Stride的长度。 - 源层中的节点数为
5 * 24 * 24 = 2880。 - 这是传统本地池层,因为 KernelShape 和 Stride 相等。
- 目标层中的节点数为
5 * 12 * 12 = 1440。
有关池层的详细信息,请参阅这些文章:
- http://www.cs.toronto.edu/~hinton/absps/imagenet.pdf(第 3.4 节)
- http://cs.nyu.edu/~koray/publis/lecun-iscas-10.pdf
- http://cs.nyu.edu/~koray/publis/jarrett-iccv-09.pdf
响应规范化捆绑
响应规范化是本地规范化方案,由 Geoffrey Hinton 等人在文章 ImageNet Classification with Deep Convolutional Neural Networks(深层卷积神经网络的 ImageNet 分类)中首次引入。
响应规范化用于避免神经网络中的通用化。 一个神经元在一个非常高的激活级别中激发时,本地响应规范化层将抑制周围神经元的激活级别。 这是通过使用三个参数(α、β 和 k)和一个卷积结构(或邻域形状)来完成的。 目标层 y 中的每个神经元对应于源层中神经元 x。 y 的激活级别由以下公式指定,其中 f 是神经元的激活级别,Nx 是内核(或包含 x 邻域中神经元的集),由以下卷积结构定义:
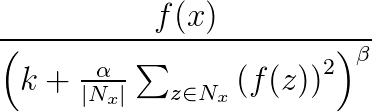
响应规范化捆绑支持所有卷积属性,除了 Sharing、MapCount 和 Weights。
如果内核包含与 x 相同的映射中的神经元,则规范化方案称为相同映射规范化。 若要定义相同映射规范化,那么 InputShape 中的第一个坐标必须具有值 1.
如果内核包含与 x 相同的空间位置中的神经元,但是神经元位于其他映射中,则规范化方案称为跨映射规范化。 这种类型的响应规范化可实现一种横向抑制,其灵感来源于从真实神经元中发现的类型,可创建不同映射上计算的神经元输出之间的大激活级别的竞争。 若要定义跨映射规范化,第一个坐标必须是大于 1 且不大于映射数的正整数,其他坐标则必须具有值 1.
因为响应规范化捆绑应用源节点值的预定义函数以确定目标节点值,所以它们不具有可训练状态(权重或偏差)。
备注
目标层中的节点对应于是内核的中央节点的神经元。 例如,如果 KernelShape[d] 为奇数,则 KernelShape[d]/2 对应于中央内核节点。 如果 KernelShape[d] 为偶数,则中央节点位于 KernelShape[d]/2 - 1。 因此,如果 Padding[d] 为 False,则第一个和最后一个 KernelShape[d]/2 节点在目标层中没有对应节点。 要避免这种情况,可将 Padding 定义为 [true, true, …, true]。
除了前面所述的四个属性,响应规范化捆绑还支持以下属性:
- Alpha:(必需)指定一个与前面公式中的
α对应的浮点值。 - Beta:(必需)指定一个与前面公式中的
β对应的浮点值。 - Offset:(可选)指定一个与前面公式中的
k对应的浮点值。 默认为 1。
下面的示例使用这些属性定义回应规范化捆绑:
hidden RN1 [, , ]
from P1 response norm {
InputShape = [ , , ];
KernelShape = [ , , ];
Alpha = 0.001;
Beta = 0.75;
}
- 源层包括五个映射,每个具有一个 12x12 维度,总计 1440 个节点。
- 值 KernelShape 指示这是一个相同的映射规范化层,其中邻域为一个 3x3 矩形。
- Padding 的默认值为 False,因此目标层的每个维度中只有 10 个节点。 要包括一个与源层中每个节点对应的目标层中的节点,可添加 Padding = [true, true, true];然后将 RN1 的大小更改为 [5, 12, 12]。
共享声明
Net # 可选择支持定义具有共享权重的多个捆绑。 如果任意两个捆绑的结构相同,则其权重可以共享。 以下语法可定义具有共享权重的捆绑:
share-declaration:
share { layer-list }
share { bundle-list }
share { bias-list } layer-list:
layer-name , layer-name
layer-list , layer-name bundle-list:
bundle-spec , bundle-spec
bundle-list , bundle-spec bundle-spec:
layer-name => layer-name bias-list:
bias-spec , bias-spec
bias-list , bias-spec bias-spec:
=> layer-name layer-name:
identifier
例如,以下共享声明指定层名称,指示应共享两个权重和偏差:
Const {
InputSize = ;
HiddenSize = ;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [] {
from H1 all;
from H2 all;
}
share { H1, H2 } // share both weights and biases
- 输入功能划分为两个相等大小的输入层。
- 隐藏层则计算两个输入层上的更高级别的功能。
- 共享声明指定 H1 和 H2 必须从其各自的输入中以相同的方式进行计算。
或者,可以使用两个单独的共享声明来指定,如下所示:
share { Data1 => H1, Data2 => H2 } // share weights
<!-- -->
share { => H1, => H2 } // share biases
只有在层包含单个捆绑时,才可以使用缩写形式。 一般情况下,只有在相关结构相同时(即具有相同大小、相同卷积几何等),才能共享。
Net # 用法的示例
本部分提供了一些示例,可了解如何使用 Net# 添加隐藏层,定义隐藏层与其它层交互的方式,以及生成卷积网络。
定义一个简单的自定义神经网络:“Hello World”示例
这个简单的示例演示了如何创建具有单个隐藏层的神经网络模型。
input Data auto;
hidden H [] from Data all;
output Out [] sigmoid from H all;
该示例阐释了一些基本的命令,如下所示:
- 第一行定义了输入层(名为
Data)。 使用auto关键字时,神经网络会自动包括输入示例中的所有功能列。 - 第二行创建隐藏层。 为该隐藏层指定了名称
H,该层有 200 个节点。 这一层完全连接到输入层。 - 第三行定义了输出层(名为
O),其中包含 10 个输出节点。 如果神经网络用于分类,则每个类有一个输出节点。 关键字 sigmoid 指示输出函数将应用于输出层。
定义多个隐藏层:计算机影像示例
下面的示例将演示如何使用多个自定义隐藏层,定义稍微复杂一些的神经网络。
// Define the input layers
input Pixels [, ];
input MetaData []; // Define the first two hidden layers, using data only from the Pixels input
hidden ByRow [, ] from Pixels where (s,d) => s[] == d[];
hidden ByCol [, ] from Pixels where (s,d) => abs(s[] - d[]) <= ; // Define the third hidden layer, which uses as source the hidden layers ByRow and ByCol
hidden Gather []
{
from ByRow all;
from ByCol all;
} // Define the output layer and its sources
output Result []
{
from Gather all;
from MetaData all;
}
此示例说明了神经网络规范语言的多个功能:
- 此结构中包含两个输入层:
Pixels和MetaData。 Pixels层是两个连接捆绑的源层(目标层为ByRow和ByCol)。- 层
Gather和Result是多个连接捆绑中的目标层。 - 输出层
Result是两个连接捆绑中的目标层;一个以第二级隐藏层Gather作为目标层,另一个以输入层MetaData作为目标层。 - 隐藏层
ByRow和ByCol使用谓词表达式指定经筛选的连接。 更确切地说,ByRow中 [x, y] 处的节点连接到Pixels中第一个索引坐标等于节点的第一个坐标 x 的节点。 同样,ByCol中 [x, y] 处的节点连接到Pixels中第二个索引坐标位于节点的第二个坐标 y 内的节点。
为多类分类定义卷积网络:数字识别示例
以下网络的定义旨在识别数字,并说明了自定义神经网络的一些高级技术。
input Image [, ];
hidden Conv1 [, , ] from Image convolve
{
InputShape = [, ];
KernelShape = [ , ];
Stride = [ , ];
MapCount = ;
}
hidden Conv2 [, , ]
from Conv1 convolve
{
InputShape = [ , , ];
KernelShape = [ , , ];
Stride = [ , , ];
Sharing = [false, true, true];
MapCount = ;
}
hidden Hid3 [] from Conv2 all;
output Digit [] from Hid3 all;
- 此结构具有单个输入层
Image。 - 关键字
convolve指示名为Conv1和Conv2的层是卷积层。 每个这些层声明都后跟一个卷积属性列表。 - Net 具有第三个隐藏层
Hid3,该层完全连接到第二个隐藏层Conv2。 - 输出层
Digit仅连接到第三个隐藏层Hid3。 关键字all指示输出层完全连接到Hid3。 - 卷积的实参数量为 3:元组
InputShape、KernelShape、Stride, and的长度。 - 每个内核的权重数为
1 + KernelShape\[0] * KernelShape\[1] * KernelShape\[2] = 1 + 1 * 5 * 5 = 26或26 * 50 = 1300。 可以计算每个隐藏层中的节点,如下所示:
NodeCount\[0] = (5 - 1) / 1 + 1 = 5NodeCount\[1] = (13 - 5) / 2 + 1 = 5NodeCount\[2] = (13 - 5) / 2 + 1 = 5可通过使用层的声明维数 [50, 5, 5] 来计算节点总数,如下所示:
MapCount * NodeCount\[0] * NodeCount\[1] * NodeCount\[2] = 10 * 5 * 5 * 5- 因为只有
d == 0时Sharing[d]为 False,因此内核数为MapCount * NodeCount\[0] = 10 * 5 = 50。
用于自定义神经网络体系结构的 Net# 语言由 Microsoft 的 Shon Katzenberger(架构师,机器学习)和 Alexey Kamenev(软件工程师,Microsoft Research)开发。 在内部,其用于机器学习项目和应用程序,其范围包括从映像检测到文本分析。 有关详细信息,请参阅 Neural Nets in Azure ML - Introduction to Net#(Azure ML 中的神经网络 - Net# 简介)
有关 Azure 机器学习的 Net# 神经网络规范语言的指南的更多相关文章
- Azure机器学习入门(二)创建Azure机器学习工作区
我们将开始深入了解如何使用Azure机器学习的基本功能,帮助您开始迈向Azure机器学习的数据科学家之路. Azure ML Studio (Azure Machine Learning Studio ...
- Azure机器学习入门(四)模型发布为Web服务
接Azure机器学习(三)创建Azure机器学习实验,下一步便是真正地将Azure机器学习的预测模型发布为Web服务.要启用Web服务发布任务,首先点击底端导航栏的运行即"Run" ...
- 微软推 Azure 机器学习工具:Algorithm Cheat Sheet
微软推 Azure 机器学习工具:Algorithm Cheat Sheet [日期:2015-05-15] 来源:CSDN 作者:Linux [字体:大 中 小] Azure Machine ...
- Azure机器学习入门(一)
我们开始深入学习Azure机器学习的基本原理并为您开启伟大的数据科学之门.Azure 机器学习的一个重要特征就是在构建预测分析方案时,它能够方便地将开发模式集成为可重复的工作流模式.这就使得Azure ...
- Azure机器学习入门(三)创建Azure机器学习实验
在此动手实践中,我们将在Azure机器学习Studio中一步步地开发预测分析模型,首先我们从UCI机器学习库的链接下载普查收入数据集的样本并开始动手实践: http://archive.ics.uci ...
- Microsoft宣布为Power BI提供AI模型构建器,关键驱动程序分析和Azure机器学习集成
微软的Power BI现在是一种正在大量结合人工智能(AI)的商业分析服务,它使用户无需编码经验或深厚的技术专长就能够创建报告,仪表板等.近日西雅图公司宣布推出几款新的AI功能,包括图像识别和文本分析 ...
- 图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1 欢迎fork欢迎三连!文章篇幅有限, ...
- Unix和Linux下C语言学习指南
转自:http://www.linuxdiyf.com/viewarticle.php?id=174074 Unix和Linux下C语言学习指南 引言 尽管 C 语言问世已近 30 年,但它的魅力仍未 ...
- Python神经网络集成技术Guide指南
Python神经网络集成技术Guide指南 本指南将介绍如何加载一个神经网络集成系统并从Python运行推断. 提示 所有框架的神经网络集成系统运行时接口都是相同的,因此本指南适用于所有受支持框架(包 ...
随机推荐
- ThinkPHP 3.2.3+ORACLE插入数据BUG修复及支持获取自增Id的上次记录
TP+ORACLE插入数据BUG修复以及获取自增Id支持getLastInsID方法 这些天在做Api接口时候,发现用TP操作Oracle数据库,发现查询修改删除都能执行, 但一旦执行插入操作老是报错 ...
- 别人的Linux私房菜(14)Linux账号管理和ACL权限设置
用户标识符UID.GID 用户的账号信息,主要是指UID对应.组和GID对应 检查系统中是否存在用户bin:id bin 登录shell验证账号密码的步骤:找到/etc/passwd核对是否存在账号, ...
- 绕过D盾的php一句话
d_dun.php <?php $a = '小狗狗你好啊'; $b = '小盾盾你好啊'; foreach ($_REQUEST as $key => $value) { $$key = ...
- python可能会用到的网络基础
网络编程 1.两种构架:(1)C/S构架:client, server (2) B/S构架:browser,server 2.地址相关:(1)MAC地址,物理地址,唯一,但可以更改 (2)ip地址,网 ...
- ceph删除pool提示(you must first set the mon_allow_pool_delete config option to true)解决办法
现象: 1.在mon节点打开/etc/ceph/ceph.conf,增加以下 2.重启ceph-mon systemctl restart ceph-mon.target 3.删除pool [root ...
- linux (ubuntu) 命令学习笔记
1, md5sum 输出字符串的MD5值 echo -n 123456 | md5sum //-n表示不打印回车符 2, ubuntu设置dock任务栏鼠标点击效果 16.04: 调整位置:gsett ...
- Unity自动生成AnimatorController
上一篇写了如何自动切割动画,这一篇写如何自动生成AnimatorController. 之前网上查了很多资料,看的一直很蒙,看不懂是怎么回事的,这里我先给大家明确几个概念: 画的不好,大家将就着看,写 ...
- c刷题
1.转义字符: C中定义了一些字母前加 "\" 来表示常见的那些不能显示的ASCII字符,如\0 空字符,\r 回车, \n换行等,就称为转义字符,因为后面的字符,都不是它本来的A ...
- const_cast的用法与测试
在C++里,把常量指针(即指向长脸的指针)赋值给非常量指针时,会提示错误,这时候就需要用到const_cast,看下面的两个转换情形: int j = 0; const int i = j; int ...
- eclipse项目无故报错,markers信息为An error occurred while filtering resources
eclipse项目无故报错,markers信息为An error occurred while filtering resources 描述:eclipse项目和resource文件上有红色的叉,其m ...