C++深度解析教程学习笔记(6)对象的构造和销毁
1. 对象的初始化
(1)从程序设计的角度看,对象只是变量,因此:
①在栈上创建对象时,成员变量初始化为随机值
②在堆上创建对象时,成员变量初始化为随机值
③在静态存储区创建对象时,成员变量初始化为 0 值
成员变量的初始化
#include <stdio.h> class Test
{
private:
int i;
int j; public:
int getI(){return i;}
int getJ(){return j;}
}; Test gt; //全局对象 int main()
{
//全局区,初始化为0
printf("gt.i = %d\n", gt.getI());
printf("gt.j = %d\n", gt.getJ()); //栈上的对象,初始化为随机值
Test st;
printf("st.i = %d\n", st.getI());
printf("st.j = %d\n", st.getJ()); //堆上创建对象,初始化为随机值
Test* pt = new Test;
printf("pt->i = %d\n", pt->getI());
printf("pt->j = %d\n", pt->getJ()); delete pt; return ;
}
(2)生活中的对象都是初始化了的
(3)初始状态是对象普遍存在一个状态
2. 构造函数
(1)C++中可以定义与类名相同的特殊成员函数,这个函数叫构造函数
①构造函数是没有任何返回类型(连 void 都没有,因为这个函数是编译器在创建对象时插入二进制代码用的,即由编译器来调用的)
②构造函数在对象定义时自动被调用
#include <stdio.h> class Test
{
private:
int i;
int j; public:
int getI(){return i;}
int getJ(){return j;}
//构造函数
Test()
{
printf("Test() Begin\n");
i = ;//成员变量初始化
j = ;//成员变量初始化
printf("Test() End\n");
}
}; Test gt; //全局对象 int main()
{
//全局区的对象
printf("gt.i = %d\n", gt.getI());//
printf("gt.j = %d\n", gt.getJ());//0 //栈上的对象
Test st;
printf("st.i = %d\n", st.getI());//
printf("st.j = %d\n", st.getJ());//0 //堆上的对象
Test* pt = new Test;
printf("pt->i = %d\n", pt->getI());//
printf("pt->j = %d\n", pt->getJ());//0 delete pt; return ;
}
3.带参数的构造函数
(1)构造函数可以根据需要定义参数
(2)一个类中可以存在多个重载的构造函数
(3)构造函数的重载遵循 C++重载规则
对象的定义和声明不同
①对象定义:申请对象的空间并调用构造函数(如 Test t;//定义并调用构造函数)
②对象声明:告诉编译器己经存在一个对象,并不调用构造函数(如 extern Test t;)
4.构造函数的调用
(1)一般情况下,编译器会根据给定的参数情况自动调用相应的构造函数
带参数的构造函数
#include <stdio.h> class Test
{
public:
//不带参的构造函数
Test()
{
printf("Test()\n");
}
Test(int v)
{
printf("Test(int v), v = %d\n", v);
}
}; int main()
{
Test t; //调用Test();
Test t1(); //调用Test(int v);
Test t2 = ; //调用Test(int v); int i();
printf("i = %d\n", i); return ;
}
(2)一些特殊情况下,需要手工调用构造函数
构造函数的手动调用
#include <stdio.h> class Test
{
private:
int m_value; public:
//不带参的构造函数
Test()
{
m_value = ; printf("Test()\n");
}
Test(int v)
{
m_value = v;
printf("Test(int v), v = %d\n", v);
} int getValue(){return m_value;}
}; int main()
{
//Test ta[3] = {1, 2, 3};//编译器自动调用带参构造函数 //定义数组对象,并手动调用带参构造函数来初始化各个对象
Test ta[] ={Test(), Test(), Test()};
for(int i = ;i< ;i++)
{
printf("ta[%d].getValue() = %d\n", i, ta[i].getValue());
} Test t = Test(); //定义并手动调用构造函数来初始化对象 return ;
}
5.特殊的构造函数
|
无参构造函数 |
拷贝构造函数 |
|
|
参数形式 |
没有参数的构造函数 |
参数为const class_name&的构造函数 |
|
默认情况 |
当类中没有定义构造函数时,编译器默认提供一个无参构造函数,并且其函数体为空 |
当类中没有定义拷贝构造函数时,编译器默认提供一个拷贝构造函数,简单的进行成员变量的值复制 |
|
注意: |
当类中定义了构造函数(含带参、不带参、或拷贝构造函数),则系统就不再提供默认的无参构造函数。而拷贝构造函数只有在我们定义时,系统才不提供。 |
|
特殊的构造函数
#include <stdio.h> class Test
{
private:
int i;
int j; public:
int getI(){return i;} int getJ(){return j;} /*
//拷贝构造函数
Test(const Test& t)
{
i = t.i;
j = t.j;
}
*/
//无参构造函数
Test()
{
}
}; int main()
{
//调用无参构造函数,注意如果我们定义了构造函数(含无参、带参或拷贝
//构造函数时)系统就不再提供默认的,需自己定义无参构造函数。
Test t1; //调用Test() Test t2 = t1;//调用拷贝构造函数,如果我们不定义,系统会提供默认的 printf("t1.i = %d, t1.j = %d\n",t1.getI(),t1.getJ());
printf("t2.i = %d, t2.j = %d\n",t2.getI(),t2.getJ()); return ;
}
6.拷贝构造函数
(1)拷贝构造函数的意义
①兼容 C 语言的初始化方式,即利用己经存在的对象去创建新的对象。(因为 C++中初始化会涉及到拷贝构造函数的调用。注意初始化与赋值是不同的,赋值时“=”运算符会被调用)
如:int a = b; //C 中,用一个变量来初始化另一个变量;
Student s2 = s1;//利用己经存在的 s1 对象来初始化,很像 C 的初始化方式
②初始化行为能够符合预期的逻辑
(2)浅拷贝和深拷贝
①拷贝后对象的物理状态相同→编译器提供的拷贝构造函数只进行浅拷贝
②拷贝后对象的逻辑状态相同
对象的初始化
#include <stdio.h> class Test
{
private:
int i;
int j;
int* p; public:
int getI(){return i;} int getJ(){return j;} int* getP(){return p;} /*
//拷贝构造函数
Test(const Test& t)
{
i = t.i;
j = t.j;
p = new int; *p = *t.p;
}
*/ //带参构造函数
Test(int v)
{
i = ;
j = ;
p = new int; *p = v;
} ~Test(){delete p;} }; int main()
{
Test t1(); //调用Test(int v);
Test t2(t1); //调用Test(const Test& t)
//t1.p和t2.p指向了同一个堆内存地址,析构的时候会释放两次p
printf("t1.i = %d, t1.j = %d, *t1.p = %d\n", t1.getI(), t1.getJ(), *t1.getP());
printf("t2.i = %d, t2.j = %d, *t2.p = %d\n", t2.getI(), t2.getJ(), *t2.getP()); return ;
}
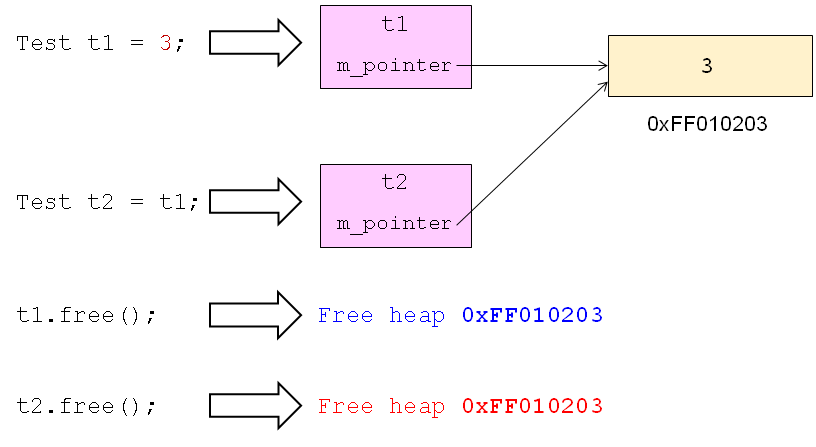
(3)什么时候需要进行深拷贝
①对象中有成员指代了系统中的资源
②如成员指向了动态内存空间、打开了外存中的文件或使用了系统中的网络端口等
③自定义拷贝构造函数时,必然需要实现深拷贝
自定义数组类
//IntArray.h
#ifndef _INTARRAY_H_
#define _INTARRAY_H_ class IntArray
{
private:
int m_length;
int* m_pointer; public:
IntArray(int len);
IntArray(const IntArray& obj);
~IntArray(); int length();
bool get(int index, int& value);
bool set(int index, int value);
}; #endif
//IntArray.cpp
#include "IntArray.h" IntArray::IntArray(int len)
{
m_pointer = new int[len]; for(int i = ; i<len; i++)
{
m_pointer[i] = ;
} m_length = len;
} IntArray::IntArray(const IntArray& obj)
{
m_length = obj.m_length; m_pointer = new int[obj.m_length]; for (int i = ;i < obj.m_length; i++)
{
m_pointer[i] = obj.m_pointer[i];
}
} IntArray::~IntArray()
{
if(m_pointer)
{
delete[] m_pointer;
}
} int IntArray::length()
{
return m_length;
} bool IntArray::get(int index, int& value)
{
bool bRet = ( <= index) && (index <m_length); if(bRet)
{
value = m_pointer[index];
} return bRet;
} bool IntArray::set(int index, int value)
{ bool bRet = ( <= index) && (index <m_length); if(bRet)
{
m_pointer[index] = value;
} return bRet;
}
//main.cpp
#include <stdio.h>
#include "IntArray.h" int main()
{
IntArray a();//调用带参构造函数
for(int i=; i<a.length(); i++)
{
a.set(i, i + );
} for(int i=; i<a.length(); i++)
{
int value = ; if(a.get(i, value))
{
printf("a[%d] = %d\n", i, value);
}
} IntArray b = a; //调用拷贝构造函数
for(int i=; i<b.length();i++)
{
int value = ; if(b.get(i, value))
{
printf("b[%d] = %d\n", i, value);
}
}
return ;
}
7.初始化列表
7.1.类成员的初始化
(1)C++中提供了初始化列表,可以对成员变量进行初始化
(2)语法规则:
ClassName::ClassName():m1(v1), m2(v2,v3),m3(v3)
{
//其它初始化操作
}
(3)注意事项
①成员的初始化顺序与成员的声明顺序相同。而与初始化列表中的位置无关
②初始化列表先于构造函数的函数体执行
#include <stdio.h> class Value
{
private:
int mi; public:
Value(int i)
{
printf("i = %d\n", i);
mi = i;
} int getI(){return mi;}
}; class Test
{
private:
Value m2;
Value m3;
Value m1; public: //初始化顺序只与声明顺序有关,与初始化列表次序无关
//即初始化顺序为:m2,m3,m1。最后才是调用构造函数
Test():m1(), m2(), m3() //成员变量的初始化
{
printf("Test::Test()\n");
} }; int main()
{
Test t; return ;
}
7.2.类中的const成员
(1)类中的 const 成员会被分配空间。但本质上是个只读变量,因为编译器无法直接得到const 成员的初始值,因此无法进入符号表成为真正意义上的常量。
类中的 const 成员(值为多少,存储在哪里?)
#include <stdio.h> class Test
{
private:
//const成员,会分配空间。其存储空间与对象存储位置一样
//可在栈上、堆或全局区等
//但编译期间无法确定初始化,所以不会进入符号表
const int ci; public:
Test()
{
//ci = 10; //不能这样初始化,ci是只读变量,不能作为左值
} int getCI(){return ci;}
} int main()
{
Test t; //会提示ci变量未被初始化 printf("t.ci = %d\n", t.getCI()); return ;
}
(2)类中的 const 成员只能在初始化列表中指定初始值。而不能在其他地方(如构造函数的内部,因为形如 c = 1 的赋值语句,意味着要给 const 变量赋值这是不允许的)
只读成员变量
#include <stdio.h> class Value
{
private:
int mi; public:
Value(int i)
{
printf("i = %d\n", i);
mi = i;
} int getI(){return mi;}
}; class Test
{
private:
const int ci;
Value m2;
Value m3;
Value m1; public: Test():m1(), m2(), m3(), ci() //成员变量的初始化
{
printf("Test::Test()\n");
} int getCI(){return ci;} int setCI(int v)
{
//说明ci是个只读变量,可以通过指针修改内存值
int* p = const_cast<int*>(&ci);
*p = v;
} }; int main()
{
Test t; printf("t.ci = %d\n", t.getCI()); // t.setCI(); printf("t.ci = %d\n", t.getCI()); //10 return ;
}
(3)初始化与赋值不同
①初始化:对正在创建的对象进行初值设置(如 int a = 1;或初始化列表的形式)
②赋值:对己经存在的对象进行值设置(如 a = 1;)
类中可以使用初始化列表对成员进行初始化,初始化列表先于构造函数体执行,const 成员变量必须在初始化列表中指定初值,const 成员变量为只读变量。
8. 对象的构造顺序
(1)对于局部对象:当程序执行流到达对象的定义语句时进行构造
#include <stdio.h> class Test
{
private:
int mi; public:
Test(int i)
{
mi = i;
printf("Test(int i): %d\n", mi);
} Test(const Test& obj)
{
mi = obj.mi;
printf("Test(const Test& obj): %d\n", mi);
} ~Test()
{
printf("~Test(): %d\n", mi);
}
}; int main()
{
int i = ;
Test a1 = i;//Test(int i):0,执行到这里时构造a1 while(i < )
{
//注意:a2的作用域只在这个大括号内
//所以,每执行1次,构造一次a2
Test a2 = ++i;//Test(int i):1、2、3
} goto LabelEnd; //因跳转,所以下列的a不会被构造 if (i < )
{
Test a = a1;//Test(const Test&):0。但因goto,该对象不会被构造
}
else
{
Test a();//不会被执行,所以不会调用Test(int i)
} LabelEnd: return ;
}
(2)对于堆对象
①当程序执行流到达 new 语句时创建对象
②使用 new 创建对象将自动触发构造函数的调用
#include <stdio.h> class Test
{
private:
int mi; public:
Test(int i)
{
mi = i;
printf("Test(int i): %d\n", mi);
} Test(const Test& obj)
{
mi = obj.mi;
printf("Test(const Test& obj): %d\n", mi);
} ~Test()
{
//printf("~Test(): %d\n", mi);
}
}; int main()
{
int i = ;
Test* a1 = new Test(i); //Test(int i):0 while(++i < )
if (i % ) //i % 2 !=0
new Test(i);//Test(int i):1、3、5、7、9 if (i < )
{
new Test(*a1);//Test(const& Test):0
}
else
{
new Test();//Test(int i):100
} return ;
}
(3)对于全局对象
①对象的构造顺序是不确定的
②不同的编译器使用不同的规则确定构造顺序
//test.h
#ifndef _TEST_H_
#define _TEST_H_ #include<stdio.h> class Test
{
public:
Test(const char* s)
{
printf("%s\n", s);
}
}; #endif
//t1.cpp
#include "test.h" Test t1("t1");//全局变量
//t2.cpp
#include "test.h" Test t2("t2");//全局变量
//t3.cpp
#include "test.h" Test t3("t3");//全局变量
//main.cpp
#include <stdio.h>
#include "test.h" //注意:全局变量会先于main函数执行,因此
//4个全局变量t1-t4会被先构造,再其顺序是不确定的,
//要依赖于编译器。 //当构造完全局对象后,会执行main函数,可以发现
//t5是最后一个被构造的。 Test t4("t4");//全局变量 int main()
{
Test t5("t5");//局部变量
return ;
}
9.对象的销毁
9.1.析构函数
(1)C++的类中可以定义一个特殊的清理函数,叫析构函数
(2)析构函数的功能与构造函数相反
(3)定义:~ClassName();//注意,无参无返回值;对象销毁时会被自动调用
#include <stdio.h> class Test
{
private:
int mi; public:
Test(int i)
{
mi = i;
printf("Test(): %d\n", mi);
} //析构函数
~Test()
{
printf("~Test(): %d\n", mi);
}
}; int main()
{
Test t(); Test* pt = new Test(); delete pt; return ;
}
析构函数的定义准则:当类中自定义了构造函数,并且构造函数中使用了系统资源(如:内存申请、文件打开等),则需要自定义析构函数
10.临时对象
(1)程序意图:在 Test()中以 0 作为参数调用 Test(int i)来将成员变量 mi 初始值设置为 0.
(2)运行结果:成员变量 mi 的值为随机值(没达到目的!)
#include <stdio.h> class Test
{
private:
int mi;
public: //带参构造函数
Test(int i)
{
mi = i;
} //不带参构造函数
Test()
{
Test();//程序的意图是把Test当成普通函数来使用以达到对mi赋值的目的但直接调用构造函数,会将产生临时对象。所以Test(0)相当于
//对新的临时对象的mi赋初值为0,而不是对这个对象本身mi赋值
} void print()
{
printf("mi = %d\n", mi);
}
}; int main()
{
Test t;
t.print(); //mi并没被赋初始,会输出随机值 return ;
}
10.1.临时对象
(1)构造函数是一个特殊的函数,调用构造函数将产生一个临时对象
(2)临时对象的生命期只有一条语句的时间
(3)临时对象的作用域只在一条语句中
(4)临时对象是 C++中值得警惕的灰色地带
解决方案
#include <stdio.h> class Test
{
private:
int mi;
//正确的做法,是提供一个用来初始化的普通函数
void init(int i){ mi = i; }
public: //带参构造函数
Test(int i)
{
init(i);
} //不带参构造函数
Test()
{
init();//调用普通的初始化函数,而不是带参的构造函数Test(int i);
} void print()
{
printf("mi = %d\n", mi);
}
}; int main()
{
Test t;
t.print(); //mi被赋值为0 return ;
}
10.2.临时对象与返回值优化(RVO)
(1)现代 C++编译器在不影响最终执行结果的前提下,会尽力减少临时对象的产生。
神秘的临时对象
#include <stdio.h> class Test
{
private:
int mi; public: //带参构造函数
Test(int i)
{
mi = i;
printf("Test(int i): %d\n", i);
} //不带参构造函数
Test()
{
mi = ;
printf("Test()\n"); } //拷贝构造函数
Test(const Test& t)
{
mi = t.mi;
printf("Test(cosnt Test& t): %d\n", t.mi);
} void print()
{
printf("mi = %d\n", mi);
} ~Test(){ printf("~Test()\n"); }
}; Test func()
{
return Test();
} int main()
{ Test t = Test(); //==> Test t = 10,临时对象被编译器给“优化”掉了说明:如果不优化,该行代码的行为:调用Test(10)
//将产生一个临时对象,并用这个对象去初始化t对象,会先调用Test(int i),再调用Test(const Test& t) Test tt = func(); //==> Test tt = Test(20);==>Test tt = 20;
//说明:如果不优化,该行代码的行为:在func内部调用Test(20),将产生一个临时对象,此时(Test(int i)被调用,然后按值返回,
//会调用拷贝构造函数Test(const Test&)产生第2个临时对象,最后用第2个临时对象去初始化tt对象,将再次调用Test(const Test& t) t.print();
tt.print(); return ;
} //实际输出(优化后)结果(在g++下,可以关闭RVO优化再测试:g++ -fno-elide-constructors test.cpp)
//Test(int i): 10
//Test(int i): 20
//~Test()
//~Test()
(2)返回值优化(RVO)
//假设 Test 是一个类,构造函数为 Test(int i);
Test func()
{
return Test();//若不优化,将产生临时对象,并返回给调用者
}
①在没有任何“优化”之前,return Test(2)代码的行为这行代码中
先构造了一个 Test 类的临时的无名对象(姑且叫它 t1),接着把 t1 拷贝到另一块临时对象 t2(不在栈上),然后函数保存好 t2 的地址(放在 eax 寄存器中)后返回,Func 的栈区间被“撤消”(这时 t1 也就“没有”了,t1 的生存期在 Func 中,所以被析构了),在Test a = TestFun(); 这一句中,a 利用 t2 的地址,可以找到 t2,接着进行构造。这样 a 的构造过程就完成了。然后再把 t2 也“干掉”。
②经过“优化”的结果
可以看到,在这个过程中,t1 和 t2 这两个临时的对象的存在实在是很浪费的,占用空间不说,关键是他们都只是为 a 的构造而存在,a 构造完了之后生命也就终结了。既然这两个临时的对象对于程序员来说根本就“看不到、摸不着”(匿名对象),于是编译器干脆在里面做点手脚,不生成它们!怎么做呢?很简单,编译器“偷偷地”在我们写的 TestFun 函数中增加一个参数 Test&,然后把 a 的地址传进去(注意,这个时候 a 的内存空间已经存在了,但对象还没有被“构造”,也就是构造函数还没有被调用),然后在函数体内部,直接用 a 来代替原来的“匿名对象”,在函数体内部就完成 a 的构造。这样,就省下了两个临时变量的开销。这就是所谓的“返回值优化”!
③编译器“优化”后的伪代码
//Test a = func(); 这行代码,经过编译优化后的等价伪代码:
//从中可以发现,优化后,减少了临时变量的产生 Test a; //a只是一个占位符
func(a); //传入a的引用 void func(Test& t) //优化时,编译器在func函数中增加一个引用的参数
{
t.Test(); //调用构造函数来构造t对象
}
直接调用构造函数将产生一个临时对象,临时对象是性能的瓶颈,也是 bug 的来源之一,现代 C++编译器会尽力避开临时对象,实际工程开发中需要人为的避开临时对象。
C++深度解析教程学习笔记(6)对象的构造和销毁的更多相关文章
- C++深度解析教程学习笔记(5)面向对象
1. 面向对象基本概念 (1)面向对象的意义在于 ①将日常生活中习惯的思维方式引入程序设计中 ②将需求中的概念直观的映射到解决方案中 ③以模块为中心构建可复用的软件系统 ④提高软件产品的可维护性和可扩 ...
- C++深度解析教程学习笔记(4)C++中的新成员
1. 动态内存分配 (1)C++通过 new 关键字进行动态内存申请,是以类型为单位来申请空间大小的 (2)delete 关键字用于内存释放 ▲注意释放数组时要加[],否则只释放这个数组中的第 1 个 ...
- C++深度解析教程学习笔记(3)函数的扩展
1.内联函数 1.1.常量与宏的回顾 (1)C++中的 const 常量可以替代宏常数定义,如: ; //等价于 #define A 3 (2)C++中是否有解决方案,可以用来替代宏代码片段呢? 1. ...
- C++深度解析教程学习笔记(2)C++中的引用
1.C++中的引用 (1)变量名的回顾 ①变量是一段实际连续存储空间的别名,程序中通过变量来申请并命名存储空间 ②通过变量的名字可以使用存储空间.(变量的名字就是变量的值,&变量名是取地址操作 ...
- C++深度解析教程学习笔记(1)C到C++的升级
1.现代软件产品架构图 比如商场收银系统 2.C 到 C++ 的升级 2.1变量的定义 C++中所有的变量都可以在需要使用时再定义,而 C 语言中的变量都必须在作用域开始位置定义. 2.2 regis ...
- 《Spring源码深度解析》学习笔记——Spring的整体架构与容器的基本实现
pring框架是一个分层架构,它包含一系列的功能要素,并被分为大约20个模块,如下图所示 这些模块被总结为以下几个部分: Core Container Core Container(核心容器)包含有C ...
- Webpack新手入门教程(学习笔记)
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 30.0px Helvetica; color: #000000 } ...
- 尚硅谷韩顺平Linux教程学习笔记
目录 尚硅谷韩顺平Linux教程学习笔记 写在前面 虚拟机 Linux目录结构 远程登录Linux系统 vi和vim编辑器 关机.重启和用户登录注销 用户管理 实用指令 组管理和权限管理 定时任务调度 ...
- TypeScript 入门教程学习笔记
TypeScript 入门教程学习笔记 1. 数据类型定义 类型 实例 说明 Number let num: number = 1; 基本类型 String let myName: string = ...
随机推荐
- 一个html+js+ashx+easyui+ado.net权限管理系统
http://www.cnblogs.com/oppoic/p/html_js_ashx_easyui_authorize.html
- python面向对象总结
一 面向对象的程序设计的由来 见概述:http://www.cnblogs.com/linhaifeng/articles/6428835.html 二 什么是面向对象的程序设计及为什么要有它 面向过 ...
- OC-协议与代理
[协议]================================================================ @protocol [协议的作用]:规定了需要实现的接口方法, ...
- jQuery中this与$(this)的区别
起初以为this和$(this)就是一模子刻出来.但是我在阅读时,和coding时发现,总不是一回事,这里就谈谈this与$(this)的区别. jQuery中this与$(this)的区别 $(&q ...
- 接口取不到POST参数
利用类似httprequester小工具调试API时偶尔出现一直取不到POST的数据 解决方式: 1.$_POST['paramName']: 只能接收Content-Type: applicatio ...
- android事件传递机制以及onInterceptTouchEvent()和onTouchEvent()总结
老实说,这两个小东东实在是太麻烦了,很不好懂,我自己那api文档都头晕,在网上找到很多资料,才知道是怎么回事,这里总结一下,记住这个原则就会很清楚了: 1.onInterceptTouchEvent( ...
- 【Android】SDK工具学习 - adb
ADB(Android Debug Bridge) 小白笔记 学习资料 adb简要介绍 adb 是一个 C/S 架构的命令行工具,主要由 3 部分组成: 运行在 PC 端的 Client : 可以通过 ...
- 高级C/C++编译技术之读书笔记(五)之动态库版本控制
最近有幸阅读了<高级C/C++编译技术>深受启发,该书深入浅出地讲解了构建过程(编译.链接)中的各种细节,从多个角度展示了程序与库文件或代码的集成方法,提出了面向代码复用和系统集成的软件架 ...
- Android开源框架-Annotation框架(以ViewMapping注解为例)
Annotation 分类 1 标准 Annotation 包括Override, Deprecated, SuppressWarnings,标准 Annotation 是指 Java 自带的几个 A ...
- 2.2 web工程的目录结构
[转] 一个最简单的Web应用的目录结构如下所示: Web应用的结构定义在Servlet的规范中,目前最新版本为3.1. 下载地址:https://jcp.org/aboutJava/communit ...