Keras的泰坦尼克号的生存率的数据分析
# coding: utf-8 # In[1]: import urllib.request
import os # In[2]: url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"
filepath="titanic3.xls"
if not os.path.isfile(filepath):
result=urllib.request.urlretrieve(url,filepath)
print('downloaded:',result) # In[3]: import numpy
import pandas as pd # In[4]: all_df = pd.read_excel(filepath) # In[5]: all_df[:5] # In[6]: cols=['survived','name','pclass' ,'sex', 'age', 'sibsp',
'parch', 'fare', 'embarked']
all_df=all_df[cols]
all_df[:5] # In[7]: all_df.isnull().sum() # In[8]: df=all_df.drop(['name'], axis=1)
df[:20] # In[9]: age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean)
df[:20] # In[10]: fare_mean = df['fare'].mean()
df['fare'] = df['fare'].fillna(fare_mean) # In[11]: df['sex']= df['sex'].map({'female':0, 'male': 1}).astype(int) # In[12]: df[:2] # In[13]: x_OneHot_df = pd.get_dummies(data=df,columns=["embarked" ]) # In[14]: x_OneHot_df[:2] # In[15]: ndarray = x_OneHot_df.values
ndarray.shape # In[16]: ndarray[:2] # In[17]: Label = ndarray[:,0]
Features = ndarray[:,1:] # In[18]: Features[:2] # In[19]: from sklearn import preprocessing
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0, 1))
scaledFeatures=minmax_scale.fit_transform(Features)
scaledFeatures[:2] # In[20]: msk = numpy.random.rand(len(all_df)) < 0.8
train_df = all_df[msk]
test_df = all_df[~msk] # In[21]: msk # In[22]: print('total:',len(all_df),
'train:',len(train_df),
'test:',len(test_df)) # In[23]: def PreprocessData(raw_df):
df=raw_df.drop(['name'], axis=1)
age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean)
fare_mean = df['fare'].mean()
df['fare'] = df['fare'].fillna(fare_mean)
df['sex']= df['sex'].map({'female':0, 'male': 1}).astype(int)
x_OneHot_df = pd.get_dummies(data=df,columns=["embarked" ]) ndarray = x_OneHot_df.values
Features = ndarray[:,1:]
Label = ndarray[:,0] minmax_scale = preprocessing.MinMaxScaler(feature_range=(0, 1))
scaledFeatures=minmax_scale.fit_transform(Features) return scaledFeatures,Label # In[24]: train_Features,train_Label=PreprocessData(train_df)
test_Features,test_Label=PreprocessData(test_df) # In[25]: train_Features[:2] # In[26]: train_Label[:2] # In[27]: from keras.models import Sequential
from keras.layers import Dense,Dropout # In[28]: model = Sequential()
model.add(Dense(units=40, input_dim=9,
kernel_initializer='uniform',
activation='relu'))
model.add(Dense(units=30,
kernel_initializer='uniform',
activation='relu'))
model.add(Dense(units=1,
kernel_initializer='uniform',
activation='sigmoid'))
model.summary() # In[29]: model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])
train_history =model.fit(x=train_Features,
y=train_Label,
validation_split=0.1,
epochs=30,
batch_size=30,verbose=2) # In[30]: import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(train_history,'acc','val_acc')
show_train_history(train_history,'loss','val_loss') # In[31]: scores = model.evaluate(x=test_Features,
y=test_Label)
scores # In[32]: Jack = pd.Series([0 ,'Jack',3, 'male' , 23, 1, 0, 5.0000,'S'])
Rose = pd.Series([1 ,'Rose',1, 'female', 20, 1, 0, 100.0000,'S'])
JR_df = pd.DataFrame([list(Jack),list(Rose)],
columns=['survived', 'name','pclass', 'sex',
'age', 'sibsp','parch', 'fare','embarked'])
all_df=pd.concat([all_df,JR_df])
all_df[-2:] # In[33]: all_Features,Label=PreprocessData(all_df)
all_probability=model.predict(all_Features)
all_probability[:10] # In[34]: pd=all_df
pd.insert(len(all_df.columns),
'probability',all_probability)
pd[-2:] # In[35]: pd[(pd['survived']==0) & (pd['probability']>0.9) ] # In[36]: pd[:5] # In[ ]: # In[ ]:
excel资源如下:
链接:https://pan.baidu.com/s/1PvonynplLKC6ZepSlL9DqQ
提取码:w7z3
采用多层感知器的方案的,主要是特点是针对数据的预处理过程。对excel表格的处理。
读取文件显示前五行:

筛选出表内的指定列:

去掉名字列生成新数据:

查找未知信息null,然后补充为平均值



修改性别样式从male和female到0和1:

将DF中的数据某列拆分:
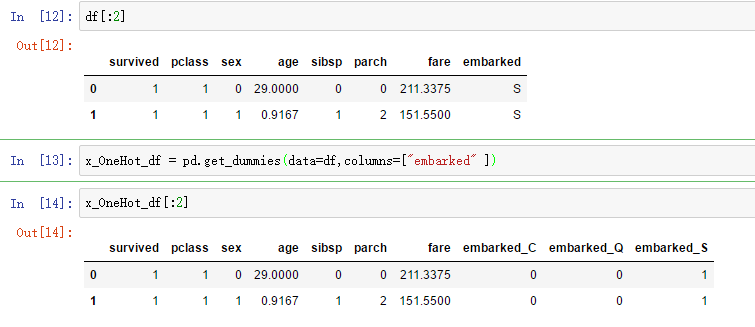
提取目标输出数据和输入数据:

将输入数据转化为0-1之间的数据方式:
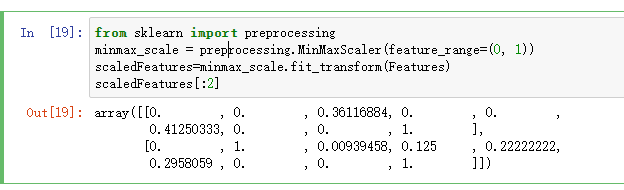
随机分割数据2:8作为测试数据和训练数据的方案!:

之后建立模型,两个隐层,计算方式为上一层神经元乘下一层神经元,加偏差下一层神经元。
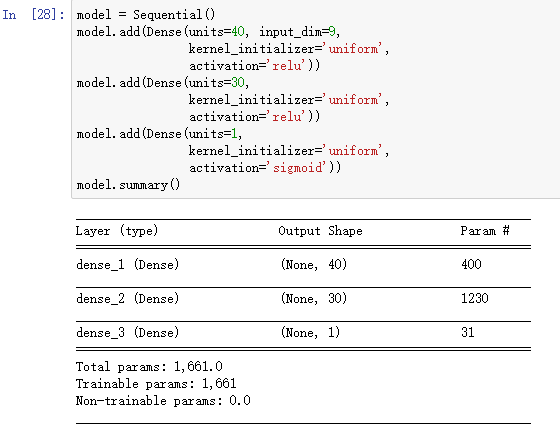
之后计算,绘图,预测。
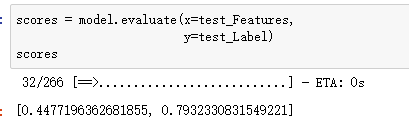
插入两行数据到总数据:

之后计算预测,找到生存概率。


筛选出实际数据为0而预测数据为存活的数据:
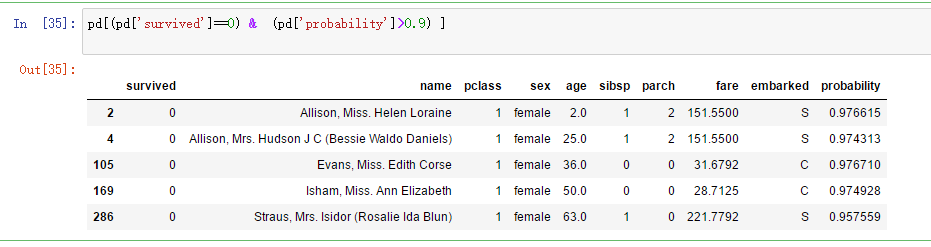
可以找到他们之所以没有存活的背后感人故事。。。。。。
Keras的泰坦尼克号的生存率的数据分析的更多相关文章
- 数据分析-kaggle泰坦尼克号生存率分析
概述 1912年4月15日,泰坦尼克号在首次航行期间撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难.沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员.虽然幸存下来有一些运气因素,但 ...
- 基于深度学习方法的dota2游戏数据分析与胜率预测(python3.6+keras框架实现)
很久以前就有想过使用深度学习模型来对dota2的对局数据进行建模分析,以便在英雄选择,出装方面有所指导,帮助自己提升天梯等级,但苦于找不到数据源,该计划搁置了很长时间.直到前些日子,看到社区有老哥提到 ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- TensorFlow从1到2(十四)评估器的使用和泰坦尼克号乘客分析
三种开发模式 使用TensorFlow 2.0完成机器学习一般有三种方式: 使用底层逻辑 这种方式使用Python函数自定义学习模型,把数学公式转化为可执行的程序逻辑.接着在训练循环中,通过tf.Gr ...
- 泰坦尼克号沉没之谜,用数据还原真相——Titanic获救率分析(用pyecharts)
泰坦尼克号获救率数据分析报告,用数据揭露真相. 一,船上乘客生存率分析报告 泰坦尼克号生存率仅有38%的,可见此次事件救援不力,救生艇严重不足,且泰坦尼克号号撞得是冰山,海水冷,没有救生艇,在水里冻死 ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- 到底该如何入门Keras、Theano呢?(浅谈)
目前刚刚开始学习Theano,可以说是一头雾水,后来发现Keras是对Theano进行了包装,直接使用Keras可以减少很多细节程序的书写,它是模块儿化的,使用比较方便,但更为细节的内容,还没有理解, ...
随机推荐
- java多线程与并发笔记
0.多线程,主要用来提高程序效率,处理耗时的操作. 多个线程写在同一个类里调用,并不是说写在前面的线程就会先运行.各个线程会进行争抢,能抢到系统资源的才会先运行. 因此,同一个程序,多个线程运行,可能 ...
- 进程实时监控pidstat命令详解
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存.设备IO.任务切换.线程等.pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行 ...
- 二分+最短路 UVALive - 4223
题目链接:https://vjudge.net/contest/244167#problem/E 这题做了好久都还是超时,看了博客才发现可以用二分+最短路(dijkstra和spfa都可以),也可以用 ...
- 【转】iOS 自动化性能采集
前言 对于iOS总体生态是比较封闭的,相比Android没有像adb这种可以查看内存.cpu的命令.在日常做性能测试,需要借助xcode中instruments查看内存.cpu等数据. 但是借助i ...
- 安恒7月赛wp
1.[order] 这道题,发现order参数处有注入点,于是就使用sqlmap盲注,emmmm,学到了sqlmap的一些小窍门. 首先,解题的语句是: sqlmap -u "htt ...
- AngularJs中url参数的获取
前言: angular获取通过链接形式访问的页面,要获取url中的参数,就不能通过路由的方式传递获取了,使用原生js或者jquery,又显得比较麻烦,好在angular已经封装了获取url参数的方法, ...
- 使用mybatis-generator-core工具自动生成mybatis实体
我们可以使用mybatis-generator-core这个工具将数据库对象转换成mybatis对象,具体步骤如下. 1.mybatis-generator-core下载 下载地址:http://do ...
- day15 json,os,sys,hashlib
序列化模块 import json # json 序列化模块 是所有语言通用的一种标准(数据转化格式). # str int bool dict list(tuple) None import pi ...
- MVC学习(四)几种分页的实现(1)
这里,我使用的是Code-First,MVC3. 我们在数据库里建一个表MyTestPages,只有一个整型字段Id. 在写一个Model类MyTestPages,代码如下 public class ...
- Bootstrap(1) 概述与环境搭建
视频教程:http://study.163.com/course/courseMain.htm?courseId=1017002 源码和笔记:http://pan.baidu.com/s/1c06Ri ...