Elasticsearch Suggester 学习
suggester搜索就像百度搜索框中的提示类似。
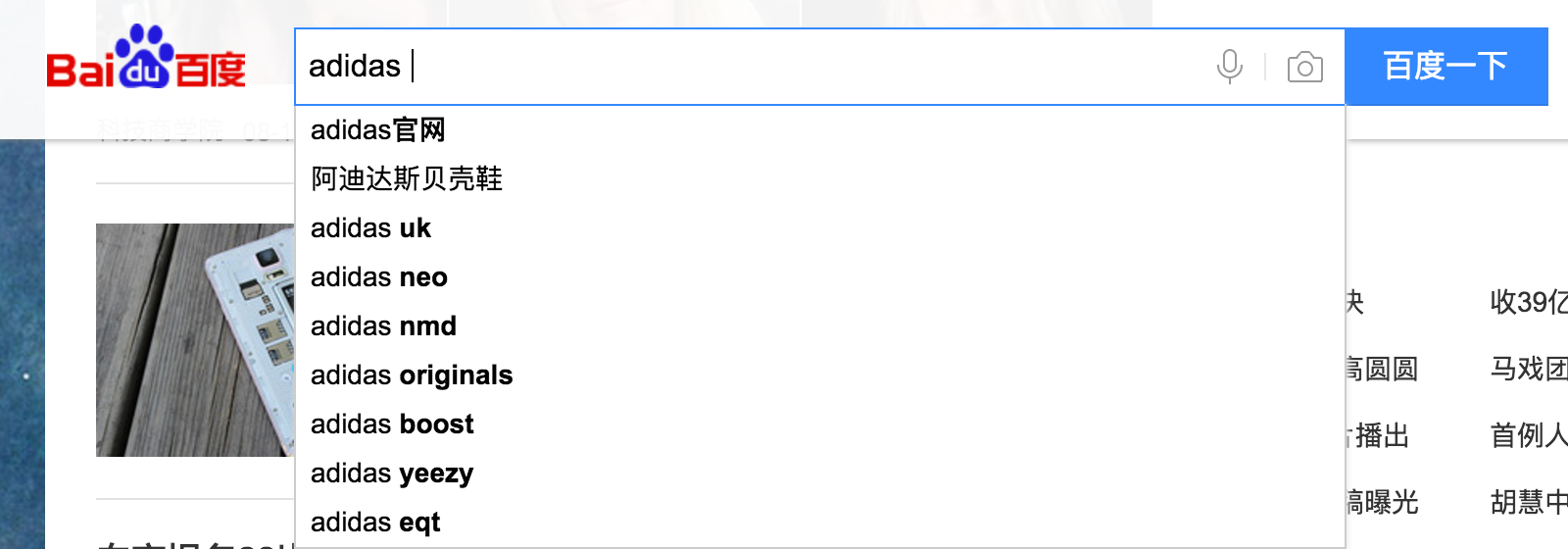
Elasticsearch 中提供类似的搜索功能。
答案就在Suggesters API。 Suggesters基本的运作原理是将输入的文本分解为token,然后在索引的字典里查找相似的term并返回。 根据使用场景的不同,Elasticsearch里设计了4种类别的Suggester,分别是:
- Term Suggester
- Phrase Suggester
- Completion Suggester
- Context Suggester
首先来看一个Term Suggester的示例:
准备一个叫做blogs的索引,配置一个text字段。
PUT /blogs/
{
"mappings": {
"tech": {
"properties": {
"body": {
"type": "text"
}
}
}
}
}
通过bulk api写入几条文档
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs", "_type" : "tech" } }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs", "_type" : "tech" } }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs", "_type" : "tech" } }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs", "_type" : "tech" } }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs", "_type" : "tech" } }
{ "body": "elk rocks"}
{ "index" : { "_index" : "blogs", "_type" : "tech" } }
{ "body": "elasticsearch is rock solid"}
此时blogs索引里已经有一些文档了,可以进行下一步的探索。为帮助理解,我们先看看哪些term会存在于词典里。
将输入的文本分析一下:
POST _analyze
{
"text": [
"Lucene is cool",
"Elasticsearch builds on top of lucene",
"Elasticsearch rocks",
"Elastic is the company behind ELK stack",
"elk rocks",
"elasticsearch is rock solid"
]
}
(由于结果太长,此处略去)
这些分出来的token都会成为词典里一个term,注意有些token会出现多次,因此在倒排索引里记录的词频会比较高,同时记录的还有这些token在原文档里的偏移量和相对位置信息。
执行一次suggester搜索看看效果:
POST /blogs/_search
{
"suggest": {
"my-suggestion": {
"text": "lucne rock",
"term": {
"suggest_mode": "missing",
"field": "body"
}
}
}
}
suggest就是一种特殊类型的搜索,DSL内部的"text"指的是api调用方提供的文本,也就是通常用户界面上用户输入的内容。这里的lucne是错误的拼写,模拟用户输入错误。 "term"表示这是一个term suggester。 "field"指定suggester针对的字段,另外有一个可选的"suggest_mode"。 范例里的"missing"实际上就是缺省值,它是什么意思?有点挠头... 还是先看看返回结果吧:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits":
},
"suggest": {
"my-suggestion": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options":
}
]
}
}
在返回结果里"suggest" -> "my-suggestion"部分包含了一个数组,每个数组项对应从输入文本分解出来的token(存放在"text"这个key里)以及为该token提供的建议词项(存放在options数组里)。 示例里返回了"lucne","rock"这2个词的建议项(options),其中"rock"的options是空的,表示没有可以建议的选项,为什么? 上面提到了,我们为查询提供的suggest mode是"missing",由于"rock"在索引的词典里已经存在了,够精准,就不建议啦。 只有词典里找不到词,才会为其提供相似的选项。
如果将"suggest_mode"换成"popular"会是什么效果?
尝试一下,重新执行查询,返回结果里"rock"这个词的option不再是空的,而是建议为rocks。
"suggest": {
"my-suggestion": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options": [
{
"text": "rocks",
"score": 0.75,
"freq": 2
}
]
}
]
}
回想一下,rock和rocks在索引词典里都是有的。 不难看出即使用户输入的token在索引的词典里已经有了,但是因为存在一个词频更高的相似项,这个相似项可能是更合适的,就被挑选到options里了。 最后还有一个"always" mode,其含义是不管token是否存在于索引词典里都要给出相似项。
有人可能会问,两个term的相似性是如何判断的? ES使用了一种叫做Levenstein edit distance的算法,其核心思想就是一个词改动多少个字符就可以和另外一个词一致。 Term suggester还有其他很多可选参数来控制这个相似性的模糊程度,这里就不一一赘述了。
Term suggester正如其名,只基于analyze过的单个term去提供建议,并不会考虑多个term之间的关系。API调用方只需为每个token挑选options里的词,组合在一起返回给用户前端即可。 那么有无更直接办法,API直接给出和用户输入文本相似的内容? 答案是有,这就要求助Phrase Suggester了。
Phrase suggester在Term suggester的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等等。看个范例就比较容易明白了:
POST /blogs/_search
{
"suggest": {
"my-suggestion": {
"text": "lucne and elasticsear rock",
"phrase": {
"field": "body",
"highlight": {
"pre_tag": "<em>",
"post_tag": "</em>"
}
}
}
}
}
返回结果:
"suggest": {
"my-suggestion": [
{
"text": "lucne and elasticsear rock",
"offset": 0,
"length": 26,
"options": [
{
"text": "lucene and elasticsearch rock",
"highlighted": "<em>lucene</em> and <em>elasticsearch</em> rock",
"score": 0.004993905
},
{
"text": "lucne and elasticsearch rock",
"highlighted": "lucne and <em>elasticsearch</em> rock",
"score": 0.0033391973
},
{
"text": "lucene and elasticsear rock",
"highlighted": "<em>lucene</em> and elasticsear rock",
"score": 0.0029183894
}
]
}
]
}
options直接返回一个phrase列表,由于加了highlight选项,被替换的term会被高亮。因为lucene和elasticsearch曾经在同一条原文里出现过,同时替换2个term的可信度更高,所以打分较高,排在第一位返回。Phrase suggester有相当多的参数用于控制匹配的模糊程度,需要根据实际应用情况去挑选和调试。
最后来谈一下Completion Suggester,它主要针对的应用场景就是"Auto Completion"。 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
为了使用Completion Suggester,字段的类型需要专门定义如下:
PUT /blogs_completion/
{
"mappings": {
"tech": {
"properties": {
"body": {
"type": "completion"
}
}
}
}
}
用bulk API索引点数据:
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "the elk stack rocks"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "elasticsearch is rock solid"}
查找:
POST blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
}
结果:
"suggest": {
"blog-suggest": [
{
"text": "elastic i",
"offset": 0,
"length": 9,
"options": [
{
"text": "Elastic is the company behind ELK stack",
"_index": "blogs_completion",
"_type": "tech",
"_id": "AVrXFyn-cpYmMpGqDdcd",
"_score": 1,
"_source": {
"body": "Elastic is the company behind ELK stack"
}
}
]
}
]
}
值得注意的一点是Completion Suggester在索引原始数据的时候也要经过analyze阶段,取决于选用的analyzer不同,某些词可能会被转换,某些词可能被去除,这些会影响FST编码结果,也会影响查找匹配的效果。
比如我们删除上面的索引,重新设置索引的mapping,将analyzer更改为"english":
PUT /blogs_completion/
{
"mappings": {
"tech": {
"properties": {
"body": {
"type": "completion",
"analyzer": "english"
}
}
}
}
}
bulk api索引同样的数据后,执行下面的查询:
POST blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
}
居然没有匹配结果了,多么费解! 原来我们用的english analyzer会剥离掉stop word,而is就是其中一个,被剥离掉了!
用analyze api测试一下:
POST _analyze?analyzer=english
{
"text": "elasticsearch is rock solid"
} 会发现只有3个token:
{
"tokens": [
{
"token": "elasticsearch",
"start_offset": 0,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "rock",
"start_offset": 17,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "solid",
"start_offset": 22,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 3
}
]
}
FST只编码了这3个token,并且默认的还会记录他们在文档中的位置和分隔符。 用户输入"elastic i"进行查找的时候,输入被分解成"elastic"和"i",FST没有编码这个“i” , 匹配失败。
好吧,如果你现在还足够清醒的话,试一下搜索"elastic is",会发现又有结果,why? 因为这次输入的text经过english analyzer的时候is也被剥离了,只需在FST里查询"elastic"这个前缀,自然就可以匹配到了。
其他能影响completion suggester结果的,还有诸如"preserve_separators","preserve_position_increments"等等mapping参数来控制匹配的模糊程度。以及搜索时可以选用Fuzzy Queries,使得上面例子里的"elastic i"在使用english analyzer的情况下依然可以匹配到结果。
因此用好Completion Sugester并不是一件容易的事,实际应用开发过程中,需要根据数据特性和业务需要,灵活搭配analyzer和mapping参数,反复调试才可能获得理想的补全效果。
回到篇首Google搜索框的补全/纠错功能,如果用ES怎么实现呢?我能想到的一个的实现方式:
- 在用户刚开始输入的过程中,使用Completion Suggester进行关键词前缀匹配,刚开始匹配项会比较多,随着用户输入字符增多,匹配项越来越少。如果用户输入比较精准,可能Completion Suggester的结果已经够好,用户已经可以看到理想的备选项了。
- 如果Completion Suggester已经到了零匹配,那么可以猜测是否用户有输入错误,这时候可以尝试一下Phrase Suggester。
- 如果Phrase Suggester没有找到任何option,开始尝试term Suggester。
精准程度上(Precision)看: Completion > Phrase > term, 而召回率上(Recall)则反之。从性能上看,Completion Suggester是最快的,如果能满足业务需求,只用Completion Suggester做前缀匹配是最理想的。 Phrase和Term由于是做倒排索引的搜索,相比较而言性能应该要低不少,应尽量控制suggester用到的索引的数据量,最理想的状况是经过一定时间预热后,索引可以全量map到内存。
Elasticsearch Suggester 学习的更多相关文章
- ElasticSearch 5学习(10)——结构化查询(包括新特性)
之前我们所有的查询都属于命令行查询,但是不利于复杂的查询,而且一般在项目开发中不使用命令行查询方式,只有在调试测试时使用简单命令行查询,但是,如果想要善用搜索,我们必须使用请求体查询(request ...
- ElasticSearch 5学习(9)——映射和分析(string类型废弃)
在ElasticSearch中,存入文档的内容类似于传统数据每个字段一样,都会有一个指定的属性,为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成字符串值,Elasticsearc ...
- ElasticSearch 5学习(7)——分布式集群学习分享2
前面主要学习了ElasticSearch分布式集群的存储过程中集群.节点和分片的知识(ElasticSearch 5学习(6)--分布式集群学习分享1),下面主要分享应对故障的一些实践. 应对故障 前 ...
- ElasticSearch 5学习(6)——分布式集群学习分享1
在使用中我们把文档存入ElasticSearch,但是如果能够了解ElasticSearch内部是如何存储的,将会对我们学习ElasticSearch有很清晰的认识.本文中的所使用的ElasticSe ...
- ElasticSearch 5学习(5)——第一个例子(很实用)
想要知道ElasticSearch是如何使用的,最快的方式就是通过一个简单的例子,第一个例子将会包括基本概念如索引.搜索.和聚合等,需求是关于公司管理员工的一些业务. 员工文档索引 业务首先需要存储员 ...
- ElasticSearch 5学习(2)——Kibana+X-Pack介绍使用(全)
Kibana是一个为 ElasticSearch 提供的数据分析的 Web 接口.可使用它对日志进行高效的搜索.可视化.分析等各种操作.Kibana目前最新的版本5.0.2,回顾一下Kibana 3和 ...
- ElasticSearch 5学习(5)——第一个例子
想要知道ElasticSearch是如何使用的,最快的方式就是通过一个简单的例子,第一个例子将会包括基本概念如索引.搜索.和聚合等,需求是关于公司管理员工的一些业务. 员工文档索引 业务首先需要存储员 ...
- Elasticsearch入门学习重点笔记
原文:Elasticsearch入门学习重点笔记 必记知识点 Elasticsearch可以接近实时的搜索和存储大量数据.Elasticsearch是一个近实时的搜索平台.这意味着当你导入一个文档并把 ...
- ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)
学完ES分布式集群的工作原理以及一些基本的将数据放入索引然后检索它们的所有方法,我们可以继续学习在分布式系统中,每个分片的文档是被如何索引和查询的. 路由 首先,我们需要明白,文档和分片之间是如何匹配 ...
随机推荐
- (分享)Linux服务器如何防止中木马
大家的windows机器可能经常装一些杀毒软件或者什么的来防止中毒,然而在Linux上我们应该怎么防止这些呢? 在面试过程中我们也经常遇到该类问题,那么我们应该怎么回答才显得既有逻辑又有深度呢? 首先 ...
- boost::lockfree::spsc_queue
#include <boost/thread/thread.hpp> #include <boost/lockfree/spsc_queue.hpp> #include < ...
- std::condition_variable(复习)
#include <iostream> // std::cout #include <thread> // std::thread #include <mutex> ...
- SharePoint解决方案及开发系列(2)-ECM
很多次跟客户做咨询及沟通的时候,客户都问SharePoint能做什么?是不是就是做文档管理?为什么要花那么多的钱没SharePoint?高大上? 我上家公司面试的时候,我的那个BOSS面试官有一个问题 ...
- es站内站内搜索笔记(一)
es站内站内搜索笔记(一) 第一节: 概述 使用elasticsearch进行网站搜索,es是当下最流行的分布式的搜索引擎及大数据分析的中间件,搜房网的主要功能:强大的搜索框,与百度地图相结合,实现地 ...
- mysql编译参数详解(./configure)
1.--prefix=PREFIX:指定程序安装路径: 2.--enable-assembler:使用汇编模式:(文档说明:compiling in x86 (and sparc) versions ...
- Linux下Solr的安装和配置
一.安装 1.需要的安装包:apache-tomcat-7.0.47.tar.gz.solr-4.10.3.tgz.tgz(jdk自行安装) 2.解压tomcat并创建solr文件夹 [root@lo ...
- Centos之常见目录作用介绍(九)
我们先切换到系统根目录 / 看看根目录下有哪些目录 [root@localhost ~]# cd / [root@localhost /]# ls bin dev home lib64 mn ...
- HDU 3182 Hamburger Magi(状压dp)
题目链接:pid=3182">http://acm.hdu.edu.cn/showproblem.php?pid=3182 Problem Description In the mys ...
- struts2+Oracle实现管理员查看用户提交的意见功能
说一下需求:这个功能类似于邮件功能,当用户在站点中提交一些建议及意见后.后台将其存入到Oracle数据库中.然后管理员登录站点,会看到还没有读过以及读过的意见及建议,并能够将未读过的意见及建议标记为已 ...