numactl 修改 非统一内存访问架构 NUMA(Non Uniform Memory Access Architecture)模式
当今数据计算领域的主要应用程序和模型可大致分为三大类:
(1)联机事务处理(OLTP)、
(2)决策支持系统(DSS)
(3)企业信息通讯(BusinessCommunications)
上述三类系统设计人员在计算平台的体系结构方面可以选择:
(1)小型独立服务器模式
(2)对称多处理SMP(Symmetrical Multi-Processing)模式
(3)大规模并行处理MPP(Massive Parallel Processing)模式
(4)非统一内存访问架构NUMA(Non Uniform Memory Access Architecture)模式
。因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,
SMP的缺点是可伸缩性有限,因为在存储器接口达到饱和的时候,增加处理器并不能获得更高的性能。
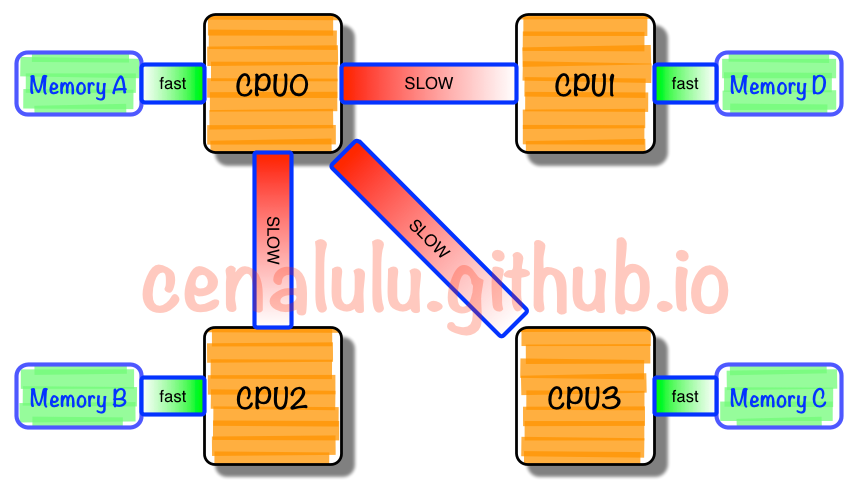
NUMA是什么
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间
(Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(Remote Access)。
所以NUMA(Non-Uniform Memory Access)就此得名。
二、NUMA相关的策略
1、每个进程(或线程)都会从父进程继承NUMA策略,并分配有一个优先node。如果NUMA策略允许的话,进程可以调用其他node上的资源。
2、NUMA的CPU分配策略有cpunodebind、physcpubind。
cpunodebind规定进程运行在某几个node之上
physcpubind可以更加精细地规定运行在哪些核上
3、NUMA的内存分配策略有localalloc、preferred、membind、interleave。
localalloc规定进程从当前node上请求分配内存
preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node
membind可以指定若干个node,进程只能从这些指定的node上请求分配内存
interleave规定进程从指定的若干个node上以RR算法交织地请求分配内存
使用numactl –interleave来修改NUMA策略即可。
参考:
cpu三大架构 numa smp mpp
cenalulu: numa
numactl 修改 非统一内存访问架构 NUMA(Non Uniform Memory Access Architecture)模式的更多相关文章
- ARMv8 内存管理架构.学习笔记
http://blog.csdn.net/forever_2015/article/details/50285955 版权声明:未经博主允许不得转载,请尊重原创, 谢谢! 目 录 第1章 分级存储 ...
- Buffer Data RDMA 零拷贝 直接内存访问
waylau/netty-4-user-guide: Chinese translation of Netty 4.x User Guide. 中文翻译<Netty 4.x 用户指南> h ...
- Linux内核内存管理架构
内存管理子系统可能是linux内核中最为复杂的一个子系统,其支持的功能需求众多,如页面映射.页面分配.页面回收.页面交换.冷热页面.紧急页面.页面碎片管理.页面缓存.页面统计等,而且对性能也有很高的要 ...
- 修改oracle数据库内存报错
今天修改oracle数据库内存时, alter system set memory_max_target=10240M scope=spfile;语句正确修改:但重启时却报错 : SQL> al ...
- Linux内核内存管理-内存访问与缺页中断【转】
转自:https://yq.aliyun.com/articles/5865 摘要: 简单描述了x86 32位体系结构下Linux内核的用户进程和内核线程的线性地址空间和物理内存的联系,分析了高端内存 ...
- C++异常机制的实现方式和开销分析 (大图,编译器会为每个函数增加EHDL结构,组成一个单向链表,非常著名的“内存访问违例”出错对话框就是该机制的一种体现)
白杨 http://baiy.cn 在我几年前开始写<C++编码规范与指导>一文时,就已经规划着要加入这样一篇讨论 C++ 异常机制的文章了.没想到时隔几年以后才有机会把这个尾巴补完 :- ...
- Memory Ordering (注意Cache带来的副作用,每个CPU都有自己的Cache,内存读写不再一定需要真的作内存访问)
Memory Ordering Background 很久很久很久以前,CPU忠厚老实,一条一条指令的执行我们给它的程序,规规矩矩的进行计算和内存的存取. 很久很久以前, CPU学会了Out-Of ...
- 【CUDA 基础】4.3 内存访问模式
title: [CUDA 基础]4.3 内存访问模式 categories: - CUDA - Freshman tags: - 内存访问模式 - 对齐 - 合并 - 缓存 - 结构体数组 - 数组结 ...
- CUDA Pro:通过向量化内存访问提高性能
CUDA Pro:通过向量化内存访问提高性能 许多CUDA内核受带宽限制,而新硬件中触发器与带宽的比率不断提高,导致带宽受限制的内核更多.这使得采取措施减轻代码中的带宽瓶颈非常重要.本文将展示如何在C ...
随机推荐
- There is a chart instance already initialized on the dom!警告
使用Echarts插件的时候,多次加载会出现There is a chart instance already initialized on the dom.这个错误,改插件已经加载完成. 并且如果你 ...
- AWS免费套餐服务器部署NETCORE网站
之前的linode充了5美元,一个月就用完了,还是创建的最便宜的服务器的!!! 以前一直想用用aws的所谓的免费套餐服务器的,现在linode过期了,可以试着用用了 下面是我的操作流程,包含错误及解决 ...
- Atitit 关于处理环保行动联盟和动物解放阵线游击队的任命书 委任状
Atitit 关于处理环保行动联盟和动物解放阵线游击队的任命书 委任状 Uke 集团文化部部长兼emir 大酋长圣旨到!! In god we trust ,Emir Decree大酋长圣旨:: En ...
- [k8s]k8s的控制层kubelet+docker配合调度机制(k8架构)
意外停掉一台node的kubelet,发现调度有问题,研究了下调度的细节 k8s架构 控制层- kubelet(配合节点docker工作) 数据层- kube-proxy 逻辑图: object 参考 ...
- 双网卡双线路DNS解析分析
在企业网络维护过程中我们经常会遇到这样或那样的奇怪问题,而很多问题需要有深厚的理论知识才能解决.而随着网络的飞速发展越来越多的中小企业开始尝试通过多条线路来保证网络的畅通,一方面双网卡下的双线接入可以 ...
- vs code 快捷键中英文对照
常用 General 按 Press 功能 Function Ctrl + Shift + P,F1 显示命令面板 Show Command Palette Ctrl + P 快速打开 Quick O ...
- C语言 结构体中的零长度数组
/* C语言零长度数组大小和取值问题 */ #include <stdio.h> #include <stdlib.h> #include <string.h> s ...
- tracert traceroute
二者都用于探测数据包从源到目的经过路由的IP,但两者探测的方法却有差别.不同点:一.应用环境不同tracert是应用在windows下.traceroute则是应用在linux/BSD/router/ ...
- jsp中相对路劲
.代表当前目录 ..代表上一层目录 例如:如下文件,aliCashier.html要引入images下的图片,应该写成../../static/images/logo.png,此处会找到本地静态路径. ...
- flask多个app应用组合
由于之前写得接口太多了,分为了多个app,每个app里面有几个接口.部署次数需要很多次,修改成部署一次,在不改变代码的情况下,不使用蓝图,最快的方式就是这样修改. from werkzeug.wsgi ...