Lucene入门学习
技术原理:
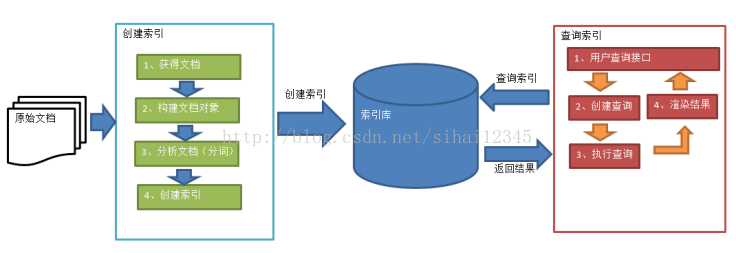
开发环境:
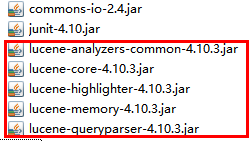
lucene包:分词包,核心包,高亮显示(highlight和memory),查询包。(下载请到官网去查看,如若下载其他版本,请看我的上篇文档,在luke里面)
原文文档:
入门程序:
package com.itheima.lucene; import java.io.File;
import java.io.FileReader; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version; /**
*
* @author *
*/
public class Test1 { //创建索引
public static void index() {
IndexWriter indexWriter = null; try {
// 1、创建Directory
//JDK 1.7以后 open只能接收Path
Directory directory = FSDirectory.open(new File("E:\\spider\\index"));
// 2、创建IndexWriter
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
indexWriter = new IndexWriter(directory, config);
indexWriter.deleteAll();//清除以前的index
//要搜索的File路径
File dFile = new File("E:\\spider\\2018-12-26");
File[] files = dFile.listFiles();
for (File file : files) {
// 3、创建Document对象
Document document = new Document();
// 4、为Document添加Field
// 第三个参数是FieldType 但是定义在TextField中作为静态变量,看API也不好知道怎么写
document.add(new Field("content", new FileReader(file), TextField.TYPE_NOT_STORED));
document.add(new Field("filename", file.getName(), TextField.TYPE_STORED));
document.add(new Field("filepath", file.getAbsolutePath(), TextField.TYPE_STORED)); // 5、通过IndexWriter添加文档到索引中
indexWriter.addDocument(document);
} } catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (indexWriter != null) {
indexWriter.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
//搜索
public static void search(String keyWord) {
DirectoryReader directoryReader = null;
try {
// 1、创建Directory
Directory directory = FSDirectory.open(new File("E:\\spider\\index"));
// 2、创建IndexReader
directoryReader = DirectoryReader.open(directory);
// 3、根据IndexReader创建IndexSearch
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
// 4、创建搜索的Query
Analyzer analyzer = new StandardAnalyzer();
// 创建parser来确定要搜索文件的内容,第一个参数为搜索的域
QueryParser queryParser = new QueryParser("content", analyzer);
// 创建Query表示搜索域为content包含UIMA的文档
Query query = queryParser.parse(keyWord);
// 5、根据searcher搜索并且返回TopDocs
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("查找到的文档总共有:"+topDocs.totalHits);
// 6、根据TopDocs获取ScoreDoc对象
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 7、根据searcher和ScoreDoc对象获取具体的Document对象
Document document = indexSearcher.doc(scoreDoc.doc);
// 8、根据Document对象获取需要的值
System.out.println("文件名:"+document.get("filename") + " " +"文件路径:"+ document.get("filepath"));
System.out.println("-----------------------------------------");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (directoryReader != null) {
directoryReader.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
//主方法
public static void main(String args[]) {
index(); search("java");//搜索带 java语汇单元的信息。(单词)
}
}
结果显示:

(学习路径还很长,不要捉急慢慢来)。
Lucene入门学习的更多相关文章
- Lucene入门学习二
接上篇:增删改查 增加:这里不做过多阐述. 删除:删除全部,根据条件删除 修该:先删除,后添加 查询(*):查询所有,精确查询,根据数值范围查询,组合查询,解析查询. package com.ithe ...
- Lucene.net入门学习
Lucene.net入门学习(结合盘古分词) Lucene简介 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全 ...
- Lucene.net入门学习系列(2)
Lucene.net入门学习系列(2) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 在使用Luce ...
- Lucene.net入门学习系列(1)
Lucene.net入门学习系列(1) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 这几天在公 ...
- Elasticsearch7.X 入门学习第五课笔记---- - Mapping设定介绍
原文:Elasticsearch7.X 入门学习第五课笔记---- - Mapping设定介绍 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本 ...
- Elasticsearch7.X 入门学习第一课笔记----基本概念
原文:Elasticsearch7.X 入门学习第一课笔记----基本概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https: ...
- vue入门学习(基础篇)
vue入门学习总结: vue的一个组件包括三部分:template.style.script. vue的数据在data中定义使用. 数据渲染指令:v-text.v-html.{{}}. 隐藏未编译的标 ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
随机推荐
- SpringCloud无废话入门04:Hystrix熔断器及监控
1.断路器(Circuit Breaker)模式 在上文中,我们人为停掉了一个provider,在实际的生产环境中,因为意外某个服务down掉,甚至某一层服务down掉也是会是有发生的.一旦发生这种情 ...
- Java数据结构和算法(五)——队列
队列.queue,就是现实生活中的排队. 1.简单队列: public class Queqe { private int array[]; private int front; private in ...
- SSE图像算法优化系列二十四: 基于形态学的图像后期抗锯齿算法--MLAA优化研究。
偶尔看到这样的一个算法,觉得还是蛮有意思的,花了将近10天多的时间研究了下相关代码. 以下为百度的结果:MLAA全称Morphological Antialiasing,意为形态抗锯齿是AMD推出的完 ...
- shell编程学习笔记(九):Shell中的case条件判断
除了可以使用if条件判断,还可以使用case 以下蓝色字体部分为Linux命令,红色字体的内容为输出的内容: # cd /opt/scripts # vim script08.sh 开始编写scrip ...
- 数据库的范式,第一、二、三、四、五范式、BC范式
数据库的规范化(上一篇博客有写到)的程度不同,便有了这么多种范式.数据库范式是数据库设计必不可少的知识,没有对范式的理解,就无法设计出高效率.优雅的数据库,甚至设计出错误误的数据库.课本中的定义比较抽 ...
- 【C++】C++中typedef、auto与decltype的作用
typedef 类型别名(type alias)是一个名字,使用typedef不会真正地创建一种新的数据类型,它只是已经存在数据类型的一个新名称.语法: typedef type name; 其中ty ...
- (原创)Rocketmq分布式消息队列的部署与监控
-------------------------------------------------------------------------------------------- 一.Rocke ...
- Cocos Lua的Touch 点击事件添加
两种方式: -- 触摸开始 local function onTouchBegan(touch, event) return true end -- 触摸结束 local function onTou ...
- Android PopupWindow 仿微信弹出效果
项目中,我须要PopupWindow的时候特别多,这个东西也特别的好使,所以我今天给大家写一款PopupWindow 仿微信弹出效果.这样大家直接拿到项目里就能够用了! 首先让我们先看效果: 那么我首 ...
- 每天进步一点点——mysql——mysqlbinlog
一. 简单介绍 mysqlbinlog:用于查看server生成的二进制日志的工具. 二. 命令格式 mysqlbinlog 选项日志文件1 三. 经常使用參数 ...