ELK安装使用教程
一、说明
ELK是当下流行的日志监控系统。ELK是Elasticsearch、Logstash、Kibana三个软件的统称。
在ELK日志监控系统中,Logstash负责读取和结构化各类日志+发送给Elasticsearch,Elasticsearch负责存储Logstash发送过来的日志+响应Kibana的查询,Kibana负责从Elasticsearch查询内容+在web界面中向用户展示。
二、ELK安装与启动
ELK看是三个工具,但是都相当于”绿色软件“,基本都是下载解压就能运行了。
1.1 安装jdk
下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
1.2 安装elasticsearch
下载地址:https://www.elastic.co/downloads/elasticsearch
tar -zxf elasticsearch-6.4..tar.gz
cd elasticsearch-6.4./
# 以后台方式启动
bin/elasticsearch -d -p pid.log
# 启动需要点时间,稍等一下再执行下一句
curl http://localhost:9200/
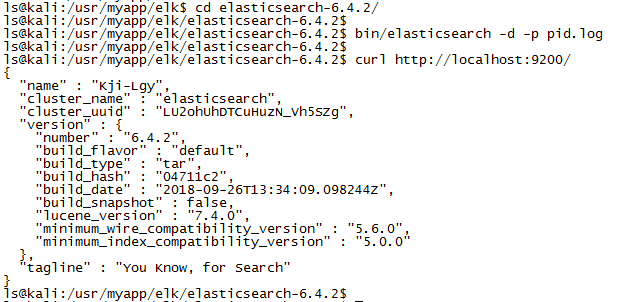
如果有如图json结果返回,那就说明安装成功。
可以弄个启停脚本,省得每次启停都得想一个需不需要带参数带什么参数:
# 启动脚本
echo './elasticsearch -d -p pid.log' > start_elasticsearch
chmod u+x start_elasticsearch
# 停止脚本,直接用kill -9杀除进程
echo 'kill -9 `cat ../pid.log`' > stop_elasticsearch
chmod u+x stop_elasticsearch
1.3 安装logstash
下载地址:https://www.elastic.co/downloads/logstash
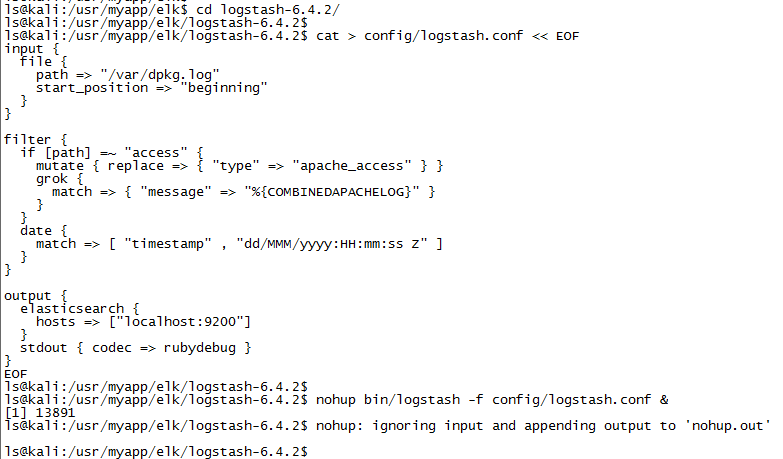
cd logstash-6.4.2/
cat > config/logstash.conf << EOF
input {
file {
path => ["/var/dpkg.log"]
start_position => "beginning"
}
} filter {
if [path] =~ "access" {
mutate { replace => { "type" => "apache_access" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
} output {
elasticsearch {
hosts => ["localhost:9200"]
}
stdout { codec => rubydebug }
}
EOF
nohup bin/logstash -f config/logstash.conf &
可以弄个启停脚本,省得每次启停都得想一个需不需要带参数带什么参数:
# 启动脚本,配置文件名改成自己的
echo 'nohup ./logstash -f ../config/logstash.conf &' > start_logstash
chmod u+x start_logstash
# 杀除进程脚本
echo 'kill -9 `ps -ef |grep logstash |grep -v grep| awk '{print $2}'|head -n 1`' > stop_logstash
chmod u+x stop_logstash
1.4 安装kibana
下载地址:https://www.elastic.co/downloads/kibana
解压后编缉config/kibana.yml,将server.host项修改为本机ip,将elasticsearch.url项赋值为elasticsearch地址。如我这里是:
server.host: "10.10.6.92"
elasticsearch.url: "http://localhost:9200"
保存后启动:
nohup bin/kibana &
启动后默认监听5601端口,使用http://{ip}:5601访问即可,界面如下图所示:

可以直接弄个启停脚本,省得每次启停都得想一个需不需要带参数带什么参数:
# 启动脚本
echo 'nohup ./kibana &' > start_kibana
chmod u+x start_kibana
# 停止脚本,直接用kill -9杀除进程
echo 'kill -9 `ps -ef |grep ./../node/bin|grep -v grep|awk '{print $2}'|head -n 1`' > stop_kibana
chmod u+x stop_kibana
三、ELK具体使用
在上一节中我们对ELK安装配置并运行了起来,这节我们进一步探究ELK更高级的配置和用法。
3.1 logstash配置说明
本节主要参考页面:https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
logstash配置主要就是config/logstash.conf文件中的input/filter/output三大节区,其中input用于指示logstash从何处读取,filter节区指示logstash如何结构化(格式化)输入,output节区指示logstash输出到哪里。这三大节区的成员都是插件,下边分别讲述各节区支持的插件及插件配置。
3.1.1 input节区插件及配置
input节区所有插件参见:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
在1.3节中我们使用的就是file插件,这里就以file插件为例讲解其为什么可以这么配置,还可以怎么配置。
在上边插件页面中点击file插件链接即可进入file插件说明页面,如下所示
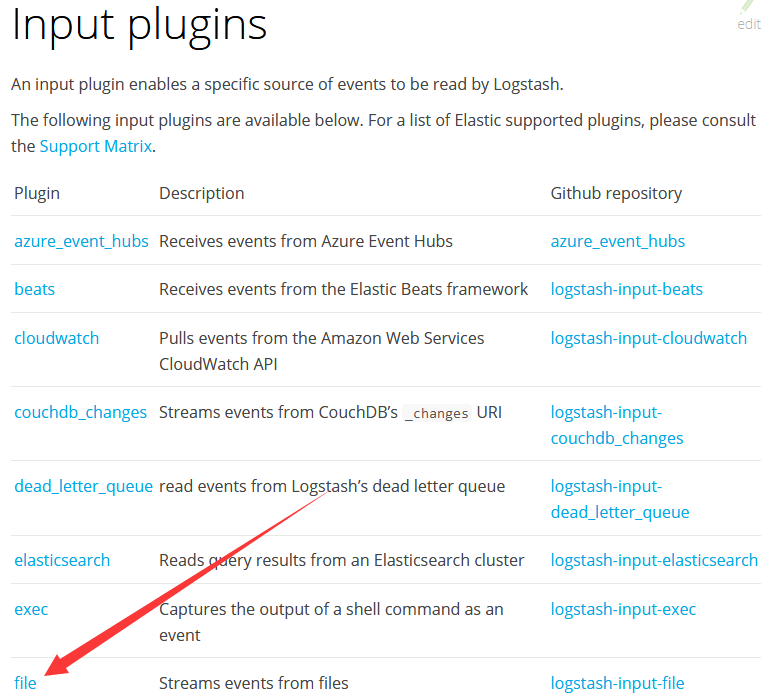
进入后直接下接到"File Input Configuration Options"节(xxx插件就下拉找到xxx Input Configuration Options节)
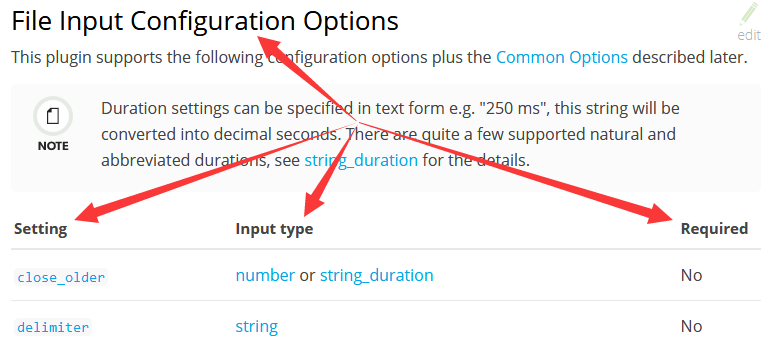
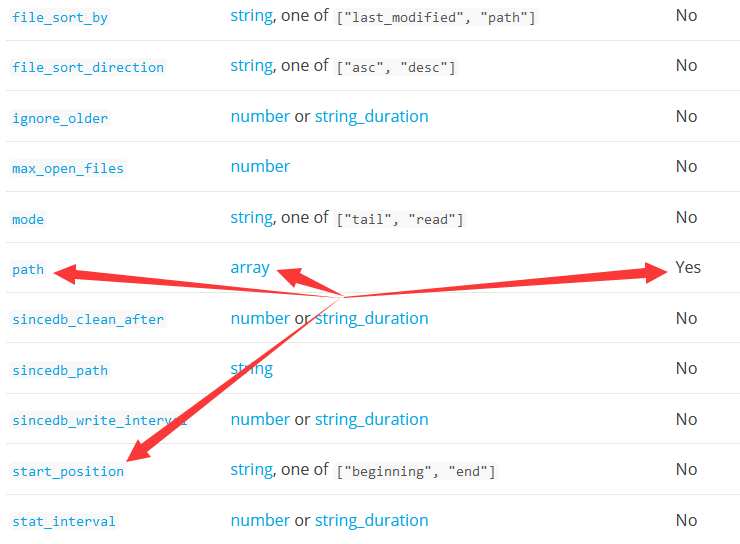
Setting列----插件支持的配置项的名称
Input type列----该配置项的值的格式。包插number(数字)、string(字符串)、array(数组)等几种类型
Required列----该配置项是否必须配置。No表示非必须,Yes表示必须
往下拉可以看到我们前面file插件配置path和start_position,可以看到path是数组类型且是必须的,而start_position是字符串类型(只能是”beginning“或”end“)不是必须的。
再点击配置项链接能跳转到配置项的详细说明。各插件都类似以上步骤查看即可。
input最常用的插件感觉是file和stdin,格式如下:
input {
file {
path => ["/home/ls/test.txt"]
start_position => "beginning"
}
stdin { }
}
3.1.2 filter节区插件及配置
filter节区所有插件参见:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
在1.3中我们配置了mutate、grok和date三个插件,多个插件组成一个插件链;比如这里输入先被mutate处理,再被传到grok处理,再被传到date处理。
所谓的”处理“是一个关键,我们将config/logstash.conf修改为如下内容(表示从标控制台获取输入、不使用任何插件、输出到控制台)并重新启动logstash
input {
stdin { }
}
filter {
}
output {
stdout { codec => rubydebug }
}
我们输入如下一条http访问日志:
127.0.0.1 - - [/Dec/::: -] "GET /xampp/status.php HTTP/1.1" "http://cadenza/xampp/navi.php" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0"
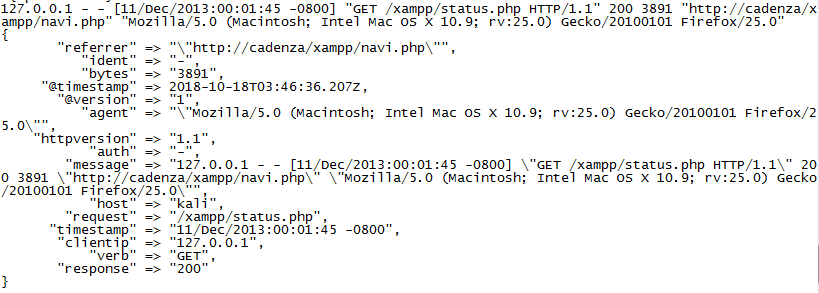
如下{}中的json就是logstash的输出,共message(信息原文)、@version(信息版本)、@timestamp(信息接收时间)、host(信息来源主机)四项。

首先,我们在filter{}中加入以下一个规则(指示以apache日志格式进行解析message项),并重启logstash并再次输入前边的http日志
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
输出结果如下,可以看到在原来那四项的基础上,增加了很多项
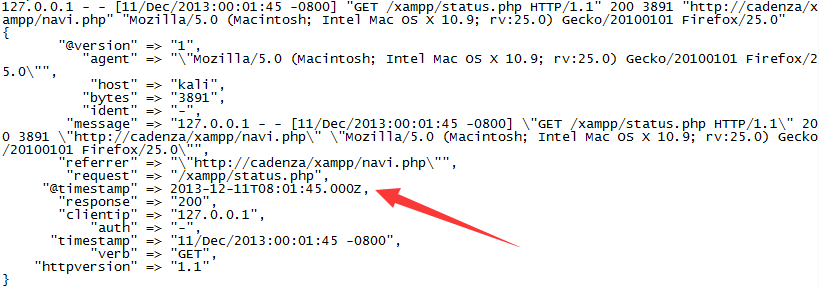
然后,我们在filter{}中再加入以下一个规则(指示以"dd/MMM/yyyy:HH:mm:ss Z"解析timestamp项,并重写为"yyyy-MMM-dd HH:mm:ss Z"格式),并重启logstash并再次输入前边的http日志
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ,"yyyy-MMM-dd HH:mm:ss Z"]
}
可以看到@timestamp项被成功按指定格式重写
最后,在filter{}中再加入以下一个规则(指示新增一个叫new_filed的项,其值为固定值”this is a new field“),此时完整配置文件如下:
input {
stdin { }
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
environment {
add_field => { "new_field" => "this is a new field" }
}
}
output {
stdout { }
}
由于environment插件默认没有安装我们先安装一下(所有插件都可以使用logstash-plugin命令进行管理,类似yum或apt)
bin/logstash-plugin install logstash-filter-environment
此时重启logstash并再次输入前边的http日志再次在控制台输入上边的http访问日志,输出结果如下。可以看到按预期新增了一个叫”new_field“的项
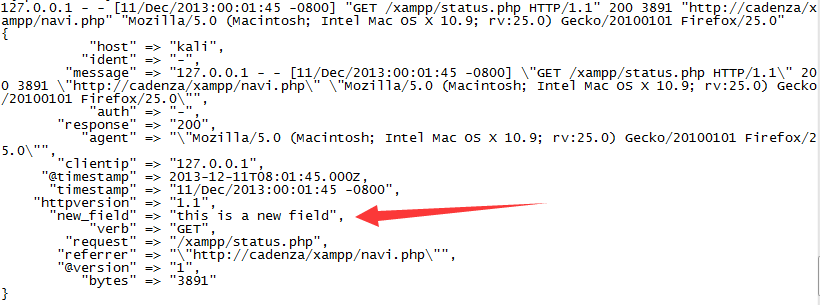
从如上分析可以得出以下结论:
logstash默认对传来的信息进行初步处理,生成message(信息原文)、@version(信息版本)、@timestamp(信息接收时间)、host(信息来源主机)四个键
后面的插件前面的插件生成的结果,以键值对为操作单无,或是修改已有键值对或是新增键值对。
最后,所有filter插件都支持以下选项
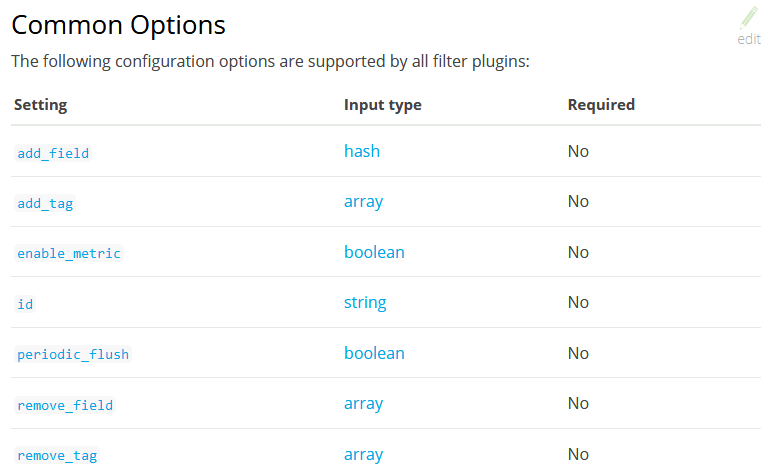
filter最常用的是将非结构化数据进行结构化的grok,由于篇幅较长分离了出去,见后边第四大点“从自定义文件解析IP并可视化”。
3.1.3 ouput节区插件及配置
output节区所有插件参见:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
在ELK中最常用的就是我们1.3中设置的,输出到elasticsearch
elasticsearch {
hosts => ["localhost:9200"]
}
3.2 elasticsearch配置说明
elasticsearch会自动完成数据接收,然后kibana来查询时会自动响应,就单个来说没有其他太多的配置。主要的配置是在集群方面(cluster)但集群没研究所以这里就不介绍了。
另外一个是配听公网地址,elasticsearch默认只监听127.0.0.1,如果要监听其他地址需要打开其config/ elasticsearch.yml,修改network.host的值。比直接监听所有地址:
network.host: 0.0.0.0
但是不是随便改完重启就完了,elasticsearch默认认为当前是开发环境,如果修改network.host监听127.0.0.1以外的地址,那么elasticsearch就认为是迁移到了生产环境。
在开发环境中如果这些项没有按要求配置那么只视为异常,但到生产环境这些项如果没按要求配置那将会被视为错误elasticsearch将拒绝启动。也就是说要修改监听地址成功,除了要修改network.host项还要保证这些项已按要求配置。

3.3 kibana使用操作
在2.4中我们只是把kibana运行起来,虽说kibana接收了elasticsearch的数据,但并没有展示这些数据,下面我们就来介绍如何展示数据。
3.3.1 总体菜单

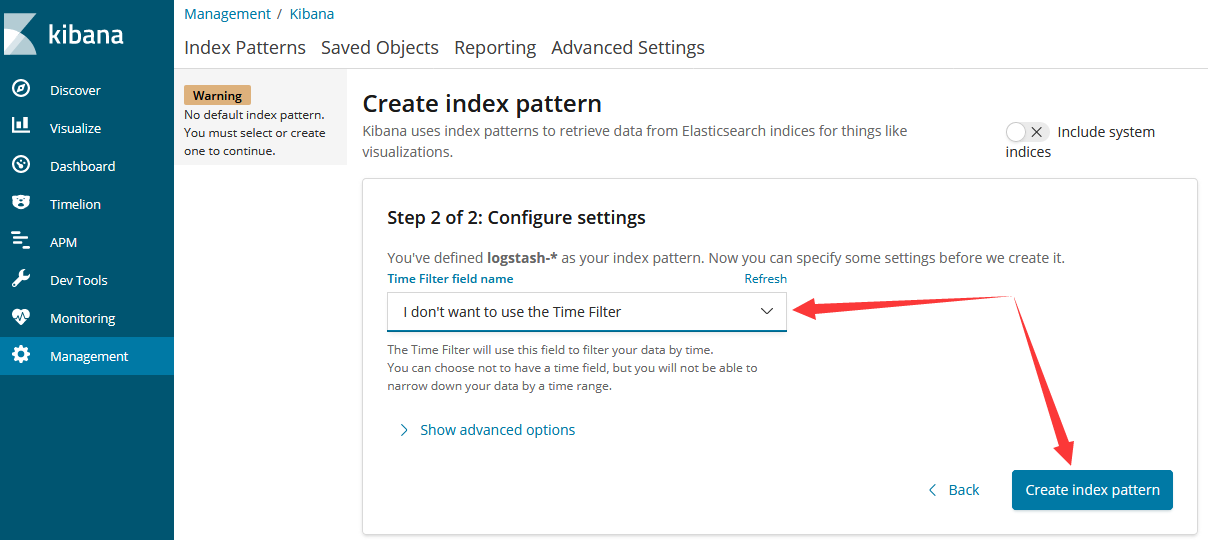
3.3.2 设置索引

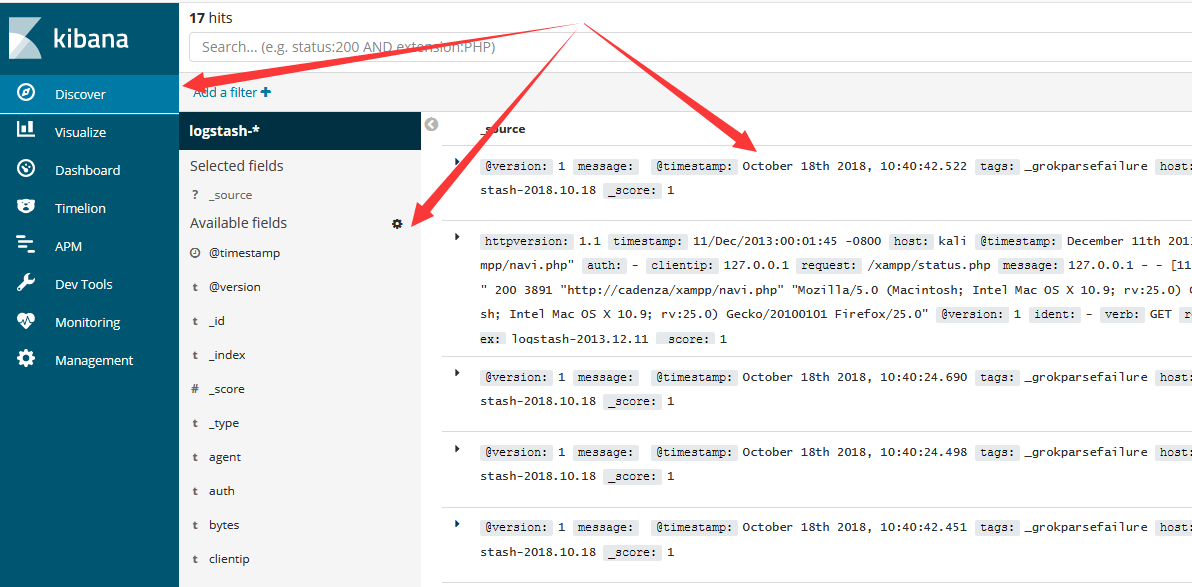
3.3.3 Discover菜单
切换到Discover菜单,默认会显示kinaba接收到的所有数据,”Available fields“那里是当前所有数据出现过的所有项,点击它们可通过他们进行数据筛选。
3.3.4 Visualize菜单
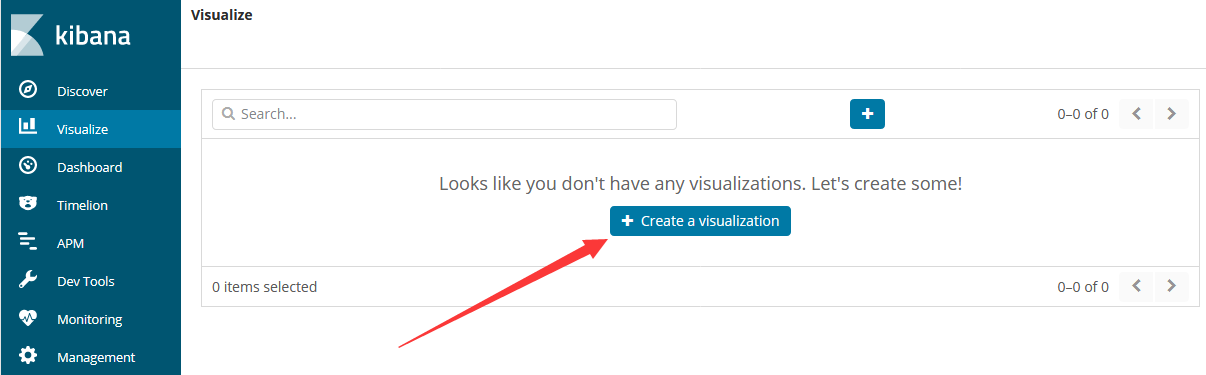
即可看到所有kibana支持的图表,我们这里以pie为例
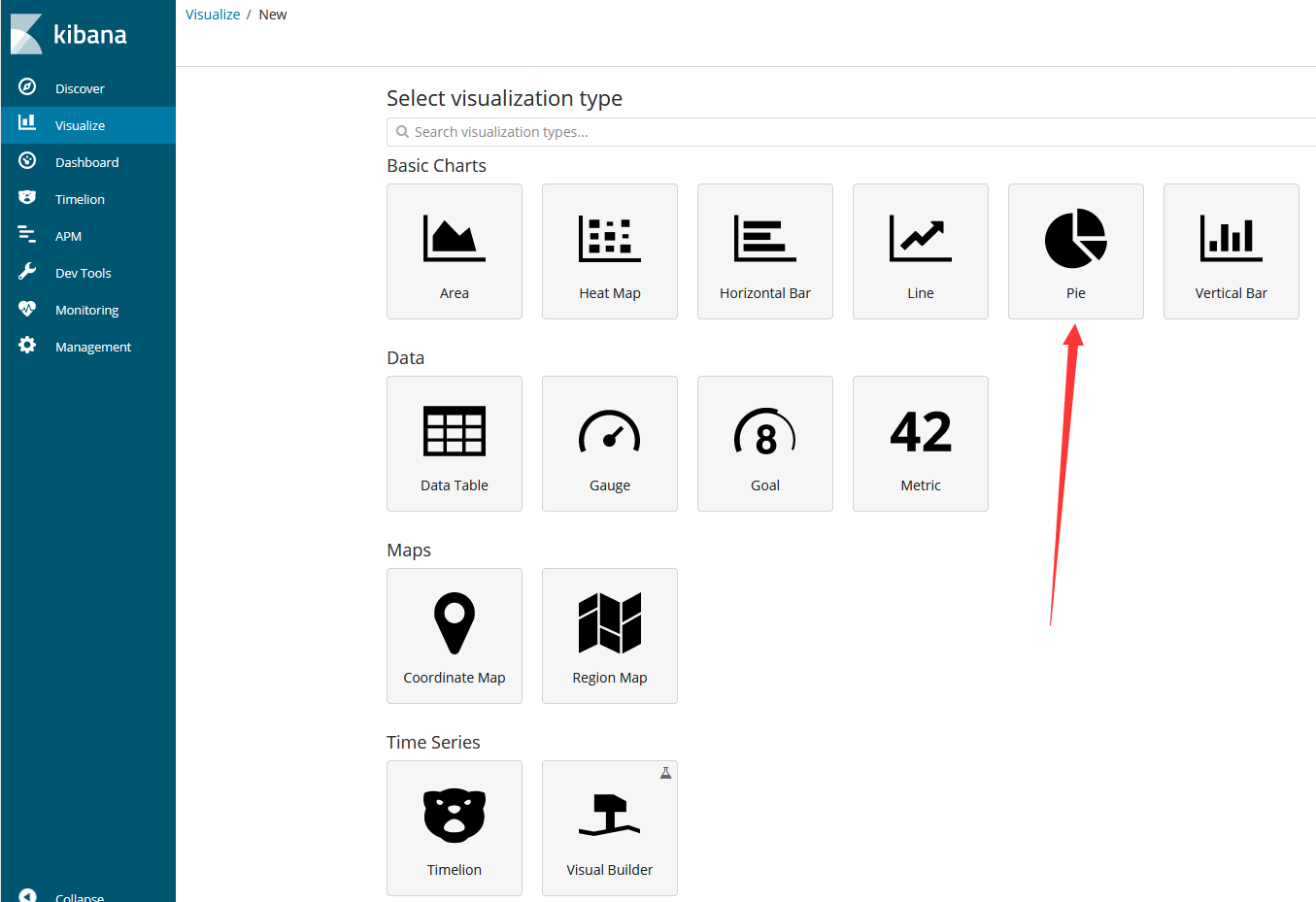
Filter表示输入过滤表达式,筛选出要参与图表绘制的数据集,我们这里直接点下方建议的“logstash-*”(这是我们前面3.2建立索引的所有数据)
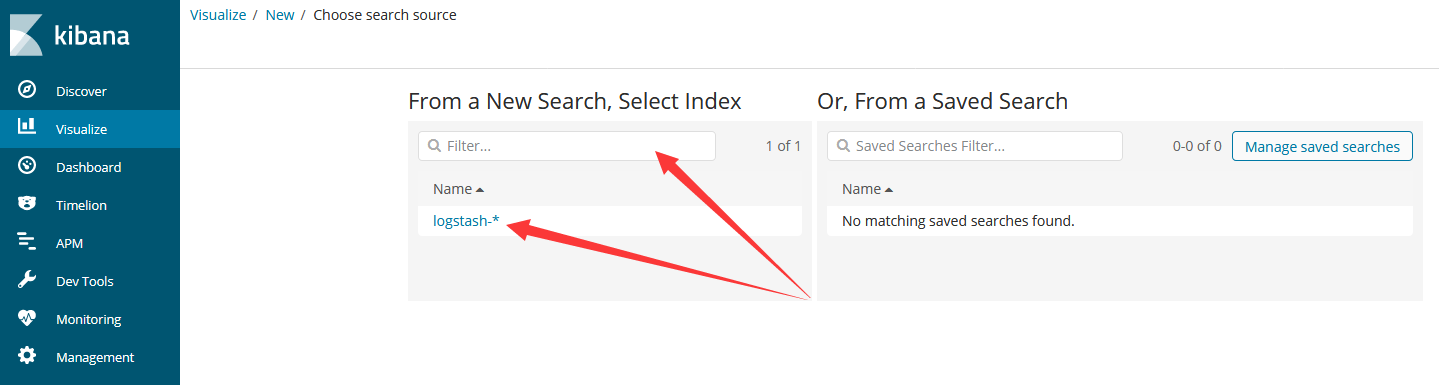
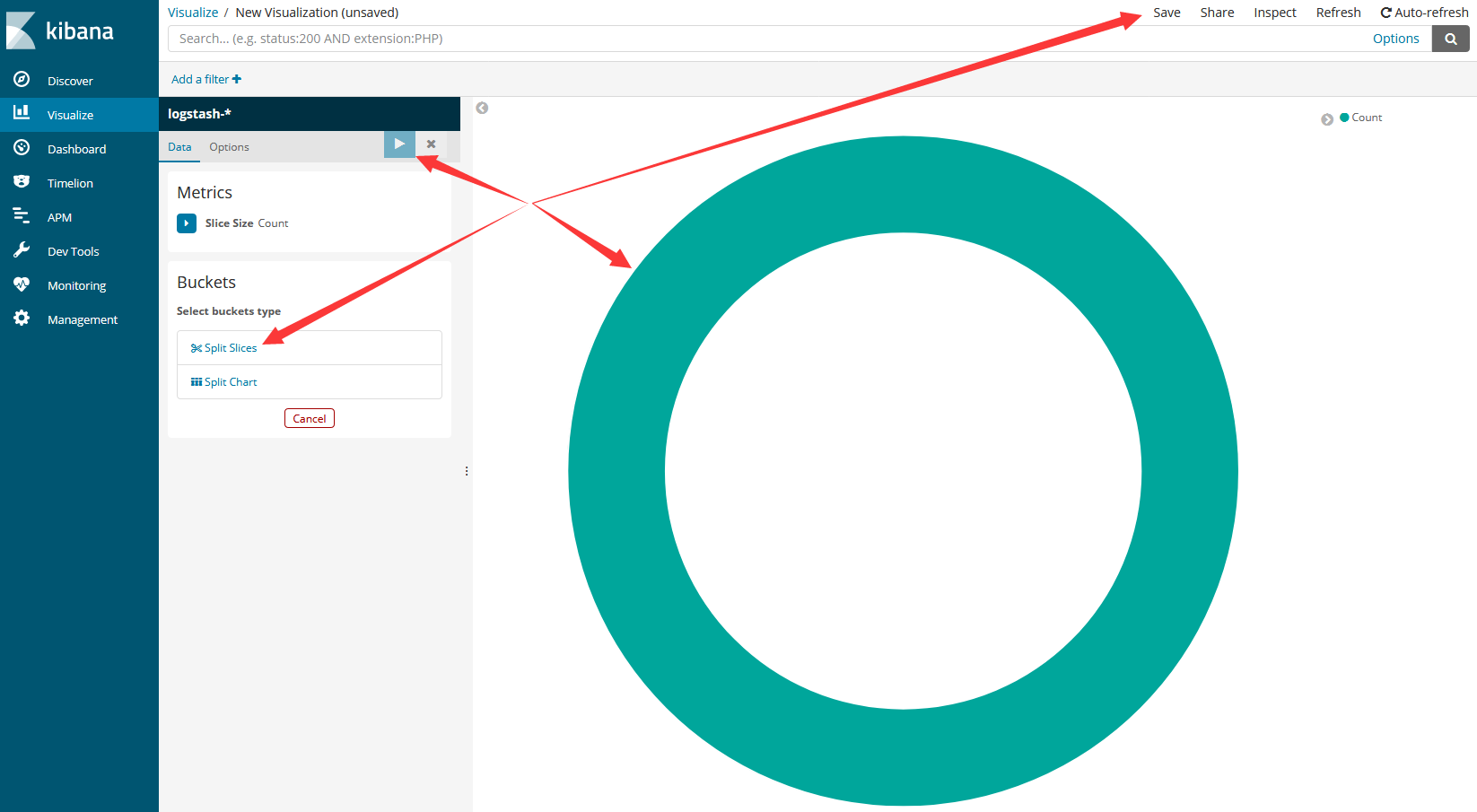
进入后正中央一个大环表示所有数据、左下方的“Split Slices”和“Split Chart”用于添加分割指标、左上方播放按钮用于分割指标效果预览,右上方“Save”菜单用于保存图表。
所谓的分割指标其实主要就是我们logstash生成的好些项,把他们以大于、小于、等于某个值进行分类。
以下是一个建立完的效果图
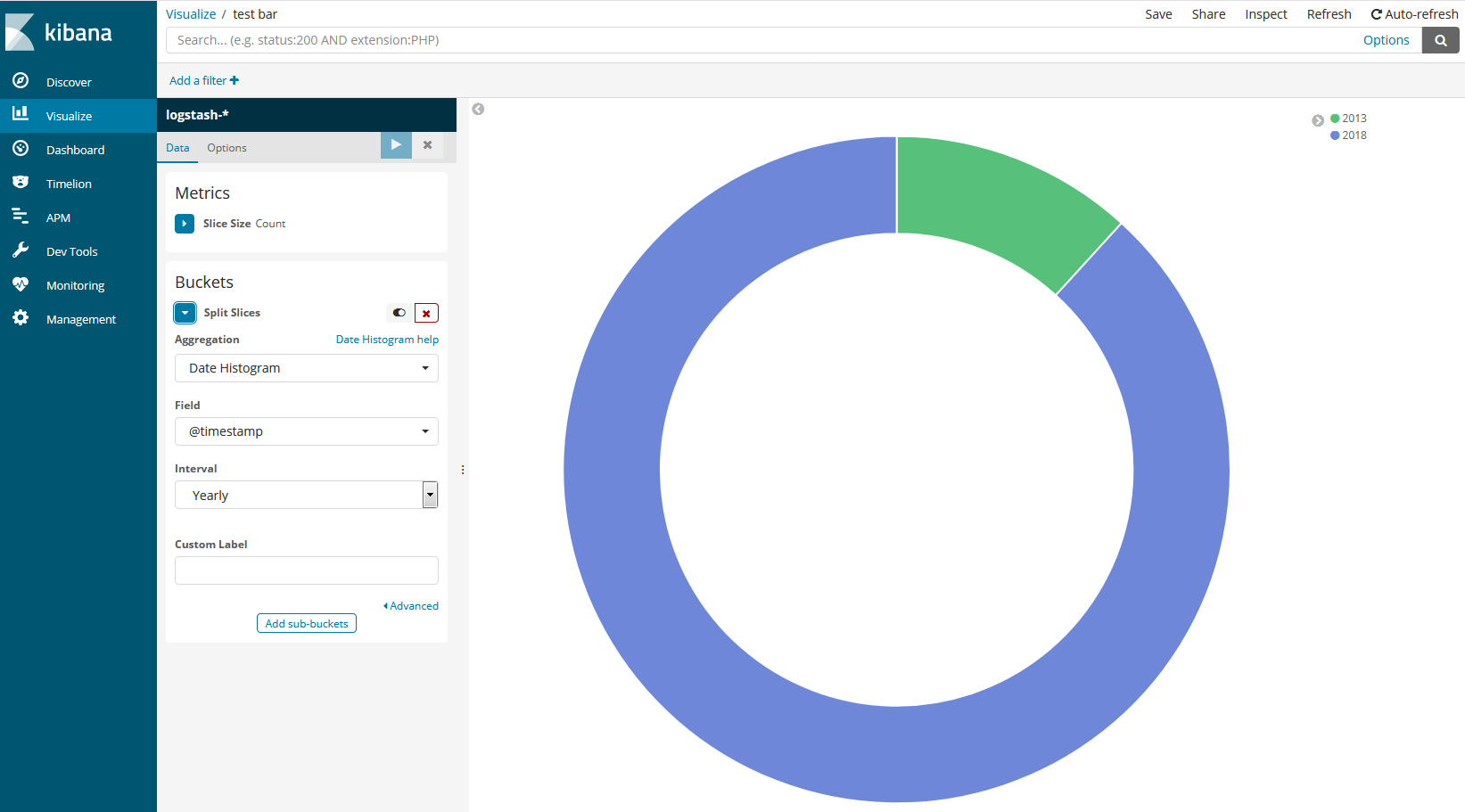
在可视化图表中,最主要的事情就是两件:一是指定如何分类(Buckets),二是指定以什么作为度量(Metrics)。
比如在上图中我们以timestamp项以年(Yearly)为基准进行分类,然后以数量(Metrics中设置为Count)作为度量(具体到这里就是timestamp项各年出现的次数),形成了上边的饼状图。
分类(Buckets)和度量(Metrics)一般都是先选Aggregation再选Field,再选Field的一些细化选项。
Aggregation----类型的意思比如是日期类型(date histogram)还是范围类型(range),这只是一个大体的分类,随便选选就行了。
Filed----就是前面说的logstash的那些项(当然logstash的项和kibana中的项只有在建索引后才能算是一回事,见下文4.3 kibana IP地理可视化),比如timestamp啦host啦,按这些项分类或排序或统计可视化图表怎么建立和配置就很明了了。
Field的一些细化选项----就是一些细化限制,自己随便多点点就知道了。
3.3.5 Dashboard
所谓仪表盘就是,就是可视化图表的集合。用3.3.4的方法创建一个pie(命名为test pie)再创建一个bar(命名为test bar)我们这里以把它们加载到新建的仪表盘为例
全点击加载上来
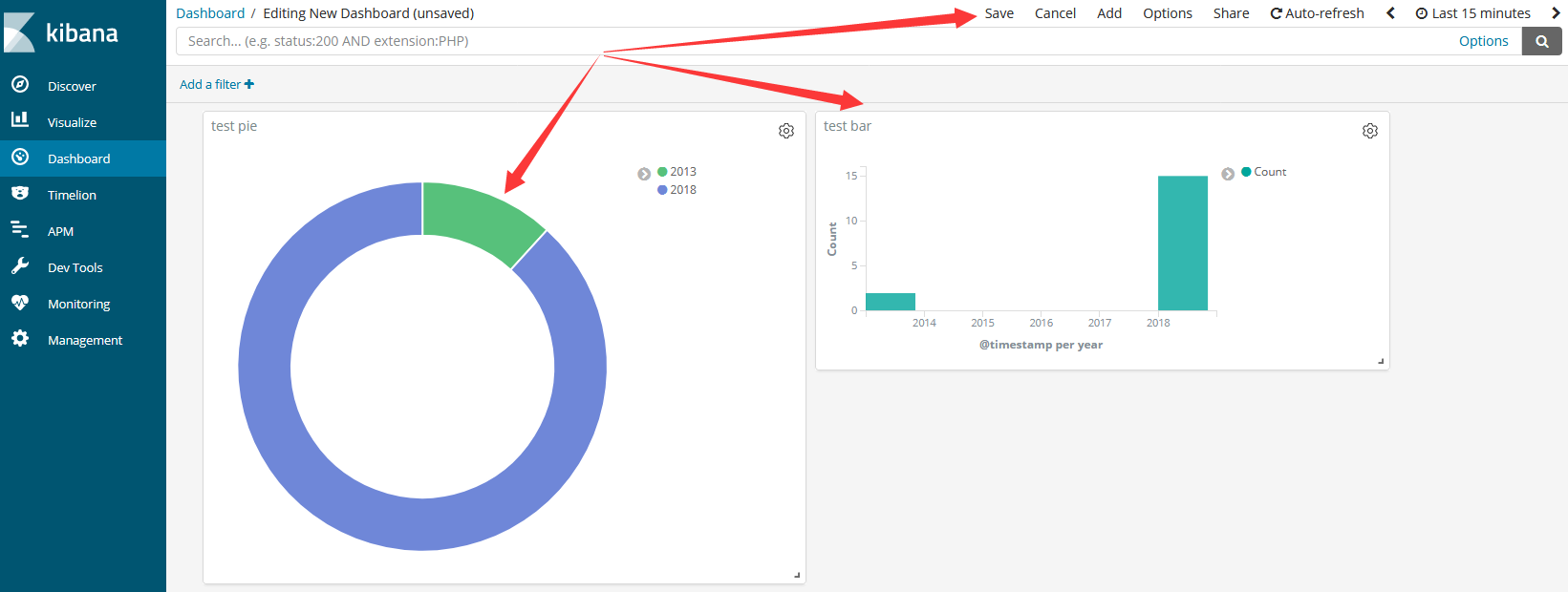
我们可以随意改变加载进来的图表的位置和大小,最后点击“Save”保存即可。这就是所谓的仪表盘,感觉和zabbix是一样的玩法。
四、从自定义文件解析IP并可视化
数据库下载地址:https://dev.maxmind.com/geoip/geoip2/geolite2/
在3.1.2中我们说明了三个关键点:多个插件是以插件链形式运行的,后续插件以其前插件生成的项为操作单元,及如何查看插件文档。但自己想了一下通过看文档知道插件选项怎么写这个答案是不能令人满意的,同时grok解析自定义文本文档是常见的需要我们就以此为例进行演示。
4.1 使用grok从自定义文本中提取ip、端口和协议
生成的内容形如下,我们使用grok插件编写规则,解析出ip、端口、协议三项:
75.207.190.84: udp
在config目录下创建patterns文件夹,再在patterns下创建patterns.conf文件,在其下写入以下内容(其实就相当于正则宏定义):
正则表达式在线测试网址:http://tool.chinaz.com/regex/
grok解析表达式在线测试网址(推荐在这里测过了再写):http://grokdebug.herokuapp.com

MYIP (\d+\.+){}\d+
MYPORT \d{,}
MYPROTO (t|u){}(c|d){}p
在logstash.conf中写入以下内容(格式要点说明都在注释中,另外注意按自己的修改文件路径):
input {
stdin { }
}
filter {
# 在真正使用时通常会接收来自不同地方不同格式的文件,此时就要限定插件对哪些来源启用而对哪些来源不启用,因为使用格式去解析不匹配的文件那是解析不了的就会报错
# 后边启用些限制,只有path项中为test.txt文件才使用此规则。这里是在控制台调试所以先注释掉
# if [path] =~ "test.txt" {
grok {
# 这里是自定义正则的文件夹
patterns_dir => ["/usr/myapp/elk/logstash-6.4.2/config/patterns"]
# 这条规则的意思是,针对前面的“message”项的内容,使用"%{MYIP:myip}:%{MYPORT:myport} %{MYPROTO:myproto}"格式进行解析
# MYIP/MYPORT/MYPROTO我们自定义的正则规则,myip/myport/myproto三项表示其前正则解析出的内容赋给这些项
# =>后的规则不要求能解析完整个项,但一定要是从头连续解析;比如可以只要match => { "message" => "%{MYIP:myip}}
# 但不能是跳过端口:match => { "message" => "%{MYIP:myip} %{MYPROTO:myproto}"}
# 其实的:和空格不是随意的是因为不用正则的地方要原样保留75.207.190.: udp中我们的正则没处理其中的:和空格要原样保留
match => { "message" => "%{MYIP:myip}:%{MYPORT:myport} %{MYPROTO:myproto}"}
# 如果不想用文件夹也可以直接把规则写在这里,比如上边这条规则直接写在这里的等价形式为
# match => { "message" => "(?<myip>(\d+\.+){3}\d+):(?<myport>(\d{1,5}) %(?<myproto>((t|u){1}(c|d){1}p)"}
}
# }
}
output {
stdout { }
}
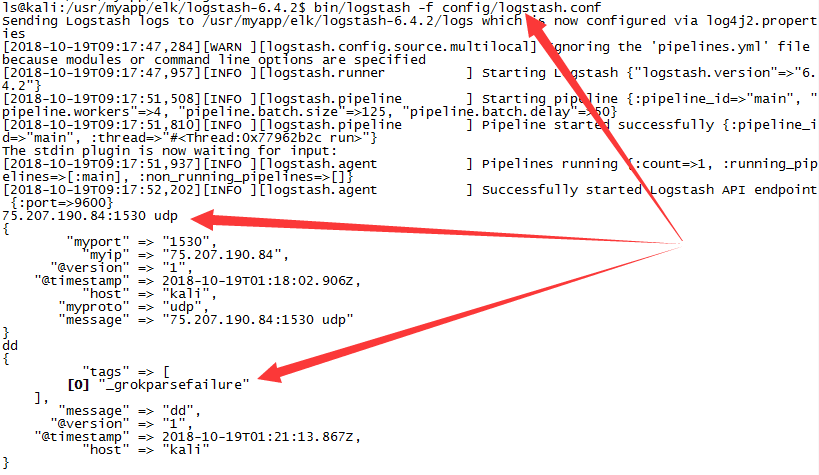
在下图中可以看到对于输入“75.207.190.84:1530 udp”,ip、端口和协议都已按预期成功提取
另外我们还输入了按%{MYIP:myip}:%{MYPORT:myport} %{MYPROTO:myproto}格式不能解析的“dd”,此时报错[0] "_grokparsefailure"。这就是上方配置注释中强调针对来源启用插件的原因。
4.2 使用geoip将ip转换为地理位置
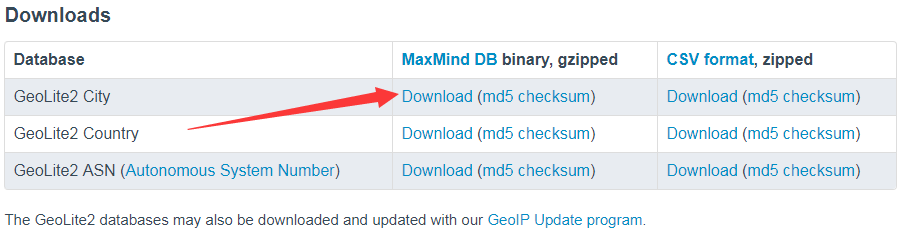
首先要下载GeoLite2数据库,下载地址:https://dev.maxmind.com/geoip/geoip2/geolite2/
这几个的区别是精度的区别ASN精确到自治域,Country精确到国家,City精确到城市。我们直接下载城市版,然后解压
按流程来讲还是得要在stdin{}和stdout{}调试一翻,完后再写真正配置,但这里为了节省篇幅混合在一起进行。
修改logstash.conf为以下内容,然后启动logstash:
input {
file {
# 存放python生成的那些东西的文件的位置,根据自己的修改
path => ["/home/ls/test.txt"]
start_position => "beginning"
}
}
filter {
# 只有path项中为test.txt文件才使用此规则
if [path] =~ "test.txt" {
grok {
# 这里是自定义正则的文件夹,根据自己的修改
patterns_dir => ["/usr/myapp/elk/logstash-6.4.2/config/patterns"]
# 这条规则的意思是,针对前面的“message”项的内容,使用"%{MYIP:myip}:%{MYPORT:myport} %{MYPROTO:myproto}"格式进行解析
# MYIP/MYPORT/MYPROTO我们自定义的正则规则,myip/myport/myproto三项表示其前正则解析出的内容赋给这些项
# =>后的规则不要求能解析完整个项,但一定要是从头连续解析;比如可以只要match => { "message" => "%{MYIP:myip}}
# 但不能是跳过端口:match => { "message" => "%{MYIP:myip} %{MYPROTO:myproto}"}
# 其实的:和空格不是随意的是因为不用正则的地方要原样保留75.207.190.: udp中我们的正则没处理其中的:和空格要原样保留
match => { "message" => "%{MYIP:myip}:%{MYPORT:myport} %{MYPROTO:myproto}"}
# 如果不想用文件夹也可以直接把规则写在这里,比如上边这条规则直接写在这里的等价形式为
# match => { "message" => "(?<myip>(\d+\.+){3}\d+):(?<myport>(\d{1,5}) %(?<myproto>((t|u){1}(c|d){1}p)"}
}
# 这里可以还是需要放if内进行限制,我们要对“myip”键进行处理,只有经过上边grok处理的才会有myip键
# 其他消息没有myip,处理时不会自动跳运而是一样报[] "_geoip_lookup_failure"
geoip{
# 指定要进行地址转换的字段----当然只能是ip字段,我们这里是myip
source => "myip"
# 下载的geoip数据库文件的位置,根据自己的修改
database => "/usr/myapp/elk/logstash-6.4.2/config/GeoLite2-City_20181016/GeoLite2-City.mmdb"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
# 输出到控制台是为了调试用的,到真正配时注释掉
stdout{}
}
我们使用以下python代码生成多一些和”75.207.190.84:1530 udp“格式一样的数据,生成后保存到/home/ls/test.txt(保存到哪都可以只要和input中file插件设置的位置一致)
for i in range(100):
print(f"{random.randint(1,255)}.{random.randint(1,255)}.{random.randint(1,255)}.{random.randint(1,255)}:{random.randint(1000,2000)} tcp")
print(f"{random.randint(1,255)}.{random.randint(1,255)}.{random.randint(1,255)}.{random.randint(1,255)}:{random.randint(1000,2000)} udp")
由于我们输出到stdout{}(用nohub启动的可以查看nohub.out),此时可以在控制台看到类似以下输出。“110.40.27.195”这个IP被成功解析为中国北京。

4.3 kibana IP地理可视化
在第三大节中我们创建了index,所谓index就是给logstash生成的那些键在kibana中设定为索引。现在myip等项和geoip的各项都是新加进来的,在kibana中就还没有对应索引所以我们需要重新建一个索引。
对于任何新增的项,都需要新建index才能将将其作为可视化图表中的“维”来使用。
取定好数据集,我这里取定为logstash-2018.10.*,除了昨天和今天的数据集logstash-2018.10.18和logstash-2018.10.19,明天传来的数据会保存为logstash-2018.10.20,由于能匹配上所以也会自动包含进去。11月的数据为logstash-2018.11.x由于匹配不上所以就不会被包含了,这就是所谓“index pattern”的意思。
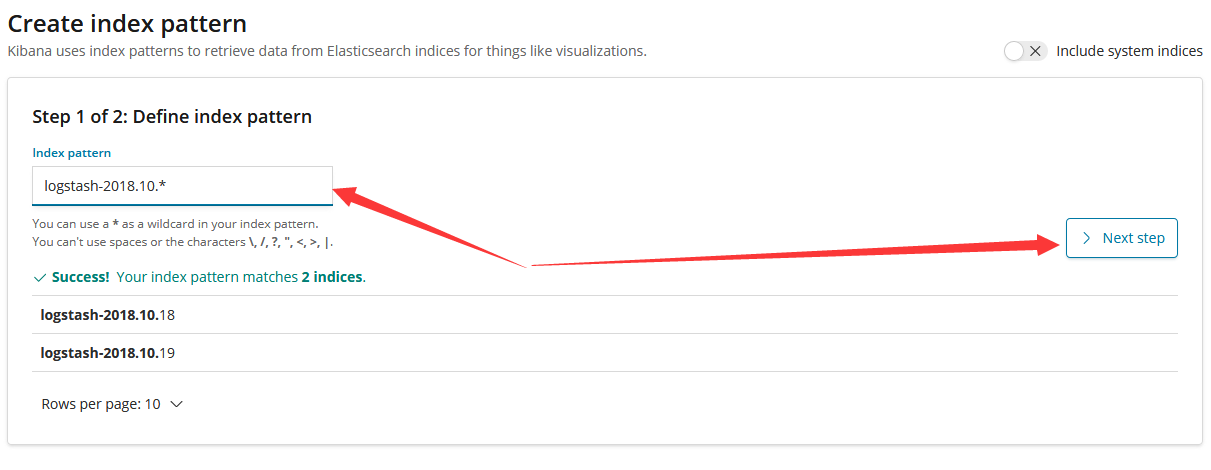
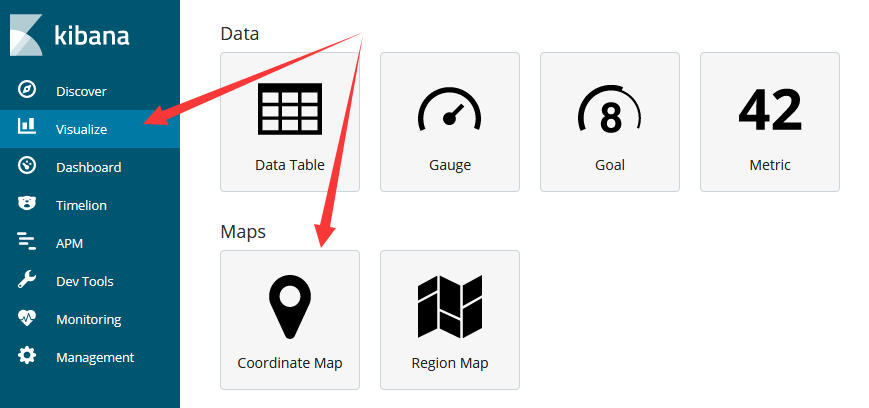
此时我们再到Visualize创建一个Region map
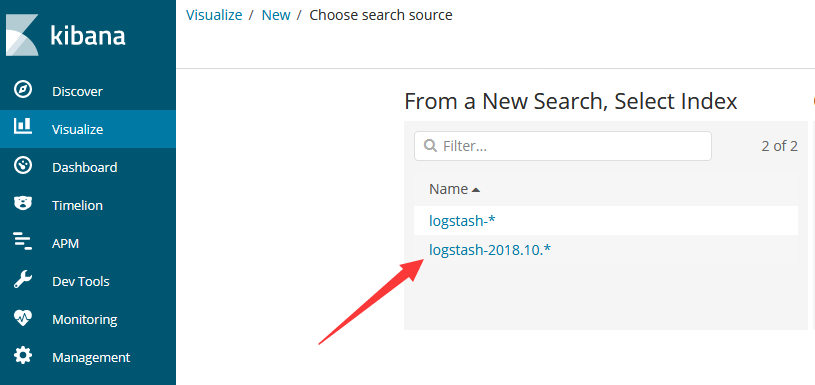
选用新建的索引
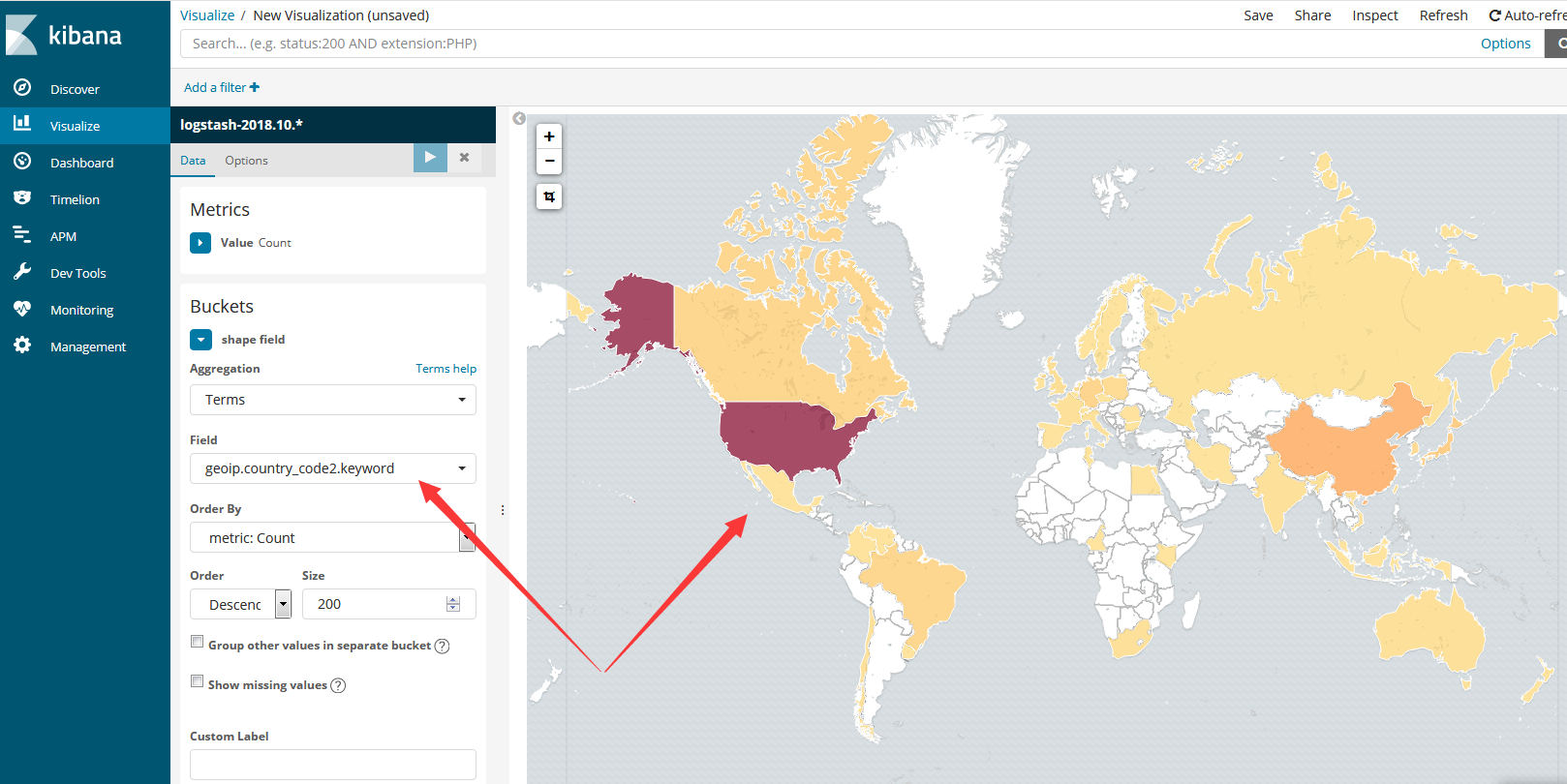
如图所示,我们以国家代码(geoip.country_code2)进行分类,然后以数量为其度量,就生成了以下图表
参考:
https://blog.csdn.net/KingBoyWorld/article/details/78555120
https://blog.csdn.net/kingboyworld/article/details/77814528
https://www.elastic.co/downloads/logstash
https://www.elastic.co/downloads/elasticsearch
https://www.elastic.co/downloads/kibana
ELK安装使用教程的更多相关文章
- ELK 安装Beat
章节 ELK 介绍 ELK 安装Elasticsearch ELK 安装Kibana ELK 安装Beat ELK 安装Logstash Beat是数据采集工具,安装在服务器上,将采集到的数据发送给E ...
- IntelliJ IDEA - 热部署插件JRebel 安装使用教程
IntelliJ IDEA - JRebel 安装使用教程 JRebel 能做什么? JRebel 是一款热部署插件.当你的 Java-web 项目在 tomcat 中 run/debug 的时候 , ...
- Zabbix3.x安装图解教程
准备知识: Zabbix3.x比较之前的2.0界面有了很大的变化,但是安装部署过程与2.x基本完全一样. 1.Zabbix2.x安装图解教程 http://www.osyunwei.com/archi ...
- VMware vCenter Server安装图解教程
安装说明: 1.安装VMware vCenter Server的主机操作系统为:Windows Server 2008 R2 2.在Windows Server 2008 R2中需要预先安装好SQL ...
- 在RedHat.Enterprise.Linux_v6.3系统中安装Oracle_11gR2教程
在RedHat.Enterprise.Linux_v6.3系统中安装Oracle_11gR2教程 本教程提供PDF格式下载: 在RedHat.Enterprise.Linux_v6.3系统中安装Ora ...
- Zabbix安装图解教程
说明: 操作系统:CentOS IP地址:192.168.21.127 Web环境:Nginx+MySQL+PHP zabbix版本:Zabbix 2.2 LTS 备注:Linux下安装zabbix需 ...
- MapGIS6.7安装图文教程(完美破解)
mapgis安装比较简单,主要注意在安装的时候,先打开软件狗,然后再进行软件安装,一般就不会照成其他安装失败的现象,有时候安装之前没有打开软件狗也安装成功了,也有这情况,不过软件使用也需要软件狗的支持 ...
- VirtualBox安装Ubuntu教程
1.VirtualBox虚拟机安装,及VirtualBox安装Ubuntu教程VirtualBox版本为VirtualBox-4.3.12-93733-Win.exe,Ubuntu版本为ubuntu- ...
- MySQL5.0版本的安装图解教程
MySQL5.0版本的安装图解教程是给新手学习的,当前mysql5.0.96是最新的稳定版本. mysql 下载地址 http://www.jb51.net/softs/2193.html 下面的是M ...
随机推荐
- [svc]unix和cpu发展历史
最近搞汇编 , 有一款8086cpu,16bit, 支持内存1M 于是勾起了对计算机历史的兴趣,多了解了下 unix起源历史 [Unix发展历史 - 程序猿-贝岩博客 - CSDN博客]https:/ ...
- 线段树 HDU-1166 敌兵布阵
敌兵布阵是一个线段树典题,题目如下(点此查看题目出处): Problem Description C国的死对头A国这段时间正在进行军事演习,所以C国间谍头子Derek和他手下Tidy又开始忙乎了.A国 ...
- 论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)
XiangBai——[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- Chart控件的用法
最近用到统计方面的功能,文档统计不用说,都是导出Excel,若要视图效果,这里推荐一个Asp.NET中的控件Char. 简单示例: 视图显示说明: 可以设定Series的ChartType属性值, ...
- Java课程总结
预备作业一 简要内容:我期望的师生关系 预备作业二 简要内容:学习基础和C语言基础调查 预备作业三 简要内容:Linux安装及学习 第一周作业 简要内容:Java入门 第二周作业 简要内容:学习基本数 ...
- JS数据类型判断的方法
最常用的判断方法:typeof var a='isString'; var b=121221; var c=[1,2,3]; var d=new Date(); var e=function(){ c ...
- Dom 兼容处理
获取子节点:childNodes 在IE下是可以正常使用的 但是在FF包含了文本节点需要配合nodeType做个类型判断 1是元素节点 3是文本节点 也可以采用 children IE ...
- web文件上传
文件上传的步骤: 1.目前Java文件上传功能都是依靠Apache组织的commons-io, fileupload两个包来实现的: 2. http://commons.apache.org/下载io ...
- iperf使用指南
注意:iperf板上版本和PC上版本要一致,至少都要是2或者3,不能一个是2,一个是3. You also get a "connection refused" error whe ...
- Linux学习笔记之时间同步the NTP socket is in use, exiting问题
[root@app1 ~]# ntpdate ntp.api.bz 17 Apr 14:39:09 ntpdate[24744]: the NTP socket is in use, exiting ...