【MySQL】覆盖索引和回表
- 先来了解一下两大类索引
- 聚簇索引(也称聚集索引,主键索引等)
- 普通索引(也成非聚簇索引,二级索引等)
- 聚簇索引
- 如果表设置了主键,则主键就是聚簇索引
- 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
- 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
InnoDB的聚簇索引的叶子节点存储的是行记录(其实是页结构,一个页包含多行数据),InnoDB必须要有至少一个聚簇索引。
由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录。
- 普通索引
普通索引也叫二级索引,除聚簇索引外的索引,即非聚簇索引。
InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
请看如下示例:
- 建表
CREATE TABLE IF NOT EXISTS `user`(
-> `id` INT UNSIGNED AUTO_INCREMENT,
-> `name` VARCHAR(),
-> `age` TINYINT(),
-> PRIMARY KEY (id),
-> INDEX idx_age (age)
-> )ENGINE=innodb charset=utf8mb4;
# id 字段是聚簇索引,age 字段是普通索引(二级索引)
- 随便加几个数据
insert into user(name,age) values('张三',);
insert into user(name,age) values('李四',);
insert into user(name,age) values('王五',);
insert into user(name,age) values('刘八',);
mysql> select * from user;
+----+------+-----+
| id | name | age |
+----+------+-----+
| | 张三 | |
| | 李四 | |
| | 王五 | |
| | 刘八 | |
+----+------+-----+
rows in set (0.06 sec)
- 索引存储结构
id 是主键,所以是聚簇索引,其叶子节点存储的是对应行记录的数据

age 是普通索引(二级索引),非聚簇索引,其叶子节点存储的是聚簇索引的的值
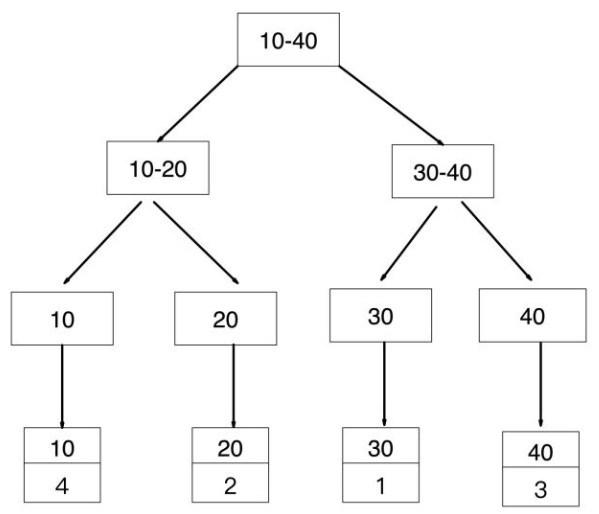
如果查询条件为主键(聚簇索引),则只需扫描一次B+树即可通过聚簇索引定位到要查找的行记录数据。
如:select * from user where id = ;
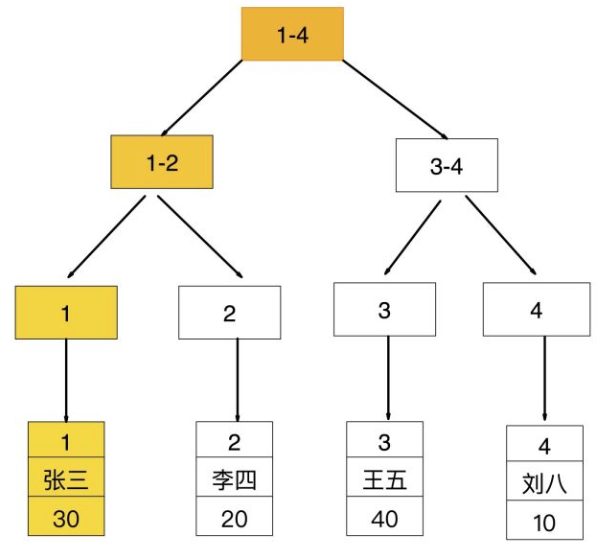
如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据。
如:select * from user where age = ;
1》先通过普通索引【age=30】定位到主键值 【id=1】
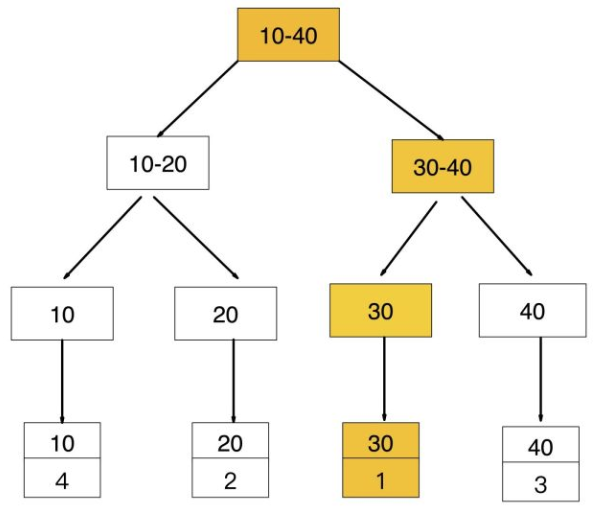
2》在通过聚集索引【id=1】定位到行记录数据
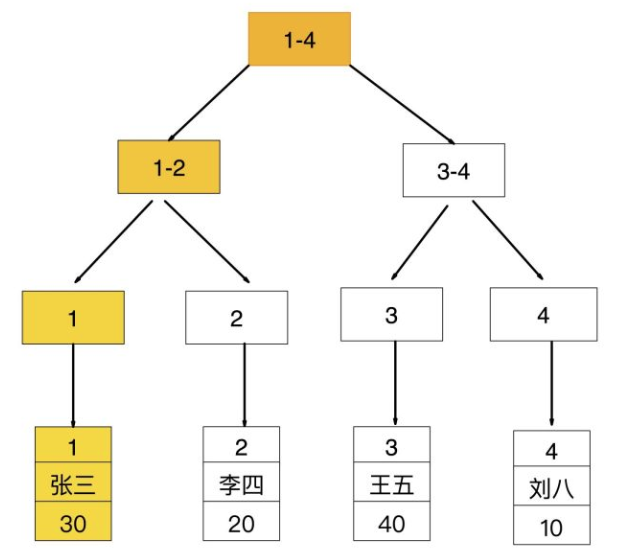
- 回表查询
先通过普通索引的值定位到聚簇索引值,在通过聚簇索引的值定位到行记录数据,要通过扫描两次索引B+树,它的性能较扫描一次较低
- 索引覆盖
只需在一颗索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
例如:select id,age from user where age = ;
- 如何实现覆盖索引
常见的方法是:将被查询的字段,建立到联合索引里去(若查询有where条件,同时where条件字段也必须为索引字段)。
1》如实现:select id,age from user where age = 10;
explain分析:因为age是普通索引,使用到了age索引,通过一次扫描B+树即可查询到相应的结果,这样就实现了覆盖索引
此时的Extra列的【Using Index】表示进行了聚簇索引
mysql> explain select id,age from user where age = ;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
| | SIMPLE | user | NULL | ref | idx_age | idx_age | | const | | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+
row in set (0.07 sec)
2》如实现:select id,age,name from user where age = 10;
explain分析:age是普通索引,但name列不在索引树上,所以通过age索引在查询到id和age的值后,需要进行回表再查询name的值。
此时的Extra列的NULL表示进行了回表查询
mysql> explain select id,age,name from user where age = ;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| | SIMPLE | user | NULL | ref | idx_age | idx_age | | const | | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
row in set (0.05 sec)
explain 使用方式如下:
EXPLAIN +SQL语句
如:EXPLAIN SELECT * FROM t1
- 为了实现索引覆盖,需要建组合索引idx_age_name(age,name)
mysql> drop index idx_age on user;
mysql> create index idx_age_name on user(`age`,`name`);
我们再次EXPLAIN分析一次:
mysql> explain select id,age,name from user where age = ;
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------------+
| | SIMPLE | user | NULL | ref | idx_age_name | idx_age_name | | const | | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------------+
row in set (0.05 sec) #可见Extra的值为【Using Index】,表示使用的覆盖索引
哪些场景适合使用索引覆盖来优化SQL:
- 全表count查询优化
mysql> explain select count(age) from user;
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| | SIMPLE | user | NULL | index | NULL | idx_age_name | | NULL | | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
row in set (0.06 sec)
- 分页查询
mysql> explain select id,age,name from user order by age limit ,;
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
| | SIMPLE | user | NULL | index | NULL | idx_age_name | | NULL | | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-------------+
row in set (0.06 sec)
【MySQL】覆盖索引和回表的更多相关文章
- mysql覆盖索引与回表
mysql覆盖索引与回表 Harri2012关注 62019.07.28 11:14:15字数 1,292阅读 77,322 select id,name where name='shenjian' ...
- mysql:如何利用覆盖索引避免回表优化查询
说到覆盖索引之前,先要了解它的数据结构:B+树. 先建个表演示(为了简单,id按顺序建): id name 1 aa 3 kl 5 op 8 aa 10 kk 11 kl 14 jk 16 ml 17 ...
- 一篇文章讲清楚MySQL的聚簇/联合/覆盖索引、回表、索引下推
迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子. 手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:"加班使我快乐". 面试官: ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- MySQL 覆盖索引
通常大家都会根据查询的WHERE 条件来穿件合适的索引,不过这只是索引优化的一个方面.设计优秀的索引应该考虑到整个查询,而不单单是WHERE 条件部分.索引确实是一种查找数据的高效方式,但是MySQL ...
- mysql覆盖索引详解
覆盖索引的定义: 如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’.即只需扫描索引而无须回表. 只扫描索引而无需回表的优点: 1.索引条目通常远小于数据行大小,只需要读取索引, ...
- Mysql覆盖索引与延迟关联
延迟关联:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据. 为什innodb的索引叶子节点存的是主键,而不是像myisam一样存数据的物理地址指针? 如果存的是物理地址指针不 ...
- MySQL 优化之 MRR (Multi-Range Read:二级索引合并回表)
MySQL5.6中引入了MRR,专门来优化:二级索引的范围扫描并且需要回表的情况.它的原理是,将多个需要回表的二级索引根据主键进行排序,然后一起回表,将原来的回表时进行的随机IO,转变成顺序IO.文档 ...
- mysql覆盖索引(屌的狠,提高速度)
话说有这么一个表: CREATE TABLE `user_group` ( `id` int(11) NOT NULL auto_increment, `uid` int(11) NOT NULL, ...
随机推荐
- Clustered和Nonclustered Indexes 各自得特点和区别及长短处
1 簇索引 簇索引对表的物理数据页中的数据按列进行排序然后再重新存储到磁盘上即簇索 引与数据是混为一体的它的叶节点中存储的是实际的数据由于簇索引对表中的数据一 一进行了排序因此用簇索引查找数据很快但由 ...
- 听说你在从事前端开发?那这10个JavaScript的优化问题你不得不知道!
JavaScript的高效优化一直都是我们前端开发中非常重要的工作,也是很多开发人员无法做好的一部分内容,今天我总结了10个优化问题,大家可以参考来做优化,这其中很多问题都是大家经常遇到的哦. ==和 ...
- THU OS
前言 最近在学清华的OS课程,实验课做的真厉害. 我们的操作系统课就是写一个系统调用,改下进程软中断通信的代码,代码量不足500...清华是借鉴MIT的课,实验课都是做一个完整的小型操作系统. 一共8 ...
- C++ 模板(template) 的定义
定义: 模板(template)是实现代码重用机制的一种工具,它可以实现类型参数化,把类型定义为参数(模板元编程),从而实现了真正的代码可重用性. 模板是用来批量生成功能和形式都几乎相同的代码的.编译 ...
- 从0开始搭建精灵宝可梦的检测APP
从0开始搭建精灵宝可梦的检测APP 本文为本人原创,转载请注明来源链接 环境要求 Tensorflow1.12.0 cuda 9.0 python3.6.10 Android Studio Anaco ...
- Linux安装Git-两种方式详细教程)
一.Git介绍 Git --- The stupid content tracker, 傻瓜内容跟踪器.Linus Torvalds 是这样给我们介绍 Git 的. Git 是用于 Linux内核开发 ...
- 麦基数(p1045)
描述: \(计算2^{P}−1的位数和最后500位数字(用十进制高精度数表示)\) Ⅰ.求位数 \(因为2^p最后一位必定不为0,求2^p-1的位数也就是求2^p位数\) \(2^p的位数确实很难求, ...
- Bootstrap初识
目录 概述 快速入门 响应式布局 CSS样式和JS插件 全局CSS样式 组件 插件 案例:黑马旅游网 概述 概念:一个前端开发的框架,Bootstrap是美国Twitter公司的设计师Mark Ott ...
- Spring官网阅读(七)容器的扩展点(二)FactoryBean
在上篇文章中我们已经对容器的第一个扩展点(BeanFactoryPostProcessor)做了一系列的介绍.其中主要介绍了Spring容器中BeanFactoryPostProcessor的执行流程 ...
- Spring源码阅读 之 bean的注册
在前面我们已经学习了配置的加载,读取,解析.现在我们已经能够将一份配置转变成对应的一个个beandefinition了,我们知道Spring是一个IOC的容器,那么我们如何将这个一个个beandefi ...