基于Python语言使用RabbitMQ消息队列(四)
路由
在上一节我们构建了一个简单的日志系统。我们能够广播消息给很多接收者。
在本节我们将给它添加一些特性——我们让它只订阅所有消息的子集。例如,我们只把严重错误(critical error)导入到日志文件(存入磁盘空间),但仍然可以打印所有日志消息到控制台。
绑定
前面的例子中我们已经创建了绑定,像下面这样:
channel.queue_bind(exchange=exchange_name,
queue=queue_name)- 1
- 2
绑定是一个交易所和一个队列之间的关系。这可以解释为:一个队列对源于这个交易所的消息感兴趣。
绑定可以采用一个额外的routing_key 参数。为避免同basic_publish参数混淆,我们称呼它为绑定键(binding key)。我们用一个键来创建一个绑定This is how we could create a binding with a key:
channel.queue_bind(exchange=exchange_name,
queue=queue_name,
routing_key='black')- 1
- 2
- 3
一个绑定键的意义取决于交易所类型。我们先前使用过的fanout类型交易所就会忽略它的值。
直接型交易所(Direct exchange)
我们先前的日志系统会广播所有消息给所有消费者。我们现在想扩展它让过滤掉一些消息,基于这些消息的严重级别。例如我们可能想要向磁盘写日志的脚本只接收严重错误critical error,不要浪费磁盘空间在warning或info日志上面。
我们正使用的fanout类型交易所不会给我们太大的灵活性——它只能够无意识地进行广播。
我们会使用直接型交易所进行替代,直接型交易所背后的路由算法很简单——一条消息会前往绑定键(binding key)恰巧匹配这条消息的路由键(routing key)的队列。
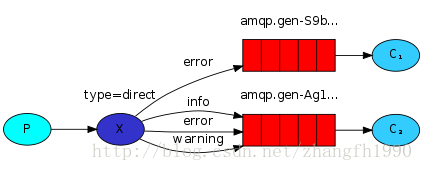
为了阐释这个问题,考虑下图的设定: 
在这个设定当中我们看到直接型交易所X有两个队列与之绑定。第一个队列的绑定键为“orange”,第二个有两个绑定键,一个是“black”,另一个是“green”。
在这个设定中,发布到交易所中的带有路由键“orange”的会被路由到队列Q1。带有路由键“black”和“green”的会前往Q2。所有其他的消息会被忽略。
多重绑定

使用相同的绑定键绑定多个队列完全没有问题。在我们的例子中我们可以用绑定键“black”在交易所X和队列Q1之间添加绑定。这样的话,direct型交易所就会表现的像fanout交易所,广播消息给所有匹配的队列。具有“black”路由键的消息会被传送给Q1和Q2。
生成日志
我们会为日志系统使用这个模型。发送消息到direct交易所,而非fanout交易所。我们会提供日志级别(log severity)作为路由键。这样接收脚本就能够选择它想要的级别来接收。我们首先关注生成日志。
像通常我们需要创建一个交易所时那样:
channel.exchange_declare(exchange='direct_logs',
type='direct')- 1
- 2
准备好发送消息:
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)- 1
- 2
- 3
为了使事情简单我们假设’severity’ 是 ‘info’, ‘warning’, ‘error’中的一种。
订阅
接收消息就跟之前的教程中一样,不同的是——我们要为每种severity创建一个新的绑定。
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)- 1
- 2
- 3
- 4
- 5
- 6
- 7
整合
emit_log_direct.py完整代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 2 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
receive_logs_direct.py完整代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
我在自己的Ubuntu终端开启了三个控制台,两个用来接收日志消息,其中一个设置为只接收error日志,并把收到的日志存入日志文件。另一个接收info,warning和error,直接打印到屏幕。如下图:
写入文件: 
打印到屏幕:

生成日志: 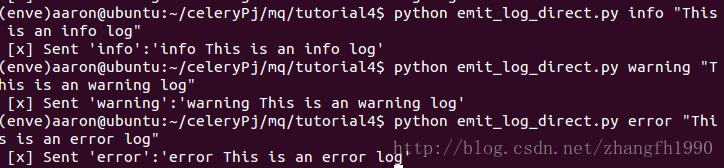
查看日志文件确实只收到了error日志:

基于Python语言使用RabbitMQ消息队列(四)的更多相关文章
- 基于Python语言使用RabbitMQ消息队列(六)
远程过程调用(RPC) 在第二节里我们学会了如何使用工作队列在多个工人中分布时间消耗性任务. 但如果我们想要运行存在于远程计算机上的方法并等待返回结果该如何去做呢?这就不太一样了,这种模式就是常说的远 ...
- 基于Python语言使用RabbitMQ消息队列(五)
Topics 在前面教程中我们改进了日志系统,相比较于使用fanout类型交易所只能傻瓜一样地广播,我们用direct获得了选择性接收日志的能力. 虽然使用direct类型交易所改进了我们的系统,但它 ...
- 基于Python语言使用RabbitMQ消息队列(一)
介绍 RabbitMQ 是一个消息中间人(broker): 它接收并且发送消息. 你可以把它想象成一个邮局: 当你把想要寄出的信放到邮筒里时, 你可以确定邮递员会把信件送到收信人那里. 在这个比喻中, ...
- 基于Python语言使用RabbitMQ消息队列(三)
发布/订阅 前面的教程中我们已经创建了一个工作队列.在一个工作队列背后的假设是每个任务恰好会传递给一个工人.在这一部分里我们会做一些完全不同的东西——我们会发送消息给多个消费者.这就是所谓的“发布/订 ...
- 基于Python语言使用RabbitMQ消息队列(二)
工作队列 在第一节我们写了程序来向命名队列发送和接收消息 .在本节我们会创建一个工作队列(Work Queue)用来在多个工人(worker)中分发时间消耗型任务(time-consuming tas ...
- python学习之-- RabbitMQ 消息队列
记录:异步网络框架:twisted学习参考:www.cnblogs.com/alex3714/articles/5248247.html RabbitMQ 模块 <消息队列> 先说明:py ...
- Python并发编程-RabbitMQ消息队列
RabbitMQ队列 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列 ...
- Python RabbitMQ消息队列
python内的队列queue 线程 queue:不同线程交互,不能夸进程 进程 queue:只能用于父进程与子进程,或者同一父进程下的多个子进程,进行交互 注:不同的两个独立进程是不能交互的. ...
- 基于ASP.NET Core 5.0使用RabbitMQ消息队列实现事件总线(EventBus)
文章阅读请前先参考看一下 https://www.cnblogs.com/hudean/p/13858285.html 安装RabbitMQ消息队列软件与了解C#中如何使用RabbitMQ 和 htt ...
随机推荐
- loadrunder之脚本篇——脚本基础知识和常用操作
1)编码工具设置 自动补全输入Tools->General Options->Environment->Auto complete word 显示功能语法Tools->Genr ...
- LeetCode 14. Longest Common Prefix字典树 trie树 学习之 公共前缀字符串
所有字符串的公共前缀最长字符串 特点:(1)公共所有字符串前缀 (好像跟没说一样...) (2)在字典树中特点:任意从根节点触发遇见第一个分支为止的字符集合即为目标串 参考问题:https://lee ...
- $《第一行代码:Android》读书笔记——第2章 Activity
(一)创建活动 1.创建活动类 创建没有Activity的项目,发现src文件夹是空的,手动创建一个包com.jyj.demo1,在包中添加一个名为MainActivity的class,该MainAc ...
- 建议13:使用Python模块re实现解析小工具
# -*- coding:utf-8 -*- # ''' Python re 的主要功能: re.compile(pattern[, flags]) 把正则表达式的模式和标识转化成正则表达式对象,供 ...
- 笔记:git和码云
背景:之前使用GitHub,无奈网速原因,有时候竟无法连接,搜索解决方案而又鱼龙混杂淹没在信息的海洋. 于是尝试码云,界面简单,全中文,用起来很是顺手. 码云使用git来管理,操作上都是git的基本指 ...
- Objective-C与Swift的混合编程
Swift 被设计用来无缝兼容 Cocoa 和 Objective-C .在 Swift 中,你可以使用 Objective-C 的 API(包括系统框架和你自定义的代码),你也可以在 Objecti ...
- Linux下解压分包文件zip(zip/z01/z02)
分包压缩的zip文件不能被7z解压,且这种格式是Windows才能创建出来,在Linux下不会以这种方式去压包.下面是在Linux下处理这种文件的做法: 方法一: cat xx.z01 xx.zip ...
- Ubuntu 使用国内apt源
编辑/etc/apt/source-list deb http://cn.archive.ubuntu.com/ubuntu/ trusty main restricted universe mult ...
- 第四节课-反向传播&&神经网络1
2017-08-14 这节课的主要内容是反向传播的介绍,非常的详细,还有神经网络的部分介绍,比较简短. 首先是对求导,梯度的求解.反向传播的核心就是将函数进行分解,分段求导,前向计算损失,反向计算各个 ...
- vs+mysql+ef配置方法
这次的项目用的是MySQL数据库,但是ADO.NET实体数据模型默认是不支持MySQL数据库的,本文档将介绍如何让VS ADO.NET实体数据模型支持MySQL. 一.安装插件 1.VS插件 mysq ...