[Project] MiniSearch文本检索简介
1. 预处理过程
预处理主要用来事先生成程序在运行过程中可能用到的数据,以便加速处理时间。
预处理的过程主要生成程序所需的三个文件:网页库文件,网页位置信息文件和倒排索引文件。
网页库文件
其中网页库文件ripepage.lib主要是以格式化的数据存储大量的网页信息,每个网页的格式化数据为:
<doc>
<docid>id</docid>
<docurl>url</docurl>
<doctitle>title</doctitle>
<doccontent>content</doccontent>
</doc>
网页位置信息文件
网页位置信息文件offset.lib主要是存放网页在网页库中的偏移位置,以便程序能快速的取出指定的网页,该文件每一行存储一个网页文件在网页库中的位置信息,每一行的格式为:
docid offset size
其中docid为网页的id(此id具有全局唯一性),offset为文档在网页库中距离文件起始位置的字节数,size为文档的大小。
倒排索引文件
倒排索引文件invert.lib为网页库中的所有词(经过分词,去停用词后)与包含这些词的文档的一种关联关系。
每个词的倒排索引在该文件中占一行,每一行的格式为:
word docid1 frequency1 weight1 … docidi frequencyi weighti…
其中word为网页库中的词, 后面接着的是每三个为一组,docidi 为包含该词的网页,frequencyi为该次在该文档中的词频,weighti为该次在该文档中的权重(归一化后的)。
2. 程序运行过程
程序首先从offset.lib中读取网页位置信息,然后根据这些信息从rippage.lib中读取网页信息,然后从invert.lib读取倒排索引信息
程序循环不断地通过socket接受来自客户端的请求,一旦受到请求就fork一个子进程负责处理该请求而主进程则继续监听。子进程接受来自客户端的查询语句,根据查询语句查找结果并将结果返回给客户端。
1. 构建网页库
生成网页库ripepage.lib,生成网页的位置偏移文件offset.lib。
遍历目录读取所需构建网页库的文件,拼接成标准格式,然后写入文件,并同时建立库索引。代码如下:
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <vector>
#include <fstream>
#include <sys/types.h>
#include <dirent.h>
#include <sys/stat.h>
#include <stdexcept>
#include <unistd.h>
#include <string.h>
#include <map>
#include <utility>
#include <set>
#include <functional>
#include <algorithm> // 扫描目录类,该类扫描指定目录下的项并将属于普通文件的项的绝对路径保存下来。
class DirScan
{
public:
// 带参数的构造函数,传入一个vector容器用于保存文件的绝对路径
DirScan(std::vector<std::string>& vec):m_vec(vec)
{ }
// 重载函数调用操作符,传入一个路径。
void operator()(const std::string &dir_name)
{
traverse(dir_name);
}
// 遍历路径,在遍历的过程中将属于文件类型的项的绝对路径保存到vector容器中。
// 遍历算法:
// 打开该目录,进入该目录,依次遍历该目录中的项,判断该项的属性,如果该项的类型是文件则保存该项的绝对路径,如果该项是目录,则递归的遍历该目录。最后遍历完目录后切换到该目录的上一级目录。
void traverse(const std::string& dir_name)
{
// 打开指定的目录
DIR* pdir = opendir(dir_name.c_str());
if (pdir == NULL)
{
std::cout << "dir open" << std::endl ;
exit(-1);
} // 进入指定的目录
chdir(dir_name.c_str());
struct dirent* mydirent ;
struct stat mystat ; // 依次遍历该目录中的相关项
while ((mydirent =readdir(pdir) ) !=NULL)
{
// 获取目录中项的属性
stat(mydirent->d_name, &mystat);
// 判断该项是不是目录。
if (S_ISDIR(mystat.st_mode))
{
// 如果该目录是'.'和‘..’(每个目录下都有这两项,如果不排除这两项程序会进入无限循环),则跳过该次循环继续下一次
if (strncmp(mydirent->d_name, ".", 1)== 0 || strncmp(mydirent->d_name,"..", 2) == 0)
{
continue ;
}
else// 如果该目录不是前二者,则递归的遍历目录
{
traverse(mydirent->d_name);
}
}
else // 如果该项不是目录(是文件),则保存该项的绝对路径
{
std::string file_name="";
file_name = file_name + getcwd(NULL,0)+"/"+ mydirent->d_name ;
m_vec.push_back(file_name);
}
}
chdir("..");
closedir(pdir);
}
private:
// 类外一个vector容器的引用,用于保存文件的绝对路径
std::vector<std::string>& m_vec ;
}; // 文件处理类,该类将多个文件以某种格式格式化文件并将各个文件统一保存到一个文件形成网页库文件。
// 每个文件被处理成<doc><docid>id</docid><doctitle>title</doctitle><docurl>url</docurl><doccontent>content</doccontent></doc>
class FileProcess
{
public:
// 带参数的构造函数,第一个参数为保存着个文件路径的vector容器,第二个参数为传入的字符串用于提取文档中的‘标题’
FileProcess(std::vector<std::string>& vec, std::string& str):m_vec(vec)
{
m_title = str ;
}
// 重载函数调用操作符,传入两个文件名用于保存建好的网页库和单个文档在网页库中的偏移位置
void operator()(const std::string &file_name, const std::string & offset_file)
{ do_some(file_name, offset_file) ;
}
// 建立网页库,并将其以及文档在库中的偏移保存到文件中。
void do_some(const std::string& file_name, const std::string& offset_file)
{
// 用于保存网页库的文件指针
FILE* fp = fopen(file_name.c_str(),"w");
// 用于保存文档在网页库中偏移的文件指针
FILE* fp_offset = fopen(offset_file.c_str(), "w");
if (fp == NULL || fp_offset == NULL)
{
std::cout << "file open" << std::endl ;
exit(0);
}
int index ;
// 动态创建一个字符数组,用于保存从文件中读取的全部内容
char* mytxt = new char[1024*1024]() ;
int mydocid ;
char myurl[256] = "" ;
// 动态创建一个字符数组,用于保存文件内容
char* mycontent = new char[1024 * 1024]() ;
// 保存文档标题
char* mytitle = new char[1024]() ;
// 依次处理各个文档。处理包括:生成文档id(该id具有全局唯一性),提取文档标题,生成文档url(文档的绝对路径),提取文档内容
for (index = 0 ; index != m_vec.size(); index ++)
{
memset(mytxt, 0, 1024*1024);
memset(myurl, 0, 256);
memset(mycontent, 0, 1024* 1024);
memset(mytitle, 0, 1024);
// 打开指定的文档
FILE * fp_file = fopen(m_vec[index].c_str(), "r");
// 读取文档,并将标题保存到mytitle
read_file(fp_file, mycontent, mytitle);
fclose(fp_file);
mydocid = index + 1 ;
strncpy(myurl, m_vec[index].c_str(), m_vec[index].size());
// 将文档格式化成指定格式的串
sprintf(mytxt, "<doc><docid>%d</docid><docurl>%s</docurl><doctitle>%s</doctitle><doccontent>%s</doccontent></doc>\n", mydocid, myurl, mytitle, mycontent);
// 算出文档在网页库的起始位置
int myoffset = ftell(fp); // 函数 ftell 用于得到文件位置指针当前位置相对于文件首的偏移字节数。
int mysize = strlen(mytxt);
char offset_buf[128]="";
// 文档的偏移通过 (文档id 文档在网页库的起始位置 文档的大小)这三个数字来确定, 在文件中占一行
// 将文档偏移信息写入到偏移文件中去
fprintf(fp_offset,"%d\t%d\t%d\n",mydocid, myoffset, mysize);
// 将格式化后的文档写入网页库中
write_to_file(fp, mytxt);
}
fclose(fp);
}
// 读取文档的内容,并提取标题,分别把内容和标题保存到mycontent 和 mytitle所指向的空间中去
void read_file(FILE* fp , char* mycontent, char* mytitle )
{
int iret ;
const int size = 1024 * 1024 ;
char* line = new char[1024]() ;
int pos = 0 ;
// 循环读取文档内容
while(1)
{
int iret = fread( mycontent + pos, 1, size - pos, fp);
if (iret == 0)//如果文档读完,则跳出循环
{
break ;
}
else //如果没有读完,则接着原来的地方继续读
{
pos += iret ;
}
}
// 将文件指针重新回到文档的开头,用于提取标题
rewind(fp) ;
// count 记录当前读到的行数,flag记录是否已经找到标题(0代表没有找到,1代表已经找到)。
int count = 0, flag = 0 ; ;
// 依次取出文档的前11行 , 看看每行有没有 ‘标题’二字,如果有则将改行作为标题,如果没有则直接将下一行(第12行)作为标题
// 如果整篇文档没有11行,则直接将第一行作为标题
while (count <=10 && fgets(line, 512, fp) != NULL)
{
std::string str_line(line);
// 如果改行有‘标题’ 二字
if ( str_line.find(m_title.c_str(), 0) != std::string::npos)
{
// 将该行赋值给mytitle,作为标题
strncpy(mytitle, str_line.c_str(), str_line.size());
flag = 1 ;
break ;
}
count ++ ; }
if (count < 11 && flag == 0)// 如果文档没有12行,将第一行作为标题
{
rewind(fp);
fgets(mytitle,1024, fp );
}
else if (count == 11 && flag == 0)// 如果有12行,则将12行作为标题
{ fgets(mytitle,1024, fp );
} }
// 将格式化后的文档写到网页库文件中
void write_to_file(FILE* fp, char* mytxt)
{
int iret , pos = 0 ;
int len = strlen(mytxt);
// 循环写到网页库文件中,直到写完
while (1)
{
iret = fwrite(mytxt + pos, 1, len - pos, fp);
len = len - iret ;
if (len == 0)
{
break ;
}
}
}
private:
// 保存文件路径的容器的引用。
std::vector<std::string>& m_vec ;
// 用于保存提取标题
std::string m_title ;
std::map<int, std::pair<int, int> > m_offset ;
}; void show(std::vector<std::string>::value_type& val)
{
std::cout << val << std::endl ;
} int main(int argc, char* argv[]) //exe src_txt_dir ripepage_filename offset_file_name
{
// 初始化一个容器,用于保存文档的路径
std::vector<std::string> str_vec ; // 定义一个扫描目录的对象
DirScan mydirscan(str_vec);
mydirscan(argv[1]); // 定义一个文件处理对象
FileProcess myfileprocess(str_vec, title);
myfileprocess(argv[2], argv[3]); std::cout << "Over" << std::endl ;
return 0 ;
}
2. 网页去重
网页去重生成新的位置偏移文件newOffset.lib。
1. 根据网页的位置偏移文件offset.lib,从网页库文件ripepage.lib中依次将每一个网页的内容读入内存中。
内存中以vector<page>来存储网页
其中page为自定义的class,该类将硬盘网页库中的每一个网页文件抽取出docid,doctitle,docurl,doccontent(这4项每一项均用string存储),网页中每个单词出现的词频(使用unordered_map<string, int> mapWordFreq来进行存储),并且封装了计算每一个网页的哈希指纹等方法
2. 使用分词程序对每个网页的content进行分词,分词结果存入一个临时的vector<string>,并且完成去除停用词的步骤,大致代码如下:
std::vector<std::string> Split::wordSplit(const char* pageContent) {
size_t pageContentSize = strlen(pageContent);
char* contentAfterSplit = new char[6 * src_len]() ;
// 中科院分词处理程序,分词后的内容以字符串形式存放在contentAfterSplit字符数组中
ICTCLAS_ParagraphProcess(pageContent, pageContentSize, contentAfterSplit, CODE_TYPE_GB, 0);
std::istringstream sin(contentAfterSplit);
std::string word ;
// 存放分词结果
std::vector<std::string> vecWord;
while(sin >> word) {
if(!conf.setStoplist.count(word) && word[0] != '\r') {
vecWord.push_back(word);
}
}
delete [] contentAfterSplit ;
return vecWord ;
}
3. 统计每个网页单词出现的词频
使用unordered_map<string, int> mapWordFreq来进行存储
void Page::getWordFreq(std::vector<std::string>& vecWord) // 参数vecWord为网页经分词其除去停用词后的返回结果
{
// std::unordered_map<std::string , int> mapWordFreq 为网页类page的数据成员;
std::vector<std::string>::iterator iter ;
for (iter = vecWord.begin(); iter != vecWord.end(); iter ++) {
mapWordFreq[*iter] ++ ;
}
}
4. 根据vector<page>中每一个网页的词频词典mapWordFreq,可以得到在所有网页中出现过的单词
将每一个网页中的每一个单词放入一个hashset中即可,此处定义为unordered_set<string> setAllWords
统计setAllWords中的每一个单词在所有网页中出现过的次数
遍历setAllWords中的每一个单词,看其是否在每一个网页的mapWordFreq中即可,
此处用unordered_map<string, int> mapWordFreqInAllPage来存储
5. 计算每一个网页中每个单词的TF-IDF值
使用unordered_map<string, double> mapTFIDFOfWord来存储
遍历由3获取的词频词典unordered_map<string, int> mapWordFreq,结合unordered_map<string, int> mapWordFreqInAllPage,很容易就可以获得每一个单词的TF-IDF值,计算公式如下:
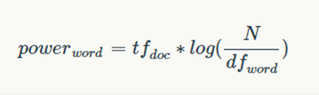
tfdoc即为单词在本网页中出现的次数(词频),N为网页总数,dfword为该单词所出现过的网页数。
TF-IDF值表明了一个单词在网页中的重要性,一个词在网页中预测主题的能力越强,那么它的权重(TF-IDF值)越大。
对网页中每一个词的TF-IDF值进行归一化,公式如下:
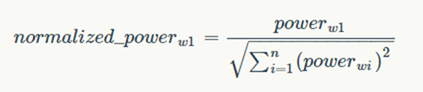
6. 计算每一个网页的哈希指纹(simhash方法)
simhash方法,先将单词使用MD5算法映射成64位的二进制向量,然后将权重融入向量中,形成一个实数向量。假设某个词的权值(TF-IDF)为w,则对二进制向量做如下改写:如果二进制的某个比特位是数值1,则实数向量中对应位置改写为w;如果比特位数值为0,则实数向量中对应位置改写为-w,即权值的负数。通过以上规则,就将二进制向量改写为体现了单词权重的实数向量。
当网页中的每一个单词都进行了上述改写后,对所有单词的实数向量累加获得一个代表文档整体的实数向量。
最后一步,再次将实数向量转换为二进制向量,转换规则如下:如果对应位置的数值大于0,则设置为二进制数字1;如果小于0,则设置为二进制数字0。
哈希指纹存放在unordered_map<string(docid), string(指纹)> fingerPrint中。
7. 利用哈希指纹对网页进行去重
如果两个网页的哈希指纹的海明距离小于3,我们则判断这两个网页为相同(相似)的网页。
8. 在网页去重的过程中,更新vector<page>
//网页去重
void removeDupPage(std::vector<Page>& vecPage) {
int i , j ; for (i = 0 ; i!= vecPage.size() - 1; i ++) {
for (j = i + 1 ; j != vecPage.size(); j ++) {
if (vecPage[i] == vecPage[j]) { // 重载了Page类的operator==,利用哈希指纹判断两篇文章是否相似 MyPage tmp = vecPage[j] ;
vecPage[j] = vecPage[vecPage.size() - 1] ;
vecPage[vecPage.size() - 1] = tmp ; vecPage.pop_back() ; j -- ;
}
}
}
网页去重后,生成新的位置偏移文件newOffset.lib
注意:在配置类conf中有将原来的位置偏移文件offset.lib加载到内存的方法
存储offset.lib的格式为:std::unordered_map<int, std::pair<int, int> > m_offset
void updateOffset(const std::vector<Page> &vecPage) {
std::ofstream of(conf.m_conf["mynewoffset"].c_str());
if (!of) {
std::cout << "open mynewoffset fail " << std::endl ;
exit(0);
}
//将去重之后的文档的偏移信息重新保存到一个新的偏移文件中去
for (page_index = 0 ; page_index != vecPage.size(); page_index ++ ) {
of << atoi(vecPagevecPage[page_index].m_docid.c_str()) <<" "
<<conf.m_offset[atoi(vecPage[page_index].m_docid.c_str()) ].first <<" "
<<conf.m_offset[atoi(page_vec[page_index].m_docid.c_str()) ].second << std::endl;
}
of.close();
}
3. 建立倒排索引文件
建立 词-文章 的倒排索引文件invert.lib
格式为:word1 <doc1, weight> <doc2, weight> … <docn, weight>
word2 <doc1, weight> <doc2, weight> … <docn, weight>
……
wordm <doc1, weight> <doc2, weight> … <docn, weight>
倒排索引存储格式为:std::unordered_map<std::string, std::vector<std::pair<int,int> > > mapReverseIndex
// 生成倒排索引
void invert_index(std::vector<MyPage> &vecPage,
std::unordered_map<std::string, std::vector<std::pair<int,int> > > &mapReverseIndex)
{
int index ;
//遍历每一个Page对象
for (index = 0 ; index != vecPage.size(); index ++) { std::map<std::string, int >::iterator iter ;
// unordered_map<string, double> mapTFIDFOfWord
for (iter = (vecPage[index].mapTFIDFOfWord).begin() ;
iter != vecPage[index].mapTFIDFOfWord.end();
iter ++ )
{
mapReverseIndex[iter->first].push_back
( std::make_pair(atoi(vecPage[index].m_docid.c_str()),iter->second) );
}
}
}
注意,需要从内存写回文件做好备份
4. 程序查询逻辑
首先将查询语句进行分词去停用词,获得一个词组,计算该词组的每个词的权重(通过 TF*IDF),然后根据网页库的倒排索引(已经提前加载到内存),找出包含查询词组的各个文档,然后通过计算找到的每个文档与查询语句(将查询语句当成一篇文档)的余弦相似度,根据这个余弦相似度给找到的文档集合按照从大到小排个序(余弦值越大,相似性越高),最后将结果封装成json格式的数据返回 。
(待续)
[Project] MiniSearch文本检索简介的更多相关文章
- POM (Project Object Model)简介
1 概念介绍 一个项目所有的配置都放置在 POM 文件中:定义项目的类型.名字,管理依赖关系,定制插件的行为等等.比如说,你可以配置 compiler 插件让它使用 java1.5 来编译. < ...
- Eclipse创建第一个Servlet(Dynamic Web Project方式)、第一个Web Fragment Project(web容器向jar中寻找class文件)
创建第一个Servlet(Dynamic Web Project方式) 注意:无论是以注解的方式还是xml的方式配置一个servlet,servlet的url-pattern一定要以一个"/ ...
- sublime Text 些许使用配置
在安装numpy等库函数时,通过“命令提示符”操作显示库函数已经安装完毕,在pycharm中可是依然显示引用失败,尝试使用sublime,显示可用,遂好好使用sublime,现配置成想用的模式. 1 ...
- sublime 配置大全
最近玩 python ,一般用的编译器是 pycharm ,功能强大,但是苦于启动速度遂准备换坑,瞄上了 sublime .这里记录一下 sublime 的设置以及坑爹项,需要注意的是我用的是 sub ...
- 所有selenium相关的库
通过爬虫 获取 官方文档库 如果想获取 相应的库 修改对应配置即可 代码如下 from urllib.parse import urljoin import requests from lxml im ...
- django总结 --》内容(django建project开始的大致流程、ORM简介)
1 安装: pip install django==1.11.9 另外:在pycharm中安装 django,在下图中七步走 2. 新建Django项目 django-admin startpro ...
- Project简介
Microsoft Project (Project)是一个国际上享有盛誉的通用的项目管理工具软件,凝集了许多成熟的项目管理现代理论和方法,可以帮助项目管理者实现时间.资源.成本的计划.控制,协助项目 ...
- .NET Core项目从xproj+project.json向csproj迁移简介
3月7日,微软发布了Visual Studio 2017 RTM,与之一起发布的还有.NET Core Runtime 1.1.0以及.NET Core SDK 1.0.0,尽管这些并不是最新版,但也 ...
- 简介 - PMP(Project Management Professional)
PMP(Project Management Professional) 官网(英文报名):https://www.pmi.org/ 中文注册:http://exam.chinapmp.cn/ Boo ...
随机推荐
- leetcode207
拓扑排序问题. class Solution { public: bool canFinish(int numCourses, vector<pair<int, int>>&a ...
- MySQL innodb_autoinc_lock_mode 详解
innodb_autoinc_lock_mode这个参数控制着在向有auto_increment 列的表插入数据时,相关锁的行为: 通过对它的设置可以达到性能与安全(主从的数据一致性)的平衡 [0]我 ...
- 使用jQuery+huandlebars判断类型的helper
兼容ie8(很实用,复制过来,仅供技术参考,更详细内容请看源地址:http://www.cnblogs.com/iyangyuan/archive/2013/12/12/3471227.html) & ...
- JDK中的注解简单了解
0.注解(注解是给编译器看的东东) 注解的定义方式是@Interface,注解属性定义是类似于普通类的方法定义的,注解属性赋值是使用default关键字完成的,如下图所示 注解在定义时可以给默认值,也 ...
- 1、detail页面 /items/detail/:id
<template> <div class="item_detail"> <van-swipe :autoplay="3000" ...
- linux网络日志分析
1.清空日志的技巧 2.访问日志格式分析 3. web日志统计举例
- jdango 使用oss存储
安装django-aliyun-oss2-storage-0.1.5.tar.gz settings文件添加 MEDIA_ROOT = os.path.join(BASE_DIR,'upload/') ...
- weld
weld - 必应词典 美[weld]英[weld] v.焊接:熔接:锻接:使紧密结合 n.焊接点:焊接处 网络焊缝
- [leetcode]35. Search Insert Position寻找插入位置
Given a sorted array and a target value, return the index if the target is found. If not, return the ...
- [leetcode]46. Permutations全排列(给定序列无重复元素)
Given a collection of distinct integers, return all possible permutations. Input: [1,2,3] Output: [ ...