Semaphore 与ThreadPoolExecutor 的使用
1、 Semaphore 信号量 (阻塞)
优点:可以控制线程的数量,不会超出线程范围
缺点:当线程死锁时,永远没法释放,导致一直阻塞
在java中,提供了信号量Semaphore的支持。
Semaphore类是一个计数信号量,必须由获取它的线程释放,
通常用于限制可以访问某些资源(物理或逻辑的)线程数目。
一个信号量有且仅有3种操作,且它们全部是原子的:初始化、增加和减少
增加可以为一个进程解除阻塞;
减少可以让一个进程进入阻塞。
如何获得Semaphore对象?
public Semaphore(int permits,boolean fair)
permits:初始化可用的许可数目。
fair: 若该信号量保证在征用时按FIFO 先进先出的顺序授予许可,则为true,否则为false;
如何从信号量获得许可?
public void acquire() throws InterruptedException
如何释放一个许可,并返回信号量?
public void release()
使用方法:
private static final Semaphore coImpInfoMutex = new Semaphore(5); // 定义五个信号量
try {
logger.info("wait for permit");
coImpInfoMutex.acquire(); // 获取信号new Thread(new Runnable() {
@Override
public void run() {
try {
// doing ....
} finally {
coImpInfoMutex.release(); // 必须释放讯号
}
}
}).start();
} catch (InterruptedException e) {
e.printStackTrace();
}
1.使用线程池的好处?
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
2.ThreadPoolExecutor的使用
A.线程池的创建
我们可以通过java.util.concurrent.ThreadPoolExecutor来创建一个线程池。
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, milliseconds,runnableTaskQueue, handler);
创建线程池需要的参数介绍:
corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。 可以选择以下几个阻塞队列。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
maximumPoolSize(线程池最大大小):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。以下是JDK1.5提供的四种策略。
- AbortPolicy:直接抛出异常。
- CallerRunsPolicy:只用调用者所在线程来运行任务。
- DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
- DiscardPolicy:不处理,丢弃掉。
- 当然也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。
keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
B.向线程池提交任务
提交任务有execute()和submit()两个方法,下面看看他俩的区别:
①接收参数不同
execute()的参数是Runnable,submit()参数可以是Runnable,也可以是Cable。
②返回值不同
execute()没有返回值,submit()有返回值Future。通过Future可以获取各个线程的完成情况,是否有异常,还能试图取消任务的执行。详见》》》》》》》》
execute()很好理解,下面看个使用submit()获取返回值的例子,假设我有很多更新各种数据的task,我希望如果其中一个task失败,其它的task就不需要执行了。那我就需要catch Future.get抛出的异常,然后终止其它task的执行,代码如下:
public class ThreadPoolTest implements Runnable {
public void run() {
try{
System.out.println(Thread.currentThread().getName());
Thread.sleep(3000);
}catch (InterruptedException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
BlockingQueue<Runnable> queue = new LinkedBlockingQueue<Runnable>();
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 6, 1, TimeUnit.DAYS, queue);
for (int i = 0; i < 10; i++) {
executor.execute(new Thread(new ThreadPoolTest(), "TestThread".concat(""+i)));
int threadSize = queue.size();
System.out.println("线程队列大小为-->"+threadSize);
}
executor.shutdown();
}
}
c.线程池的关闭
我们可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池,它们的区别详见 http://www.cnblogs.com/shamo89/p/6703563.html
可以简单的总结为shutdown()是正常结束线程池,已经添加进去正在执行的线程正常执行,没添加的线程不会再添加。shutdownNow()则是强制中断线程池里的线程,但是因为是通过interuppt()来执行的,所以会有局限性,另外该方法会返回未执行的任务。
所以通常调shutdown来正常关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow。
23. 线程池的分析
A.流程分析:线程池的主要工作流程如下图:
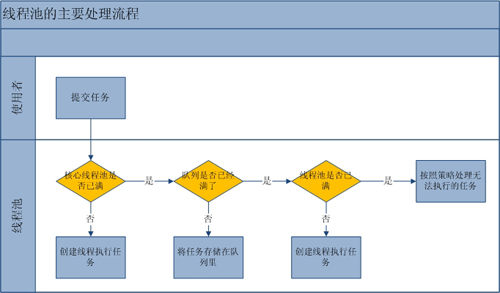
从上图我们可以看出,当提交一个新任务到线程池时,线程池的处理流程如下:
- 首先线程池判断基本线程池是否已满?没满,创建一个工作线程来执行任务。满了,则进入下个流程。
- 其次线程池判断工作队列是否已满?没满,则将新提交的任务存储在工作队列里。满了,则进入下个流程。
- 最后线程池判断整个线程池是否已满?没满,则创建一个新的工作线程来执行任务,满了,则交给饱和策略来处理这个任务。
B.源码分析
上面的流程分析让我们很直观的了解了线程池的工作原理,让我们再通过源代码来看看是如何实现的。线程池执行任务的方法如下:

1 public void execute(Runnable command) {
2 if (command == null)
3 throw new NullPointerException();
4 //如果线程数小于基本线程数,则创建线程并执行当前任务
5 if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
6 //如线程数大于等于基本线程数或线程创建失败,则将当前任务放到工作队列中。
7 if (runState == RUNNING && workQueue.offer(command)) {
8 if (runState != RUNNING || poolSize == 0)
9 ensureQueuedTaskHandled(command);
10 }
11 //如果线程池不处于运行中或任务无法放入队列,并且当前线程数量小于最大允许的线程数量,
12 // 则创建一个线程执行任务。
13 else if (!addIfUnderMaximumPoolSize(command))
14 //抛出RejectedExecutionException异常
15 reject(command); // is shutdown or saturated
16 }
17 }
2.4. 合理的配置线程池
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
- 任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
- 任务的优先级:高,中和低。
- 任务的执行时间:长,中和短。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。
CPU密集型任务配置尽可能小的线程,如配置Ncpu+1个线程的线程池。
IO密集型任务则由于线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。
混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。
我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
建议使用有界队列,有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点,比如几千。
有一次我们组使用的后台任务线程池的队列和线程池全满了,不断的抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行SQL变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞住,
任务积压在线程池里。
如果当时我们设置成无界队列,线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。
当然我们的系统所有的任务是用的单独的服务器部署的,而我们使用不同规模的线程池跑不同类型的任务,但是出现这样问题时也会影响到其他任务。
2.1. 线程池的监控
通过线程池提供的参数进行监控。线程池里有一些属性在监控线程池的时候可以使用
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量。小于或等于taskCount。
- largestPoolSize:线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过。如等于线程池的最大大小,则表示线程池曾经满了。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,池里的线程不会自动销毁,所以这个大小只增不+ getActiveCount:获取活动的线程数。
3、线程ThreadPoolTaskExecutor的使用
// 配合spring使用
<bean id="taskExecutor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="30" />
<property name="keepAliveSeconds" value="200" />
<property name="maxPoolSize" value="50" />
</bean>
Semaphore 与ThreadPoolExecutor 的使用的更多相关文章
- Semaphore最详细解析
官方解释: 一个计数信号量.在概念上,信号量维持一组许可证.如果有必要,每个acquire()都会阻塞,直到许可证可用,然后才能使用它.每个release()添加许可证,潜在地释放阻塞获取方.但是,没 ...
- Java Concurrent之 AbstractQueuedSynchronizer
ReentrantLock/CountDownLatch/Semaphore/FutureTask/ThreadPoolExecutor的源码中都会包含一个静态的内部类Sync,它继承了Abstrac ...
- 【转】Java并发的AQS原理详解
申明:此篇文章转载自:https://juejin.im/post/5c11d6376fb9a049e82b6253写的真的很棒,感谢老钱的分享. 打通 Java 任督二脉 —— 并发数据结构的基石 ...
- Java并发编程原理与实战十九:AQS 剖析
一.引言在JDK1.5之前,一般是靠synchronized关键字来实现线程对共享变量的互斥访问.synchronized是在字节码上加指令,依赖于底层操作系统的Mutex Lock实现.而从JDK1 ...
- cas aqs lock之间的关系
CAS 对应cpu的硬件指令, 是最原始的原子操作 cas主要是在AtomicInteger AtomicXXX类中使用, 用于实现线程安全的自增操作 ++. 对应一个unsafe对象, 根据os平台 ...
- Java 并发包中的高级同步工具
Java 并发包中的高级同步工具 Java 中的并发包指的是 java.util.concurrent(简称 JUC)包和其子包下的类和接口,它为 Java 的并发提供了各种功能支持,比如: 提供了线 ...
- 源码级深挖AQS队列同步器
我们知道,在java中提供了两类锁的实现,一种是在jvm层级上实现的synchrinized隐式锁,另一类是jdk在代码层级实现的,juc包下的Lock显示锁,而提到Lock就不得不提一下它的核心队列 ...
- 并发编程 13—— 线程池的使用 之 配置ThreadPoolExecutor 和 饱和策略
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- Java线程池之ThreadPoolExecutor
前言 线程池可以提高程序的并发性能(当然是合适的情况下),因为对于没有线程的情况下,我们每一次提交任务都新建一个线程,这种方法存在不少缺陷: 1. 线程的创建和销毁的开销非常高,线程的创建需要时间, ...
随机推荐
- centos7 下安装pycharm
CentOS 7环境下Pycharm安装流程记录: 1.准备安装文件: 方法1: 使用内置火狐浏览器访问下载最新格式为tar.gz的压缩包 网址:https://www.jetbrains.com/p ...
- squid代理允许FTP访问设置
# TAG: acl # Defining an Access List ============================= #Default: # acl all src all # #Re ...
- input type="file"多图片上传 原生html传递的数组集合
单个的input type="file"表单也是可以实现多图片上传的 代码如下: <form action="manypic.php" method=&q ...
- Quartz.Net进阶之四:CronTrigger 详述
以前都是将所有的内容放在一篇文章里,就会导致文章很长,对于学习的人来说,有时候这也是一个障碍.所以,以后我的写作习惯,我就会把我写的文章缩短,但是内容不会少,内容更集中.这样,学习起来也不会很累,很容 ...
- HTML中调用JavaScript的几种情况和规范写法
JavaScript执行在html中,引用有几种方式? 我知道的方法有3种: 第一种:外部引用远程JavaScript文件.如<script type="text/javascript ...
- 家庭家长本-微信小程序
寒假在家的时候,做了一个简单的网页版家庭账本,后来自己学习了微信小程序的制作方法,现在想做一个微信小程序的家庭记账本. 首先要在微信公众平台注册一个微信小程序的账号,用的邮箱一个只能注册一个微信小程序 ...
- C语言基础课第二次作业
一. 题目7-1 统计学生成绩 1.实验代码 #include<stdio.h> int main(void) { int i,grade,n; ,b=,c=,d=,e=; scanf( ...
- HTML5 添加新的标签 input属性
<!-- 新增 有语意标签 --> <nav></nav> <!-- 导航标签 --> <seclion></seclion> ...
- MFC树形控件的使用(右键点击)
在MFC中,会用到树形控件,这里做下记录. 右键点击 1.添加右键点击事件(NM_RCLICK) 2.获得鼠标在Client的坐标 CPoint point; GetCursorPos(&po ...
- python模块:xml.etree.ElementTree
"""Lightweight XML support for Python. XML is an inherently hierarchical data format, ...