Python学习笔记之函数式编程
python中的高阶函数
高阶函数就是 变量名指向函数,下面代码中的变量abs其实是一个函数,返回数字的绝对值,如abs(-10) 返回 10
- def add(x,y,f):
- return f(x) +f(y)
- add(-5,9,abs)
- #
python把函数作为参数
利用add(x,y,f)函数计算:
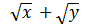
- import math
- def add(x, y, f):
- return f(x) + f(y)
- print add(25, 9, math.sqrt)
- #5,3
python中map()函数
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:
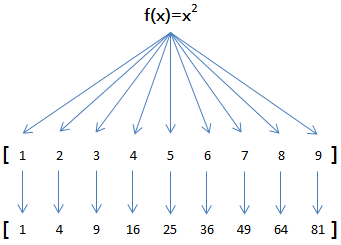
因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
- def f(x):
- return x*x
- print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
输出结果:
- [1, 4, 9, 10, 25, 36, 49, 64, 81]
注意:map()函数不改变原有的 list,而是返回一个新的 list。
例如:假设用户输入的英文名字不规范,没有按照首字母大写,后续字母小写的规则,请利用map()函数,把一个list(包含若干不规范的英文名字)变成一个包含规范英文名字的list:
- #小写转大写
- def format_name(s):
- return s.title()
- print map(format_name, ['adam', 'LISA', 'barT'])
- #['Adam', 'Lisa', 'Bart']
python中reduce()函数
from functools import reduce # Python3.X中需要引入包
reduce()函数也是Python内置的一个高阶函数。reduce()函数接收的参数和 map()类似,一个函数 f,一个list,但行为和 map()不同,reduce()传入的函数 f 必须接收两个参数,reduce()对list的每个元素反复调用函数f,并返回最终结果值。
例如,编写一个f函数,接收x和y,返回x和y的和:
- def f(x, y):
- return x + y
调用 reduce(f, [1, 3, 5, 7, 9])时,reduce函数将做如下计算:
- 先计算头两个元素:f(1, 3),结果为4;
- 再把结果和第3个元素计算:f(4, 5),结果为9;
- 再把结果和第4个元素计算:f(9, 7),结果为16;
- 再把结果和第5个元素计算:f(16, 9),结果为25;
- 由于没有更多的元素了,计算结束,返回结果25。
上述计算实际上是对 list 的所有元素求和。虽然Python内置了求和函数sum(),但是,利用reduce()求和也很简单。
reduce()还可以接收第3个可选参数,作为计算的初始值。如果把初始值设为100,计算:
- reduce(f, [1, 3, 5, 7, 9], 100)
结果将变为125,因为第一轮计算是:
计算初始值和第一个元素:f(100, 1),结果为101。
例如:
Python内置了求和函数sum(),但没有求积的函数,请利用recude()来求积:
输入:[2, 4, 5, 7, 12]
输出:2*4*5*7*12的结果
- def prod(x, y):
- return x*y
- print reduce(prod, [2, 4, 5, 7, 12])
python中filter()函数
filter()函数是 Python 内置的另一个有用的高阶函数,filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
- def is_odd(x):
- return x % 2 == 1
然后,利用filter()过滤掉偶数:
- filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
- py3 中还要加list,.....print(list( filter(is_sqr, range(1, 101)))
结果:[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
- def is_not_empty(s):
- return s and len(s.strip()) > 0
- filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])
- #['test', 'str', 'END']
- #Python 3.X 中
- print(list(filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])))
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' '),如下:
- a = ''
- a.strip()
- #结果: '123'
- a='\t\t123\r\n'
- a.strip()
- #结果:'123'
请利用filter()过滤出1~100中平方根是整数的数,即结果应该是:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
- import math
- def is_sqr(x):
- r = int(math.sqrt(x))
- return r*r==x
- print filter(is_sqr, range(1, 101))
#[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
- #python 3.X print(list(filter(is_sqr, range(1, 101))))
#[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
python中自定义排序函数
Python内置的 sorted()函数可对list进行排序:
- >>>sorted([36, 5, 12, 9, 21])
- #[5, 9, 12, 21, 36]
但 sorted()也是一个高阶函数,它可以接收一个比较函数来实现自定义排序,比较函数的定义是,传入两个待比较的元素 x, y,如果 x 应该排在 y 的前面,返回 -1,如果 x 应该排在 y 的后面,返回 1。如果 x 和 y 相等,返回 0。
因此,如果我们要实现倒序排序,只需要编写一个reversed_cmp函数:
- def reversed_cmp(x, y):
- if x > y:
- return -1
- if x < y:
- return 1
- return 0
这样,调用 sorted() 并传入 reversed_cmp 就可以实现倒序排序:
- >>> sorted([36, 5, 12, 9, 21], reversed_cmp)
- #[36, 21, 12, 9, 5]
sorted()也可以对字符串进行排序,字符串默认按照ASCII大小来比较:
- >>> sorted(['bob', 'about', 'Zoo', 'Credit'])
- ['Credit', 'Zoo', 'about', 'bob']
'Zoo'排在'about'之前是因为'Z'的ASCII码比'a'小。
例如:
对字符串排序时,有时候忽略大小写排序更符合习惯。请利用sorted()高阶函数,实现忽略大小写排序的算法。
输入:['bob', 'about', 'Zoo', 'Credit']
输出:['about', 'bob', 'Credit', 'Zoo']
- def cmp_ignore_case(s1, s2):
- u1 = s1.upper()
- u2 = s2.upper()
- if u1 > u2:
- return 1
- if u1 < u2:
- return -1
- return 0
- print sorted(['bob', 'about', 'Zoo', 'Credit'], cmp_ignore_case)
- #python 3.X 中自定义排序函数 sorted()
- a = ['bob', 'about', 'Zoo', 'Credit']
- print(sorted(a, key=str.lower))
- l = [36, 5, 12, 9, 21]
- print(sorted(l, key=lambda x:(x<0,abs(x))))
python中返回函数
Python的函数不但可以返回int、str、list、dict等数据类型,还可以返回函数!
例如,定义一个函数 f(),我们让它返回一个函数 g,可以这样写:
- def f():
- print 'call f()...'
- # 定义函数g:
- def g():
- print 'call g()...'
- # 返回函数g:
- return g
仔细观察上面的函数定义,我们在函数 f 内部又定义了一个函数 g。由于函数 g 也是一个对象,函数名 g 就是指向函数 g 的变量,所以,最外层函数 f 可以返回变量 g,也就是函数 g 本身。
调用函数 f,我们会得到 f 返回的一个函数:
- >>> x = f() # 调用f()
- call f()...
- >>> x # 变量x是f()返回的函数:
- <function g at 0x1037bf320>
- >>> x() # x指向函数,因此可以调用
- call g()... # 调用x()就是执行g()函数定义的代码
请注意区分返回函数和返回值:
- def myabs():
- return abs # 返回函数
- def myabs2(x):
- return abs(x) # 返回函数调用的结果,返回值是一个数值
返回函数可以把一些计算延迟执行。例如,如果定义一个普通的求和函数:
- def calc_sum(lst):
- return sum(lst)
调用calc_sum()函数时,将立刻计算并得到结果:
- >>> calc_sum([1, 2, 3, 4])
- 10
但是,如果返回一个函数,就可以“延迟计算”:
- def calc_sum(lst):
- def lazy_sum():
- return sum(lst)
- return lazy_sum
# 调用calc_sum()并没有计算出结果,而是返回函数:
- >>> f = calc_sum([1, 2, 3, 4])
- >>> f
- <function lazy_sum at 0x1037bfaa0>
# 对返回的函数进行调用时,才计算出结果:
- >>> f()
- 10
由于可以返回函数,我们在后续代码里就可以决定到底要不要调用该函数。
例如:
请编写一个函数calc_prod(lst),它接收一个list,返回一个函数,返回函数可以计算参数的乘积。
- def calc_prod(lst):
- def lazy_prod():
- def f(x,y):
- return x*y
- return reduce(f, lst, 1)
- return lazy_prod
- f = calc_prod([1, 2, 3, 4])
- print f()
python中闭包
在函数内部定义的函数和外部定义的函数是一样的,只是他们无法被外部访问:
- def g():
- print 'g()...'
- def f():
- print 'f()...'
- return g
将 g 的定义移入函数 f 内部,防止其他代码调用 g:
- def f():
- print 'f()...'
- def g():
- print 'g()...'
- return g
但是,考察上一小节定义的 calc_sum 函数:
- def calc_sum(lst):
- def lazy_sum():
- return sum(lst)
- return lazy_sum
注意: 发现没法把 lazy_sum 移到 calc_sum 的外部,因为它引用了 calc_sum 的参数 lst。
像这种内层函数引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)。
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。
例如:
返回闭包不能引用循环变量,请改写count()函数,让它正确返回能计算1x1、2x2、3x3的函数。
- def count():
- fs = []
- for i in range(1, 4):
- def f(j):
- def g():
- return j*j
- return g
- r = f(i)
- fs.append(r)
- return fs
- f1, f2, f3 = count()
- print f1(), f2(), f3()
python中匿名函数 lambda函数
高阶函数可以接收函数做参数,有些时候,我们不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算 f(x)=x2 时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
- #Function 正常使用的表达方法
- def func(n):
- return n + 1
- print(func(2))
- #Lambda 表达方法
- f = lambda x:x+1
- print(f)
- print(f(2))
- >>> map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])
- [1, 4, 9, 16, 25, 36, 49, 64, 81]
- #Python 3.X中是:
- print(list(map(lambda x: x * x, [1,2,3,4,5,6,7,8,9])))
- #[1, 4, 9, 16, 25, 36, 49, 64, 81]
当然Lambda表达式也有以下的使用情况:
- #多参数情况
- print("多参数情况")
- multi = lambda x,y,z: x+y+z
- print(multi(1,2,3))
- #和非匿名函数一块工作
- print("和非匿名函数一块工作")
- def namedFunc(n):
- return lambda x:n+x
- print(namedFunc(2)) #会打印出function,相当于 lambda x: 2+x
- print(namedFunc(2)(3)) #会打印出5
- f = namedFunc(2)
- print(f(3)) #等同于namedFunc(2)(3)
通过对比可以看出,匿名函数 lambda x: x * x 实际上就是:
- def f(x):
- return x * x
关键字lambda 表示匿名函数,冒号前面的 x 表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不写return,返回值就是该表达式的结果。
例如:
- print filter(lambda s: s and len(s.strip())>0, ['test', None, '', 'str', ' ', 'END'])
- #Python3.x 中是这样的:
- print(list(filter(lambda s: s and len(s.strip())>0, ['test', None, '', 'str', ' ', 'END'])))
对于lambda表达式在Python程序中的一些小建议:
1. 对于简单的逻辑处理,可以放心使用Lambda表达式,这样比较简洁
2. 对于复杂的逻辑处理,尽量避免使用Lambda表达式,易读性差,而且容易出错(大牛除外)
python 中 decortor 装饰器

python中编写无参数decorator
Python的 decorator 本质上就是一个高阶函数,它接收一个函数作为参数,然后,返回一个新函数。
使用 decorator 用Python提供的 @ 语法,这样可以避免手动编写f = decorate(f) 这样的代码。
考察一个@log的定义:
- def log(f):
- def fn(x):
- print 'call ' + f.__name__ + '()...'
- return f(x)
- return fn
对于阶乘函数,@log工作得很好:
- @log
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- print factorial(10)
结果:
- call factorial()...
- 3628800
但是,对于参数不是一个的函数,调用将报错:
- @log
- def add(x, y):
- return x + y
- print add(1, 2)
- #结果:
- Traceback (most recent call last):
- File "test.py", line 15, in <module>
- print add(1,2)
- TypeError: fn() takes exactly 1 argument (2 given)
因为 add() 函数需要传入两个参数,但是 @log 写死了只含一个参数的返回函数。
要让 @log 自适应任何参数定义的函数,可以利用Python的 *args 和 **kw,保证任意个数的参数总是能正常调用:
- def log(f):
- def fn(*args, **kw):
- print 'call ' + f.__name__ + '()...'
- return f(*args, **kw)
- return fn
现在,对于任意函数,@log 都能正常工作。
例子:
请编写一个@performance,它可以打印出函数调用的时间。
- import time
- def performance(f):
- def fn(*args, **kw):
- t1 = time.time()
- r = f(*args, **kw)
- t2 = time.time()
- print 'call %s() in %fs' % (f.__name__, (t2 - t1))
- return r
- return fn
- @performance
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- print factorial(10)
python中完善decorator
Python学习笔记之函数式编程的更多相关文章
- python学习笔记011——函数式编程
1 函数式编程 面向对象 ,面向过程 ,函数式编程 侧重函数的作用,注重函数结果的传递 函数可以被赋值,也可以接受其他的值 2 函数式编程特点 1.函数是一等公民 与其他变量一样,可以赋值和被赋值,可 ...
- Python学习笔记6 函数式编程_20170619
廖雪峰python3学习笔记: # 高阶函数 将函数作为参数传入,这样的函数就是高阶函数(有点像C++的函数指针) def add(x, y): return x+y def mins(x, y): ...
- python学习笔记(六) 函数式编程
一 函数对象 函数同样可以作为对象复制给一个变量,如下: f = abs; print(f(-10)) f = 'abs'; print(f) def add(a,b,f): return f(a) ...
- python学习笔记1 -- 函数式编程之高阶函数 sorted排序
python提供了很强大的内置排序函数,妈妈再也不担心我不会写冒泡排序了呀,sorted函数就是这个排序函数,该函数参数准确的说有四个,sorted(参数1,参数2,参数3,参数4). 参数1 是需要 ...
- python学习笔记1 -- 函数式编程之高阶函数 map 和reduce
我用我自己,就是高阶函数,直接表现就是函数可以作为另一个函数的参数,也可以作为返回值 首先一个知识点是 函数的表现形式,印象中的是def fw(参数)这种方式定义一个函数 python有很多的内置函 ...
- python学习笔记1 -- 函数式编程之高阶函数 使用函数作为返回值
使用函数作为返回值,看起来就很高端有木有,前面了解过函数名本身就是一个变量,就比如abs()函数,abs只是变量名,而abs()才是函数调用,那么我们如果把ads这个变量作为返回值返回会怎么样呢,这就 ...
- python学习笔记1 -- 函数式编程之高阶函数 filter
filter 函数用于过滤序列,与map 和reduce函数类似,作为高阶函数,他们也是同样的使用方法,filter(参数1, 参数2),参数1是一个函数,而参数2是一个序列. filter的作用是根 ...
- python学习笔记(七):面向对象编程、类
一.面向对象编程 面向对象--Object Oriented Programming,简称oop,是一种程序设计思想.在说面向对象之前,先说一下什么是编程范式,编程范式你按照什么方式来去编程,去实现一 ...
- Clojure学习笔记(二)——函数式编程
定义 “函数式编程”是一种编程范式(programming paradigm),即如何编写程序的方法论.主要思想是把运算过程尽量写成一系列嵌套的函数调用. 举例来说,现在有这样一个数学表达式: (1 ...
随机推荐
- CronExpression
CronTrigger CronTriggers往往比SimpleTrigger更有用,如果您需要基于日历的概念,而非SimpleTrigger完全指定的时间间隔,复发的发射工作的时间表.CronTr ...
- fidder及Charles使用
1. fidder抓https包的基本配置,可参见以下博文 http://blog.csdn.net/idlear/article/details/50999490 2. 遇到问题:抓包看只有Tunn ...
- linux command ------ unlink 和 rm 的区别
unlink 不能用于删除文件夹,rm 可以删除文件和文件夹 当删除文件时,rm 和 unlink 是完全一样的.
- Qt ------ UDP发送不了或接收不到问题
1.禁用不需要的网卡,比如禁用虚拟机网卡. 2.向所有网卡广播数据 /* * 直接调用 QUdpSocket 的 writeDatagram() 函数发送数据,如果有多张网卡(装了虚拟机会增加网卡), ...
- java基础知识代码-------枚举类型
package com.mon10.day22; /** * 类说明 :枚举类型,案例二 * * @author 作者 : chenyanlong * @version 创建时间:2017年10月22 ...
- python---django中orm的使用(5)数据库的基本操作(性能相关:select_related,和prefetch_related重点)(以及事务操作)
################################################################## # PUBLIC METHODS THAT ALTER ATTRI ...
- python---django中orm的使用(2)
1.基于对象的正向查询和反向查询 在python---django中orm的使用(1)中也提到了正向和反向查找 表:一对多 书籍和出版社 class Book(models.Model): titl ...
- Java入门系列(九)Java API
String,StringBuilder,StringBuffer三者的区别 1.首先说运行速度,或者说是执行速度 在这方面运行速度快慢为:StringBuilder > StringBuffe ...
- CSS规范 - 代码格式--(来自网易)
选择器.属性和值都使用小写 在xhtml标准中规定了所有标签.属性和值都小写,CSS也是如此.单行写完一个选择器定义 便于选择器的寻找和阅读,也便于插入新选择器和编辑,便于模块等的识别.去除多余空格, ...
- html5 canvas 对角线渐变
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...