Hbase到Solr数据同步及Solr分离实战
1. 起因
- 由于历史原因,公司的数据是持久化在HBase中,查询是通过Solr来实现,这这样的设计必然涉及到要把Hbase中的数据实时同步到Solr,但所有的服务都在一个同一个集群及每台机子都安装了很多不同的服务,导致数据经常丢失,Solr分片也经常在Recovering、Down 状态中游离,因此决定把Solr剥离出来,形成单独的集群,给其它服务减压。
2. 要求
- 保证数据不能丢失
- 切换期间业务能正常使用
- 切换失败,可以回归到旧的集群
3. 整体流程设计
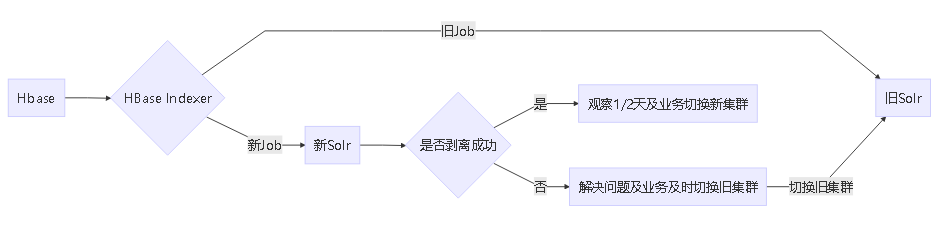
- HBase Indexer 要同时往新旧集群同步数据,保证Hbase中的新加数据及时更新
4. 实施步骤
新集群操作
- 在新Solr集群配置Host如下:
vim /etc/hosts
172.16.213.8 solrmaster s27
172.16.213.12 solrslave1 ss1
172.16.213.13 solrslave2 ss2
172.16.213.9 solrslave3 ss3
172.16.213.10 solrslave4 ss4
172.16.213.14 solrslave5 ss5
172.16.213.11 solrslave6 ss6
- 新建 Collection
./solr create_collection -c collection_coupon -n collection_coupon -shards 6 -replicationFactor 3
-d /opt/lucidworks-hdpsearch/solr/server/solr/configsets/coupon_schema_configs/conf
可以通过scp把旧的配置的配置文件拷贝到新集群,保证配置一致,以免出现莫名的错误。
旧集群操作
- 把新的集群配置到Host文件,千万记住集群中的每台服务器都需要配置,不然在同步的过程中,会出现不能解析的情况。
- 在Hbase Index 的安装服务器上添加新的Index任务,用来同步数据到旧的集群
./hbase-indexer add-indexer -n indexer_coupon_solr -c /opt/lucidworks-hdpsearch/hbase-indexer/demo/coupon_indexer_mapper.xml
-cp solr.zk=solrslave1:2181,solrslave2:2181,solrslave3:2181,solrslave4:2181,solrslave5:2181,solrslave6:2181/solr -cp solr.collection=collection_coupon
这里要注意solr.zk 的设置,一定要设置为新加入solr集群的zk
- 检查新加入的任务是否为启动状态
./hbase-indexer list-indexers remote_indexer_coupon
+ Lifecycle state: ACTIVE
+ Incremental indexing state: SUBSCRIBE_AND_CONSUME
+ Batch indexing state: INACTIVE
+ SEP subscription ID: Indexer_remote_indexer_coupon
+ SEP subscription timestamp: 2018-05-07T18:04:28.434+08:00
+ Connection type: solr
+ Connection params:
+ solr.zk = solrslave1:2181,solrslave2:2181,solrslave3:2181,solrslave4:2181,solrslave5:2181,solrslave6:2181/solr
+ solr.collection = collection_coupon
+ Indexer config:
940 bytes, use -dump to see content
+ Indexer component factory: com.ngdata.hbaseindexer.conf.DefaultIndexerComponentFactory
+ Additional batch index CLI arguments:
(none)
+ Default additional batch index CLI arguments:
(none)
+ Processes
+ 1 running processes
+ 0 failed processes
在Processes中,关键是否有1个任务是否正在运行,如果没有或者失败,检查修复
- 全量同步,由于是新加入的集群,需要第一次做全量同步,然后任务会自动增量同步,执行这个命令需要切换到hdfs用户下。
su hdfs
hadoop jar /opt/lucidworks-hdpsearch/hbase-indexer/tools/hbase-indexer-mr-1.6-SNAPSHOT-job.jar
--conf /opt/lucidworks-hdpsearch/hbase-indexer/conf/hbase-site.xml --hbase-indexer-zk localhost:2181
--hbase-indexer-name indexer_coupon_solr --reducers 0
注意观察日志信息,如果没有错误,继续下面的操作
- 观察增量同步,这个需要测试人员或者实施配合下,看是否新旧集群都能正常同步
5. 在整个测试及实施过程遇到的注意事项
- Hbase Index 只能跟Hbase安装在同一个zk集群下,才能全量、增量同时正常工作
- 新加入的集群主机名要在旧的集群中的每台服务器上添加
- 添加新的任务,只需要-cp solr.zk 命令参数修改成新的zk集群即可,其它配置不需要修改
- 在执行全量同步时--hbase-indexer-zk 只需要设置本机
6. 参考文档
在操作过程中也可以参考我以前的文章
目前采用这样组合并不多,在整个剥离过程中遇到的问题能查到的资料并不多,所以决定记录下来,目前新的集群已经正式替换旧的集群,给其它业务减压,同时新的集群功能更单纯,更好扩展。欢迎有这方面的问题的同行一起交流。
我的QQ群(码农之家):53135235
Hbase到Solr数据同步及Solr分离实战的更多相关文章
- 5.hbase表新增数据同步之add_peer
一.前提主从集群之间能互相通讯: 二.在cluster1上(源集群): 1.查看集群已开启的peers hbase(main):011:0> list_peers PEER_ID CLUSTE ...
- 【Canal】互联网背景下有哪些数据同步需求和解决方案?看完我知道了!!
写在前面 在当今互联网行业,尤其是现在分布式.微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis.Memcached等NoSQL数据库,也会使用大量的Solr.Elastics ...
- 【Canal】数据同步的终极解决方案,阿里巴巴开源的Canal框架当之无愧!!
写在前面 在当今互联网行业,尤其是现在分布式.微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis.Memcached等NoSQL数据库,也会使用大量的Solr.Elastics ...
- solr 简单搭建 数据库数据同步(待续)
原来在别的公司负责过文档检索模块的维护(意思就是不是俺开发的啦). 所以就略微接触和研究了下文档检索. 文档检索事实上是全文检索.是通过一种技术把N多文档进行一定规律的分割归类,然后创建易于搜索的索引 ...
- Solr数据不同步
Solr配置了集群,本地有253和254,2个独立的Solr服务. 同一个页面的图片,刷新2次,图片地址不一样,最后查明,后台数据源Solr1和Solr2的数据不一致. 第1步推测:本地缓存, ...
- 用solr DIH 实现mysql 数据定时,增量同步到solr
基础环境: (二)设置增量导入为定时执行的任务: 很多人利用Windows计划任务,或者Linux的Cron来定期访问增量导入的连接来完成定时增量导入的功能,这其实也是可以的,而且应该没什么问题. 但 ...
- HBase数据同步ElasticSearch该程序
ElasticSearch的River机械 ElasticSearch本身就提供了River机械,对于同步数据. 在这里,现在能找到的官方推荐River: http://www.elasticsear ...
- HBase数据同步到ElasticSearch的方案
ElasticSearch的River机制 ElasticSearch自身提供了一个River机制,用于同步数据. 这里能够找到官方眼下推荐的River: http://www.elasticsear ...
- Solr系列四:Solr(solrj 、索引API 、 结构化数据导入)
一.SolrJ介绍 1. SolrJ是什么? Solr提供的用于JAVA应用中访问solr服务API的客户端jar.在我们的应用中引入solrj: <dependency> <gro ...
随机推荐
- odoo按钮图标 icon
https://www.slideshare.net/TaiebKristou/odoo-icon-smart-buttons http://www.iconfont.cn/collections/d ...
- 【原创】SQL Server 性能调优读书笔记
CPU 100%: 有时可能是硬盘性能不足,或者内存容量不够,让CPU一直忙于I/O. 导致性能问题的一些因素: 用户习惯:在运行尖峰时刻做一些不必做但消耗资源的事情,如之行数据库完整备份,如在服务器 ...
- Zookeeper配置文件中的配置项解释和Zookeeper的安装
zookeeper的默认配置文件为zookeeper/conf/zoo_sample.cfg,需要将其修改为zoo.cfg.其中各配置项的含义,解释如下: 1.tickTime:CS通信心跳时间Zoo ...
- 无监督学习——K-均值聚类算法对未标注数据分组
无监督学习 和监督学习不同的是,在无监督学习中数据并没有标签(分类).无监督学习需要通过算法找到这些数据内在的规律,将他们分类.(如下图中的数据,并没有标签,大概可以看出数据集可以分为三类,它就是一个 ...
- 打印页面时a标签不显示URL的方法
以前写博客啊,总想写一篇大作,然后希望能挂到博客园首页,隔一会儿看看阅读量有多少.其实哪有那么多大作,大部分时间都是解决了一个小问题,然后需要记录一下.比如下面这篇. 今天遇到一个需求是,打印网页时, ...
- Hibernate的集合一对多与多对一
需求: 部门与员工 一个部门有多个员工; [一对多] 多个员工,属于一个部门 [多对一] 1.javaBean ——Dept.java package com.gqx.oneto ...
- 通过http URL 获取图片流 转为字节数组
通过http URL 获取图片流 转为字节数组 读取本地文件转为数组 /** * 获取 文件 流 * @param url * @return * @throws IOException */ pri ...
- Visual Studio自带的的Developer Command Prompt对话框
简单了解Visual Studio的Developer Command Prompt VS2008的命令为:Visual Studio 2008 Command Prompt 目录是: 其详细信息如下 ...
- 并发编程之 SynchronousQueue 核心源码分析
前言 SynchronousQueue 是一个普通用户不怎么常用的队列,通常在创建无界线程池(Executors.newCachedThreadPool())的时候使用,也就是那个非常危险的线程池 ^ ...
- 用python写web一定要去破解的异步请求问题.经历web.py和tornado,完破!
1.问题 上个学期,给学校写了一个数据服务,主要从oracle里面读取一些数据供查询使用,非常快速的用web.py搭建了起来.调试顺利,测试正常,上线!接下来就是挨骂了,我铁定知道会卡,但是没想到会那 ...