Memcache简介 & 内存分配机制




【Memcached分布式】
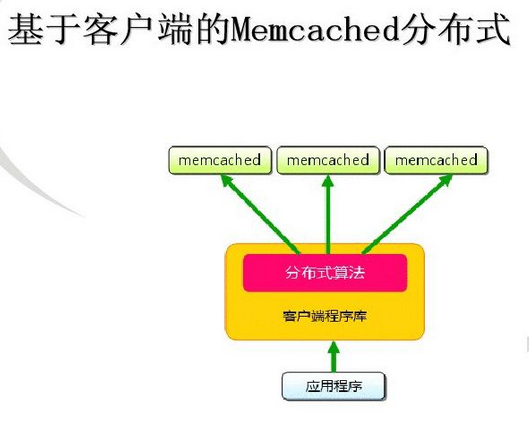
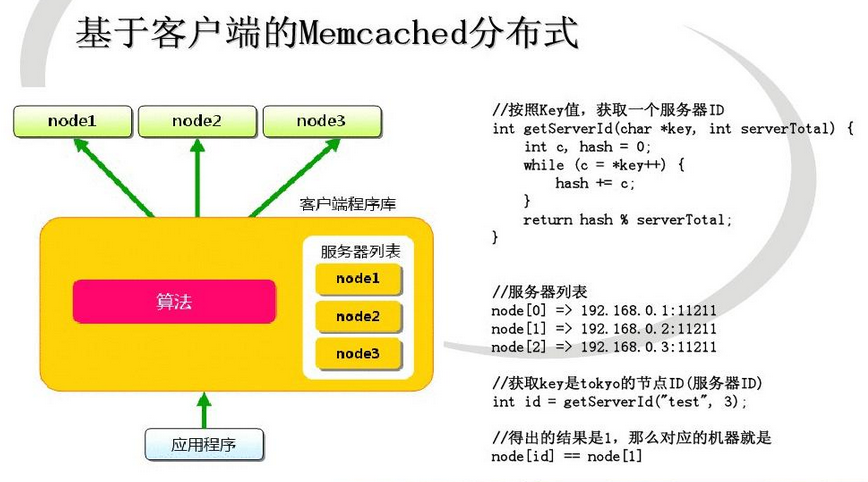
Memcached虽然称为“分布式“缓存服务器,但服务器端并没有“分布式”的功能。Memcached的分布式完全是有客户端实现的。现在我们就看一下memcached是怎么实现分布式缓存的。
例如下面假设memcached服务器有node1~node3三台,应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据。
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存“tokyo”及其值。
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
Memcached的缓存分布策略:http://blog.csdn.net/bintime/article/details/6259133
【缓存策略】
当ms的hash表满了之后,新的插入数据会替代老的数据,更新的策略是LRU(最近最少使用),以及每个kv对的有效时限。Kv对存储有效时限是在mc端由app设置并作为参数传给ms的。
同时ms采用是偷懒替代法,ms不会开额外的进程来实时监测过时的kv对并删除,而是当且仅当,新来一个插入的数据,而此时又没有多余的空间放了,才会进行清除动作。
【内存分配机制】

默认情况下,ms是用一个内置的叫“块分配器”的组件来分配内存的。舍弃C++标准的malloc/free的内存分配,为了避免内存碎片,否则操作系统要花费更多时间来查找这些逻辑上连续的内存块(实际上是断开的)。用了块分配器,ms会轮流的对内存进行大块的分配,并不断重用。当然由于块的大小各不相同,当数据大小和块大小不太相符的情况下,还是有可能导致内存的浪费。
同时,ms对key和data都有相应的限制,key的长度不能超过250字节,data也不能超过块大小的限制 --- 1MB。
因为 mc所使用的hash算法,并不会考虑到每个ms的内存大小。理论上mc会分配概率上等量的kv对给每个ms,这样如果每个ms的内存都不太一样,那可能会导致内存使用率的降低。所以一种替代的解决方案是,根据每个ms的内存大小,找出他们的最大公约数,然后在每个ms上开n个容量=最大公约数的 instance,这样就等于拥有了多个容量大小一样的子ms,从而提供整体的内存使用率。

Memcache简介 & 内存分配机制的更多相关文章
- Memcache之内存分配机制
可参见:http://blog.csdn.net/hguisu/article/details/7353482
- memcache的内存管理机制
Memcache使用了Slab Allocator的内存分配机制:按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题Memcache的存储涉及到slab,page,chunk三 ...
- memcached学习——memcached的内存分配机制Slab Allocation、内存使用机制LRU、常用监控记录(四)
内存分配机制Slab Allocation 本文参考博客:https://my.oschina.net/bieber/blog/505458 Memcached的内存分配是以slabs为单位的,会根据 ...
- Go语言内存分配机制
前言: 本文是学习<<go语言程序设计>> -- 清华大学出版社(王鹏 编著) 的2014年1月第一版 做的一些笔记 , 如有侵权, 请告知笔者, 将在24小时内删除, 转载请 ...
- map的内存分配机制分析
该程序演示了map在形成的时候对内存的操作和分配. 因为自己对平衡二叉树的创建细节理解不够,还不太明白程序所显示的日志.等我明白了,再来修改这个文档. /* 功能说明: map的内存分配机制分析. 代 ...
- list的内存分配机制分析
该程序演示了list在内存分配时候的问题.里面的备注信息是我的想法. /* 功能说明: list的内存分配机制分析. 代码说明: list所管理的内存地址可以是不连续的.程序在不断的push_back ...
- vector的内存分配机制分析
该程序初步演示了我对vector在分配内存的时候的理解.可能有误差,随着理解的改变,改代码可以被修改. /* 功能说明: vector的内存分配机制分析. 代码说明: vector所管理的内存地址是连 ...
- 阿里面试官:小伙子,你给我说一下JVM对象创建与内存分配机制吧
内存分配机制 逐步分析 类加载检查: 虚拟机遇到一条new指令(new关键字.对象的克隆.对象的序列化等)时,会先去检查这个指令的参数在常量池中定位到一个类的符号引用,并且这个符号引用代表的类是否 ...
- JVM的艺术-对象创建与内存分配机制深度剖析
JVM的艺术-对象创建与内存分配机制深度剖析 引言 本章将介绍jvm的对象创建与内存分配.彻底带你了解jvm的创建过程以及内存分配的原理和区域,以及包含的内容. 对象的创建 类加载的过程 固定的类加载 ...
随机推荐
- asp.net mvc4连接mysql
环境:vs2013+mysql5.6+mysql connector for .net 6.8.3+MySQL for Visual Studio 1.1.3 参考:http://dev.mysql. ...
- SQL Server 2008 收缩日志 清空删除大日志文件
SQL2008 的收缩日志 由于SQL2008对文件和日志管理进行了优化,所以以下语句在SQL2005中可以运行但在SQL2008中已经被取消: (SQL2005) BackupLog DNName ...
- Python函数参数默认值的陷阱和原理深究(转)
add by zhj: 在Python文档中清楚的说明了默认参数是怎么工作的,如下 "Default parameter values are evaluated when the func ...
- Python中的默认参数(转)
add by zhj: Python设计者为何将默认参数设计成这样呢?参见Python函数参数默认值的陷阱和原理深究 原文:https://github.com/acmerfight/insight_ ...
- python生成器&迭代器
列表生成式 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 里每个值都加一 普通做法 a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]for index,i in e ...
- hdu 2112 HDU Today(map与dijkstra的结合使用)
HDU Today Time Limit: 15000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- PAAS、IAAS和SAAS区别
IaaS: Infrastructure-as-a-Service(基础设施即服务) 有了IaaS,你可以将硬件外包到别的地方去.IaaS公司会提供场外服务器,存储和网络硬件,你可以租用.节省了维护成 ...
- SUBMIT RM07DOCS【MB51】 获取返回清单,抓取标准报表数据
*&---------------------------------------------------------------------* *& Report YT_SUBMIT ...
- Open SQL和Native SQL到底有什么本质的区别
1.個人愚見:它們只是在实现的方式上,执行效率上不同,有的书上还说native sql存在一定风险 *& 20170521 171300 1.Open sql 是由创建数据库数据的ABAP命令 ...
- ZFIR_001 ole下载
*&---------------------------------------------------------------------** Report ZFIR_001* Appli ...