Inception-Resnet-V2
零、Inception-Resnet-V2的网络模型
整体结构如下,整体设计简洁直观:
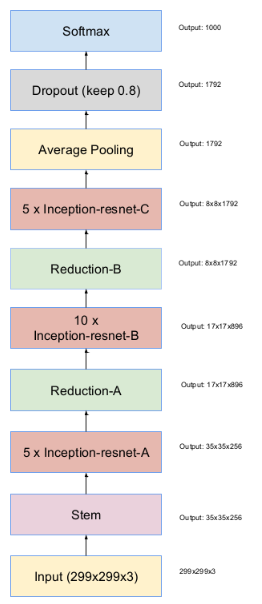
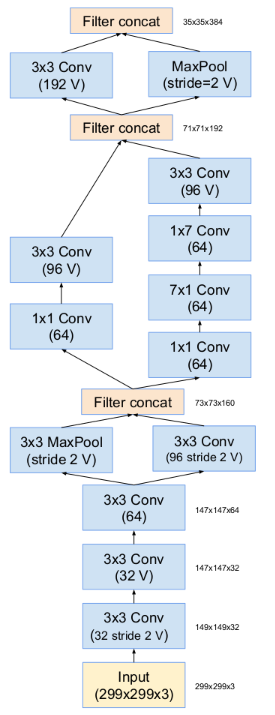
其中的stem部分网络结构如下,inception设计,并且conv也使用了7*1+1*7这种优化形式:
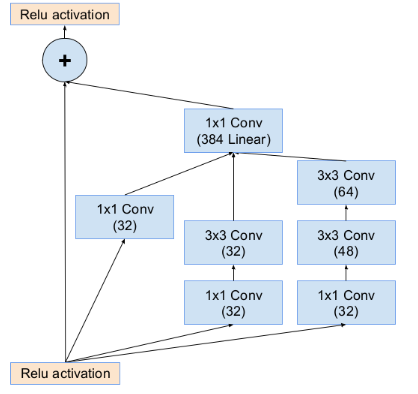
inception-resnet-A部分设计,inception+残差设计:
截自https://my.oschina.net/gyspace/blog/893788
一、Inception
基本思想:不需要人为决定使用哪个过滤器,或是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
细节:网络中存在softmax分支,原因——即便是隐藏单元和中间层也参与了特征计算,它们也能预测图片的分类,它在Inception网络中起到一种调整的效果,防止过拟合。
二、Resnet
残差网络就是残差块的堆叠,这样可以把网络设计的很深;
残差网络和普通网络的差异是,al+2在进行非线性变化前,把al的数据拷贝了一份与zl+2累加后进行了非线性变换;
对于普通的卷积网络,用梯度下降等常用的优化算法,随着网络深度的增加,训练误差会呈现出先降低后增加的趋势,而我们期望的理想结果是随着网络深度的增加训练误差逐渐减小,而Resnet随着网络深度的增加训练误差会一直减小。
三、1*1卷积的主要作用有以下几点:
1、降维( dimension reductionality )。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500*500*20。
2、加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
当1*1卷积出现时,在大多数情况下它作用是升/降特征的维度,这里的维度指的是通道数(厚度),而不改变图片的宽和高。
Inception-Resnet-V2的更多相关文章
- GoogLeNet 之 Inception v1 v2 v3 v4
论文地址 Inception V1 :Going Deeper with Convolutions Inception-v2 :Batch Normalization: Accelerating De ...
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
from:https://blog.csdn.net/qq_14845119/article/details/73648100 Inception v1的网络,主要提出了Inceptionmodule ...
- Feature Extractor[ResNet v2]
0. 背景 何凯明大神等人在提出了ResNet网络结构之后,对其做了进一步的分析工作,详细的分析了ResNet 构建块能起作用的本质所在.并通过一系列的实验来验证恒等映射的重要性,并由此提出了新的构建 ...
- inception - resnet
只有reduction-A是共用的,只是改了其中的几个参数 linear是线性激活. 结构是一样的
- AI:IPPR的数学表示-CNN结构进化(Alex、ZF、Inception、Res、InceptionRes)
前言: 文章:CNN的结构分析-------: 文章:历年ImageNet冠军模型网络结构解析-------: 文章:GoogleLeNet系列解读-------: 文章:DNN结构演进Histor ...
- 海康威视研究院ImageNet2016竞赛经验分享
原文链接:https://zhuanlan.zhihu.com/p/23249000 目录 场景分类 数据增强 数据增强对最后的识别性能和泛化能力都有着非常重要的作用.我们使用下面这些数据增强方法. ...
- 学习笔记TF034:实现Word2Vec
卷积神经网络发展趋势.Perceptron(感知机),1957年,Frank Resenblatt提出,始祖.Neocognitron(神经认知机),多层级神经网络,日本科学家Kunihiko fuk ...
- 谷歌开源的TensorFlow Object Detection API视频物体识别系统实现教程
视频中的物体识别 摘要 物体识别(Object Recognition)在计算机视觉领域里指的是在一张图像或一组视频序列中找到给定的物体.本文主要是利用谷歌开源TensorFlow Object De ...
- 第二十二节,TensorFlow中的图片分类模型库slim的使用、数据集处理
Google在TensorFlow1.0,之后推出了一个叫slim的库,TF-slim是TensorFlow的一个新的轻量级的高级API接口.这个模块是在16年新推出的,其主要目的是来做所谓的“代码瘦 ...
- Tensorflow 使用slim框架下的分类模型进行分类
Tensorflow的slim框架可以写出像keras一样简单的代码来实现网络结构(虽然现在keras也已经集成在tf.contrib中了),而且models/slim提供了类似之前说过的object ...
随机推荐
- 【LeetCode】【动态规划】表格移动问题
前言 这里总结了两道表格移动的问题,分别是:Unique Paths 和 题一:Unique Paths 描述 A robot is located at the top-left corner of ...
- $python正则表达式系列(5)——零宽断言
本文主要总结了python正则零宽断言(zero-length-assertion)的一些常用用法. 1. 什么是零宽断言 有时候在使用正则表达式做匹配的时候,我们希望匹配一个字符串,这个字符串的前面 ...
- java中类名.class, class.forName(), getClass()区别
Class对象的生成方式如下: 1.类名.class 说明: JVM将使用类装载器, 将类装入内存(前提是:类还没有装入内存),不做类的初始化工作.返回Class的对象 2.Cla ...
- Python编程-多线程
一.python并发编程之多线程 1.threading模块 multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍 1.1 开启线程的 ...
- Windows定时任务没有执行
最近部署网站首页静态化程序,需要定时执行的,由于部署在Windows上,为了方便直接用Windows计划任务做定时了.跑了一段时间发现.首页的静态html文件日期一直是老的,手动执行程序会更新,怀疑任 ...
- 适配iOS9问题汇总
iOS 9适配过程中出现的问题,收集的链接资料供大家学习分享. http://wiki.mob.com/ios9-对sharesdk的影响(适配ios-9必读)/ http://www.cocoach ...
- USB引脚及定义
USB 2.0 USB接口定义: USB引脚定义: 针脚 名称 说明 接线颜色 1 VCC +5V电压 红色 2 D- 数据线负极 白色 3 D+ 数据线正极 绿色 4 GND 接地 黑色 Min ...
- vector对象
vector是模板而非类型,由vector生成的类型必须包含vector中元素的类型,例如vector<int> 定义和初始化vector对象: vector<T> v1 ...
- math.floor实现四舍五入
lua math.floor 实现四舍五入: lua 中的math.floor函数是向下取整函数. math.floor(5.123) -- 5 math.floor(5.523) -- 5 用此特 ...
- python练习_sed替换
python练习_sed替换 需求: 做一个sed替换小程序,实现在windows下可以与实现linux中sed替换的功能 支持正则(re模块) 以下代码实现的功能与思路: 功能: (1)支持文件内容 ...