Linux——线程
线程
我们都知道一个程序的执行是由进程来完成的,而进程里真正执行代码却是由线程来完成,它是真正的执行流。通常将一个程序⾥里一个执行路线就叫做线程(thread)。对它更准确的定义是:线程是“一个进程内部的控制序列” 。而一切进程都至少有一个执行线程。
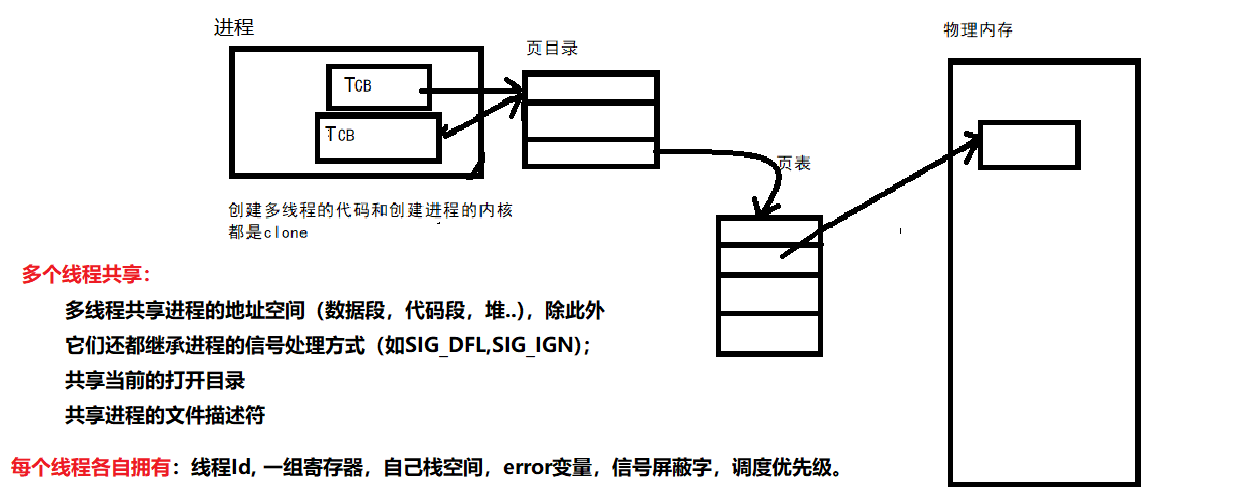
进程与线程关系:
①进程是资源竞争的基本单位
②线程是程序执行的最小单位
线程优点:
·线程占用的资源要比进程少很多,创建一个新线程的代价要比创建一个新进程小得多(线程不用去开虚拟地址空间)
·与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
·能充分利用多处理器的可并行数量
·在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
·计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
·I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程缺点
1.性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较⼤大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
2.健壮性降低
编写多线程需要更全⾯面更深入的考虑,在一个多线程程序⾥里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
3.缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些系统函数会对整个进程造成影响。
4.编程难度提⾼高
编写与调试一个多线程程序比单线程程序困难得多
返回值
所有pthreads处理函数出错时不会设置全局变量errno(而大部分其他POSIX函数会这样做)。
而是将错误代码通过返回值返回 其实pthreads同样也提供了线程内的errno变量,以支持其它使用errno的代码。
但对于pthreads函数的错误,建议通过返回值业判定,因为读取返回值要比读取线程内的errno变量的开销更小
相关函数
(1)线程标识
线程ID和进程ID一样,不过进程ID在整个系统中是唯一的,但线程ID不同,它只有在它所属的进程上下文中才有意义。线程ID用pthread_t数据类型表示,该类型实现是用一个结构来代表的,可移植的系统中不能把它想pid_t类型一样当整数处理。所以通常会用一个函数来对两个线程ID进行比较
int pthread_equal(pthread_t tid1, pthread_t tid2)
同时,线程可以通过pthread_self获取自身的线程ID
pthread_t pthread_self(void);
但值得注意的是:没有线程之前,一个进程对应内核里的一个进程描述符,对应一个进程ID。但是引入线程概念之后,情况发⽣生了变化,一个用户进程下管辖N个用户态线程,每个线程作为一个独立的调度实体在内核态都有自己的进程描述符,进程和内核的描述符一下子就变成了1:N关系,POSIX标准又要求进程内的所有线程调用getpid函数时返回相同的进程ID
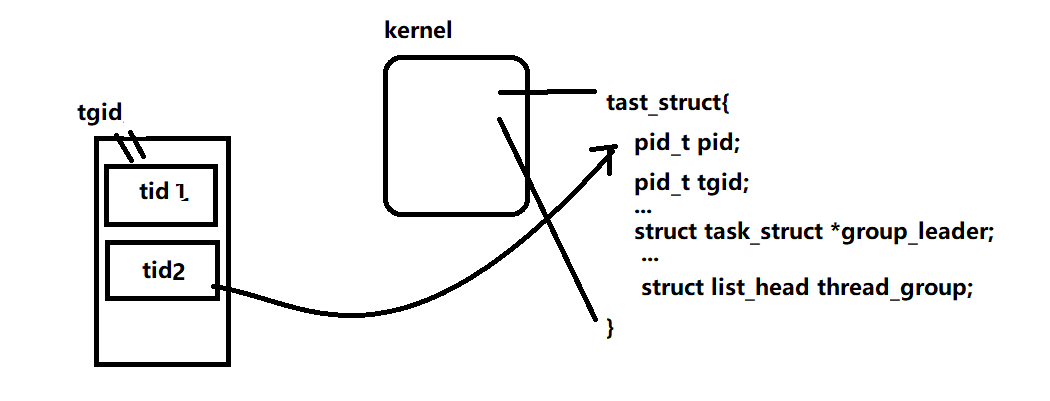
多线程的进程,又被称为线程组,线程组内的每一个线程在内核之中都存在一个进程描述符结构(task_struct)与之对应。进程描述符结构体中的pid,表面上看对应的是进程ID,其实不然,它对应的是线程ID;进程描述符中的tgid,含义是Thread Group ID,它才对应的是用户层面的进程ID
Linux提供了gettid系统调用来返回其线程ID,可是glibc并没有将该系统调用封装起来,在开放接口来供程序员使用。如果确实需要获得线程ID,可以采用如下一个系统调用函数获得:
#include <sys/syscall.h>
pid_t tid;
tid = syscall(SYS_gettid);
例子
#include <stdio.h>
#include <sys/syscall.h>
#include <pthread.h>
#include <unistd.h> void *route( void *arg)
{
pid_t tid = syscall(SYS_gettid);
while ( 1 ) {
printf("tid = %d, pid=%d\n", tid, syscall(SYS_getpid));
sleep(1);
}
} int main( void )
{
pthread_t myid;
pthread_create(&myid, NULL, route, NULL);
pid_t tid = syscall(SYS_gettid);
pid_t pid = syscall(SYS_getpid);
while ( 1 )
{
printf("tid = %d, pid=%d\n", tid, pid);
sleep(1);
}
}
结果不难验证出来

注:ps命令中的-L选项,会显示如下信息:
LWP:线程ID,既gettid()系统调用的返回值。
NLWP:线程组内线程的个数
还有pthread_t是什么类型取决于实现。对于Linux目前实现的NPTL实现而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。
前面说了传统的进程模型,每个进程只有一个控制线程。在POSIX线程情况下:在创建多线程之前,程序也是以单进程中的单个控制线程启动的。所以程序的行为于传统的进程没什么区别。而要新增线程可通过pthread_create创建。
(2)创建线程 pthread_create函数
原型:int pthread_create(pthread_t *thread, //线程标识符
const pthread_attr_t *attr, // 线程属性 通常填NULL
void *(*start_routline) (void *), // 线程回调函数
void *arg); // 回调函数的参数 NULL
创建成功线程ID会被设置成thread指向的内存单元。新创建的线程从start_routline地址开始执行,该函数有一个无类型的指针参数arg,如果需要向start_routeline函数传递一个以上的参数,那么需要吧这些参数放到一个结构中,然后吧这个结构的地址传入。
例子:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h> void *myroute(void *arg)
{
printf("this is thread one\n");
printf("pid:%d thread one:%lx\n", getpid(), pthread_self());
} int main( void )
{
pthread_t tid;
if(pthread_create(&tid, NULL, myroute, NULL) != 0)
perror(" can`t create thread"),exit( 1);
printf("pid:%d main thread:%lx\n",getpid(), pthread_self());
sleep(1);
printf("return\n");
}

改造一下
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h> void *myroute(void *arg)
{
while( 1)
{
printf("this is thread one\n");
printf("pid:%d thread one:%lx\n", getpid(), pthread_self());
}
} int main( void )
{
pthread_t tid;
if(pthread_create(&tid, NULL, myroute, NULL) != 0)
perror(" can`t create thread"),exit( 1);
while(1)
{
printf("pid:%d main thread:%lx\n",getpid(), pthread_self());
sleep(1);
}
printf("return\n");
}
注:而对于第二个参数attr用于定制各种不同的线程属性,通常会将它置空 使线程拥有默认的属性,如果需要对线程属性进行设置,会用到下面两函数
#include <pthread.h>
//初始化线程属性
int pthread_attr_init(pthread_attr_t *attr);
//销毁线程属性
int pthread_attr_destroy(pthread_attr_t *attr);
它的属性有
Thread attributes:
分离属性: Detach state = PTHREAD_CREATE_JOINABLE
抢夺资源范围: Scope = PTHREAD_SCOPE_SYSTEM
是否继承调度策略: Inherit scheduler = PTHREAD_INHERIT_SCHED
调度策略() Scheduling policy = SCHED_OTHER //分时调度策略就是SCHED_OTHER
调度优先级: Scheduling priority = 0
线程栈之间的保留区: Guard size = 4096 bytes //主要用来保证线程安全
自己指定的线程栈地址:Stack address = 0x40196000
自己指定线程栈栈大小:Stack size = 0x201000 bytes
对于其中的分离属性:
用到下面这两个函数。它们分别是设置分离状态和获取分离状态
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
例子
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h> pthread_attr_t attr; void *route( void *arg )
{
printf("route1\n");
} int main( void )
{
pthread_t tid;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
pthread_create(&tid, &attr, route, NULL); int ret;
pthread_attr_getdetachstate(&attr, &ret);
if ( ret == PTHREAD_CREATE_DETACHED ) {
printf("PTHREAD_CREATE_DETACHED\n");
} else if (ret == PTHREAD_CREATE_JOINABLE ) {
printf("PTHREAD_CREATE_JOINABLE\n");
} pthread_attr_destroy(&attr);
}
结果:
tp@tp:~/day19$ ./a.out
PTHREAD_CREATE_DETACHED
(3)线程的退出pthread_exit函数
#include <pthread.h> void pthread_exit(void *retval);
retval参数是一个无类型指针,和传给启动例程的单个参数类似,注意不要让它指向一个局部变量。进程中的其他线程可以通过调用pthread_join函数访问到这个指针,获取该线程的终止状态。
(4)取消执行中线程pthread_cancle函数
原型
int pthread_cancel(pthread_t thread);
参数
thread:线程ID
返回值:成功返回0;失败返回错误码
总结关于 线程死亡条件:
1 线程处理函数返回时;
2.pthread_exit被调用 (进程中所有线程都死亡后,进程才死亡)
3. 线程被其他线程调用了pthread_cancel函数取消。(但值得注意的是:cancel的线程不是立马退出,而是要等到系统调用到了cancel点。可以调用 pthread_testcancel(void)函数来 人为加上一个cancel)
线程等待和分离
(5)线程等待函数 pthread_join
之所以需要线程等待函数是由于①已经退出的线程,其空间没有被释放,仍然在进程的地址空间内。②创建新的线程不会复⽤用刚才退出线程的地址空间。
#include <pthread.h> int pthread_join(pthread_t thread, void **value_ptr); 注意这里retval是一个二级指针,因为在执行等待线程死亡过程中需要修改。函数直到pid线程死亡才返回,成功返回0,失败返回错误码。
此时调用线程一直阻塞,直到指定的线程thread调用pthread_exit、从启动历程中返回或者被取消。thread线程以不同的⽅方法终止,pthread_join得
到的终止状态是不同的:
1. 如果thread线程通过return返回,*value_ ptr所指向的单元里存放的是thread线程函数的返回值。
2. 如果thread线程被别的线程调用pthread_ cancel异常终掉,*value_ ptr所指向的单元里存放的是常数PTHREAD_ CANCELED。
3. 如果thread线程是⾃自己调用pthread_exit 终止的 ,*valueptr所指向的单元存放的是传给pthread_exit的参数。
4. 如果对thread线程的终止状态不感兴趣,可以传NULL给value_ ptr参数。
若对线程的返回值并不感兴趣,可把valude_ptr设置为NULL(一般会置空)。此种情况下,调用pthread_join函数可以等待指定的线程终止,但不获取线程的种止状态。
(6)线程分离函数
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源
int pthread_detach(pthread_t thread);
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离:
pthread_detach(pthread_self());
joinable和分离是冲突的,一个 线程不能既是joinable又是分离的。
例子:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
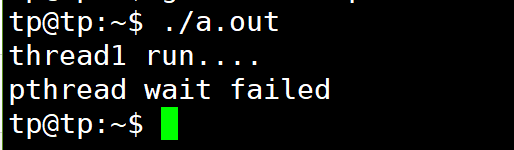
#include <pthread.h> void *thread_run( void* arg)
{
pthread_detach( pthread_self());
printf( "%s\n" , (char*) arg);
return NULL;
}
int main( void )
{
pthread_t tid;
char str[] = "thread1 run....";
if (pthread_create(&tid, NULL, thread_run, str) != 0) {
printf( " create thread error\n" ) ;
return 1;
}
int ret = 0;
sleep( 1) ;
if (pthread_join( tid, NULL ) == 0 ) {
printf( "pthread wait success\n" ) ;
ret = 0;
} else {
printf( "pthread wait failed\n" ) ;
ret = 1;
}
return ret;
}
Linux——线程的更多相关文章
- [转载]Linux 线程实现机制分析
本文转自http://www.ibm.com/developerworks/cn/linux/kernel/l-thread/ 支持原创.尊重原创,分享知识! 自从多线程编程的概念出现在 Linux ...
- linux线程的实现
首先从OS设计原理上阐明三种线程:内核线程.轻量级进程.用户线程 内核线程 内核线程就是内核的分身,一个分身可以处理一件特定事情.这在处理异步事件如异步IO时特别有用.内核线程的使用是廉价的,唯一使用 ...
- linux线程的实现【转】
转自:http://www.cnblogs.com/zhaoyl/p/3620204.html 首先从OS设计原理上阐明三种线程:内核线程.轻量级进程.用户线程 内核线程 内核线程就是内核的分身,一个 ...
- Linux线程-创建
Linux的线程实现是在内核以外来实现的,内核本身并不提供线程创建.但是内核为提供线程[也就是轻量级进程]提供了两个系统调用__clone()和fork (),这两个系统调用都为准备一些参数,最终都用 ...
- Linux线程学习(一)
一.Linux进程与线程概述 进程与线程 为什么对于大多数合作性任务,多线程比多个独立的进程更优越呢?这是因为,线程共享相同的内存空间.不同的线程可以存取内存中的同一个变量.所以,程序中的所有线程都可 ...
- Linux线程学习(二)
线程基础 进程 系统中程序执行和资源分配的基本单位 每个进程有自己的数据段.代码段和堆栈段 在进行切换时需要有比较复杂的上下文切换 线程 减少处理机的空转时间,支持多处理器以及减少上下文切换开销, ...
- Linux 线程(进程)数限制分析
1.问题来源公司线上环境出现MQ不能接受消息的异常,运维和开发人员临时切换另一台服务器的MQ后恢复.同时运维人员反馈在出现问题的服务器上很多基本的命令都不能运行,出现如下错误:2. 初步原因分析和 ...
- Linux 线程与进程,以及通信
http://blog.chinaunix.net/uid-25324849-id-3110075.html 部分转自:http://blog.chinaunix.net/uid-20620288-i ...
- linux 线程的内核栈是独立的还是共享父进程的?
需要考证 考证结果: 其内核栈是独立的 206 static struct task_struct *dup_task_struct(struct task_struct *orig) 207 { 2 ...
- Linux 线程模型的比较:LinuxThreads 和 NPTL
Linux 线程模型的比较:LinuxThreads 和 NPTL GNU_LIBPTHREAD_VERSION 宏 大部分现代 Linux 发行版都预装了 LinuxThreads 和 NPTL,因 ...
随机推荐
- Linux遇到的问题(一)Ubuntu报“xxx is not in the sudoers file.This incident will be reported” 错误解决方法
提示错误信息 www@iZ236j3sofdZ:~$ ifconfig Command 'ifconfig' is available in '/sbin/ifconfig' The command ...
- 流媒体服务器之————EasyDarwin开源流媒体服务器:编译、配置、部署
源码下载地址:https://github.com/EasyDarwin/EasyDarwin/archive/v7.0.5.zip 查看 Ubuntu 的版本号 sudo lsb_release - ...
- Flex 编写 loading 组件
Flex 界面初始化有时那个标准的进度条无法显示,界面长时间会处理空白的状态!我们来自定义一个进度条, 这个进度条加载在 Application 应用程序界面的 <s:Application 标 ...
- 在Emacs中启用Fcitx输入法
安装fcitx输入法,在 ~/.xinitrc文件中添加如下内容 (我用startx启动图形环境,所以在~/.xinitrc中配置X会话) export LC_CTYPE="zh_CN.UT ...
- # 20155337 2016-2017-2 《Java程序设计》第六周学习总结
20155337 2016-2017-2 <Java程序设计>第六周学习总结 教材学习内容总结 •串流(Stream): 数据有来源及目的地,衔接两者的是串流对象.如果要将数据从来源取出, ...
- Android改进版CoverFlow效果控件
最近研究了一下如何在Android上实现CoverFlow效果的控件,其实早在2010年,就有Neil Davies开发并开源出了这个控件,Neil大神的这篇博客地址http://www.inter- ...
- shell脚本常用参数
shell 脚本 常用参数 #!/bin/sh # 在脚本第一行脚本头 # sh为当前系统默认shell,可指定为bash等shell sh -x # 执行过程 sh -n # 检查语法 (a=bbk ...
- spring的普通类中获取session和request对像
在使用spring时,经常需要在普通类中获取session,request等对像. 1.第一钟方式,针对Spring和Struts2集成的项目: 在有使用struts2时,因为struts2有一个接口 ...
- CRT/LCD/VGA Information and Timing【转】
转自:http://www.cnblogs.com/shangdawei/p/4760933.html 彩色阴极射线管的剖面图: 1. 电子QIANG Three Electron guns (for ...
- 关于内核中spinlock的一些个人理解 【转】
由于2.6内核可以抢占,应该在驱动程序中使用 preempt_disable() 和 preempt_enable(),从而保护代码段不被抢占(禁止 IRQ 同时也就隐式地禁止了抢占).preempt ...