Scrapy实现腾讯招聘网信息爬取【Python】
一.腾讯招聘网
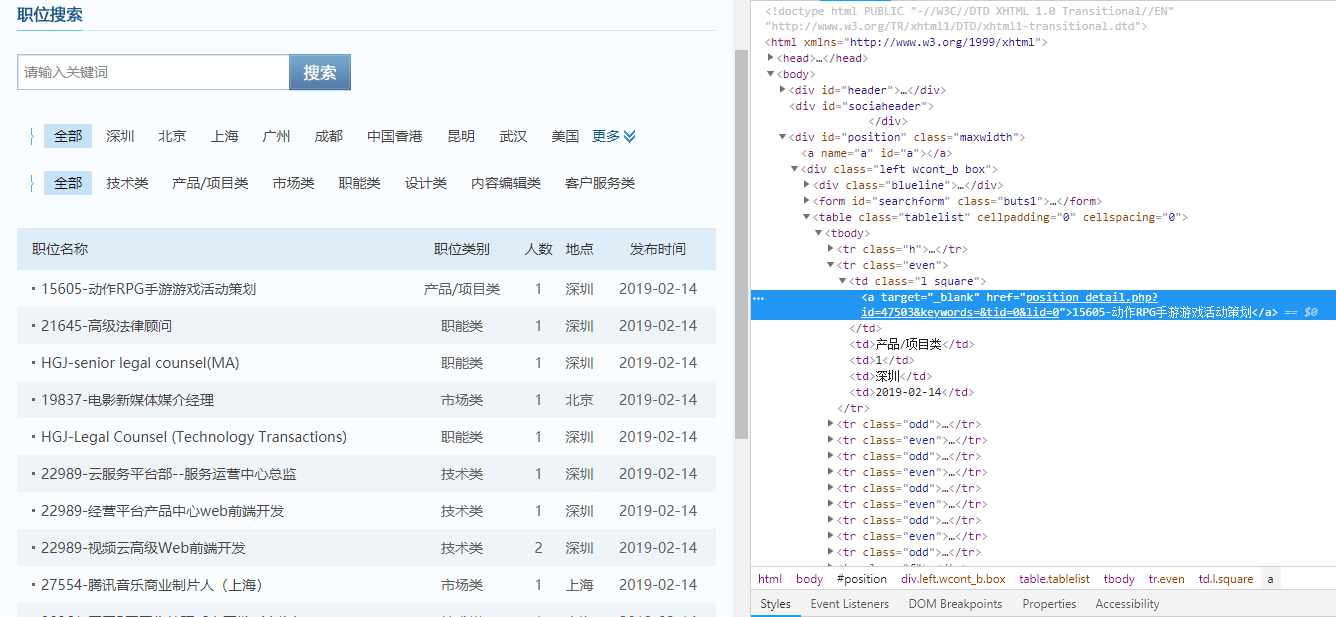
二.代码实现
1.spider爬虫
- # -*- coding: utf-8 -*-
- import scrapy
- from Tencent.items import TencentItem
- class TencentSpider(scrapy.Spider):
- name = 'tencent'
- allowed_domains = ['tencent.com']
- base_url = 'https://hr.tencent.com/position.php?&start='
- offset = 0
- start_urls = [base_url + str(offset)]
- def parse(self, response):
- node_list = response.xpath("//tr[@class='even'] | //tr[@class='odd']")
- for node in node_list:
- # 创建Item对象来保存信息
- item = TencentItem()
- positionName = node.xpath("./td[1]/a/text()").extract()[0]
- if len(node.xpath("./td[2]/text()")):
- positionType = node.xpath("./td[2]/text()").extract()[0]
- else:
- positionType = ""
- positionNumber = node.xpath("./td[3]/text()").extract()[0]
- location = node.xpath("./td[4]/text()").extract()[0]
- publishTime = node.xpath("./td[5]/text()").extract()[0]
- # 保存到item中
- item['positionName'] = positionName
- item['positionType'] = positionType
- item['positionNumber'] = positionNumber
- item['location'] = location
- item['publishTime'] = publishTime
- yield item
- # 判断是否需要拼接下一页路径
- if self.offset < 2770:
- self.offset += 10
- # 拼接下一页路径
- url = self.base_url + str(self.offset)
- # dont_filter=True 禁止因域名不同而过滤
- yield scrapy.Request(url, callback=self.parse)
2.管道
- # -*- coding: utf-8 -*-
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
- import json
- class TencentPipeline(object):
- def __init__(self):
- self.f = open("Tencent.json", "w")
- def process_item(self, item, spider):
- text = json.dumps(dict(item), ensure_ascii=False) + ",\n"
- self.f.write(text)
- return item
- def close_spider(self, spider):
- self.f.close()
3.实体
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- class TencentItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- # 职位名称
- positionName = scrapy.Field()
- # 职位类别
- positionType = scrapy.Field()
- # 人数
- positionNumber = scrapy.Field()
- # 地点
- location = scrapy.Field()
- # 发布时间
- publishTime = scrapy.Field()
三.结果【部分展示】
- {"positionName": "15605-动作RPG手游游戏活动策划", "positionType": "产品/项目类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "21645-高级法律顾问", "positionType": "职能类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "HGJ-senior legal counsel(MA)", "positionType": "职能类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "19837-电影新媒体媒介经理", "positionType": "市场类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "HGJ-Legal Counsel (Technology Transactions)", "positionType": "职能类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "22989-云服务平台部--服务运营中心总监", "positionType": "技术类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "22989-经营平台产品中心web前端开发", "positionType": "技术类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "22989-视频云高级Web前端开发", "positionType": "技术类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "27554-腾讯音乐商业制片人(上海)", "positionType": "市场类", "positionNumber": "", "location": "上海", "publishTime": "2019-02-14"},
- {"positionName": "30361-天天P图图像处理后台开发(上海)", "positionType": "技术类", "positionNumber": "", "location": "上海", "publishTime": "2019-02-14"},
- {"positionName": "15573-MMORPG UE4手游资深美术3D设计(上海)", "positionType": "设计类", "positionNumber": "", "location": "上海", "publishTime": "2019-02-14"},
- {"positionName": "15573-MMORPG UE4手游3D动画设计师(上海)", "positionType": "设计类", "positionNumber": "", "location": "上海", "publishTime": "2019-02-14"},
- {"positionName": "15573-MMORPG UE4手游3D特效美术师(上海)", "positionType": "设计类", "positionNumber": "", "location": "上海", "publishTime": "2019-02-14"},
- {"positionName": "15573-MMORPG UE4手游交互设计师(上海)", "positionType": "设计类", "positionNumber": "", "location": "上海", "publishTime": "2019-02-14"},
- {"positionName": "AQ-产品安全经理(深圳)", "positionType": "职能类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "AQ-产品安全经理(广州)", "positionType": "职能类", "positionNumber": "", "location": "广州", "publishTime": "2019-02-14"},
- {"positionName": "29050-数据安全经理/专家(深圳)", "positionType": "职能类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "29050-数据安全经理/专家(北京)", "positionType": "职能类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "AQ-行业合作经理(北京)", "positionType": "职能类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "AQ-行业合作经理(深圳)", "positionType": "职能类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "27553-腾讯音乐人曲库运营", "positionType": "内容编辑类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "22086-体育号创作平台产品经理", "positionType": "产品/项目类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "22086-体育号CP管理产品经理 ", "positionType": "产品/项目类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "22086-体育号内容质量产品经理", "positionType": "产品/项目类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "28297-二次元手游本地化策划(深圳)", "positionType": "产品/项目类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "GY0-腾讯云海外商务拓展", "positionType": "市场类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "PCG10-高级产品经理(工具产品方向)", "positionType": "产品/项目类", "positionNumber": "", "location": "成都", "publishTime": "2019-02-14"},
- {"positionName": "18432-策略分析师", "positionType": "产品/项目类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "18432-基金高级分析师", "positionType": "产品/项目类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "21309-在线教育运营专家/增长黑客", "positionType": "产品/项目类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "28481-高级医疗商务拓展经理(北京)", "positionType": "市场类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "21882-高级医学编辑(深圳/北京)", "positionType": "内容编辑类", "positionNumber": "", "location": "北京", "publishTime": "2019-02-14"},
- {"positionName": "18402-MMO手游-平台渠道运营", "positionType": "产品/项目类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "28170-腾讯游戏直播业务管理经理(深圳)", "positionType": "产品/项目类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "28170-腾讯游戏直播内容品牌经理(深圳)", "positionType": "市场类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "PCG10-浏览器阅读中心后台开发工程师(深圳)", "positionType": "技术类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
- {"positionName": "PCG10-浏览器阅读中心前端开发工程师(深圳)", "positionType": "技术类", "positionNumber": "", "location": "深圳", "publishTime": "2019-02-14"},
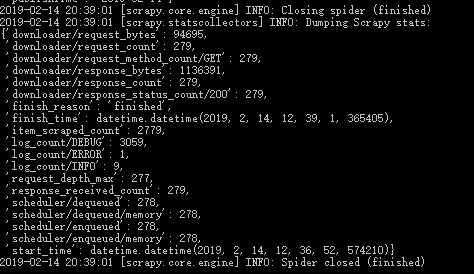
四.详情
Scrapy实现腾讯招聘网信息爬取【Python】的更多相关文章
- 腾讯招聘网数据爬取存入mongodb
#!/user/bin/env python3 # -*- coding: utf-8 -*- import requests from lxml import etree from math imp ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
随机推荐
- Spring概况(一)
spring是什么? spring是一个开源框架,最初是为了解决企业应用开发的复杂性而创建的,但现在已经不止应用于企业应用. 是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架. - 从大 ...
- iOS逆向开发(5):微信强制升级的突破 | 多开 | 微信5.0
接下来的几篇文章,小程以微信为例,实战地演示一下:如何注入iOS的APP.其中使用到的知识,基本在前面的文章中都有介绍到. 小白:小程,我想用回旧版本的微信! 小程:为什么要用旧版本微信呢? 小白:你 ...
- Spring Boot中使用断路器
断路器本身是电路上的一种过载保护装置,当线路中有电器发生短路时,它能够及时的切断故障电路以防止严重后果发生.通过服务熔断(也可以称为断路).降级.限流(隔离).异步RPC等手段控制依赖服务的延迟与失败 ...
- linux服务器部署tomcat和Nginx
项目需要,申请了三台测试机器,好在测试机里面光秃秃的什么都没有,我就可以好好的学习一把玩一把了!接下来以图文的形式讲一下我所碰到的坑以及小小的收获吧! 一.准备工作 首先你得有一台可以玩的linux服 ...
- solr查询工作原理深入内幕
1.什么是Lucene? 作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用, ...
- man nfsd(rpc.nfsd中文手册)
本人译作集合:http://www.cnblogs.com/f-ck-need-u/p/7048359.html rpc.nfsd() System Manager's Manual rpc.nfsd ...
- 第一册:lesson sixty nine.
原文: The car race. There is a car race near our town every year. In 1995 ,there was a very big race. ...
- java通过Access_JDBC30读取access数据库时无法获取最新插入的记录
1.编写了一个循环程序,每几秒钟读取一次,数据库中最新一行数据 连接access数据库的方法和查询的信息.之后开一个定时去掉用. package javacommon.util; import jav ...
- SSM 设置静态资源处理
使用weblogic的虚拟路径virtual-directory-mapping 在页面上展示文件服务器上的图片 <weblogic-web-app> ......省略其他部分 <c ...
- Hibernate入门(九)级联删除
Hibernate级联删除 上一篇文章学习了级联保存和更新,这个级联删除应该很好理解的.一样的道理,删除一方,同时删除有关联的一方. https://www.cnblogs.com/deepSleep ...