从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们介绍了Hive的表操作做了简单的描述和实践。在实际使用中,可能会存在数据的导入导出,虽然可以使用sqoop等工具进行关系型数据导入导出操作,但有的时候只需要很简便的方式进行导入导出即可
下面我们开始介绍hive的数据导入,导出,以及集群的数据迁移进行描述。
导入文件到Hive
一:语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]二:从本地导入
使用"LOCAL"就可以从本地导入
三:从集群导入
将语法中"LOCAL"去掉即可。
四:OVERWRITE
使用该参数,如果被导入的地方存在了相同的分区或者文件,则删除并替换,否者直接跳过。
五:实战
根据上篇我们建立的带分区的score的例子,我们先构造两个个文本文件score_7和score_8分别代表7月和8月的成绩,文件会在后面附件提供下载。
由于建表的时候没有指定分隔符,所以这两个文本文件的分隔符。
先将文件放入到linux主机中,/data/tmp路径下。
导入本地数据
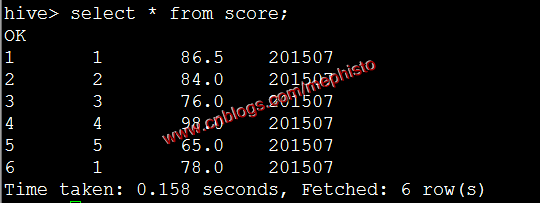
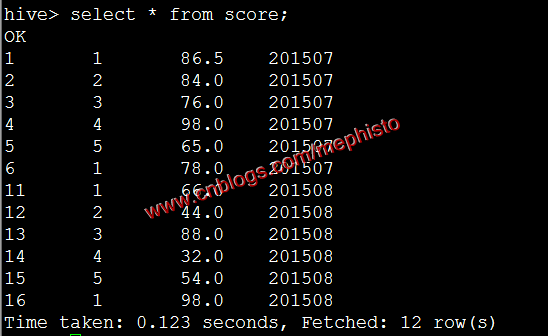
load data local inpath '/data/tmp/score_7.txt' overwrite into table score PARTITION (openingtime=201507);
我们发现001变成了1这是以为表的那一类为int形,所以转成int了。
将score_8.txt 放到集群中
su hdfs
hadoop fs -put score_8.txt /tmp/input导入集群数据
load data inpath '/tmp/input/score_8.txt' overwrite into table score partition(openingtime=201508);

将其他表的查询结果导入表
一:语法
Standard syntax: INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement; Hive extension (multiple inserts): FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...; FROM from_statement INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] ...; Hive extension (dynamic partition inserts): INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement; INSERT INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement;二:OVERWRITE
使用该参数,如果被导入的表或者分区中有相同的内容,则该内容被替换,否者直接跳过。
三:INSERT INTO
该语法从0.80才开始支持,它会保持目标表,分区的原有的数据的完整性。
四:实战
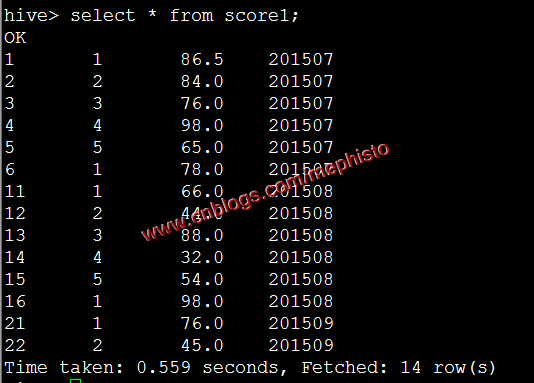
我们构造一个和score表结构一样的表score1
create table score1 ( id int, studentid int, score double ) partitioned by (openingtime string);插入数据
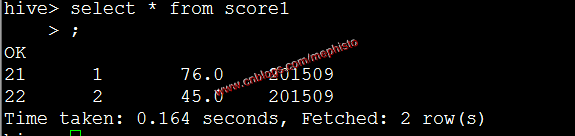
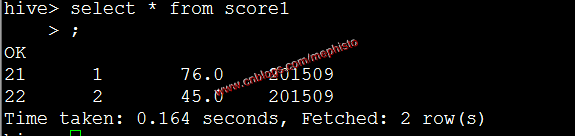
insert into table score1 partition (openingtime=201509) values (21,1,''),(22,2,'');
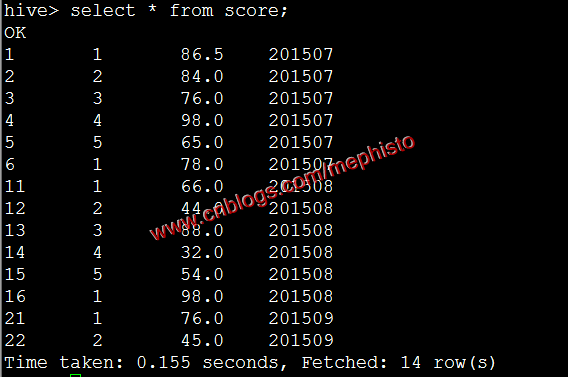
我们将表score1的查询结果导入到score中,这里指定了201509分区。
insert overwrite table score partition (openingtime=201509) select id,studentid,score from score1;
动态分区插入
一:说明
本来动态分区插入属于将其他表结果插入的内容,但是这个功能实用性很强,特将其单独列出来阐述。该功能从Hive 0.6开始支持。
二:参数
动态分区参数会在该命令生命周期内有效,所以一般讲修改的参数命令放在导入之前执行。
Property Default Note hive.error.on.empty.partition false Whether to throw an exception if dynamic partition insert generates empty results hive.exec.dynamic.partition false Needs to be set to trueto enable dynamic partition insertshive.exec.dynamic.partition.mode strict In strictmode, the user must specify at least one static partition in case the user accidentally overwrites all partitions, innonstrictmode all partitions are allowed to be dynamichive.exec.max.created.files 100000 Maximum number of HDFS files created by all mappers/reducers in a MapReduce job hive.exec.max.dynamic.partitions 1000 Maximum number of dynamic partitions allowed to be created in total hive.exec.max.dynamic.partitions.pernode 100 Maximum number of dynamic partitions allowed to be created in each mapper/reducer node 三:官网例子
我们可以下看hive官网的例子
FROM page_view_stg pvs
INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country)
SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip, pvs.cnt在这里country分区将会根据pva.cut的值,被动态的创建。注意,这个分区的名字是没有被使用过的,在
nonstrict模式,dt这个分区也可以被动态创建。四:实战
我们先清空score表的数据(3个分区)
insert overwrite table score partition(openingtime=201507,openingtime=201508,openingtime=201509) select id,studentid,score from score where 1==0;
将7月8月数据插入到score1
load data local inpath '/data/tmp/score_7.txt' overwrite into table score1 partition(openingtime=201507);
load data local inpath '/data/tmp/score_8.txt' overwrite into table score1 partition(openingtime=201508);
设置自动分区等参数
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
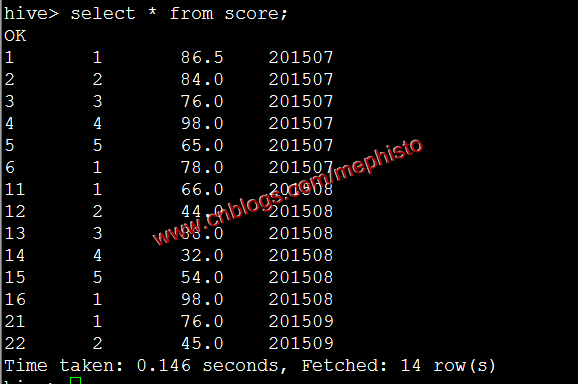
set hive.exec.max.dynamic.partitions.pernode=;将score1的数据自动分区的导入到score
insert overwrite table score partition(openingtime) select id,studentid,score,openingtime from score1;图片

将SQL语句的值插入到表中
一:说明
该语句可以直接将值插入到表中。
二:语法
Standard Syntax:
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...] Where values_row is:
( value [, value ...] )
where a value is either null or any valid SQL literal三:官网例子
CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2))
CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC; INSERT INTO TABLE students
VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32); CREATE TABLE pageviews (userid VARCHAR(64), link STRING, came_from STRING)
PARTITIONED BY (datestamp STRING) CLUSTERED BY (userid) INTO 256 BUCKETS STORED AS ORC; INSERT INTO TABLE pageviews PARTITION (datestamp = '2014-09-23')
VALUES ('jsmith', 'mail.com', 'sports.com'), ('jdoe', 'mail.com', null); INSERT INTO TABLE pageviews PARTITION (datestamp)
VALUES ('tjohnson', 'sports.com', 'finance.com', '2014-09-23'), ('tlee', 'finance.com', null, '2014-09-21');四:实战
在将其他表数据导入到表中的例子中,我们新建了表score1,并且通过SQL语句将数据插入到score1中。这里就只是将上面的步骤重新列举下。
插入数据
insert into table score1 partition (openingtime=201509) values (21,1,''),(22,2,'');
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。
模拟数据文件下载
Github https://github.com/sinodzh/HadoopExample/tree/master/2016/hive%20test%20file
系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上的更多相关文章
- sqoop将oracle数据导入hdfs集群
使用sqoop将oracle数据导入hdfs集群 集群环境: hadoop1.0.0 hbase0.92.1 zookeeper3.4.3 hive0.8.1 sqoop-1.4.1-incubati ...
- 将数据导入MongoDB集群与MySQL
import sys import json import pymongo import datetime from pymongo import MongoClient client = Mongo ...
- 从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 从零自学Hadoop(01):认识Hadoop ...
- 如何利用sqoop将hive数据导入导出数据到mysql
运行环境 centos 5.6 hadoop hive sqoop是让hadoop技术支持的clouder公司开发的一个在关系数据库和hdfs,hive之间数据导入导出的一个工具. 上海尚学堂 ...
- SQL SERVER 与ACCESS、EXCEL的数据导入导出转换
* 说明:复制表(只复制结构,源表名:a 新表名:b) select * into b from a where 1<>1 * 说明:拷贝表(拷贝数据,源表名:a 目标表名:b) ...
- SQL SERVER 和ACCESS、EXCEL的数据导入导出
SQL SERVER 与ACCESS.EXCEL之间的数据转换SQL SERVER 和ACCESS的数据导入导出[日期:2007-05-06] 来源:Linux公社 作者:Linux 熟 悉 ...
- Redis异构集群数据在线迁移工具Redis-Migrate-Tool【转】
摘要:Redis-Migrate-Tool(后面都简称RMT),是唯品会开源的redis数据迁移工具,主要用于异构redis集群间的数据在线迁移,即数据迁移过程中源集群仍可以正常接受业务读写请求,无业 ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- 从零自学Hadoop(18):Hive的CLI和JDBC
阅读目录 序 Hive CLI(old CLI) Beeline CLI(new CLI) JDBC Demo下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出 ...
随机推荐
- CSS表格溢出省略号代替及其他标签
box-shadow: 20px 20px 55px #777; // div阴影效果 filter:alpha(opacity=60) //设置透明度为60 opacity:0.6 //非IE浏览器 ...
- 将Json数据转换为ADO.NET DataSet对象
Json数据转换为ADO.NET DataSet其实方法有很多,Newtonsoft.Json也提供了DataSet的Converter用以转换Json数据.但是有些情况下DataSet Conver ...
- 【Kylin实战】Hive复杂数据类型与视图
1. 引言 在分析广告日志时,会有这样的多维分析需求: 曝光.点击用户分别有多少? 标签能覆盖多少广告用户? 各个标签(标注)类别能覆盖的曝光.点击在各个DSP上所覆盖的用户数 -- 广告数据与标签数 ...
- jQuery-1.9.1源码分析系列(二)jQuery选择器
1.选择器结构 jQuery的选择器根据源码可以分为几块 init: function( selector, context, rootjQuery ) { ... // HANDLE: $(&quo ...
- JAVA keytool 使用详解
Keytool是一个Java数据证书的管理工具 ,Keytool将密钥(key)和证书(certificates)存在一个称为keystore的文件中在keystore里,包含两种数据: 密钥实体 ...
- 实际案例:在现有代码中通过async/await实现并行
一项新技术或者一个新特性,只有你用它解决实际问题后,才能真正体会到它的魅力,真正理解它.也期待大家能够多分享解一些解决实际问题的内容. 在我们遭遇“黑色30秒”问题的过程中,切身体会到了异步的巨大作用 ...
- .NET正则表达式基础入门(三)
括号 正则表达式中的括号能将多个字符或者表达式当做一组,即将他们看成一个整体.这样量词就可以修饰这一组表达式.阅读本章前,建议先下载我于CSDN上传的示例代码,下载无需分数,下载链接. 1.分组 假设 ...
- ios 文件操作(NSFileManager)
IOS的沙盒机制,应用只能访问自己应用目录下的文件,iOS不像android,没有SD卡概念,不能直接访问图像.视频等内容. iOS应用产生的内容,如图像.文件.缓存内容等都必须存储在自己的沙盒内. ...
- 【C#公共帮助类】FTPClientHelper帮助类,实现文件上传,目录操作,下载等动作
关于本文档的说明 本文档使用Socket通信方式来实现ftp文件的上传下载等命令的执行 欢迎传播分享,必须保持原作者的信息,但禁止将该文档直接用于商业盈利. 本人自从几年前走上编程之路,一直致力于收集 ...
- js自动切换图片
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...