吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数
import tensorflow as tf # 1. sparse_softmax_cross_entropy_with_logits样例。
# 假设词汇表的大小为3, 语料包含两个单词"2 0"
word_labels = tf.constant([2, 0]) # 假设模型对两个单词预测时,产生的logit分别是[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5]
predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]]) # 使用sparse_softmax_cross_entropy_with_logits计算交叉熵。
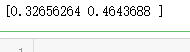
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits) # 运行程序,计算loss的结果是[0.32656264, 0.46436879], 这对应两个预测的
# perplexity损失。
sess = tf.Session()
print(sess.run(loss))
# 2. softmax_cross_entropy_with_logits样例。
# softmax_cross_entropy_with_logits与上面的函数相似,但是需要将预测目标以
# 概率分布的形式给出。
word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits)
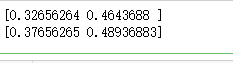
# 运行结果与上面相同:[ 0.32656264, 0.46436879]
print(sess.run(loss)) # label smoothing:将正确数据的概率设为一个比1.0略小的值,将错误数据的概率
# 设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。
word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_smooth, logits=predict_logits)
# 运行结果:[ 0.37656265, 0.48936883]
print(sess.run(loss)) sess.close()
吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数的更多相关文章
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:PTB 语言模型
import numpy as np import tensorflow as tf # 1.设置参数. TRAIN_DATA = "F:\TensorFlowGoogle\\201806- ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--测试
import sys import codecs import tensorflow as tf # 1.参数设置. # 读取checkpoint的路径.9000表示是训练程序在第9000步保存的ch ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\TensorFlowGoogle ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Seq2Seq模型--测试
import sys import codecs import tensorflow as tf # 1.参数设置. # 读取checkpoint的路径.9000表示是训练程序在第9000步保存的ch ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Seq2Seq模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经用9.2.1小节中的方法转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\Tens ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:文本数据预处理--生成训练文件
import sys import codecs # 1. 参数设置 MODE = "PTB_TRAIN" # 将MODE设置为"PTB_TRAIN", &qu ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:数据集高层操作
import tempfile import tensorflow as tf # 1. 列举输入文件. # 输入数据生成的训练和测试数据. train_files = tf.train.match_ ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:输入数据处理框架
import tensorflow as tf # 1. 创建文件列表,通过文件列表创建输入文件队列 files = tf.train.match_filenames_once("F:\\o ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:循环神经网络预测正弦函数
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # 定义RNN的参数. HIDDEN_SIZE = ...
随机推荐
- mailx发送邮件
cent6.5自带mailx 这是个第三方的邮件发送 比如用自己的126给其他账户发邮件 cent6.5还自带了postfix 可以停掉 sendmail(cent5才自带6是postfix)也 ...
- android 动画基础绘——view 动画
前言 对android 动画的整理,android 动画分为view动画(也叫补间动画),帧动画,属性动画. 看到这几个概念,让我想起了flash这东西.如果需要查各种动画具体的含义,那么可以去查询f ...
- 吴裕雄--天生自然JAVA SPRING框架开发学习笔记:第一个Spring程序
1. 创建项目 在 MyEclipse 中创建 Web 项目 springDemo01,将 Spring 框架所需的 JAR 包复制到项目的 lib 目录中,并将添加到类路径下,添加后的项目如图 2. ...
- tensorflow---darknet53
#! /usr/bin/env python# coding=utf-8#=============================================================== ...
- pycharm 的 使用 设置智能目录 Pycharm 断点跳转及 Step Over/Step Into/Step Out 等的区别
pycharm 右键点击文件夹 有个mark directiory as 根据需要给目录进行设置 Pycharm调试程序时,有时需要直接从第一个断点跳转至第二个断点,如果还是用单步调试的话就非常 ...
- vue select框change事件
vue Select 中< :label-in-value="true" @on-change="satusSelect"> satusSelect ...
- 9.1hadoop 内置计数器、自定义枚举计数器、Streaming计数器
1.1 计数器 计数器的作用是用来统计数量的,用于记录特定事件的次数,分为内置计数器.自定义java枚举计数器.自定义Stream计数器三大类.用于质量分析,或应用级统计.分析计数器的值比分析一堆日 ...
- MySQL-TPS,QPS到底是什么
计算TPS,QPS的方式 qps,tps是衡量数据库性能的关键指标,网上普遍有两种计算方式 TPS,QPS相关概念 QPS:Queries Per Second 查询量/秒,是一台服务 ...
- bootstrap 网格
实现原理 网格系统的实现原理非常简单,仅仅是通过定义容器大小,平分12份(也有平分成24份或32份,但12份是最常见的),再调整内外边距,最后结合媒体查询,就制作出了强大的响应式网格系统.Bootst ...
- 学习Unet的一些过程
毕业设计的项目,需要用到手机作为控制端,这就需要用到Unity的网络模块. 因为只会设计到几个简单的按钮命令,所以不打算做多么复杂的功能,一开始打算用C#的Socket编程,但是考虑到多线程的关系觉得 ...