我的第一个python爬虫
我的第一个爬虫,哈哈,纯面向过程
实现目标:
1.抓取本地conf文件,其中的URL地址,然后抓取视频名称以及对应的下载URL
2.抓取URL会单独写在本地路径下,以便复制粘贴下载
废话补多少,代码实现效果如下:
代码如下:
#!/usr/local/python/bin/python3
import requests
import re
import chardet
import random
import signal
import time
import os
import sys
def DealwithURL(url):
r = requests.get(url)
pattern = re.compile('<meta http-equiv="refresh" content="0.1;url=')
findurl=re.findall(pattern,r.text)
if findurl:
pattern = re.compile('<meta http-equiv="refresh" content="0.1;url=(.*)"')
transferurl = re.findall(pattern,r.text)[0]
return transferurl
else :
return True
def GetNewURL(url):
r = requests.get(url)
r.encoding='utf-8'
pattern = re.compile('alert(.*)">')
findurl=re.findall(pattern,r.text)
findurl_str = (" ".join(findurl))
return (findurl_str.split(' ',1)[0][2:])
def gettrueurl(url):
if DealwithURL(url)==True:
return url
else :
return GetNewURL(DealwithURL(url))
def SaveLocalUrl(untreatedurl,treatedurl):
if untreatedurl == treatedurl :
pass
else :
try:
fileconf = open(r'main.conf','r')
rewritestr = ""
for readline in fileconf:
if re.search(untreatedurl,readline):
readline = re.sub(untreatedurl,treatedurl,readline)
rewritestr = rewritestr + readline
else :
rewritestr = rewritestr + readline
fileconf.close()
fileconf = open(r'main.conf','w')
fileconf.write(rewritestr)
fileconf.close()
except:
print ("get new url but open files ng write to logs")
def handler(signum,frame):
raise AssertionError
def WriteLocalDownloadURL(downfile,downurled2k):
urlfile = open(downfile,'a+')
urlfile.write(downurled2k+'\n')
def GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers):
downurlstr = (" ".join(titleurl))
downnamestr = (" ".join(titlename))
r = requests.get((sourceurl+downurlstr),headers)
pattern = re.compile('autocomplete="on">(.*)/</textarea></div>')
downurled2k = re.findall(pattern,r.text)
downurled2kstr = (" ".join(downurled2k))
WriteLocalDownloadURL(update_file , downurled2kstr)
print (downnamestr , downurled2kstr)
def ReadLocalFiles() :
returndict={}
localfiles = open(r'main.conf')
readline = localfiles.readline().rstrip()
while readline :
if readline.startswith('#'):
pass
else:
try:
readline = readline.rstrip()
returndict[readline.split('=')[0]] = readline.split('=')[1]
except:
print ("Please Check your conf %s" %(readline))
sys.exit(1)
readline = localfiles.readline().rstrip()
localfiles.close()
return returndict
def GetListURLinfo(sourceurl , title , getpagenumber , total,update_file,headers):
if total >= 100:
total = 100
if total <= 1:
total = 2
getpagenumber = total
for number in range(0,total) :
try:
signal.signal(signal.SIGALRM,handler)
signal.alarm(3)
url = sourceurl + title + '-' + str(random.randint(1,getpagenumber)) + '.html'
r = requests.get(url,headers)
pattern = re.compile('<div class="info"><h2>(.*)</a><em></em></h2>')
r.encoding = chardet.detect(r.content)['encoding']
allurl = re.findall(pattern,r.text)
for lineurl in allurl:
try:
signal.signal(signal.SIGALRM,handler)
signal.alarm(3)
pattern = re.compile('<a href="(.*)" title')
titleurl = re.findall(pattern,lineurl)
pattern = re.compile('title="(.*)" target=')
titlename = re.findall(pattern,lineurl)
GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers)
signal.alarm(0)
except AssertionError:
print (lineurl,titlename , "Timeout Error: the cmd 10s have not finished")
continue
# title = '/list/'+str(random.randint(1,8))
# print (title)
# print (title_header)
except AssertionError:
print ("GetlistURL Infor Error")
continue
def GetTitleInfo(url,down_page,update_file,headers):
title = '/list/'+str(random.randint(1,8))
titleurl = url + title + '.html'
r = requests.get(titleurl,headers)
r.encoding = chardet.detect(r.content)['encoding']
pattern = re.compile(' 当前:.*/(.*)页 ')
getpagenumber = re.findall(pattern,r.text)
getpagenumber = (" ".join(getpagenumber))
GetListURLinfo(url , title , int(getpagenumber) , int(down_page),update_file,headers)
def write_logs(time,logs):
loginfo = str(time)+logs
try:
logfile = open(r'logs','a+')
logfile.write(loginfo)
logfile.close()
except:
print ("Write logs error,code:154")
def DeleteHisFiles(update_file):
if os.path.isfile(update_file):
try:
download_files = open(update_file,'r+')
download_files.truncate()
download_files.close()
except:
print ("Delete " + update_file + "Error --code:166")
else :
print ("Build New downfiles")
def main():
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome","Accept": "text/html,application/xhtml+xml,application/xml; q=0.9,image/webp,*/*;q=0.8"}
readconf = ReadLocalFiles()
try:
file_url = readconf['url']
down_page = readconf['download_page']
update_file = readconf['download_local_files']
except:
print ("Get local conf error,please check it")
sys.exit(-1)
DeleteHisFiles(update_file)
untreatedurl = file_url
treatedurl = gettrueurl(untreatedurl)
SaveLocalUrl(untreatedurl,treatedurl)
url = treatedurl
GetTitleInfo(url,int(down_page),update_file,headers)
if __name__=="__main__":
main()
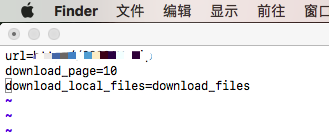
对应的main.conf如下:
本着对爬虫的好奇来写下这些代码,如有对代码感兴趣的,可以私聊提供完整的conf信息,毕竟,我也是做运维的,要脸,从不用服务器下片。
我的第一个python爬虫的更多相关文章
- 一个python爬虫小程序
起因 深夜忽然想下载一点电子书来扩充一下kindle,就想起来python学得太浅,什么“装饰器”啊.“多线程”啊都没有学到. 想到廖雪峰大神的python教程很经典.很著名.就想找找有木有pdf版的 ...
- 记我的第一个python爬虫
捣鼓了两天,终于完成了一个小小的爬虫代码.现在才发现,曾经以为那么厉害的爬虫,在自己手里实现的时候,也不过如此.但是心里还是很高兴的. 其实一开始我是看的慕课上面的爬虫教学视屏,对着视屏的代码一行行的 ...
- 我的第一个Python爬虫——谈心得
2019年3月27日,继开学到现在以来,开了软件工程和信息系统设计,想来想去也没什么好的题目,干脆就想弄一个实用点的,于是产生了做“学生服务系统”想法.相信各大高校应该都有本校APP或超级课程表之类的 ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- 我的第一个 python 爬虫脚本
#!/usr/bin/env python# coding=utf-8import urllib2from bs4 import BeautifulSoup #res = urllib.urlopen ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- 第一个python爬虫程序
1.安装Python环境 官网https://www.python.org/下载与操作系统匹配的安装程序,安装并配置环境变量 2.IntelliJ Idea安装Python插件 我用的idea,在工具 ...
- 一个python爬虫工具类
写了一个爬虫工具类. # -*- coding: utf-8 -*- # @Time : 2018/8/7 16:29 # @Author : cxa # @File : utils.py # @So ...
- 我的第一个python爬虫程序
程序用来爬取糗事百科上的图片的,程序设有超时功能,具有异常处理能力 下面直接上源码: #-*-coding:utf-8-*- ''' Created on 2016年10月20日 @author: a ...
随机推荐
- C常量与控制语句
在C语言中定义常量的两种方式 在C语言编程中定义常量有两种方法. const关键字 #define预处理器 1. const关键字 const关键字用于定义C语言编程中的常量. const float ...
- k8s学习笔记之三:k8s快速入门
一.前言 kubectl是apiserver的客户端工具,工作在命令行下,能够连接apiserver上实现各种增删改查等各种操作 kubectl官方使用文档:https://kubernetes.io ...
- Python + Robot Framework 环境搭建
一.Python 安装 说明:由于RIDE是基于python2.x开发,后期未做python3.x兼容,所以这里安装python2.7. 链接: https://pan.baidu.com/s/1yf ...
- java面试题收集
http://www.cnblogs.com/yhason/archive/2012/06/07/2540743.html 2,java常见面试题 http://www.cnblogs.com/yha ...
- 协程,greenlet,gevent
""" 协程 """ ''' 协程: 类似于一个可以暂停的函数,可以多次传入数据,可以多次返回数据 协程是可交互的 耗资源大小:进程 --& ...
- win7 64 位 + vs2015 + opencv3.2
下载OpenCv_3.2_vc14 链接:http://pan.baidu.com/s/1eSBu1NG 密码:104g 1.下载好后,进行解压到自己指定的目录: 解压后可以得到: 2.添加环境变量 ...
- 学习excel的使用技巧四显示正常的数字
记得之前在excel中输入一些数字比如输入手机号 就会变成1.E几类似这种 那么怎样显示正常的数字呢 先选中要操作的输入框 1 找到 数字 这个功能的地方 2 设置为 数值 并且小数点为0 3 ...
- myeclipse和jdk的安装和配置
一.安装JDK 1.下载得到jdk-8u11-windows-i586.1406279697.exe,直接双击运行安装,一直next就可以,默认是安装到系统盘下面Program Files,我这里装在 ...
- 如何查看java的class文件
1.首先拿到javac文件 例如:test.class 2.可以使用文本编辑器用二进制的方式打开() cafe babe 0000 0034 0056 0a00 1200 3209 0010 0033 ...
- spark-1
先测试搭好的spark集群: 本地模式测试: 在spark的目录下: ./bin/run-example SparkPi 10 --master local[2] 验证成功: 集群模式 Spark S ...