分布式框架Celery(转)
一.简介
Celery是一个异步任务的调度工具。
Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农。
在 Python 中定义 Celery 的时候,我们要引入 Broker,中文翻译过来就是“中间人”的意思,在这里 Broker 起到一个中间人的角色。在工头提出任务的时候,把所有的任务放到 Broker 里面,在 Broker 的另外一头,一群码农等着取出一个个任务准备着手做。
这种模式注定了整个系统会是个开环系统,工头对于码农们把任务做的怎样是不知情的。所以我们要引入 Backend 来保存每次任务的结果。这个 Backend 有点像我们的 Broker,也是存储任务的信息用的,只不过这里存的是那些任务的返回结果。
我们可以选择只让错误执行的任务返回结果到 Backend,这样我们取回结果,便可以知道有多少任务执行失败了。
Celery(芹菜)是一个异步任务队列/基于分布式消息传递的作业队列。它侧重于实时操作,但对调度支持也很好。Celery用于生产系统每天处理数以百万计的任务。Celery是用Python编写的,但该协议可以在任何语言实现。
它也可以与其他语言通过webhooks实现。Celery建议的消息队列是RabbitMQ,但提供有限支持Redis, Beanstalk, MongoDB, CouchDB, 和数据库(使用SQLAlchemy的或Django的 ORM) 。Celery是易于集成Django, Pylons and Flask,
使用 django-celery, celery-pylons and Flask-Celery 附加包即可。
二.Celery 的架构
Celery 是一个强大的 分布式任务队列 的 异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行。我们通常使用它来实现异步任务(async task)和定时任务(crontab)。我们需要一个消息队列来下发我们的任务。
首先要有一个消息中间件,此处选择rabbitmq (也可选择 redis 或 Amazon Simple Queue Service(SQS)消息队列服务)。推荐 选择 rabbitmq 。使用RabbitMQ是官方特别推荐的方式。它的架构组成如下图:
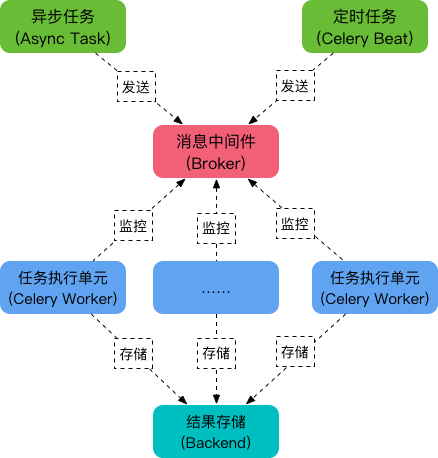
可以看到,Celery 主要包含以下几个模块:
任务模块 Task
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
消息中间件 Broker
Broker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等。
任务执行单元 Worker
Worker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
任务结果存储 Backend
Backend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, redis 和 MongoDB 等。
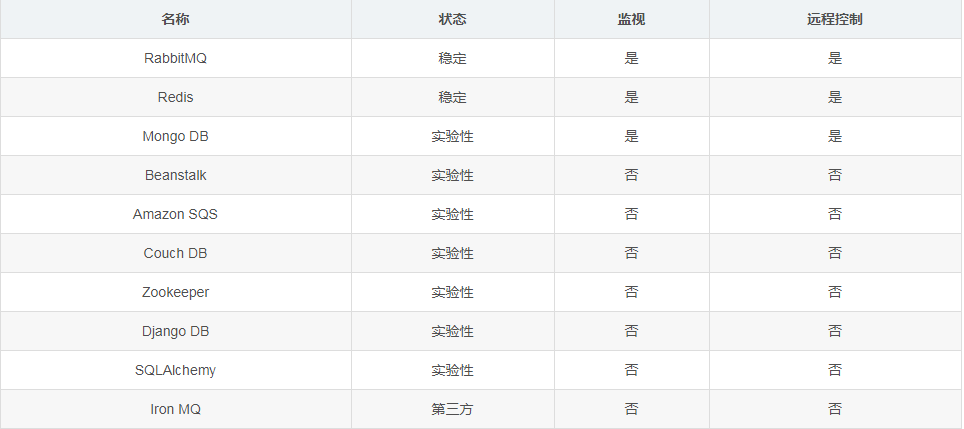
各个中间件的比较:
三.安装及初步使用
pip install celery #安装celery
小试牛刀:1. 定义任务函数。2. 运行celery服务。3. 客户应用程序的调用。
编写一个tasks.py的文件
# encoding: utf-8
from celery import Celery
#任务调度名称,指定中间件和结果存储的位置
app = Celery('tasks',broker="redis://127.0.0.1:6379/0",backend='redis://127.0.0.1:6379/1') @app.task
def add(x,y):
return x + y
上述代码导入了celery,然后创建了celery 实例 app,实例化的过程中指定了任务名tasks(和文件名一致),传入了broker和backend。然后创建了一个任务函数add。
运行:
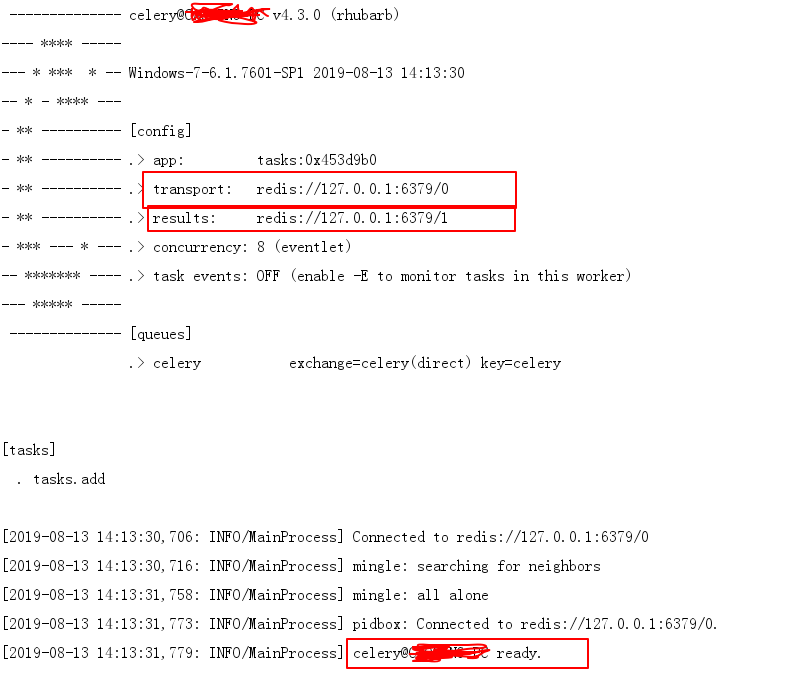
celery -A task worker -l info -P eventlet
这里,-A 表示我们的程序的模块名称,worker 表示启动一个执行单元,-l 是批 -level,表示打印的日志级别,-P这个参数是celery4.x之后要使用的,否则会报错。可以使用 celery –help 命令来查看celery命令的帮助文档。执行命令后,
worker界面展示信息如下:
如果你不想使用 celery 命令来启动 worker,可直接使用文件来驱动,修改task.py (增加入口函数main)
if __name__ == '__main__':
app.start()
再执行
python task.py worker
终端调用(需要在tasks.py同级目录下运行):
D:\tom\celery
λ python
Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from tasks import add
>>> r=add.delay(3,4)
>>> print(r.get())
7
>>> print(r.result)
7
>>> print(r.ready())
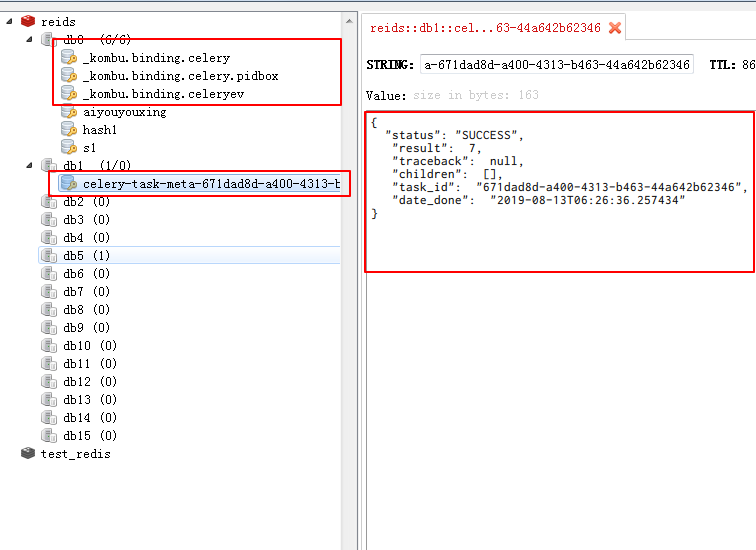
到redis看一下结果:
另外一种方法:
启用任务和的调度都使用脚本
功能:模拟一个耗时操作,并打印 worker 所在机器的 IP 地址,中间人和结果存储都使用 redis 数据库
#encoding=utf-8
#filename my_first_celery.py
from celery import Celery
import time
import socket app = Celery('tasks', broker='redis://127.0.0.1:6379/0',backend ='redis://127.0.0.1:6379/0' ) def get_host_ip():
"""
查询本机ip地址
:return: ip
"""
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(('8.8.8.8', 80))
ip = s.getsockname()[0]
finally:
s.close()
return ip @app.task
def add(x, y):
time.sleep(3) # 模拟耗时操作
s = x + y
print("主机IP {}: x + y = {}".format(get_host_ip(),s))
return s
启动这个 worker:
celery -A my_first_celery worker -l info -P eventlet
这里,-A 表示我们的程序的模块名称,worker 表示启动一个执行单元,-l 是批 -level,表示打印的日志级别。可以使用 celery –help 命令来查看celery命令的帮助文档。执行命令后,worker界面展示信息如下:
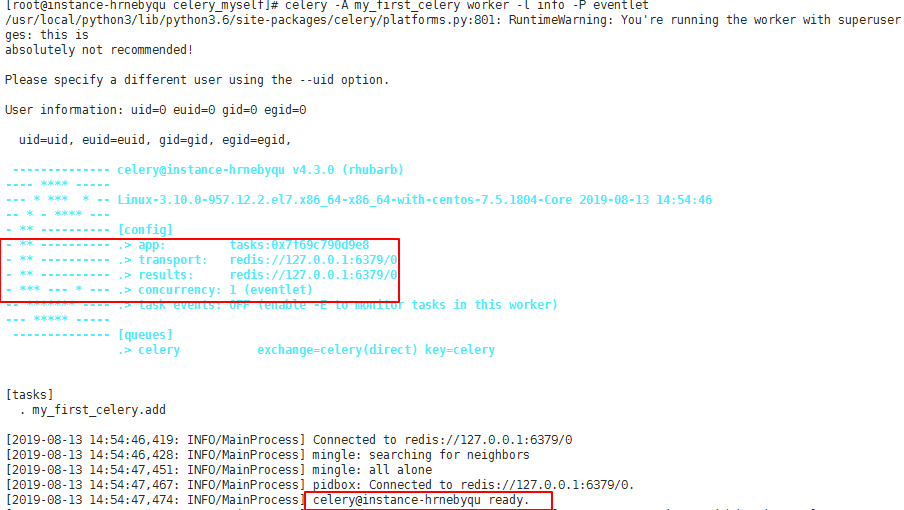
调用任务:
在 my_first_celery.py 的同级目录下编写如下脚本 start_task.py如下。
#encoding=utf-8
from my_first_celery import add #导入我们的任务函数add
import time
result = add.delay(12,12) #异步调用,这一步不会阻塞,程序会立即往下运行 while not result.ready():# 循环检查任务是否执行完毕
print(time.strftime("%H:%M:%S"))
time.sleep(1) print(result.get()) #获取任务的返回结果
print(result.successful()) #判断任务是否成功执行
执行
python start_task.py
结果如下所示:
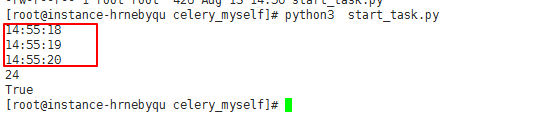
发现等待了大约3秒钟后,任务返回了结果24,并且是成功完成,此时worker界面增加的信息如下:

这里的信息非常详细,其中2004447e-1183-4d65-ae5d-bd8ead70e216是taskid,只要指定了 backend,根据这个 taskid 可以随时去 backend 去查找运行结果,使用方法如下:
>>> from my_first_celery import add
>>> taskid='2004447e-1183-4d65-ae5d-bd8ead70e216'
>>> add.AsyncResult(taskid).get()
24
>>> #或者
>>> from celery.result import AsyncResult
>>> AsyncResult(taskid).get()
24
重要说明:如果想远程执行 worker 机器上的作业,请将 my_first_celery.py 和 start_tasks.py 复制到远程主机上(需要安装
celery),修改 my_first_celery.py 指向同一个中间人和结果存储,再执行 start_tasks.py 即可远程执行 worker 机器上的作业。my_first_celery.add函数的代码不是必须的,你也要以这样调用任务:
from my_first_celery import app
app.send_task("my_first_celery.add",args=(1,3))
四.第一个 celery 项目
在生产环境中往往有大量的任务需要调度,单独一个文件是不方便的,celery 当然支持模块化的结构,我这里写了一个用于学习的 Celery 小型工程项目,含有队列操作,任务调度等实用操作,目录树如下所示:

app.py
#!/usr/bin/env python
# -*- coding: utf- -*-
#author tom from celery import Celery app = Celery("myCeleryProj", include=["myCeleryProj.tasks"]) app.config_from_object("myCeleryProj.settings") if __name__ == "__main__":
app.start()
settings.py
#!/usr/bin/env python
# -*- codin
# g: utf-8 -*-
#author tom
from kombu import Queue
import re
from datetime import timedelta
from celery.schedules import crontab CELERY_QUEUES = ( # 定义任务队列
Queue("default", routing_key="task.#"), # 路由键以“task.”开头的消息都进default队列
Queue("tasks_A", routing_key="A.#"), # 路由键以“A.”开头的消息都进tasks_A队列
Queue("tasks_B", routing_key="B.#"), # 路由键以“B.”开头的消息都进tasks_B队列
) CELERY_TASK_DEFAULT_QUEUE = "default" # 设置默认队列名为 default
CELERY_TASK_DEFAULT_EXCHANGE = "tasks"
CELERY_TASK_DEFAULT_EXCHANGE_TYPE = "topic"
CELERY_TASK_DEFAULT_ROUTING_KEY = "task.default" CELERY_ROUTES = (
[
(
re.compile(r"myCeleryProj\.tasks\.(taskA|taskB)"),
{"queue": "tasks_A", "routing_key": "A.import"},
), # 将tasks模块中的taskA,taskB分配至队列 tasks_A ,支持正则表达式
(
"myCeleryProj.tasks.add",
{"queue": "default", "routing_key": "task.default"},
), # 将tasks模块中的add任务分配至队列 default
],
) # CELERY_ROUTES = (
# [
# ("myCeleryProj.tasks.*", {"queue": "default"}), # 将tasks模块中的所有任务分配至队列 default
# ],
# ) # CELERY_ROUTES = (
# [
# ("myCeleryProj.tasks.add", {"queue": "default"}), # 将add任务分配至队列 default
# ("myCeleryProj.tasks.taskA", {"queue": "tasks_A"}),# 将taskA任务分配至队列 tasks_A
# ("myCeleryProj.tasks.taskB", {"queue": "tasks_B"}),# 将taskB任务分配至队列 tasks_B
# ],
# ) BROKER_URL = "redis://127.0.0.1:6379/0" # 使用redis 作为消息代理 CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/0" # 任务结果存在Redis CELERY_RESULT_SERIALIZER = "json" # 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间,不建议直接写86400,应该让这样的magic数字表述更明显 CELERYBEAT_SCHEDULE = {
"add": {
"task": "myCeleryProj.tasks.add",
"schedule": timedelta(seconds=10),
"args": (10, 16),
},
"taskA": {
"task": "myCeleryProj.tasks.taskA",
"schedule": crontab(hour=21, minute=10),
},
"taskB": {
"task": "myCeleryProj.tasks.taskB",
"schedule": crontab(hour=21, minute=12),
},
}
readme.txt
#启动 worker
#分别在三个终端窗口启动三个队列的worker,执行命令如下所示:
celery -A myCeleryProj.app worker -Q default -l info
celery -A myCeleryProj.app worker -Q tasks_A -l info
celery -A myCeleryProj.app worker -Q tasks_B -l info
#当然也可以一次启动多个队列,如下则表示一次启动两个队列tasks_A,tasks_B。
celery -A myCeleryProj.app worker -Q tasks_A,tasks_B -l info
#则表示一次启动两个队列tasks_A,tasks_B。
#最后我们再开启一个窗口来调用task: 注意观察worker界面的输出
>>> from myCeleryProj.tasks import *
>>> add.delay(4,5);taskA.delay();taskB.delay() #同时发起三个任务
<AsyncResult: 21408d7b-750d-4c88-9929-fee36b2f4474>
<AsyncResult: 737b9502-77b7-47a6-8182-8e91defb46e6>
<AsyncResult: 69b07d94-be8b-453d-9200-12b37a1ca5ab>
#也可以使用下面的方法调用task
>>> from myCeleryProj.app import app
>>> app.send_task(myCeleryProj.tasks.add,args=(4,5)
>>> app.send_task(myCeleryProj.tasks.taskA)
>>> app.send_task(myCeleryProj.tasks.taskB)
转自:https://blog.csdn.net/somezz/article/details/82343346
五.管理与监控
Celery管理和监控功能是通过flower组件实现的,flower组件不仅仅提供监控功能,还提供HTTP API可实现对woker和task的管理。
安装使用
pip3 install flower
启动
flower -A project --port=5555
# -A :项目目录
#--port 指定端口
访问http:ip:5555
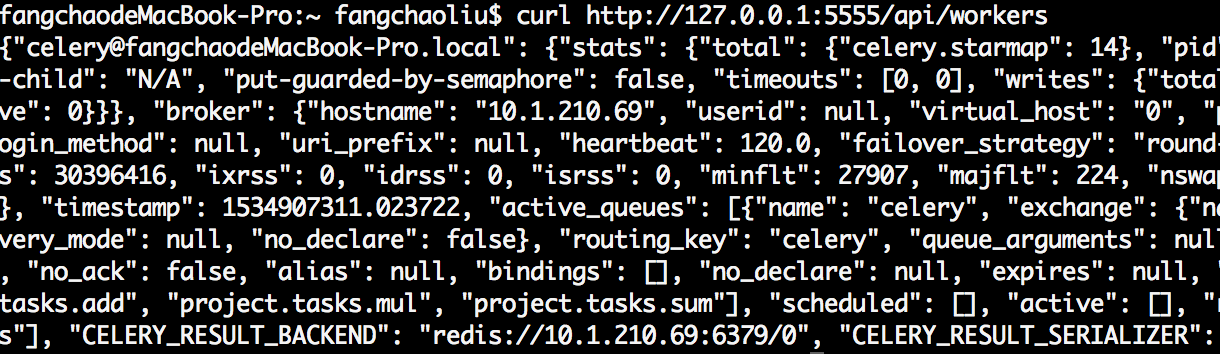
api使用,例如获取woker信息
curl http://127.0.0.1:5555/api/workers
结果:
更多api参考:https://flower.readthedocs.io/en/latest/api.html
分布式框架Celery(转)的更多相关文章
- Python 并行分布式框架 Celery
Celery 简介 除了redis,还可以使用另外一个神器---Celery.Celery是一个异步任务的调度工具. Celery 是 Distributed Task Queue,分布式任务队列,分 ...
- [源码解析] 并行分布式框架 Celery 之架构 (2)
[源码解析] 并行分布式框架 Celery 之架构 (2) 目录 [源码解析] 并行分布式框架 Celery 之架构 (2) 0x00 摘要 0x01 上文回顾 0x02 worker的思考 2.1 ...
- [源码解析] 并行分布式框架 Celery 之架构 (1)
[源码解析] 并行分布式框架 Celery 之架构 (1) 目录 [源码解析] 并行分布式框架 Celery 之架构 (1) 0x00 摘要 0x01 Celery 简介 1.1 什么是 Celery ...
- [源码解析] 并行分布式框架 Celery 之 worker 启动 (1)
[源码解析] 并行分布式框架 Celery 之 worker 启动 (1) 目录 [源码解析] 并行分布式框架 Celery 之 worker 启动 (1) 0x00 摘要 0x01 Celery的架 ...
- [源码解析] 并行分布式框架 Celery 之 worker 启动 (2)
[源码解析] 并行分布式框架 Celery 之 worker 启动 (2) 目录 [源码解析] 并行分布式框架 Celery 之 worker 启动 (2) 0x00 摘要 0x01 前文回顾 0x2 ...
- [源码解析] 并行分布式框架 Celery 之 容错机制
[源码解析] 并行分布式框架 Celery 之 容错机制 目录 [源码解析] 并行分布式框架 Celery 之 容错机制 0x00 摘要 0x01 概述 1.1 错误种类 1.2 失败维度 1.3 应 ...
- [源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Mingle
[源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Mingle 目录 [源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Ming ...
- 【转】Python 并行分布式框架 Celery
原文链接:https://blog.csdn.net/freeking101/article/details/74707619 Celery 官网:http://www.celeryproject.o ...
- [源码解析] 并行分布式任务队列 Celery 之 消费动态流程
[源码解析] 并行分布式任务队列 Celery 之 消费动态流程 目录 [源码解析] 并行分布式任务队列 Celery 之 消费动态流程 0x00 摘要 0x01 来由 0x02 逻辑 in komb ...
随机推荐
- 渗透利器-BadUSB 控制外网主机详解 Teensy2.0++
准备工作 一块 Teensy2.0++ 的板子(淘宝一搜就有) Arduino编译器 1.8.7版本下载连接:arduino下载地址 Teensy插件 下载连接:Teensy下载地址 [外链图片转存失 ...
- nevertheless|magnificent |prosperous|
ADV 然而;不过You use nevertheless when saying something that contrasts with what has just been said. Mos ...
- 制作MACOSX 10.9Mavericks安装启动U盘教程
苹果OS X Mavericks发布了,不少朋友又开始制作系统安装U盘了.其实下面介绍的方法与之前介绍的方法可能有些不同,不过原理还是一样的.下面看看具体的操作步骤吧! 1. 首先你需要开启显示隐藏文 ...
- mongodb Map/reduce测试代码
private void AccountInfo() { ls.Clear(); DateTime dt = DateTime.Now.Date; IMongoQuery query = Query& ...
- python 面向对象静态方法、类方法、属性方法、类的特殊成员方法
静态方法:只是名义上归类管理,实际上在静态方法里访问不了类或实例中的任何属性. 在类中方法定义前添加@staticmethod,该方法就与类中的其他(属性,方法)没有关系,不能通过实例化类调用方法使用 ...
- react render渲染的几种情况
1. 首次加载 2. setState改变组件内部state. 注意: 此处是说通过setState方法改变. 3. 接受到新的props
- 产品需求说明书 PRD模版
XXX产品需求说明书 [版本号:V+数字] 编 制: 日 期: 评 审: 日 期: 批 准: 日 期: 修订记录 版本 修订章节 修订内容 ...
- 餐厅随评系列之四:Umu日本料理(米其林二星)
文章目录 在过去的几个月,工作和生活都极其忙碌,因此博客短暂停更了一阵子.慢慢积累下了很多素材,从近期开始恢复博客更新,不过很多内容估计得靠回忆了. 索性采取"倒叙"的方法,先从最 ...
- uploadifive如何动态传参
直接上代码 关键:$('#file_upload').data('uploadifive').settings.formData = { 'ID': 'ceshi'}; //动态更改formData的 ...
- 微服务SpringBoot总结
什么是SpringBootSpringBoot是Spring项目中的一个子工程,与我们所熟知的Spring-framework 同属于spring的产品官方介绍:Spring Boot makes i ...