python---基础知识回顾(三)(面向对象)
一.多继承(寻找方法)
主要学习多继承中的寻找方法的方式:分别是深度优先和广度优先
1.当类是经典类时,多继承情况下,会按照深度优先方式查找
2.当类是新式类时,多继承情况下,会按照广度优先方式查找
新式类和经典类的区分:
如果当类继承于object或者其父类继承于object,那么该类就是新式类
以后推荐使用新式类,新式类中包含有更多的功能

深度优先和广度优先:都是直接父类从左向右查询:
经典类:深度优先:
class D:
......
pass class B(D):
......
pass class C(D):
......
pass class A(B,C):
.....
def bar():
self.search()
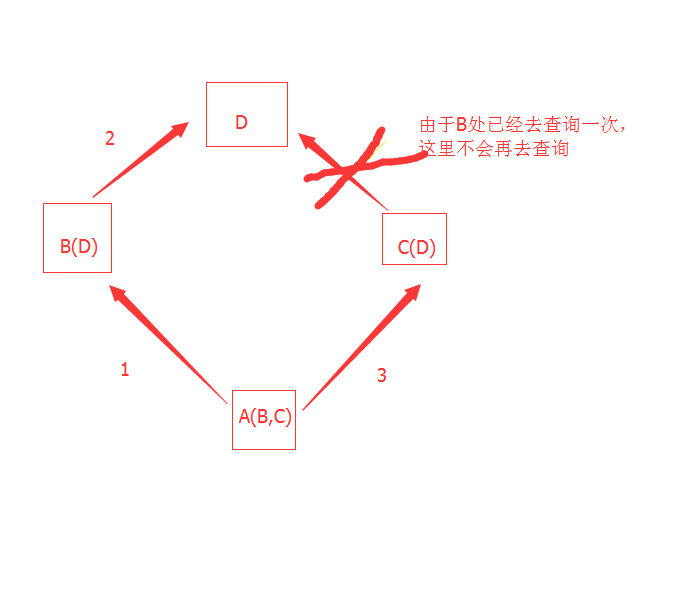
若是在A中没有该search函数---->则去(左父类)B类中去寻找,若是B类中也没有---->则去B父类(D)(向更深一级去查询)
若是D中也没有----->再去(A右父类C)中去查询 查找顺序 A--->B ---->D---->C 若是查找到了,则停止,没有则报错
新式类:广度优先
class D(object):
......
pass class B(D):
......
pass class C(D):
......
pass class A(B,C):
.....
def bar():
self.search()
若是在A中没有该search函数---->则去(左父类)B类中去寻找,若是B类中也没有---->再去(A右父类C)中去查询--->则去B父类(D)(向更深一级去查询)
查找顺序 A--->B ---->C---->D 若是查找到了,则停止,没有则报错

上面只是简单介绍,并不完整,而且mro并未介绍,所以上面的继承关系,虽然易于理解,但是可能不是太准确。
详细请看:python---方法解析顺序MRO(Method Resolution Order)<主要解决类中super方法>
二.多态(多种形态)
意味着可以对不同类的对象使用同样的操作(就算不知道变量所引用的对象类型是什么,还是能对他进行操作,而他也会根据对象或类的不同而表现出不同的行为)
class Foo:
def f1(self):
print("foo") class Bar:
def f1(self):
print("bar") def func(obj): #obj有多种形态,可以是Foo,也可以是Bar
obj.f1() func(Foo())
func(Bar())
毁掉这种多态的形式是使用type,isinstance或者issubclass函数等。如果可能尽量避免使用这些函数。真正重要的是让对象按照你所希望的方式工作,而不是在意是否是正确的类型。
补充:类和对象在内存中的存在形式:
类以及类中的方法在内存中只有一份,而根据类创建的每一个对象都在内存中需要存一份
三.类的成员(主要是属性)
分为三大类:字段,方法和属性
-----字段:分为普通字段,静态字段
类中成员 -----方法:分为普通方法,类方法,静态方法
-----属性:普通属性
(一)字段:
普通字段属于对象,静态字段属于类(静态字段也可以使用self(对象)访问,但是不能进行修改,修改的话,会变为普通字段,这时使用对象访问则只会访问到普通字段,而不是静态字段)
# coding:utf8
# __author: Administrator
# date: //
# /usr/bin/env python class Test:
name = "asda" def __init__(self,age):
self.age = age def get(self):
print(self.name,self.age) #直接访问普通字段
obj = Test()
print(obj.age)
print(obj.name) #可以访问 obj.get() #直接访问静态字段
print(Test.name)
两种字段在内存中存放方式:
静态字段只存放一个,普通字段随对象的创建而增加。

obj = Test()
obj2 = Test() print(id(obj.age),id(obj2.age)) # 497898592 不同的对象,包含属于自己的普通字段
print(obj.age,obj2.age) # print(id(obj.name),id(obj2.name),id(Test.name)) # 5282648 但是包含同一个静态字段
print(obj.name,obj2.name) #asda asda
一般对静态字段的访问,我们最好使用类来访问.因为我们若是使用对象来访问静态字段,对其进行修改时,往往达到不一样的预期(使用对象修改的话,在该对象中该字段会变为普通字段,这时使用对象访问则只会访问到普通字段,而不是静态字段,也不会影响到其他对象数据。达不到统一修改数据)
obj.name = "gaega"
print(id(obj.name),id(obj2.name),id(Test.name)) # 5282648 5282648 只是在内存中对其有生成了一个普通字段,叫做name
print(obj.name,obj2.name,Test.name) #gaega asda asda
相同名字的普通字段和静态字段的访问:
class Test:
name = "asda" def __init__(self,name,age):
self.age = age
self.name = name def get(self):
print(self.name,self.age,Test.name) obj = Test("adadfafwad",)
obj.get() #adadfafwad asda
(二):方法
普通方法:由对象调用;至少含有一个self参数(代表该调用对象)
类方法:由类调用;至少含有一个cls参数(代表调用该方法的类)
静态方法:有类调用;无默认参数
3种方法的调用者不同,默认参数不同
class Foo:
def __init__(self):
pass
#普通方法
def ord_func(self):
print("普通方法")
@classmethod
def class_func(cls):
print("类方法")
@staticmethod
def static_func():
print("静态方法")
#调用普通方法
f = Foo()
f.ord_func()
#调用类方法
Foo.class_func()
#调用静态方法
Foo.static_func()
三种方法的使用
所有方法都保存在类的内存中
(三):属性
是普通方法的变种
1.属性的基本使用
class Foo:
def ord_func(self):
pass #定义属性
@property
def prop(self):
pass 使用属性
obj = Foo()
obj.prop #进行调用
注意:
- 定义时:在普通方法基础上加上@property
- 定义时:属性仅有一个self参数
- 调用时:不需要括号
属性存在意义是:(1)访问属性时可以制造出和访问字段完全相同的假象,(2)属性由方法变种而来,如果Python中没有属性,方法完全可以代替其功能
class Foo:
def ord_func(self):
pass def set_prop(self,...):
pass def get_prop(self):
return ... obj = Foo()
obj.set_prop(....)
obj.get_prop()
方法替换
Python的属性的功能是:属性内部进行一系列的逻辑计算,最终将计算结果返回。
2.属性的两种定义方式:
- 装饰器:在方法上应用装饰器(上面的基本使用就是)
- 静态字段:在类中定义值为property对象的静态字段
(1)装饰器方式:在类的普通方法上应用@property装饰器
在python中类有经典类和新式类两种。新式类的属性也比经典类的属性丰富
经典类:
class Goods:
@property
def price(self):
return
obj = Goods()
res = obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
新式类:
class Goods(object):
@property
def price(self):
print('@property')
@price.setter
def price(self, value):
print('@price.setter')
@price.deleter
def price(self):
print('@price.deleter')
# ############### 调用 ###############
obj = Goods()
obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
obj.price = # 自动执行 @price.setter 修饰的 price 方法,并将 赋值给方法的参数
del obj.price # 自动执行 @price.deleter 修饰的 price 方法
(2)静态字段方法:
#静态字段方法,经典类和新式类无区别
class Rect:
def __init__(self):
self.width =
self.height = def setSize(self,size):
self.width,self.height = size def getSize(self):
return self.width,self.height def delSize(self):
self.width,self.height = (0,0) size = property(getSize,setSize,delSize,"这是doc") #由于属性是基于普通方法实现的,我们最好使用对象的方式来设置,获取
r = Rect()
r.size = ,
print(r.size) #(, )
其中property构造方法中有四个参数
def __init__(self, fget=None, fset=None, fdel=None, doc=None)
第一个参数是方法名,调用 对象.属性 时自动触发执行方法,用于获取
第二个参数是方法名,调用 对象.属性 = XXX 时自动触发,用于赋值
第三个参数是方法名,调用 del 对象.属性 时自动触发执行函数,用于删除
第四个参数是字符串,调用 对象.属性.__doc__ 此参数是该属性的描述信息
其中Django中的request也是由静态字段方法的属性实现:
从request.POST进入源码中查看:
class WSGIRequest(http.HttpRequest):
def __init__(self, environ):
script_name = get_script_name(environ)
path_info = get_path_info(environ)
if not path_info:
# Sometimes PATH_INFO exists, but is empty (e.g. accessing
# the SCRIPT_NAME URL without a trailing slash). We really need to
# operate as if they'd requested '/'. Not amazingly nice to force
# the path like this, but should be harmless.
path_info = '/'
self.environ = environ
self.path_info = path_info
# be careful to only replace the first slash in the path because of
# http://test/something and http://test//something being different as
# stated in http://www.ietf.org/rfc/rfc2396.txt
self.path = '%s/%s' % (script_name.rstrip('/'),
path_info.replace('/', '', ))
self.META = environ
self.META['PATH_INFO'] = path_info
self.META['SCRIPT_NAME'] = script_name
self.method = environ['REQUEST_METHOD'].upper()
self.content_type, self.content_params = cgi.parse_header(environ.get('CONTENT_TYPE', ''))
if 'charset' in self.content_params:
try:
codecs.lookup(self.content_params['charset'])
except LookupError:
pass
else:
self.encoding = self.content_params['charset']
self._post_parse_error = False
try:
content_length = int(environ.get('CONTENT_LENGTH'))
except (ValueError, TypeError):
content_length =
self._stream = LimitedStream(self.environ['wsgi.input'], content_length)
self._read_started = False
self.resolver_match = None def _get_scheme(self):
return self.environ.get('wsgi.url_scheme') @cached_property
def GET(self):
# The WSGI spec says 'QUERY_STRING' may be absent.
raw_query_string = get_bytes_from_wsgi(self.environ, 'QUERY_STRING', '')
return http.QueryDict(raw_query_string, encoding=self._encoding) def _get_post(self):
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post def _set_post(self, post):
self._post = post @cached_property
def COOKIES(self):
raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '')
return http.parse_cookie(raw_cookie) @property
def FILES(self):
if not hasattr(self, '_files'):
self._load_post_and_files()
return self._files POST = property(_get_post, _set_post)
四.类的成员修饰符(私有)
私有成员命名时一般使用__双下划綫命名。(特殊成员除外__init__,__new__ .....)
注意:私有成员也可以在外部访问:使用对象._类__属性名
class C(object):
__name = "dasfa" #静态私有字段 def __init__(self):
self.__age = def get(self):
return self.__age,C.__name obj = C() age,name = obj.get()
print(age,name) # dasfa print(C.__name,obj.__name,obj.__age) #AttributeError: type object 'C' has no attribute '__name' print(obj._C__name,obj._C__age) #dasfa
注意:不止字段,对于成员方法也可以定义私有(私有是不可以继承的)
五.类的特殊成员
1.__doc__:表示类的描述信息
class C(object):
'''这是类的描述信息''' def __init__(self):
pass obj = C()
print(C.__doc__,obj.__doc__) #这是类的描述信息 这是类的描述信息
2.__module__和__class__分别表示当前操作对象在哪个模块,和类是什么
class C(object):
'''这是类的描述信息''' def __init__(self):
pass obj = C()
print(C.__module__,C.__class__,obj.__module__,obj.__class__)
#__main__ <class 'type'> __main__ <class '__main__.C'>
#<class 'type'>说明了类也是对象,说明python中一切皆对象
补充:isinstance(obj,cls)可以用于判断是不是类的对象,issubclass(subcls,cls)可以看类是不是其子类
3.__init__构造方法,通过类创建对象是自动触发。
补充super可以获取父类的方法来执行
class A(object):
def __init__(self):
print("这是A")
class B(A):
def __init__(self):
print("这是B")
class C(B):
def __init__(self):
super(C,self).__init__()
print("这是C")
obj = C()
# 这是B
# 这是C
要想执行A构造,需要在B中加入super函数
4.__del__析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
5.__call__
对象后面加括号,触发执行。在前面的由类实现的装饰器中有使用到。
class A(object):
def __init__(self):
print("这是A")
def __call__(self, *args, **kwargs):
print("对象()来调用了")
objA = A() #这是A
objA() #对象()来调用了
6.__dict__
类调用:返回类中静态成员,和成员方法(即存放在类中内存中的数据字典)
对象调用:返回对象的普通字段(即存在类中的数据字典)
class A(object):
name = "Adaf" def __init__(self):
self.age =
print("这是A") def get(self):
return self.age def __call__(self, *args, **kwargs):
print("对象()来调用了") objA = A() #这是A
objA() #对象()来调用了
print(objA.__dict__) #{'age': }
print(A.__dict__) #{'__dict__': <attribute '__dict__' of 'A' objects>, '__init__': <function A.__init__ at 0x0000000000B83400>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__call__': <function A.__call__ at 0x0000000000B83598>, 'get': <function A.get at 0x0000000000B83510>, '__doc__': None, '__module__': '__main__', 'name': 'Adaf'}
7.__str__
若是在类中调用了该方法,那么在打印对象时,将输出该方法的返回值
class A(object):
def __init__(self):
print("这是A")
def __str__(self):
return "这就是__str__"
objA = A() #这是A
print(objA) #这就是__str__
8.__getitem__,__setitem__,__delitem__
用于索引操作,如字典。以上分别获取,设置,删除数据
class Foo(object):
def __init__(self):
self.dict = {} def __getitem__(self, key):
return self.dict[key] def __setitem__(self, key, value):
self.dict[key] = value def __delitem__(self, key):
del self.dict[key] objF = Foo()
objF['k1']='v1'
print(objF['k1']) #v1
print(objF.dict) #{'k1': 'v1'}
del objF['k1']
print(objF.dict) #{}
自定义session或者cookie时使用过
9.__getslice__、__setslice__、__delslice__
用于切片,如列表
>>> l = [,,,,]
>>> l
[, , , , ]
>>> l[:]
[, ]
>>> l[:] = [] #会将这两个元素变为一个
>>> l
[, , , ]
>>> del l[:] #删除这两个元素
>>> l
[, ]
>>> dit = []
>>> dit[:] = [,] #若是原来不存在数据,或者索引超过,会从默认处开始添加数据
>>> dit
[, ]
>>> dit[]
列表切片补充
class Foo1(object):
def __init__(self):
self.list = [] def __getslice__(self, i, j):
return self.list[i:j] def __setslice__(self, i, j, sequence):
self.list[i:j] = sequence def __delslice__(self, i, j):
del self.list[i:j] foo1 = Foo1()
foo1[:]=[,,,,]
foo1[:]=[,]
print(foo1[:]) #[, , , , ]
10.__iter__用于迭代器。之所以列表,字典,元组可以进行for循环,是因为类型内部定义了__iter__
class Foo(object):
def __init__(self, sq):
self.sq = sq
def __iter__(self):
return iter(self.sq)
obj = Foo([,,,])
for i in obj:
print i
11.__new__和__metaclass__
补充:在__module__和__class__中说过python中一切都是对象(我们定义的类也是对象)
class C(object):
'''这是类的描述信息''' def __init__(self):
pass print(C.__class__)
#<class 'type'>
#<class 'type'>说明了类也是对象,说明python中一切皆对象
说明类是type类的一个实例!即:Foo类对象 是通过type类的构造方法创建。
使用type创建类:
def type_func(self):
print("type 创建的 普通成员方法") Foo3 = type('Foo2',(object,),{'func':type_func}) #创建了一个Foo2类,赋值给Foo3,,其中含有func,是由type_func赋值的 #所以最好类名保持一致,函数名也一致
type普通成员方法
def type_func(self):
print("type 创建的 普通成员方法") def type_static():
print("type 创建的 静态成员方法") @classmethod
def type_class(cls):
print("type 创建的 类成员方法") Foo3 = type('Foo3',(object,),{'name':'这是静态字段','type_func':type_func,'type_static':type_static,'type_class':type_class}) f = Foo3()
print(Foo3.name) #这是静态字段
print(f.type_func(),Foo3.type_class(),Foo3.type_static())
# type 创建的 普通成员方法
# type 创建的 类成员方法
# type 创建的 静态成员方法
type静态和类成员方法和静态成员字段
注意:
type中不止可以放置属性和方法,还可以放置类,作为元类
from django.forms import ModelForm
from repository import models def create_dynamic_model_form(admin_class):
'''动态生成modelform'''
class Meta:
model = models.CustumerInfo # 将表与元类中的数据关联
fields = "__all__" dynamic_form = type("DynamicModelForm",(ModelForm,),{'Meta':Meta}) print(dynamic_form)
type中设置元类
那么问题来了,类默认是由 type 类实例化产生,type类中如何实现的创建类?类又是如何创建对象?
答:类中有一个属性 __metaclass__,其用来表示该类由 谁 来实例化创建,所以,我们可以为 __metaclass__ 设置一个type类的派生类,从而查看 类 创建的过程。
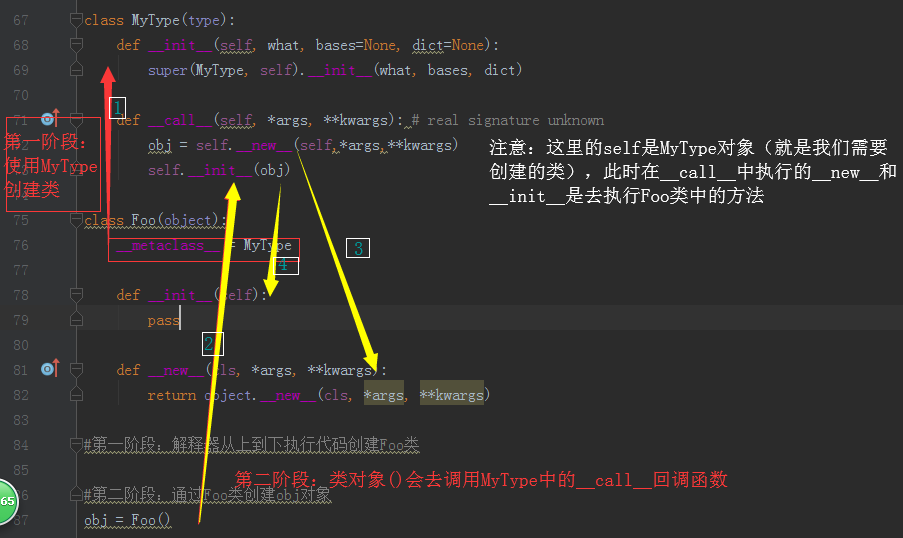
class MyType(type):
def __init__(self, what, bases=None, dict=None):
super(MyType, self).__init__(what, bases, dict) def __call__(self, *args, **kwargs): # real signature unknown
obj = self.__new__(self,*args,**kwargs)
self.__init__(obj) class Foo(object):
__metaclass__ = MyType def __init__(self):
pass def __new__(cls, *args, **kwargs):
return object.__new__(cls, *args, **kwargs) #第一阶段:解释器从上到下执行代码创建Foo类 #第二阶段:通过Foo类创建obj对象
obj = Foo()
这里也可以了解到__init__和__call__是由类执行而不是由对象执行
六.异常处理
python用异常对象来表示异常情况,遇到错误后,会引发异常。如果异常对象并未被处理或捕捉,程序就会用所谓的回溯(traceback,一种错误信息)来终止程序
>>> /
Traceback (most recent call last):
File "<stdin>", line , in <module>
ZeroDivisionError: division by zero
1.自己触发错误:raise语句
raise 异常类或异常对象(Exception及其子类) #可以触发错误
>>> raise Exception
Traceback (most recent call last):
File "<stdin>", line , in <module>
Exception
#没有任何错误信息的普通异常 >>> raise Exception("fafwafwa")
Traceback (most recent call last):
File "<stdin>", line , in <module>
Exception: fafwafwa
#添加了异常信息的普通异常
常用异常类:
Exception 所有异常的基类
AttributeError 特性引用或者赋值失败时引发
IOError 试图打开不存在文件时引发
IndexError 在使用序列中不存在的索引时引发
KeyError 在使用映射中不存在的键时引发
NameError 找不到名字(变量)时引发
SyntaxError 在代码为错误时引发
TypeError 在内建操作或者函数应用于错误类型的对
ValueError 在内建操作或者函数应用于正确类型的对象,但是该对象使用不合适的值时引发
ZeroDivisionError 在除法或者模操作的第二个参数为0时引发
https://blog.csdn.net/gavin_john/article/details/50738323
2.自定义异常类:
需要确保从所有异常的基类Exception中继承
class SomeCustomException(Exception):
def __init__(self,msg):
self.msg = msg def __str__(self):
return self.msg try:
raise SomeCustomException("自定义异常")
except SomeCustomException as e:
print(e)
3.捕捉多个异常:
try:
...
except TypeError:
...
except ZeroDivisionError:
... 或者
try:
...
except (TypeError,ZeroDivisionError):
...
4.捕捉对象:
except (TypeError,ZeroDivisionError) as e:
或者
except (TypeError,ZeroDivisionError) , e:
>>> try:
... x = input("one:")
... y = input("two:")
... print(x/y)
... except (ZeroDivisionError,TypeError) as e:
... print(e)
...
one:
two:
unsupported operand type(s) for /: 'str' and 'str' #默认去捕捉第一个错误,返回给异常对象e
5.真正的全捕捉
>>> try:
... x = input("one:")
... y = input("two:")
... print(x/y)
... except :
... print(e)
或者
>>> try:
... x = input("one:")
... y = input("two:")
... print(x/y)
... except Exception,e:
... print(e)
6.异常中的其他语句:
try:
主要语句
pass
except TypeError as e:
异常处理
pass
else:
主要语句执行无错误时,执行该模块
pass
finally:
无论是否出错,最终都会执行该模块
pass
7.断言assert
assert 条件, 错误信息
>>> assert == #正确时,不会执行
>>> assert == ,"dasd"
Traceback (most recent call last):
File "<stdin>", line , in <module>
AssertionError: dasd #错误时,抛出断言错误
Python中何时使用断言 assert
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单。在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件时就崩溃而且相对于返回一些不容易看懂的错误提示,不如让他返回给我们自定义的错误提示
全局变量
count = #不希望被修改,但是有可能其他人调用程序时将其修改了。此时需要抛出错误 assert count == , "固定数据被修改"
七.反射
函数前面也提及过,反射
hasattr,getattr,setattr,delattr
用于判断对象中是否有这个成员,.....
def hasattr(*args, **kwargs): # real signature unknown
"""
Return whether the object has an attribute with the given name. This is done by calling getattr(obj, name) and catching AttributeError.
"""
pass
也可以获取类中是否有这个成员,.....
也可以获取模块中是否有这个函数,.....
class Test:
age = def __init__(self):
self.name = "dsafd"
pass def get(self):
print("ok") print(hasattr(Test(),'get')) #True
print(hasattr(Test,'get')) #True
模块:
if hasattr(sys, "setdefaultencoding"):
del sys.setdefaultencoding
python中一切都是对象
相似的obj.__dict__可以获取成员
八:更好的继承方式
案例:水果按照去果皮的方法,分为剥皮和削皮两种,那么苹果是属于削皮类,香蕉属于剥皮类。
传统的设计类的继承为:

class Fruit:
def __init__(self):
pass class BpFruit(Fruit):
def __init__(self):
pass def BpFunc(self):
pass class XpFruit(Fruit):
def __init__(self):
pass def XpFunc(self):
pass class Apple(XpFruit):
def __init__(self):
pass class Banana(BpFruit):
def __init__(self):
pass
简单实现方法
对于上面的继承方式,我们再想扩展的话,会有点困难,对于现在的框架,例如Django,对于继承来说,不会使用上面的方法。不易维护。
例如:现在要将水果再分为夏天和冬天水果,那么大概是需要将原来的类继承全部推翻,在重新设计。但是若是采用下面这种方式:

当我们需要在进行其他分类,只需添加该分类在分类同一级上,进行组合继承即可。降低耦合
class Fruit(object):
def __init__(self):
pass class BpFruit(object):
def __init__(self):
pass def BpFunc(self):
pass class XpFruit(object):
def __init__(self):
pass def XpFunc(self):
pass class Apple(XpFruit,Fruit):
def __init__(self):
pass class Banana(BpFruit,Fruit):
def __init__(self):
pass
简单代码实现
九:运算符重载
运算符重载可以实现对象之间的运算。python将运算符和类的内置方法关联起来。每个运算符都会有一个函数
__add__()对应“+” __gt__()对应“>” .....
案例:实现对加号和大于号的重载
class Fruit(object):
def __init__(self,price):
self.price = price def __add__(self, other):
return self.price + other.price def __gt__(self, other):
if self.price > other.price:
return True
else:
return False class Apple(Fruit):
pass class Banana(Fruit):
pass a = Apple()
b = Banana() c = a+b
print(c) # #苹果贵
if a > b:
print("苹果贵")
else:
print("香蕉贵")
案例:实现对运算符<<的重载
import sys class Stream:
def __init__(self,file):
self.file = file def __lshift__(self, other):
self.file.write(str(other))
return self class Fruit(Stream):
def __init__(self,price = ,file = None):
super(Fruit,self).__init__(file)
self.price = price class Apple(Fruit):
pass class Banana(Fruit):
pass a = Apple(,sys.stdout) #
b = Banana(,sys.stdout) #
python---基础知识回顾(三)(面向对象)的更多相关文章
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- python基础知识回顾之列表
在python 中,主要的常用数据类型有列表,元组,字典,集合,字符串.对于这些基础知识,应该要能够足够熟练掌握. 如何创建列表: # 创建一个空列表:定义一个变量,然后在等号右边放一个中括号,就创建 ...
- python基础知识(三)
摘要:主要涉及新数据类型set集合.三元运算.深浅拷贝.函数基础.全局变量与局部变量 一.set --> 无序,不允许重复的集合 不允许重复的列表, 1,创建 s = set() 接收 ...
- python 基础知识-day10(面向对象)
1.面向对象的概念 拥有共同属性的一类进行归类的过程叫做面向对象. 2.注意事项 class定义类的时候,类名的首字母必须大写 3.面向对象案例 1 class Person(object): 2 d ...
- python基础知识回顾之字符串
字符串是python中使用频率很高的一种数据类型,内置方法也是超级多,对于常用的方法,还是要注意掌握的. #author: Administrator #date: 2018/10/20 # pyth ...
- python基础知识回顾之元组
元组与列表的方法基本一样,只不过创建元组是用小括号()把元素括起来,两者的区别在于,元组的元素不可被修改. 元组被称为只读列表,即数据可以被查询,但不能被修改,列表的切片操作适用于元组. 元组写在小括 ...
- python基础知识回顾[1]
1.声明变量 # 声明一个变量name用来存储一个字符串'apollo' name = 'apollo' # 声明一个变量age用来存储一个数字20 age = 20 # 在控制台打印变量name中存 ...
- python基础知识第三篇(列表)
列表 list 类 中提供的方法 li=[1,5,dhud,dd,] 通过list类创建的对象 中括号括起来 逗号分隔每个元素 列表中的元素可以是数字,字符串,也可以是列表,也可以是布尔值 所有的都能 ...
- Python基础知识(三)
Python基础知识(三) 一丶整型 #二进制转成十进制的方法 # 128 64 32 16 8 4 2 1 1 1 1 1 1 1 例如数字5 : 101 #十进制转成二进制的方法 递归除取余数,从 ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
随机推荐
- 对 JavaScript 中的5种主要的数据类型进行值复制
定义一个函数 clone(),可以对 JavaScript 中的5种主要的数据类型(包括 Number.String.Object.Array.Boolean)进行值复制 使用 typeof 判断值得 ...
- Java设计模式-建造者(Builder)模式
目录 由来 使用 1. 定义抽象 Builder 2. 定义具体 Builder类 3. 定义具体 Director类 4. 测试 定义 文字定义 结构图 优点 举例 @ 最近在看Mybatis的源码 ...
- jmeter学习(1)基础支持+安装部署
1. Apache jmeter 是100%的java桌面应用程序 支持的协议有:WEB-HTTP/HTTPS , SOAP, FTP, JDBC, LDAP, MAIL, MongoDB ...
- PAT甲题题解-1042. Shuffling Machine (20)-模拟
博主欢迎转载,但请给出本文链接,我尊重你,你尊重我,谢谢~http://www.cnblogs.com/chenxiwenruo/p/6789205.html特别不喜欢那些随便转载别人的原创文章又不给 ...
- PowerTeam--Alpha阶段个人贡献分及转会人员
PowerTeam--Alpha阶段个人贡献分 我们的团队共有6人,总分300分. 经团队成员通过个人申请以及组内投票的方式,最终的等级评定如下面的等级评定矩阵所示: β1 β2 β3 γ1 γ2 ...
- 《Linux内核设计与实现》第五章读书笔记
第五章 系统调用 5.1与内核通信 1. 系统调用 让应用程序受限的访问硬件设备 提供创建新进程并与已有进程通信的机制 提供申请操作系统其他资源能力是用户空间进程和硬件设备之间的中间层 2. 系统调 ...
- 重温httpsession①
Session—HTTPSession 服务器创建的,Javaweb提供的 与HTTP协议无关是服务器端对象,保存在服务器端.用来会话跟踪. Cookie与服务器创建,与HTTP协议相关,保存在客户端 ...
- Visual Studio的安装应用及单元测试
新建项目—Visual C#—类库 一.Visual Studio的安装 这可能是自己安装软件用的的最长时间的一次 ..刚下载完安装的时候灰常的尴尬,因为2013版本和2015的版本都是不支持在win ...
- ElasticSearch 2 (2) - Setup
ElasticSearch 2.1.1 (2) - Setup Installation Elasticsearch can be started using: $ bin/elasticsearc ...
- php 中的 “!=”和“!==”
!==是指绝对不等于,比如,$a = 2, $b=”2″ 那么,$a!==$b成立,可是$a!=$b不成立: