9.1(java学习笔记)正则表达式
一、正则表达式
1.1正则表达式
正则表达式是描述一种规则,通过这个规则可以匹配到一类字符串。
2.1正则语法
2.1.1普通字符:字母、数字、下划线、汉字以及没有特殊意义的符号都是普通字符。
正则表达式为普通字符时,直接匹配该字符。

正则表达式go为普通字符,故直接匹配相同部分。(图中高亮为匹配到得)
2.1.2转义字符:除了普通字符外,还有一些特殊字符并不能直接表示,需要在前面加上‘\’。
这类字符称为转义字符,同样的正则表达式为转义字符时,直接匹配对应字符。
简单转义字符:
| \n | 代表换行符 |
| \t | 代表制表符 |
| \\ | 代表\本身 |
| \^ , \$ , \. , \( , \) , \{ , \} , \? , \+ , \* , \| , \[ , \] | 代表自身(^,$...) |
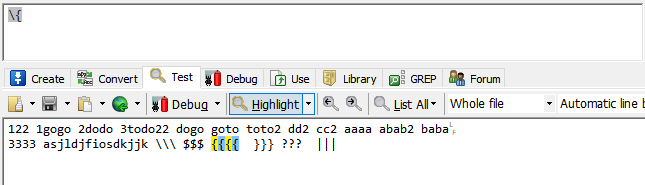
例如要匹配‘{’ 不能直接输入‘{’ ,而是要输入‘\{’ 才代表‘{’。
2.1.3标准字符集合
能与‘多种字符’匹配的表达式,可以代表一类字符。
大写作用域相反。
\d:任意一个数字(0~9)

可以看到只要是数字都被匹配了,注意是一个数字,所以高亮颜色是交替显示的。
如果是\D就代表任意一个非数字字符。

\w:任意一个字母、数字或下划线。即(a-z A-Z 0-9 _)
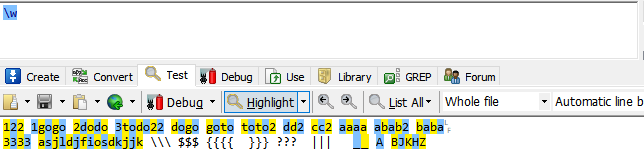
只要是字符、数字、下划线都被匹配了
\W代表任意一个非字母、数字或下划线字符。
\s:任意一个空白字符(即空格,制表符(Tab),换行符等空白字符)
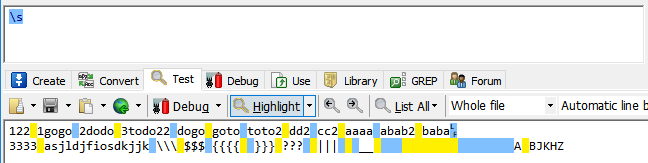
\S代表任意一个非空白字符。
.代表任意一个字符(换行符除外)

2.1.4自定义字符集合
上面的标准字符集合含义是固定的,这些显然无法满足我们的一些需求。
这个时候就要用到自定义字符集合了。
[abc..]匹配[]中任意一个字符
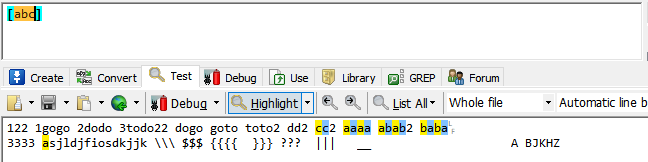
括号中是abc则匹配a或b或c。
[^abc..]匹配除了括号内内容的其他内容。

[^abc]代表匹配除了abc字符的其他字符。
[a-z]匹配a-z之间任意一个字符

[a-zA-Z0-9]代表匹配任意一个a-z A-Z 0-9之间的字符。
1.特殊字符放入中括号中,则失去特殊含义只表示其本身。例如.是代表所有字符,但是[.]只表示.本身。
2.标准字符集合中,除小数点外,如果被放入中括号,则保持原有含义。例如[\d]代表数字。
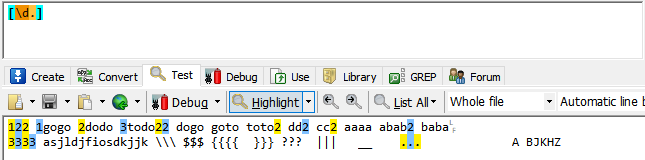
[\d.]代表数字和 .
中扩号中转义字符仍然要加\
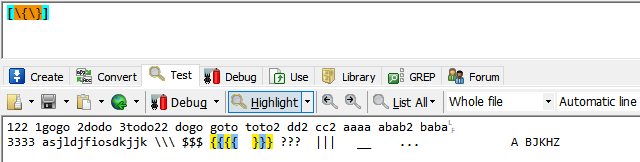
[\{\}]代表 { }
2.1.5量词
量词顾名思义就是表示数量的词。
{n}:修饰前一个表达式出现的次数。
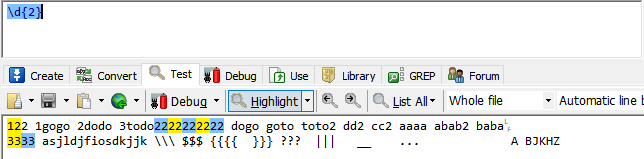
例如这里的\d{2} 类似 \d\d,所以数字是两两匹配的。
注意是修改前一个表达式,\d\d{2}代表7个数字,而不是12个,要想表示12个数字可以用(\d\d){12}表示
{m,n}修饰前一个表达式,代表最少出现m次,最多出现n次。

我们看\d{2,5}代表匹配2-5位数字的字符串,可是我们发现匹配的字符串没有两位的,
这时因为正则默认遵循贪婪模式,即匹配到的越多越好。所有但有2个数字满足条件时仍然会继续匹配,
直到下一位不是数字,或者当前匹配的位数已达到最大位数n时才终止。
我们只需要在最后加个?即可将贪婪模式修改为非贪婪模式。即匹配两位就开始下一个匹配。
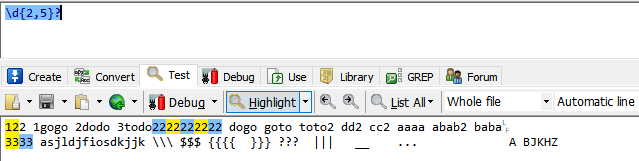
{m,}最少m次,最多可以是任意。
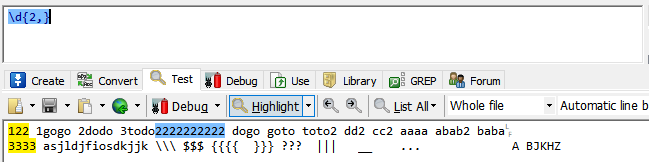
\d{2,}代表最少两个数字,但由于最多没有指定,默认又是贪婪模式,所以匹配越多越好,直到下一个字符不满足条件才会终止。
注意没有{,m}这种写法。
?代表{0,1} 即 \d? == \d{0,1}

最少出现0次,最多1次,由于是贪婪模式,故只有在下一个字符不是数字或到达最大次数(一次)终止。
所以匹配一位数字。
+代表最少出现1次,最多出现次数为任意。类似{1,}
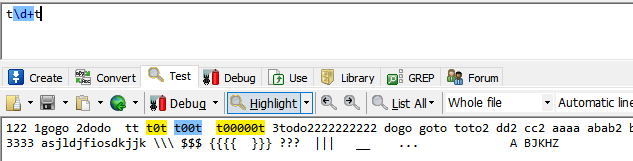
t\d+t类似t\d{1,}t 代表t~t直接出现一个或多个数字,由于是贪婪模式,故数字越多越好。
*代表出现或不出现任意次数,类似{0,}
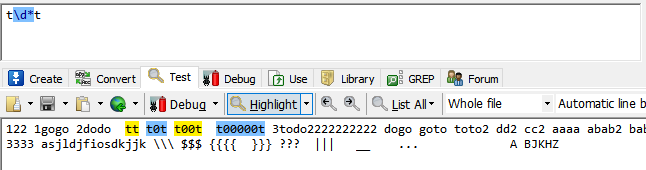
t\d*t代表t~t直接出现数字,或者不出现数字都可以。
2.1.6字符边界
下述符号匹配的不是具体的字符而是符合条件的位置,所有又称为零宽匹配,因为没有匹配具体的字符是没有宽度的。
^代表字符开头匹配
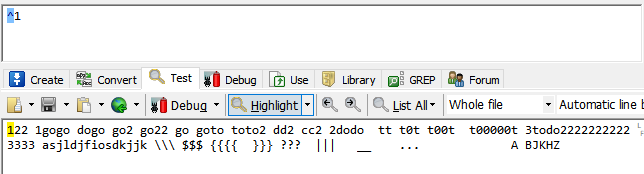
会匹配字符串开头的1,这时将两行字符串看做一整个字符串,只有一个开头和一个结尾。
^1表示在字符串开头匹配1。^2代表在字符串开头匹配2,但是字符串开头没有2,所以不会显示。
$表示在字符串末尾匹配

显然字符串末尾是Z不是H所以没有匹配,换做Z$就会匹配末尾的Z。
\b代表单词边界,就是匹配\b左右两边字符不全是\w(a-z A-Z 0-9)
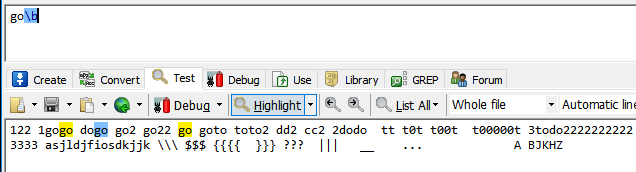
前面说了\b是匹配左右两边字符不全是\w,例如第一个被匹配的go的\b 左边是o可以用\w表示,右边是空格 不能用\w表示,所以匹配。
再来看下第一个不能匹配的go(1gogo中第一个go) ,它\b左边是o右边是g都可以\w表示所以不能匹配。
2.1.7正则匹配模式
1.忽略大小写模式
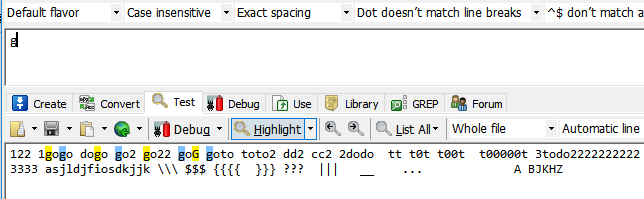
我们可以看到无论是大写的G还是小写的g都被匹配了,这时忽略大小写模式。
我们看表达式输入框上面一栏的第二个 Case insensitive 选择不敏感模式,即忽略大小写。
还可以设置为 Case sensitive敏感模式,即不忽略大小写。
2.单行模式
将整个文本看做一个字符串,只有一个开头和一个结尾。
之前在字符边界中将两行看做一行,这个字符串只有一个开头和一个结尾,就是单行模式。

我们看最后一个don't match ait line breaks 这个代表单行模式(single-line mode),将文本看做一个字符串,只有一个开头和结尾。
3.多行模式

此时修改为多行模式,每一行看做一个字符串。
2.1.8选择符和分组
| 表示或的关系。

a|b表示 a或者b都可以。
()捕获组
1.在被修改时次数时,括号中的表达式可以作为整体被修饰。
例如(\d\d){2}代表4个数字
2.()中表达式的内容可以被单独获取到,一般通过反向引用表示。
3.每一括号会被分配一个编号,后续通过这个编号引用对应结果。
结合上述2,3 例如(\w{2})\1 我们指定\w{2} 代表任意两个字符。
此时(\w{2})就代表任意两个字符,此时只有一个括号所以编号是1,
\1就代表对(\w{2})内容的引用,例如(\w{2})匹配的aa,那么\1也代表aa。
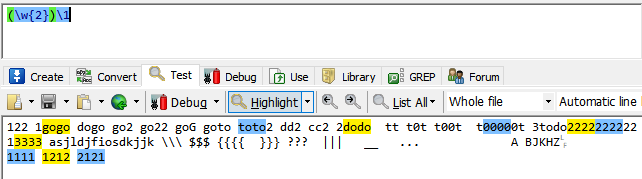
此时就是匹配4位字符,这4位前2个字符和后面2个字符相同的.

第一个(\d)的编号1,第二个编号是2,所以就可以匹配四位相同的数字或者ABAB形式的数字。
括号编号是从左往右数,以左边括号为准。
()()()这种括号编号很好理解依次为1,2,3
(()())这种括号也是从左往右数,第一左括号的编号是1,所以最大的括号编号代表1.
里面两个小括号代表2,3.
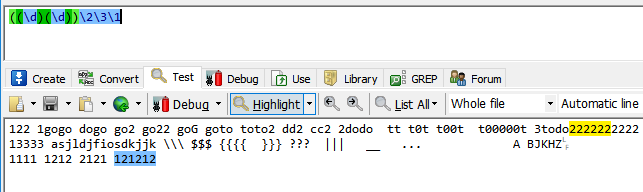
我们看121212这个,最大括号的编号是1,代表的12,。第一个小括号的编号是2,代表1。第二个小括号编号是3,代表2.
\2代表1,\3代表2,\1代表12.所以((\d)(\d))\2\3\1 表示121212.
222222分析如上述方法。
(?:)非捕获组,上述的捕获组会保存捕获的内容,既然要保持就肯定要占内存,有的时候我只需要组织表达式(捕获组功能1),
并不需要它保存内容,就可以是用(?:)这种写法只会组织内容,例如(?:\d\d){2}就代表4位数字,当然既然这个不保存捕获的内容,
自然无法使用\1这种引用。
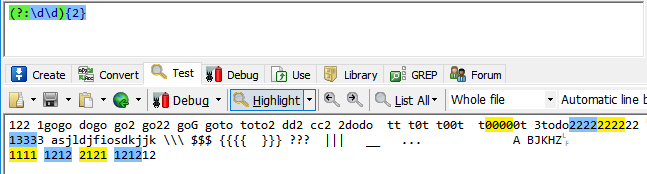
只组织内容不保存,无法引用捕获的内容。优点就是省内存。
2.1.9(预搜索)零宽断言
只对子表达式进行匹配,子表达式结果不计入最终的匹配结果。
(?exp):断言出现位置后的内容能匹配表达式exp。

\w代表数字字母下划线,+表示最少一个,后面的(?=ing)表示断言出现位置的后面要等于ing。
但是最终的匹配结果并不包含ing。
(?!exp):断言出现位置后面不能匹配表达式exp
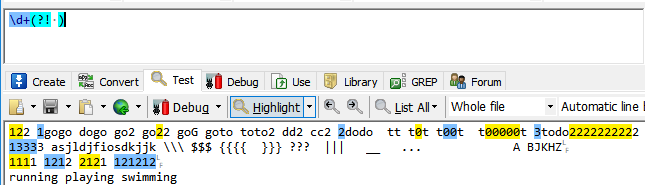
\d+(?! )代表数字后面不以空格结尾的,第三行的121212后面是换行符\n,不是空格.
(?<!exp):表示断言出现位置前面的内容不能匹配表达式exp
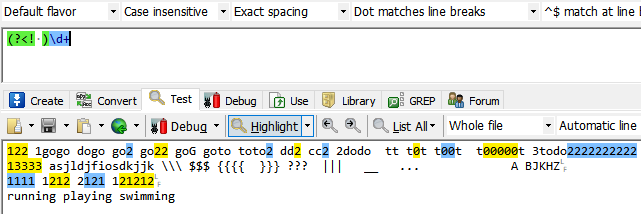
匹配数字前面不是空格的子串。
(?<=exp):表示断言出现位置前面的内容能匹配表达式exp

表示前面时空格的数字子串。
二、正则在java中使用
在java中使用正则需要使用以下两个类。
Pattern:正则表达式的编译表示,也就是说一个正则表达式要对应一个Pattern对象。
主要方法:
static Pattern compile(String regex);将正则表达式regex编译为Pattern对象。(也就是说可将一个Pattren看做一个正则表达式)
Matcher matcher(CharSequence input);创建一个匹配器,该匹配器会的用于匹配对应的输入input。匹配规则就是的正则表达式。
static boolean matches(String regex, CharSequence input);根据regex的规则匹配input,匹配返回True反之防护False。
String[] split(input);将input按照指定规则切割。
Matcher:将规则与字符序列进行匹配的引擎。
主要方法:
boolean matches();将规则与整个字符序列进行匹配。满足防护True,反之返回False。
String replaceAll(String replacement);将满足匹配规则(正则表达式)的字符替换为replacement。
boolean find();寻找满足匹配条件的子序列。
String group();返回满足完整匹配条件的子序列
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class TestRegex{
- public static void main(String[] args){
- // java字符串中\\代表\,故在书写正则表达式时需将\用\\代替
- String regex = "\\d+";//匹配规则:一个或多个数字
- String input1 = "123456";
- String input2 = "123aa456";
- //Pattern将正则表达式编译为一个实例,这个实例代表一个正则表达式。
- Pattern p = Pattern.compile(regex);
- Matcher m = p.matcher(input1);//创建一个匹配器,匹配输入内容。
- //input全为数字,故满足匹配条件
- System.out.println(m.matches());//开始匹配
- //input2数字之间有空格,故不满足匹配条件。
- //要使匹配结果为Ture,是整个字符序列满足匹配条件,
- //123aaa456中,虽然123 456都满足匹配条件,但是123aa456整个整体不满足。
- //123,456是满足条件的子序列,可以通过find和group输出。
- System.out.println(regex + " " + input2+Pattern.compile(regex).matcher(input2).matches());
- //此处邮箱规则定义:至少一个字母数字下划线@至少一个字母数字下划线(结尾为.com或.cn)
- System.out.println("是否为邮箱" + Pattern.matches("\\w+@\\w+(?:\\.cn|\\.com)", "123456@qq.com"));
- }
- }
- 运行结果:
- true
- \d+ 123aa456false
- 是否为邮箱true
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class TestRegex{
- public static void main(String[] args){
- // java字符串中\\代表\,故在书写正则表达式时需将\用\\代替
- String regex = "\\d+";//匹配规则:一个或多个数字
- String input1 = "123456";
- String input2 = "123aa456";
- //Pattern将正则表达式编译为一个实例,这个实例代表一个正则表达式。
- Pattern p = Pattern.compile(regex);
- Matcher m = p.matcher(input2);//创建一个匹配器,匹配输入内容。
- while(m.find()){//寻找满足匹配条件的子序列,有则返回true反之返回false
- //将满足匹配条件的子序列打印出来
- System.out.println(input2+"中满足匹配条件的子序列:"+m.group(0));
- }
- }
- }
- 运行结果:
- 123aa456中满足匹配条件的子序列:123
- 123aa456中满足匹配条件的子序列:456
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class TestRegex{
- public static void main(String[] args){
- // java字符串中\\代表\,故在书写正则表达式时需将\用\\代替
- String regex = "([0-9]+)([a-z]+)";//匹配规则:一个或多个数字
- String input2 = "123aa456a";
- //Pattern将正则表达式编译为一个实例,这个实例代表一个正则表达式。
- Pattern p = Pattern.compile(regex);
- Matcher m = p.matcher(input2);//创建一个匹配器,匹配输入内容。
- while(m.find()){
//输出满足完整匹配规则(([0-9])([a-z]))的子序列.- System.out.println(input2+"中满足匹配条件的子序列:"+m.group());
//输出满足完整匹配规则的子序列中,满足表达式1([0-9]+)的序列- System.out.println("子序列中满足匹配式([0-9]+)的子序列:"+m.group(1));
//输出满足完整匹配规则的子序列中,满足表达式2([a-z]+)的序列- System.out.println("子序列中满足匹配式([a-z]+)的子序列:"+m.group(2));
- }
- }
- }
- 运行结果:
- 123aa456a中满足匹配条件的子序列:123aa
- 子序列中满足匹配式([0-9]+)的子序列:123
- 子序列中满足匹配式([a-z]+)的子序列:aa
- 123aa456a中满足匹配条件的子序列:456a
- 子序列中满足匹配式([0-9]+)的子序列:456
- 子序列中满足匹配式([a-z]+)的子序列:a
上述规则group() group(0)输出的是满足完整表达式([0-9]+)([a-z]+)的子序列。
group(1)则是输出满足完整表示式([0-9]+)([a-z]+)中,第一个表达式([0-9]+)的序列。
group(2)就是完整表达式中第二个表达式([0-z]+),以此类推。
- import java.util.Arrays;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class TestRegex{
- public static void main(String[] args){
- // java字符串中\\代表\,故在书写正则表达式时需将\用\\代替
- String regex = "[a-z]+";//匹配规则:一个或多个数字
- String input2 = "123aa456a";
- Pattern p = Pattern.compile(regex);
- Matcher m = p.matcher(input2);//创建一个匹配器,匹配输入内容。
- //String中的split可以用正则指定切割规则(已有对象,指定规则)
- System.out.println( Arrays.toString(input2.split("[a-z]+")));//以字母为边界切割
- //Pattern中的split方法是需要指定切割切割对象。(已有规则,指定对象)
- System.out.println( Arrays.toString(p.split(input2)));
- //Matcher中将满足规则的部分替换为指定字符,这里指定的规则为一个或多个字母替换为#
- System.out.println((m.replaceAll("#").toString()));
- }
- }
- 运行结果:
- [123, 456]
- [123, 456]
- 123#456#
使用正则可以简便的完成一些复杂的切割和替换。
RegexBuddy下载地址:https://www.52pojie.cn/forum.php?mod=viewthread&tid=762690
9.1(java学习笔记)正则表达式的更多相关文章
- JAVA学习笔记--正则表达式
正则表达式是一种强大而灵活的文本处理工具.使用正则表达式,可以让我们以编程的方式构造复杂的文本,并对输入的字符串进行搜索. 一.基础正则表达式语法(表格来自J2SE6_API) 字符 x 字符 x \ ...
- Java 学习笔记 正则表达式
2019.3.27 正则表达式 \w 单词字符,匹配[]a-zA-Z_0-9] \w{3} 表示匹配3个字符()ab8,abc,a_c,a5_...) \w+ 至少一个,1到多个 \w* 0个到n个 ...
- java学习笔记——正则表达式
NO 方法名称 类型 描述 1 public boolean matches(String regex) 普通 正则验证使用 2 public String replaceAll(String reg ...
- 《Java学习笔记(第8版)》学习指导
<Java学习笔记(第8版)>学习指导 目录 图书简况 学习指导 第一章 Java平台概论 第二章 从JDK到IDE 第三章 基础语法 第四章 认识对象 第五章 对象封装 第六章 继承与多 ...
- Java学习笔记4
Java学习笔记4 1. JDK.JRE和JVM分别是什么,区别是什么? 答: ①.JDK 是整个Java的核心,包括了Java运行环境.Java工具和Java基础类库. ②.JRE(Java Run ...
- java学习笔记06--正则表达式
java学习笔记06--正则表达式 正则表达式可以方便的对数据进行匹配,可以执行更加复杂的字符串验证.拆分.替换等操作. 例如:现在要去判断一个字符串是否由数字组成,则可以有以下的两种做法 不使用正则 ...
- 20155234 2610-2017-2第九周《Java学习笔记》学习总结
20155234第九周<Java学习笔记>学习总结 教材学习内容总结 数据库本身是个独立运行的应用程序 撰写应用程序是利用通信协议对数据库进行指令交换,以进行数据的增删查找 JDBC(Ja ...
- Java学习笔记之---API的应用
Java学习笔记之---API的应用 (一)Object类 java.lang.Object 类 Object 是类层次结构的根类.每个类都使用 Object 作为超类.所有对象(包括数组)都实现这个 ...
- Java学习笔记【一、环境搭建】
今天把java的学习重新拾起来,一方面是因为公司的项目需要用到大数据方面的东西,需要用java做语言 另一方面是原先使用的C#公司也在慢慢替换为java,为了以后路宽一些吧,技多不压身 此次的学习目标 ...
- 0037 Java学习笔记-多线程-同步代码块、同步方法、同步锁
什么是同步 在上一篇0036 Java学习笔记-多线程-创建线程的三种方式示例代码中,实现Runnable创建多条线程,输出中的结果中会有错误,比如一张票卖了两次,有的票没卖的情况,因为线程对象被多条 ...
随机推荐
- hadoop之HDFS与MapReduce
Hadoop历史 雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. 随后在2003 ...
- gitlab迁移升级
一.迁移步骤 1.首先安装最新版本gitlab(gitlab7.2安装) 2.停止旧版本gitlab服务 3.将旧的项目文件完整导入新的gitlab bundle exec rake gitlab:i ...
- MongoDB加索引
1.登陆MongoDB, 命令行在MongoDB主目录下执行:mongo -port 27017 2.切换至需要添加索引的db 并授权 use MeetingBooking db.auth({&quo ...
- Active Directory Domain Services in Windows Server 2016/2012
Applies To: Windows Server 2016, Windows Server 2012 R2, Windows Server 2012 You will find links to ...
- SQLyog 使用笔记,自增主键数据冲突错误
select max(id) from test ; desc test ; insert into test (a,b,c) values ('abc','123-213','test'); RE ...
- mysql 等 null 空值排序
[sqlserver]: sqlserver 认为 null 最小. 升序排列:null 值默认排在最前. 要想排后面,则:order by case when col is null then 1 ...
- 链接加载文件gcc __attribute__ section
在阅读源代码的过程中,发现一个头文件有引用: /** The address of the first device table entry. */ extern device_t devices[] ...
- 跟我一起写 Makefile(一)【转】
转自:http://blog.csdn.net/haoel/article/details/2886 跟我一起写 Makefile 陈皓 概述—— 什么是makefile?或许很多Winodws的程序 ...
- 利用git把本地项目传到github+将github中已有项目从本地上传更新
利用git把本地项目传到github中 1.打开git bash命令行,进入到要上传的项目中,比如Spring项目,在此目录下执行git init 的命令,会发下在当前目录中多了一个.git的文件夹( ...
- 取消SecureCRT的右击粘贴功能
默认为选中时自动复制,右键粘贴 要取消的话在: Options->Global Options ...->Terminal 里面有个Mouse的选项块. Paste on Right/Le ...