requests库(爬虫)
北京理工大学嵩天老师的课程:http://www.icourse163.org/course/BIT-1001870001
官方文档:http://docs.python-requests.org/en/master/
中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
安装
pip install requests
Requests库的七个主要方法
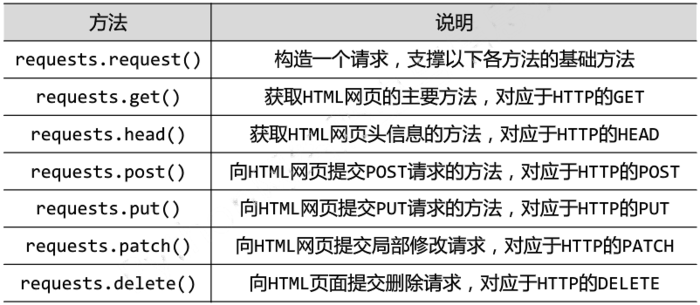
get方法
r = requests.get(url)
右边构造一个向服务器请求资源的Requests对象,左边返回一个包含服务器资源的Response对象给r,完整参数:
r = requests.get(url,params=None,**kwargs)
如果我们打开requests库get方法源代码,我们可以看到get方法实际上使用了request方法来封装,requests库的其他方法也都是通过调用request方法来封装的:
def get(url, params=None, **kwargs):
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)
Resonse对象的属性
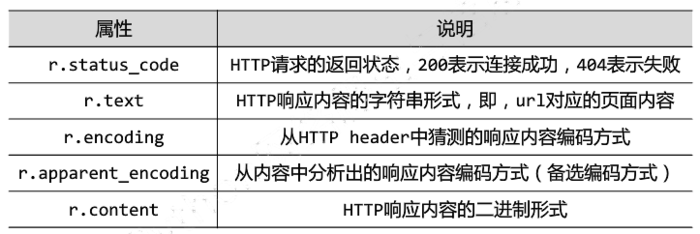
r.encoding:如果header中不存在charset字段,默认编码为ISO-8859-1,此时的编码输出r.text中的中文将是乱码。
r.apparent_encoding:会根据HTTP网页的内容分析出应该使用的编码。
>>> r.encoding 'ISO-8859-1' >>> r.apparent_encoding 'utf-8'
解决中文乱码方法修改r.encoding值:
>>> r.encoding=r.apparent_encoding
爬取网页的通用代码框架
Requests库爬取网页时可能会遇到的异常
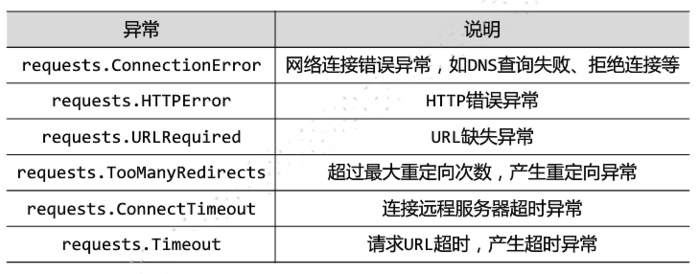
使用r.raise_for_status()方法构建通用代码框架:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == '__main__':
url = 'https://www.baidu.com/'
print(getHTMLText(url))
HTTP协议及request方法
HTTP(Hypertext Transfer Protocol,超文本传输协议)是一个基于"请求与响应"模式的/无状态的应用层协议。
URL是通过HTTP协议存取资源的Internet路径。
HTTP协议对资源的操作:
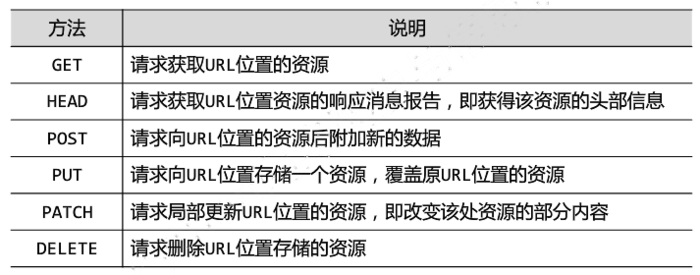
request方法
requests.request(method,url,**kwargs)
详情参参考官方文档:http://docs.python-requests.org/en/master/api/
这是中文的文档:http://docs.python-requests.org/zh_CN/latest/api.html
method(请求方式7个)包括:
GET、HEAD、POST、PUT、PATCH、delete、OPTIONS
**kwargs(控制访问参数13个,均为可选)包括:
params、data、json/headers、cookies、auth、files、timeout/proxies、allow_redirects、stream、verify、cert
params:字典或字节序列,作为参数增加到url中:
>>> import requests
>>> kv={"k1":"v1","k2":"v2"}
>>> r=requests.request('GET','https://www.baidu.com/',params=kv)
>>> r.url
'https://www.baidu.com/?k1=v1&k2=v2'
data:字典、字节序列或文件对象,作为Request的内容
json:JSON格式的数据,作为Request的内容
headers:字典,HTTP定制头
cookies:字典或CookieJar,Request中的cookie
auth:元祖,支持HTTP认证功能
files:字典,传输文件
>>> fs={'file':open('data.xls','rb')}
>>> r=requests.request('POST','https://www.baidu.com/',files=fs)
timeout:设定的超时时间,以秒为单位。超时时间内没有返回结果则抛出超时的异常
>>> r=requests.request('GET','https://www.baidu.com/',timeout=10)
proxies:字典类型,设定访问代理服务器,可以增加的登陆认证,有效隐藏用户爬取网站的源IP地址信息。
>>> r=requests.request('GET','https://www.baidu.com/',timeout=10)
>>> pxs={'http':'http://user:pass@10.10.10.1:1234',
... 'http':'https://10.10.10.1:4321'}
>>> r=requests.request('GET','https://www.baidu.com/',proxies=pxs)
allow_redirects:True/Flase,默认为True,重定向开关
stream:True/Flase,默认为True,获取内容立即下载开关
verify:True/Flase,默认为True,认证SSL证书开关
cert:本地SSL证书路径
除了reques之外的其他六个主要方法
requests.get(url, params=None, **kwargs) requests.head(url, **kwargs) requests.post(url, data=None, json=None, **kwargs) requests.put(url, data=None, **kwargs) requests.patch(url, data=None, **kwargs) requests.delete(url, **kwargs)
除了url其他的参数与访问控制参数就是跟方法request中的一样。
网络爬虫爬亦有道之策略与限制
网路爬虫的规模

网络爬虫的限制
限制原因:
- 网络爬虫可能会给Web服务器带来巨大的资源开销
- 网络爬虫获取数据后可能会带来法律风险
- 网络爬虫可能会造成隐私泄露
限制方法:
1.来源审查:判断User-Agent进行限制。
审查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问。
2.发布公告:Robots协议。
告知所有爬虫网站的爬虫策略,要求爬虫遵守。
Robots协议
Robots Exclusion Standard 网络爬虫排除标准
作用:告知网络爬虫哪些可抓取哪些不行。
形式:网站的根目录下的robots.txt文件。
以京东的为例:
https://www.jd.com/robots.txt
User-agent: * Disallow: /?* Disallow: /pop/*.html Disallow: /pinpai/*.html?* User-agent: EtaoSpider Disallow: / User-agent: HuihuiSpider Disallow: / User-agent: GwdangSpider Disallow: / User-agent: WochachaSpider Disallow: /
User-agent: * :表示无论什么爬虫都应该遵守如下协议
Disallow:表示不允许爬取符合后面的通配符表示的路径
其余四个User-agent不允许爬取任何资源,被京东认为是恶意爬虫。
Rebots协议的使用
网络爬虫:自动或人工识别rebots.txt,再进行内容爬取。
约束性:建议但非约束性,网络爬虫可以不遵守,但是存在法律风险。
遵守原则:

爬取实例
京东商品页面的爬取
import requests
url = "http://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
亚马逊商品页面的爬取
按实例1的步骤去做发现出现了错误:

发现是由于亚马逊有自身的头部审查,故我们模拟浏览器访问:
import requests
url = "http://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'}
r= requests.get(url,headers = kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
百度/360搜索关键词提交
首先我们需要知道搜索关键词的提交接口:
百度:http://www.baidu.com/s?wd=keyword 360:http://www.so.com/s?q=keyword
接下来我们可以利用params参数将关键词加入,代码如下:
import requests
keyword = "Python"
try:
kv = {'wd': keyword}
r = requests.get("http://www.baidu.com/s", params=kv)
print(r.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
网络图片的爬取和存储
网络图片链接的格式:https://pic.cnblogs.com/avatar/1054809/20171230220706.png
import requests
import os
url = "https://pic.cnblogs.com/avatar/1054809/20171230220706.png"
root = "D://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
IP地址归属地的查询
我们python没有这样的库,但是网上有这样的资源,一个网站http://www.ip38.com/有这样的功能
import requests
url = "http://m.ip138.com/ip.asp?ip="
try:
r = requests.get(url + '202.204.80.112')
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
爬取页面图片
import requests
import os
import re
from bs4 import BeautifulSoup
def getHTMLText(url):
r = requests.get(url)
html = r.text
return html
def getImgURL(html):
soup = BeautifulSoup(html, 'html.parser')
imgs = soup.find_all('img')
li = []
for img in imgs:
src = img.attrs['src']
li.append(src)
return li
def getImg(urls):
for url in urls:
root = "D://images//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
def main():
url = 'http://www.feizl.com/html/65323.htm' # 带爬取网页URL
html = getHTMLText(url)
urls = getImgURL(html)
getImg(urls)
if __name__ == '__main__':
main()
requests库(爬虫)的更多相关文章
- 爬虫1.1-基础知识+requests库
目录 爬虫-基础知识+requests库 1. 状态返回码 2. URL各个字段解释 2. requests库 3. requests库爬虫的基本流程 爬虫-基础知识+requests库 关于html ...
- Python爬虫小白入门(二)requests库
一.前言 为什么要先说Requests库呢,因为这是个功能很强大的网络请求库,可以实现跟浏览器一样发送各种HTTP请求来获取网站的数据.网络上的模块.库.包指的都是同一种东西,所以后文中可能会在不同地 ...
- python爬虫从入门到放弃(四)之 Requests库的基本使用
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--robots协议与Requests库实战
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 慕课链接:https://www.icourse163.org/learn/BIT-1001870001?tid=100223 ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT 慕课链接:https://www.icourse163.org/learn/BIT-10018 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
随机推荐
- pymysql的使用与参数简要
pymysql.Connect()参数说明 host(str): MySQL服务器地址 port(int): MySQL服务器端口号 user(str): 用户名 passwd(str): 密码 db ...
- 【Mybatis】【1】generate批量生成实体类,数据库接口类和mapper
前言: 1,实体类之类如果自己写的话,比较繁琐,还容易出错,所以用generate自动生成 2,int类型可能会生成为short类型,建议不要手动改回int类.因为下次生成又是short类型了,可能会 ...
- Java中char和String的相互转换
转自:http://blog.csdn.net/yaokai_assultmaster/article/details/52082763 Java中char是一个基本类型,而String是一个引用类型 ...
- 解决SpringMVC+Thymeleaf中文乱码
乱码效果截图 解决办法:在org.thymeleaf.templateresolver.ServletContextTemplateResolver和org.thymeleaf.spring5.vie ...
- 内建函数之:reduce()使用
#!/usr/bin/python#coding=utf-8'''Created on 2017年11月2日 from home @author: James zhan ''' print reduc ...
- SSM 框架 整合<SpringMVC+Spring+MyBatis>
一 框架的搭建1.建立一个maven项目 2.建立五个module(entity,dao,service,action,web-view) 3.给予它们之间的依赖关系 dao-->entity ...
- app性能测试指标
性能测试在软件的质量保证中起着重要的作用,它包括的测试内容丰富多样.中国软件评测中心将性能测试概括为三个方面:应用在客户端性能的测试.应用在网络上性能的测试和应用在服务器端性能的测试.通常情况下,三方 ...
- vuex实现原理
一.Store的层次结构 Store,负责管理整个数据访问.修改等: 提高API: State,数据结构: 所有的getters.mutations,全部都注册到store里:结构大概是: { 'xx ...
- select 取value值
<md-select ng-model="alarmSelect" style="margin: 0px 0px 0px 0px;" ng-change= ...
- ES6 用Promise对象实现的 Ajax 操作
下面是一个用Promise对象实现的 Ajax 操作的例子. const getJSON = function(url) { const promise = new Promise(function( ...